[ML] Decision Tree (의사결정나무)

Decision Tree란?
: 의사결정나무(decision tree)는 여러 가지 규칙을 순차적으로 적용하면서 독립 변수 공간을 분할하는 분류 모형이다. 분류(classification)와 회귀(regression)에 모두 사용될 수 있기 때문에 CART(Classification And Regression Tree)라고도 한다.
작동 원리
: 의사결정 나무의 핵심 원리는 불순도(impurity)를 최소화하는 방향으로 데이터를 분할하는 것이다. 불순도는 일반적으로 지니 계수(Gini Index), 엔트로피(Entropy), 정보 이득(Information Gain) 등을 사용해 측정한다.
불순도(Impurity)
: 각 노드에서 클래스의 혼합 정도이다. 불순도가 낮을수록 해당 노드는 한 클래스의 데이터로 잘 분류된 상태를 의미한다.
의사결정 나무는 불순도를 최소화하는 방향으로 학습을 진행하게 된다.
지니계수(Gini)
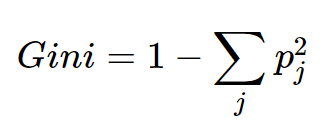
: 데이터의 불순도를 측정하는 방법으로 0에서 1사이의 값을 가진다. 0은 완벽하게 분류된 상태(하나의 클래스만 존재), 1은 모든 클래스가 동등하게 분포된 상태를 의미한다.
엔트로피(Entropy)
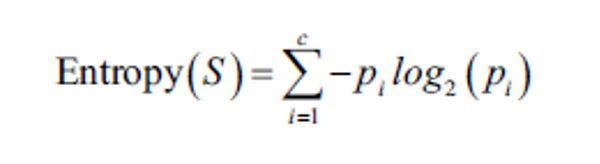
: 엔트로피도 불순도를 측정하는 방법 중 하나로, 정보의 불확실성을 측정한다. 엔트로피가 높을수록 정보의 불확실성이 높아진다. 엔트로피는 클래스의 비율이 균등할수록 높은 값을 가진다. 따라서 의사결정나무는 엔트로피를 최소화하는 방향으로 분할한다.
정보 이득(Information Gain)
정보이득 = 부모노드의 불순도 - 자식노드의 불순도들의 가중평균
: 불순도를 감소시키는 정도를 측정하는 지표로 부모노드와 자식노드의 불순도의 차이를 의미한다. 즉, 어떤 특성을 선택했을 때 얻는 정보의 양을 나타낸다. 정보 이득이 큰 특성을 기준으로 데이터를 분할하게 된다.
정보이득의 최대화 -> 불순도의 감소 -> 엔트로피의 감소
가지치기(Pruning)
: 과적합을 방지하기 위한 방법 중 하나이다. Full Tree는 모든 끝 마디에서의 순도가 100%인 상태입니다. 분기가 너무 많아져서 Overfitting이 일어나기 쉽기 때문에 적절한 수준에서 끝 노드를 결합해주는 가지치기가 필요하다.
특성 중요도(Feature Importance)
: 각 특성이 얼마나 중요한 역할을 하는지를 측정하는 지표이다. 이는 해당 특성에 의한 분할이 불순도를 얼마나 감소시키는지에 따라 결정된다. 특성 중요도의 합은 항상 1이며, 각 특성의 중요도는 0과 1사이의 값을 갖는다. 불순도를 가장 크게 감소시키는 변수의 중요도가 가장 크다.
Python 예제 코드
scikit-learn의 DecisionTreeClassifier를 사용하였다. scikit-learn에서는 CART 알고리즘을 사용하는데 이경우는 이진트리로만 분기한다.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
clf = DecisionTreeClassifier(criterion='gini', max_depth=None, random_state=42)
clf.fit(X_train, y_train)import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(25,10))
plot_tree(clf, filled=True, fontsize = 14)
plt.show()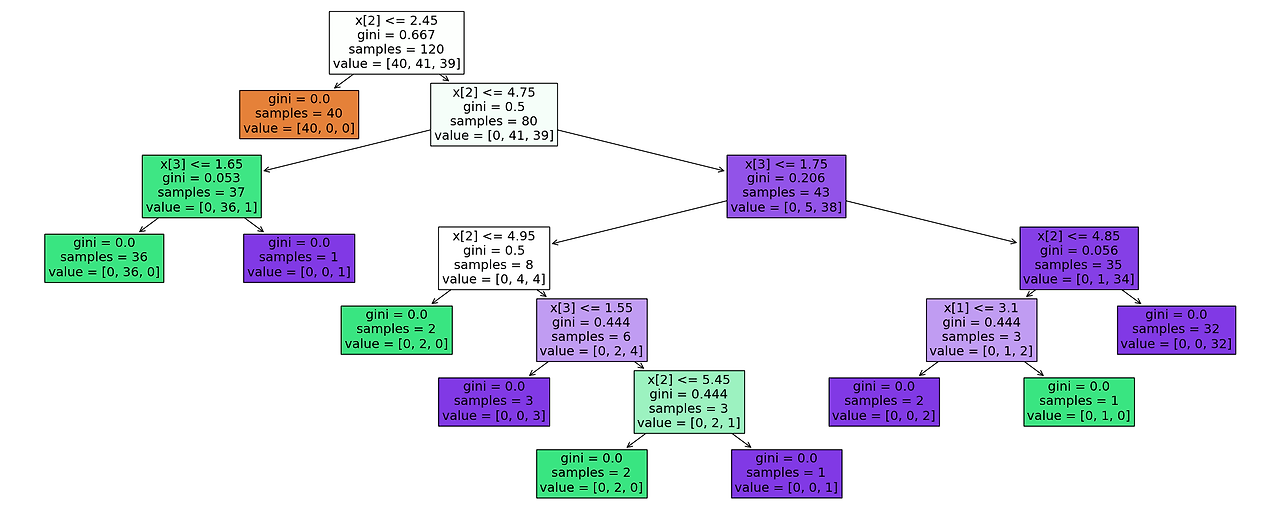
DecisionTreeClassifier 하이퍼파라미터
criterion: 'gini' 또는 'entropy'. 기본값은 'gini'. 이 매개변수는 불순도를 측정하는 기준을 결정합니다. 'gini'는 지니 불순도를, 'entropy'는 엔트로피를 의미합니다.splitter: 'best' 또는 'random'. 기본값은 'best'. 'best'는 가장 좋은 분할을 찾고, 'random'은 무작위로 분할합니다max_depth: 트리의 최대 깊이를 결정합니다. 이 매개변수를 통해 과적합을 방지할 수 있습니다. None으로 설정하면, 모든 잎이 순수해질 때까지 트리가 성장합니다.min_samples_split: 노드를 분할하기 위해 필요한 최소 샘플 수를 결정합니다. 숫자로 지정할 수도 있고, 전체 샘플 수에 대한 비율로 지정할 수도 있습니다.min_samples_leaf: 리프 노드에 있어야 하는 최소 샘플 수를 결정합니다. 숫자로 지정할 수도 있고, 전체 샘플 수에 대한 비율로 지정할 수도 있습니다.min_weight_fraction_leaf: 가중치가 부여된 전체 샘플 수에 대한 비율로, 리프 노드에 있어야 하는 최소 샘플 수를 결정합니다.max_features: 각 노드에서 분할에 사용할 특성의 최대 수를 결정합니다.random_state: 내부적으로 사용되는 난수 생성기의 시드입니다. 이 값을 고정하면, 같은 조건에서 같은 결과를 얻을 수 있습니다.max_leaf_nodes: 리프 노드의 최대 수를 결정합니다. None일 경우 제한이 없습니다.min_impurity_decrease: 이 값보다 불순도 감소가 큰 분할만 고려됩니다.class_weight: 클래스 가중치를 지정합니다. 주로 불균형 데이터셋에 사용됩니다.
