※ 데이터베이스 SQL로 애플리케이션 서버랑 DB를 연결할 때 필요한게 JDBC라는 기술이다. 순수하게 JDBC로 개발하는 건 어려워서 스프링은 JDBC 템플릿이라는 기술을 제공한다. 이걸 가지고 애플리케이션에서 데이터베이스로 SQL을 편리하게 날릴 수 있다.
더 혁신적인 방법인 SPA가 있는데, SQL조차도 개발자들이 직접 짜는게 아닌 SPA가 SQL 쿼리를 다 날려준다.
또 JPA기술을 쓰면 쿼리 없이 객체를 바로 DB에 저장하고 관리할 수 있다.
스프링데이터JPA는 JPA를 편리하게 쓸 수 있도록 한 번 감싼 기술이다.
앞으로 기술들을 적용해가면서 회원 정보(ID, name)을 한단계씩 바꿔가는 과정을 통해 공부해보자.
DB는 실무에서 MySQL, Oracle을 많이 사용한다. 특히 MySQL계열이라고 부르는 DB많이 사용할 것이다.
H2 데이터베이스 설치
이때까진 메모리에 데이터를 저장했기때문에 서버가 내려가면 회원 데이터가 다 사라졌었다.
실무에서는 데이터베이스에 데이터를 저장하고 관리한다. 우리는 가볍고 심플한 H2 데이터베이스를 설치해보자.
https://www.h2database.com
다음 링크에서 설치할 수 있다.
설치이후 cmd에서 해당 설치 파일에 들어가(cd study/h2/bin)
chmod 755 h2.sh 로 권한을 준 뒤(윈도우는 할 필요 없음)
./h2.sh 로 실행해보자.
화면이 다음과 같이 뜨는 경우는 ip주소를 localhost로 수정해주면 된다.
http://218.38.137.27:8082/?key=ec39c7c6097db728ee29d3311c7c786b5bf9e4d5f384deff16f097f40235f6b4
⬇️
http://localhost:8082/login.jsp?jsessionid=34640a29cf8535d3eb5ff23656c59f1a
그러면 다음과 같은 화면이 뜬다.
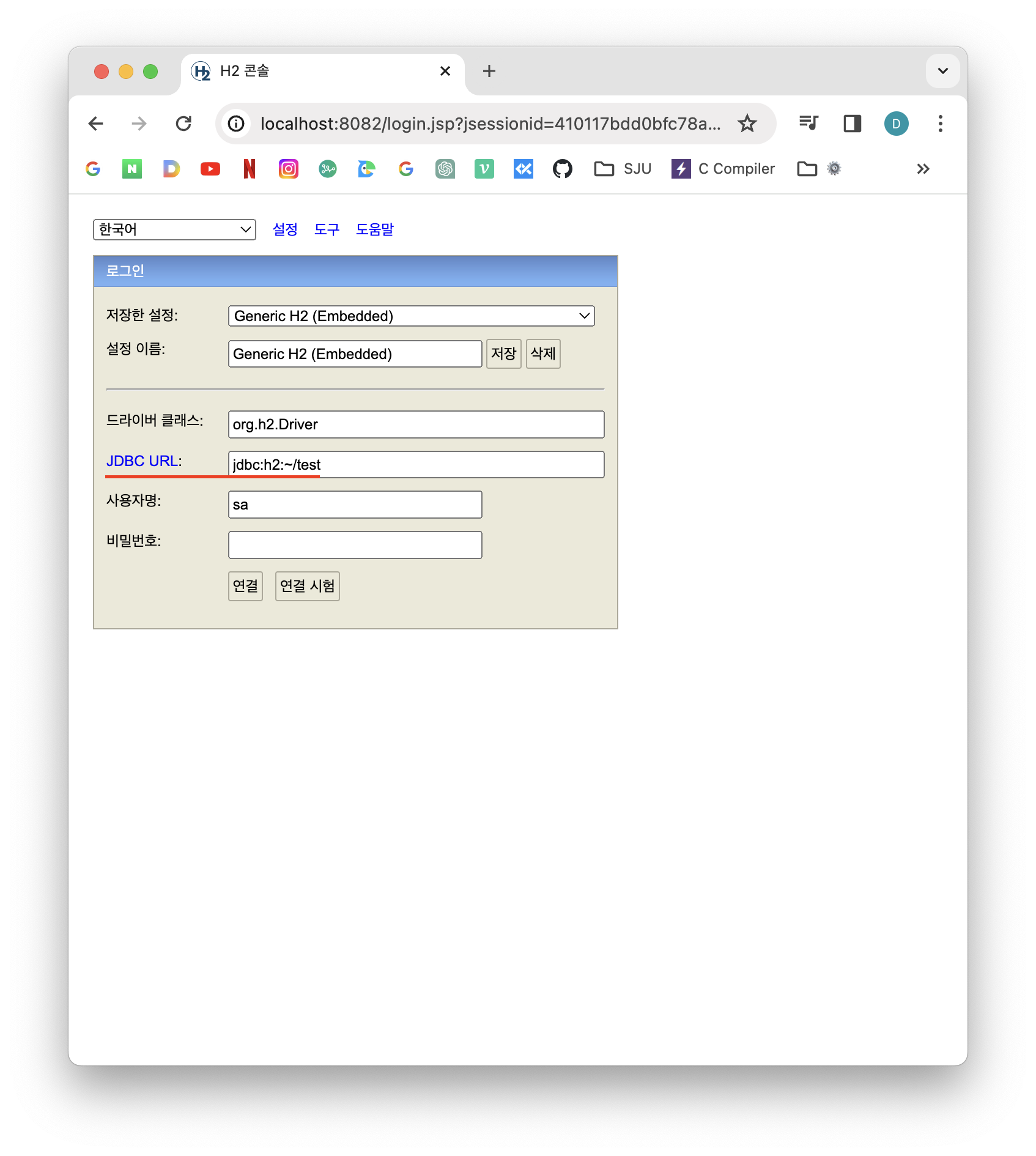
최초에는 데이터베이스 파일을 만들어주어야한다.
JDBC URL: jdbc:h2:~/test이는 내 홈에 테스트 파일을 생성한다는 것을 말한다.
연결 버튼을 누르면 홈에 test.mv.db파일이 생긴다.
앞으로 위의 방법처럼 파일로 접근하게 되면 동시에 애플리케이션, 웹 콘솔과 같은 것들이 접근할 때 파일 충돌이 일어나 같이 접근이 안될 수 있다. 그러므로 파일 생성은 위와 같은 방법으로 하고 그 다음부터는 파일에 직접 접근하는게 아닌 소켓을 통해서 다음과 같이 접근해야 여러군데에서 접근할 수 있다. (jdbc:h2:tcp://localhost/~/test 입력)
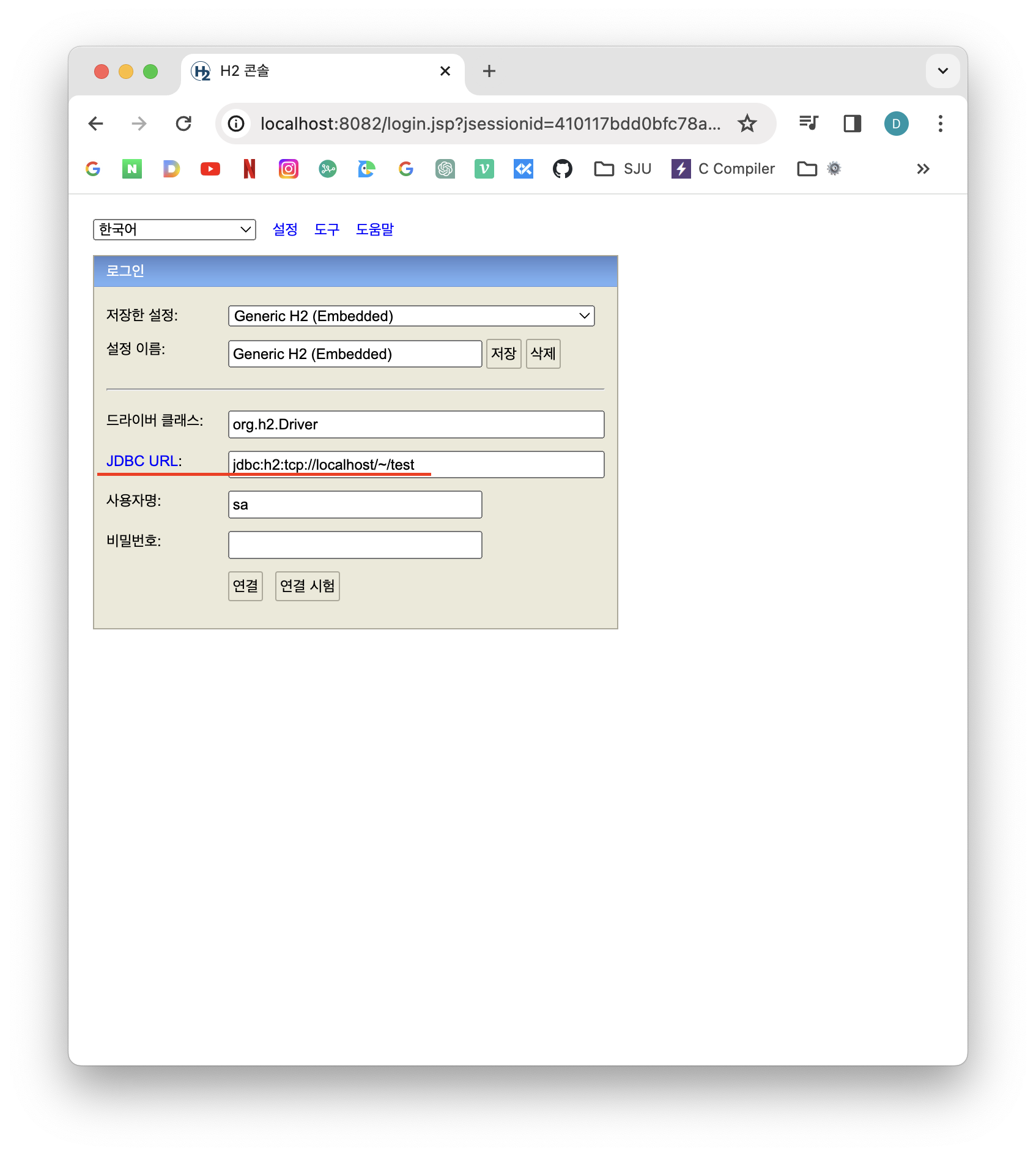
(문제가 생기면 파일을 지우고 처음부터 다시 해보자(rm test.mv.db))
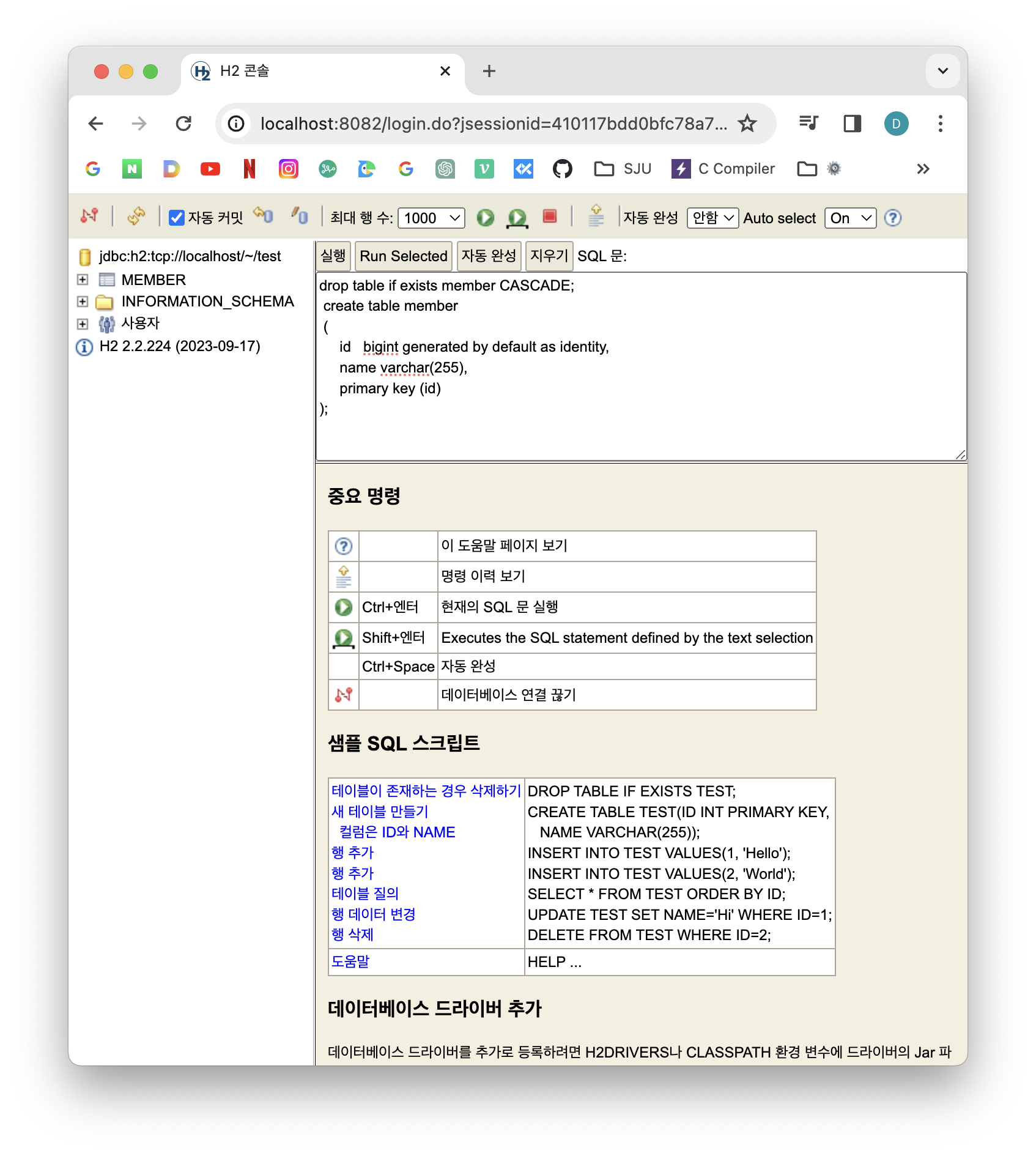
이제 데이터베이스 파일을 만들어줬으니 여기에 테이블을 만들어보자.
다음 코드를 입력하면 된다.
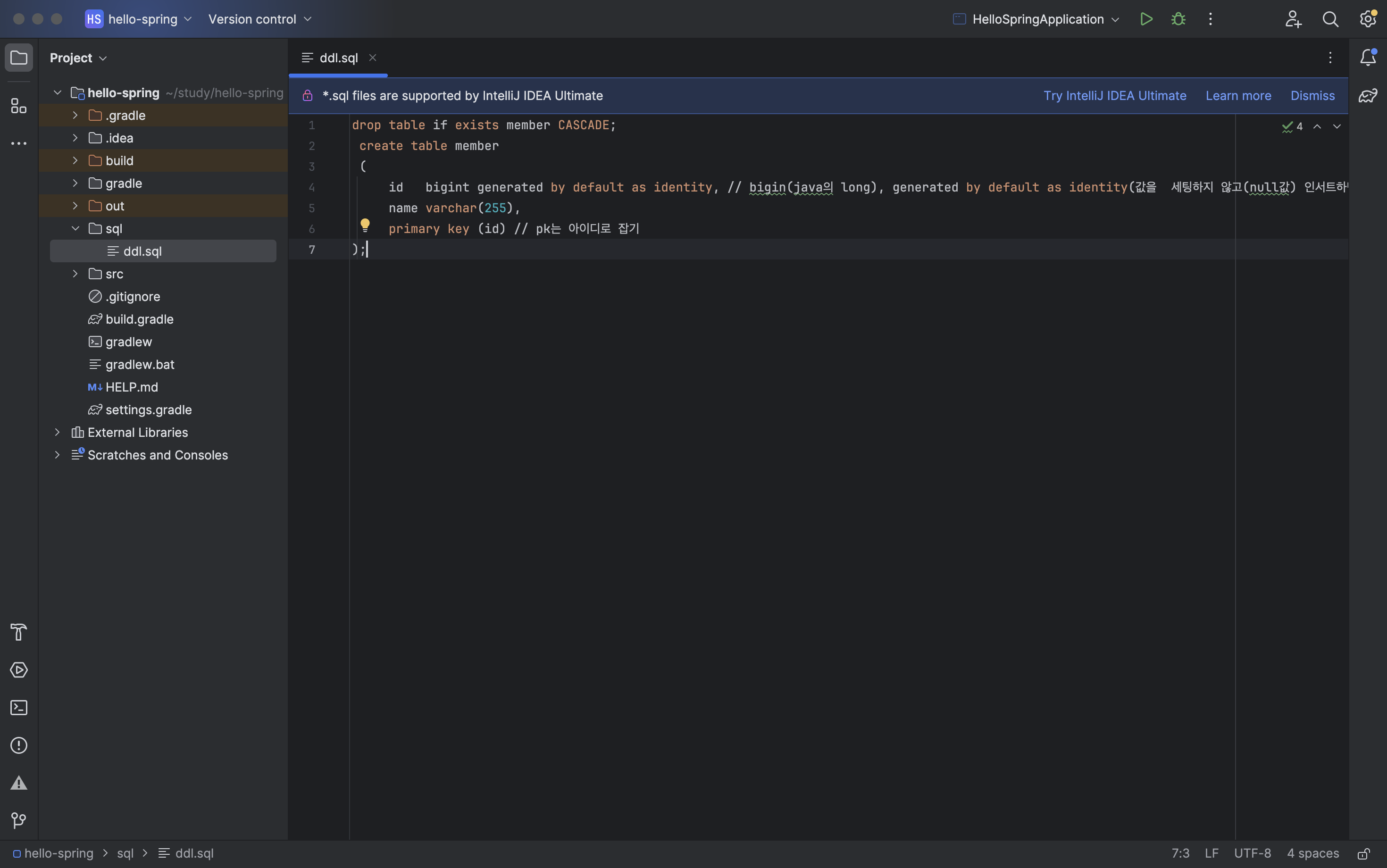
drop table if exists member CASCADE;
create table member
(
id bigint generated by default as identity,
name varchar(255),
primary key (id)
);※ 참고
bigin : java의 long을 의미
generated by default as identity : 값을 세팅하지 않고(null값) 인서트하면 db가 들어왔을 때 자동으로 id값을 채워준다.
primary key (id) : pk는 아이디로 설정했다.
select * from member를 입력하면 (왼쪽의 member파일 클릭하면 자동작성됨) 다음과 같이 테이블이 잘 만들어진 것을 볼 수 있다.
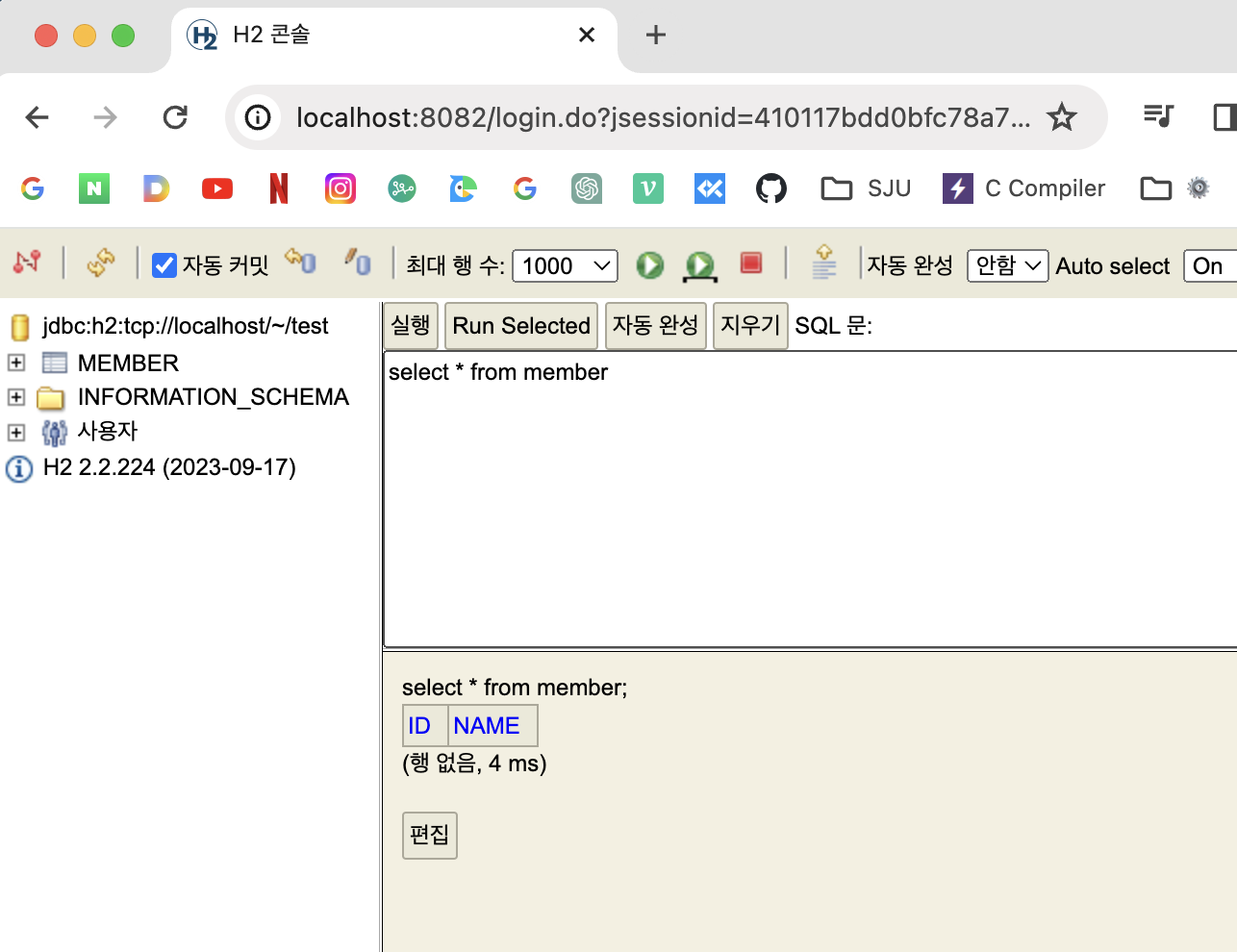
이제 이 테이블에 insert를 해보자.
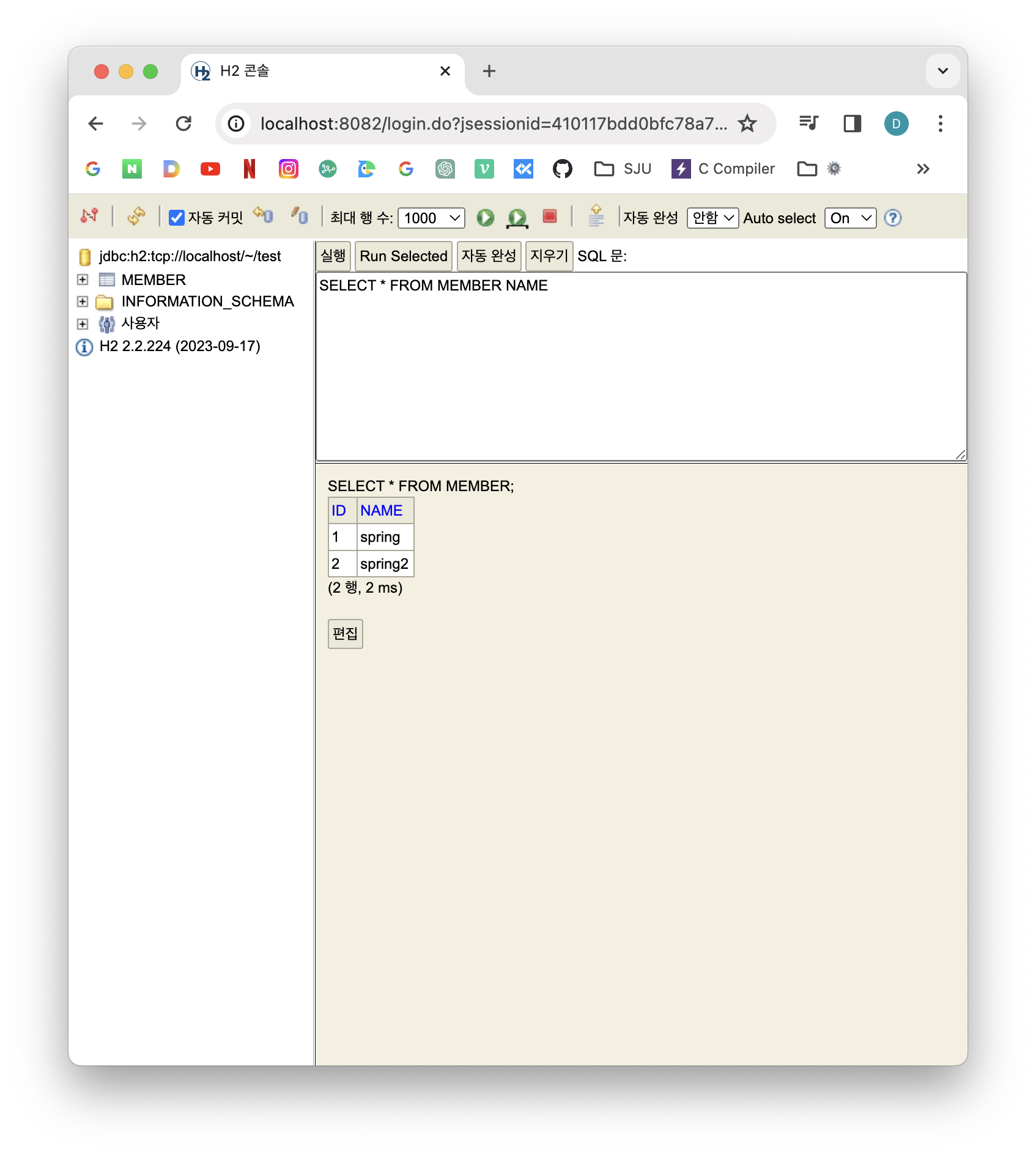
insert into member(name) values('spring')
insert into member(name) values('spring2') 위를 입력하고 멤버를 확인하면 다음과 같이 잘 생성된 것을 볼 수 있다.
(id를 생략하고 넣으면 db가 generate value해서 id를 자동으로 증가시켜 만들어준다.)
💡 tip
git에서 소스 관리를 하기 위해 sql디렉토리를 다음과 같이 만들어 따로 관리해주자.
순수 JDBC
이렇게 JDBC API로 직접 코딩하는 것은 20년 전 이야기이다.
이 부분은 참고만 하고 넘어가자.
build.gradle 파일에 jdbc, h2 데이터베이스 관련 라이브러리 추가
implementation 'org.springframework.boot:spring-boot-starter-jdbc'
runtimeOnly 'com.h2database:h2'resources/application.properties
spring.datasource.url=jdbc:h2:tcp://localhost/~/test
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.username=sa[JDBC 리포지토리 구현]
JdbcMemberRepository.java
SpringConfig.java
파일을 변경해준다. (자세한 코드는 생략)
스프링 통합 테스트
이제 테스트를 스프링과 엮어서 실행 해보자. 이전의 테스트는 순수 자바만을 이용한 테스트였다.
MemberServiceIntegrationTest.java에서 다음 부분을 추가하고 필요없는 부분은 삭제하였다.
MemberServiceIntegrationTest.java
...
@SpringBootTest
@Transactional
class MemberServiceIntegrationTest {
@Autowired MemberService memberService;
@Autowired MemberRepository memberRepository;
...
}-
@SpringBootTest의 역할
테스트를 스프링 컨테이너와 함께 실행한다 -
@Transactional의 역할
테스트 케이스에 이 애노테이션이 있으면, 테스트 시작 전에 트랜잭션을 시작하고, 테스트 완료 후에 항상 롤백한다. 이렇게 하면 DB에 데이터가 남지 않으므로 다음 테스트에 영향을 주지 않는다.
테스트메소드 각각 하나마다 적용이 된다.
서비스에 붙으면 롤백하지 않고 정상적으로 동작하고, 테스트 케이스에 붙었을 때만 항상 롤백하도록 동작한다.
- 데이터베이스는 기본적으로
transaction이라는 개념이 있어,insert query를 한 다음 이걸commit하기 전까지 DB에 반영이 안된다. commit은 자동으로 하냐 안하냐의 차이뿐 꼭 해줘야 한다.(오토커밋모드)
@Transactional 애노테이션을 테스트케이스에 달면 테스트를 실행할 때 transaction을 먼저 실행하고 테스트가 끝나면 롤백을 해준다. 즉 DB에 해당 데이터를 반영하지 않는다.
1) 우선 delete from MEMBER로 DB의 데이터 모두 지워주기
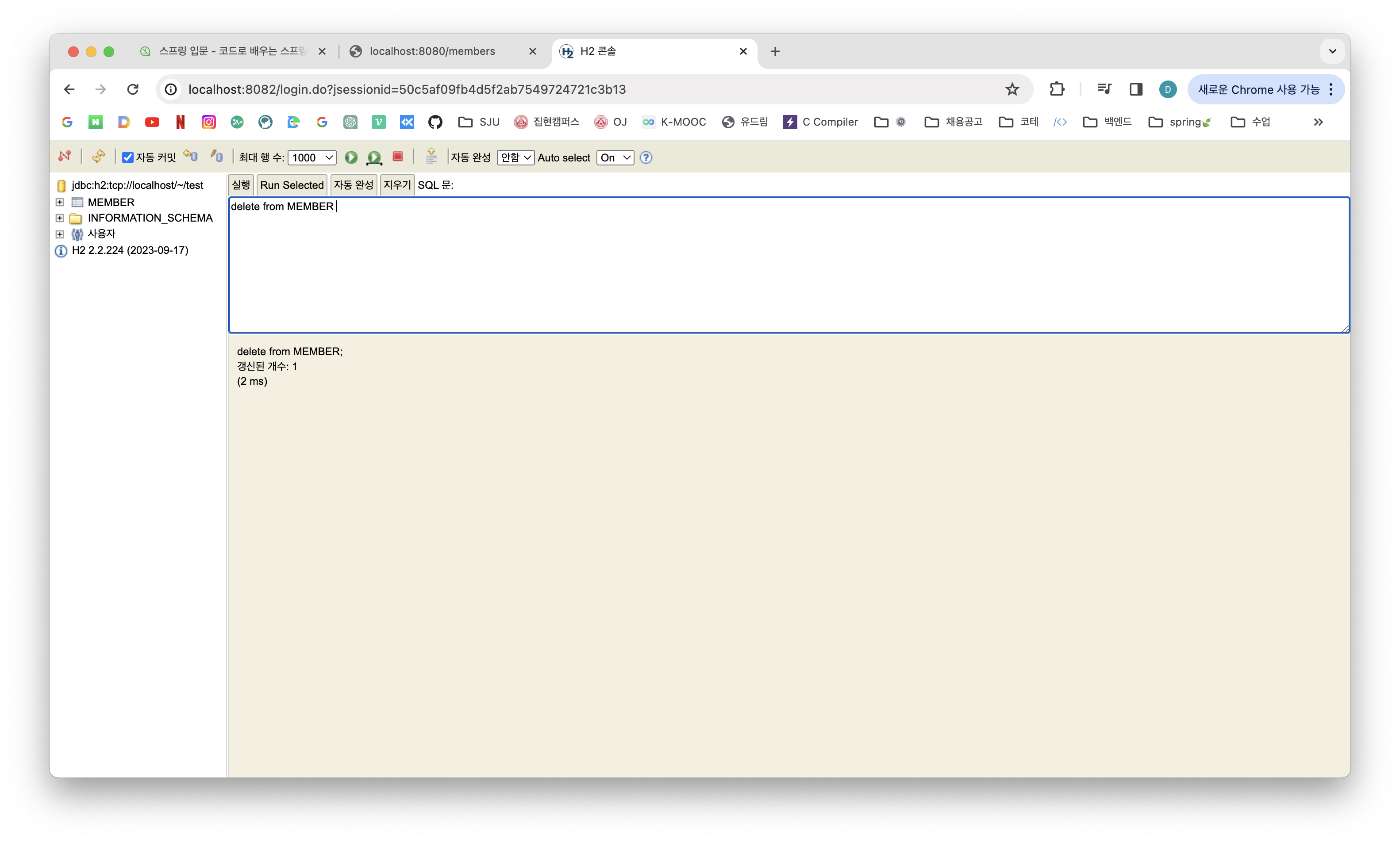
2-1) @Transactional이 없는 경우
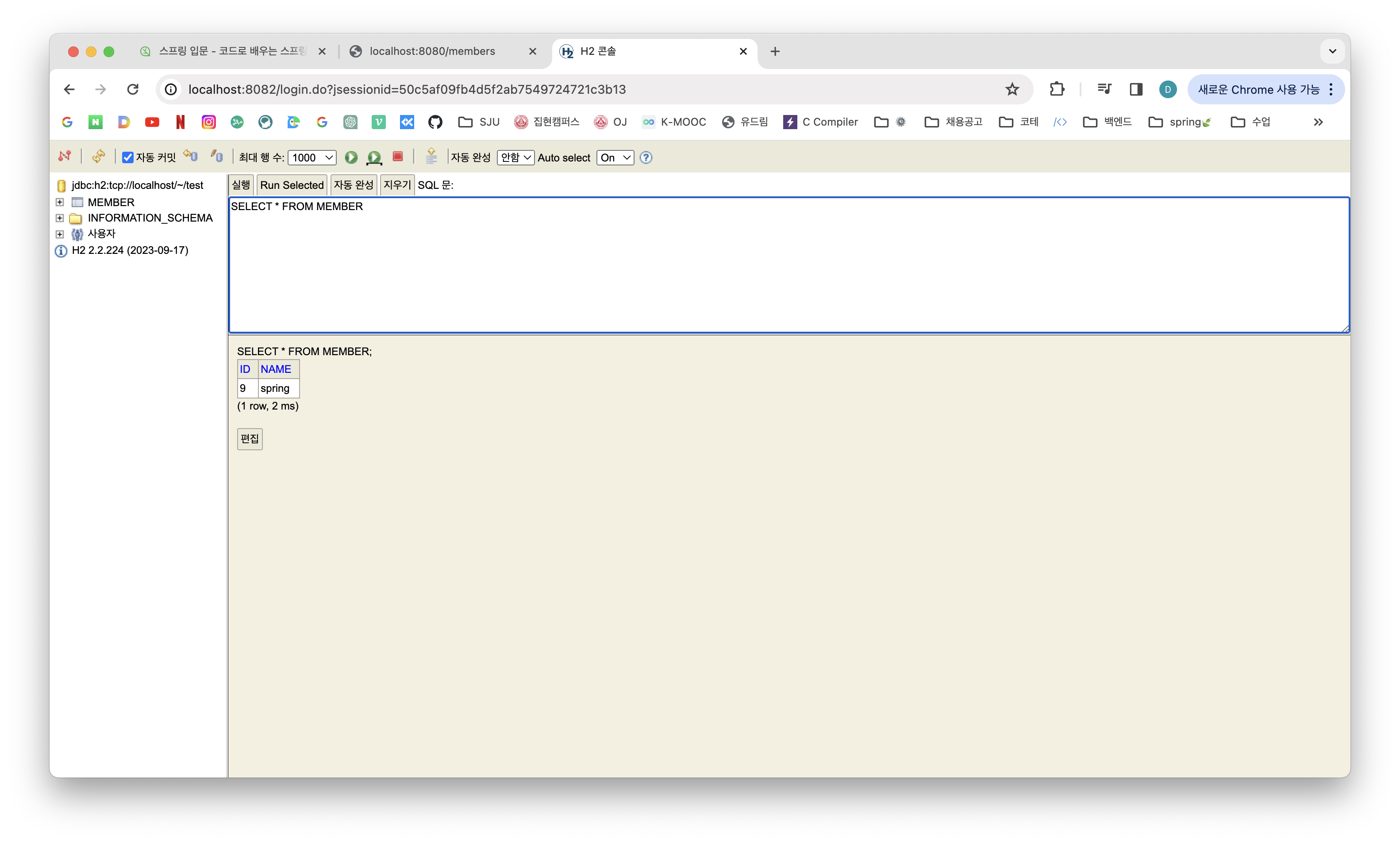
만약 @Transactional을 생략하고 테스트를 중복으로 실행하면 이미 데이터가 db에 들어갔기 때문에 “이미 존재하는 회원입니다.”가 뜨면서 오류가 발생한다.
2-2) @Transactional이 있는 경우
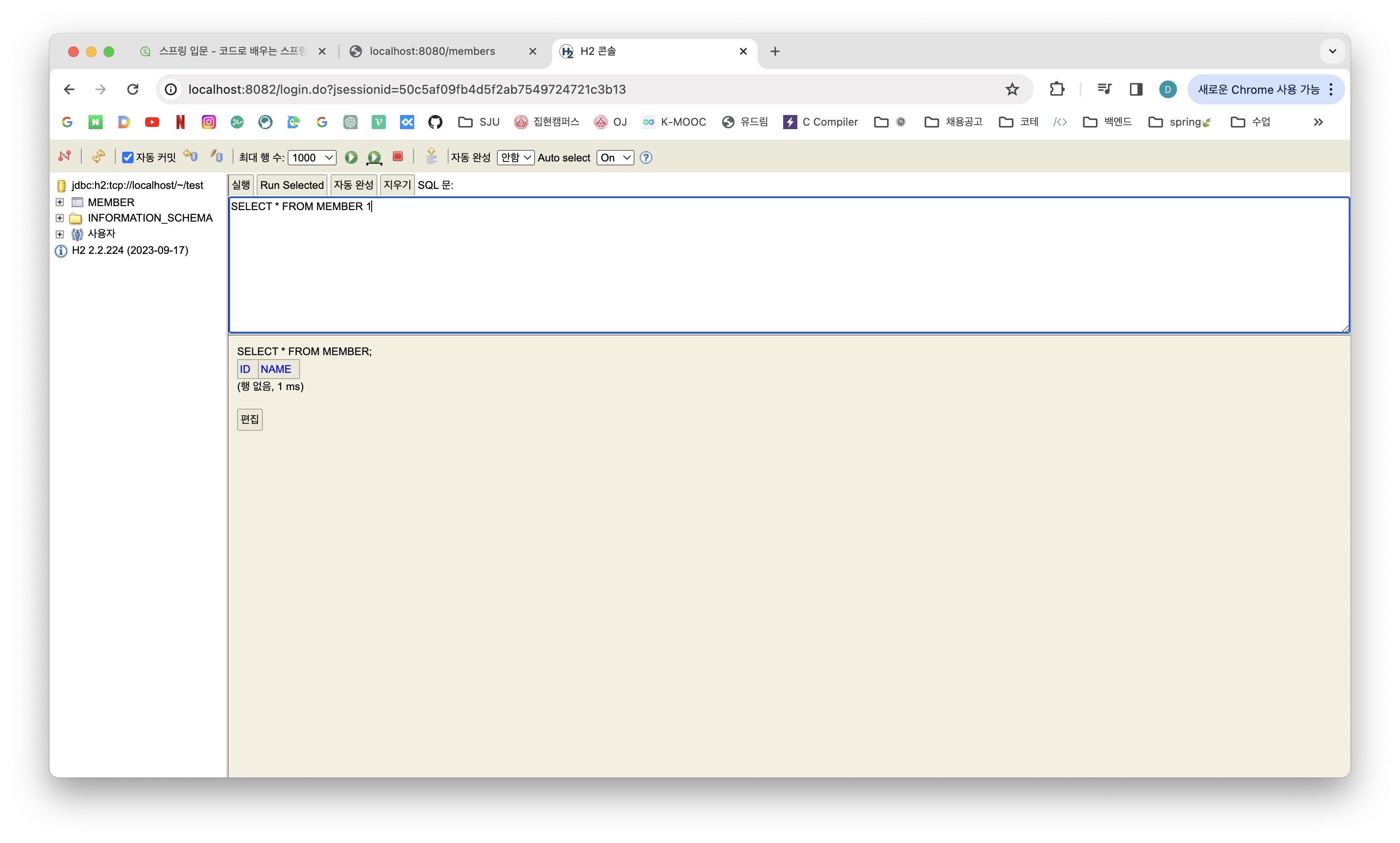
- 단위테스트 vs 통합테스트
단위테스트: 순수 자바 코드로 최소한의 단위로 테스트를 실행하는 것. 짧은 시간이 걸린다.
통합테스트: 스프링 컨테이너, DB 등을 연동하는 것. 단위 테스트보다 오랜 시간이 걸린다.
—> 단위 테스트가 좋은 테스트일 확률이 높다.
스프링 JDBC Template
순수 JDBC가 아닌 JDBC Template을 이용해 코드를 짜보자.
JDBC Template은 실무에서도 많이 사용하는 템플릿이다.
환경설정은 순수 Jdbc와 동일하게 하면 된다.
스프링 JdbcTemplate과 MyBatis 같은 라이브러리는 JDBC API에서 본 반복 코드를 대부분 제거해준다. 하지만 SQL은 직접 작성해야 한다.
JdbcTemplateMemberRepository.java
...
public class JdbcTemplateMemberRepository implements MemberRepository {
private final JdbcTemplate jdbcTemplate;
@Autowired // 생성자가 하나면 @Autowired를 생략해도 된다.
public JdbcTemplateMemberRepository(DataSource dataSource) {
jdbcTemplate = new JdbcTemplate(dataSource);
}
@Override
public Member save(Member member) {
...
}
@Override
public Optional<Member> findById(Long id) {
List<Member> result = jdbcTemplate.query("select * from member where id = ?", memberRowMapper(), id);
return result.stream().findAny();
} // 순수 JDBC로 구현했던 굉장히 긴 코드를 2줄로 짤 수 있다.
// id로 JDBC 템플릿에서 쿼리를 날려 그 결과를 RowMapper를 통해서 매핑을 하고 리스트로 받아서 옵션으로 바꿔서 반환
@Override
public Optional<Member> findByName(String name) {
...
}
@Override
public List<Member> findAll() {
...
}
private RowMapper<Member> memberRowMapper() { // 매핑해주기
return (rs, rowNum) -> {
Member member = new Member();
member.setId(rs.getLong("id"));
member.setName(rs.getString("name"));
return member;
};
}
}그리고 repository에 연결해주자
SpringConfig.java
...
@Bean
public MemberRepository memberRepository() {
// return new MemoryMemberRepository();
// return new JdbcMemberRepository(dataSource);
return new JdbcTemplateMemberRepository(dataSource);
}
...MemberServiceIntegrationTest를 실행시켜보면 잘 실행되는 것을 확인할 수 있다.

JPA
JDBC에서 JDBC Template로 바꿔 코드를 작성하니 코드가 훨씬 간결해졌다.
하지만 여전히 SQL은 개발자가 작성해줘야한다.
JPA를 사용하면 SQL query도 JPA가 자동으로 처리해준다.
객체를 JPA에 집어넣으면 JPA가 중간에서 DB에 SQL을 날리고 DB를 통해서 가져온다.
JPA를 사용하면
SQL, 데이터 중심에서 객체 중심의 설계를 할 수 있게 되어 개발 생산성을 높일 수 있다.
build.gradle
다음 코드를 추가해주고 gradle을 refresh해준다.
dependencies {
...
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
...
}application.properties
다음 코드를 추가.
...
spring.jpa.show-sql=true // JPA가 날리는 SQL을 볼 수 있다.
spring.jpa.hibernate.ddl-auto=none
//JPA를 사용하면 객체를 테이블로 만든다.
//우리는 테이블이 만들어져있기 때문에 테이블 생성 기능은 끄고 시작한다.JPA는 인터페이스만 제공이 되는 것이고 구현체로 Hibernate, Eclipse Link등 구현 기술들이 있는 것이다.
보통 JPA 인터페이스에 Hibernate를 거의 사용한다.
즉 JPA는 자바진영의 표준인터페이스이고 구현은 여러 업체들이 하는 것이다.
JPA는 ORM이라는 기술이다.
※ ORM(Object Relational Mapping)
객체와 관계형 데이터베이스 테이블을 매핑한다는 뜻
스프링 데이터 JPA
스프링 부트와 JPA만 사용해도 개발 생산성이 정말 많이 증가하고, 개발해야할 코드도 확연히 줄어든다.
여기에 스프링 데이터 JPA를 사용하면 리포지토리에 구현 클래스 없이 인터페이스 만으로 개발을 완료할 수 있다.
그리고 반복 개발해온 기본 CRUD 기능도 스프링 데이터 JPA가 모두 제공한다.
스프링 데이터 JPA는 인터페이스를 통한 기본적인 CRUD findByName() , findByEmail() 처럼 메서드 이름 만으로 조회 기능 제공 페이징 기능 자동 제공한다.
스프링 데이터 JPA를 통해 개발자는 핵심 비즈니스 로직을 개발하는데, 집중할 수 있다.
실무에서 관계형 데이터베이스를 사용한다면 스프링 데이터 JPA는 이제 선택이 아니라 필수.
주의: 스프링 데이터 JPA는 JPA를 편리하게 사용하도록 도와주는 기술이므로 JPA를 먼저 학습한 후에 스프링 데이터 JPA를 학습해야 한다.
