서버 애플리케이션의 성능 개선을 위해 눈여겨보고는 하는 인덱스, 이 인덱스는 크게 클러스터 인덱스와 논클러스터 인덱스로 구분됩니다.
쉽게 얘기해 클러스터 인덱스는 실제 데이터를 물리적으로 정렬해 클러스터로 꾸려둔 것이고, 논클러스터 인덱스는 인덱스 페이지를 이용하는 그 외의 것들을 지칭한다고 볼 수 있는데요, 각 인덱스의 특징이 무엇이고 무엇이 다른지 알아보겠습니다.
1. 클러스터 인덱스
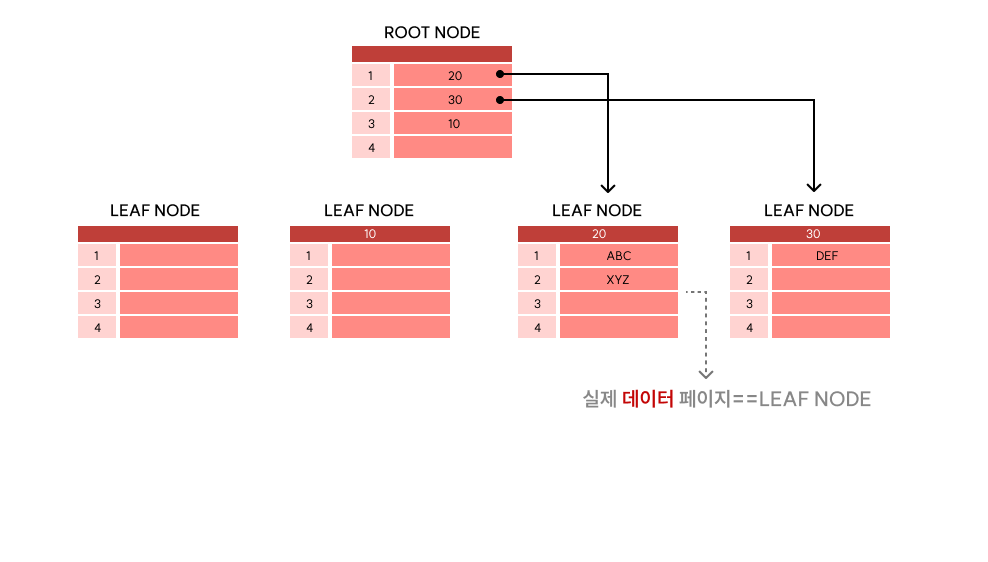
1. 특징
- 테이블당 1개만 허용됨
- B-Tree 구조임
- 물리적으로 행을 재배열하며 항상 정렬 상태를 유지함
- 테이블에 PK를 설정할 시, 자동으로 해당 칼럼에 대해 클러스터 인덱스가 만들어짐
- 리프 페이지로 데이터 페이지를 가짐
- 따라서 논클러스터 인덱스보다 조회 속도가 빠르나, 입력, 수정, 삭제의 속도는 느림
- 인덱스 페이지를 따로 만들지 않으므로, 논클러스터 인덱스보다 차지하는 용량이 적음
2. 유용한 경우
- 테이블 데이터가 자주 업데이트되지 않고, 조회가 더 많이 일어나는 경우
- 값이 물리적으로 정렬되어 있기 때문에, Between같이 범위 값을 반환하거나 Order by같이 정렬하는 쿼리와 함께 사용하면 성능이 좋음
2. 논클러스터 인덱스
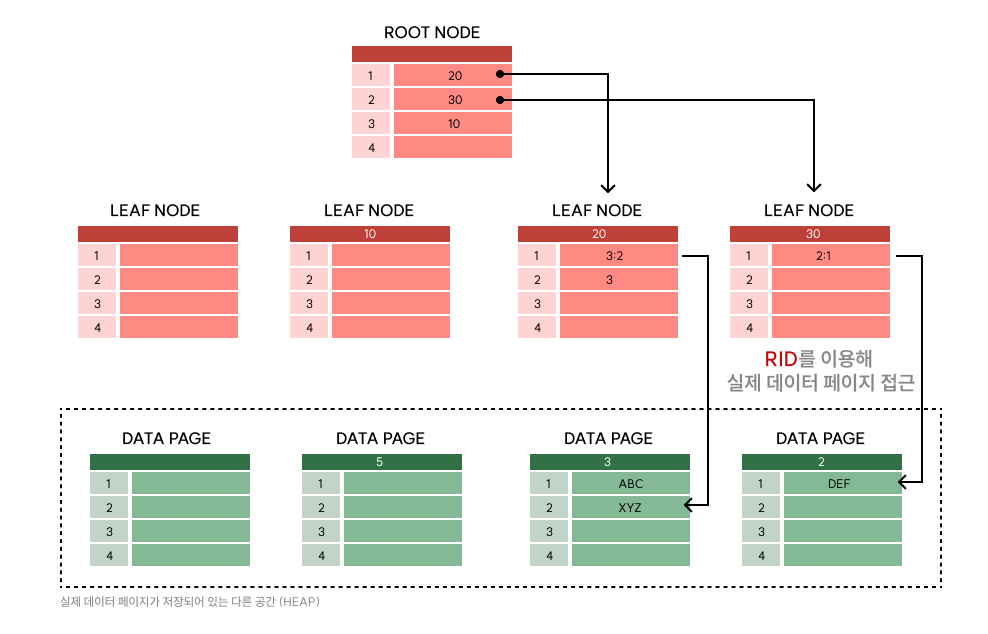
1. 특징
- 테이블당 약 240개가 허용됨
- 로그 파일에 인덱스 페이지가 저장됨
- 즉, 실제 데이터가 저장된 곳(Heap)과 인덱스 페이지는 별도의 공간에 존재함
- 레코드의 물리적 행을 정렬하지 않고, 인덱스 페이지만 정렬함
- 즉, 실제 데이터는 클러스터 인덱스와 다르게 정렬되어 있지 않음
- 리프 페이지는 데이터 페이지가 아닌, 데이터 페이지의 위치를 나타내는 포인터(RID)임
- 따라서 클러스터 인덱스보다 조회 속도는 느리나, 입력, 수정, 삭제의 속도는 빠름
- 인덱스 페이지를 생성하기 때문에 클러스터 인덱스에 비해 차지하는 용량이 큼
👀 RID?
- Row Id
- DB에서 데이터가 가진 실제 주소
- 데이터를 구분할 수 있도록, 모든 데이터는 유니크한 주소를 가지고 있음
2. 유용한 경우
- 데이터가 조회보다는 업데이트가 더 많이 일어나는 경우
이렇듯, 클러스터 인덱스와 논클러스터 인덱스는 데이터 구조뿐만 아니라, 데이터에 접근하는 과정도 상이합니다.
클러스터 인덱스는 데이터에 바로 접근할 수 있는 반면, 논클러스터 인덱스는 목차에서 해당 페이지의 번호를 찾아 데이터에 접근하는 단계가 더 필요하죠.
인덱스 구조에 대해 공부하는 과정에서 해당 내용에 대해 간단하게 다루어봤는데요, 차차 인덱스, DB 관련 내용을 포스팅해보도록 하겠습니다.👍

CS 마스터를 향해 ..