하루 개요
프로그래머스 문제 1개 풀기
Nodejs 구현 공부 (챕터 1-24 ~ 27)
운영체제 공부 챕터 4
네트워크 공부 및 정리
배열, map, set 차이점
프로그래머스 신고결과 받기 javaScript 풀이
https://school.programmers.co.kr/learn/courses/30/lessons/92334
내 풀이
const solution = (id_list, report, k) => {
const reportArray = [...new Set(report)].map((elem) => elem.split(" "));
const reportedUsers = reportArray.map((elem) => elem[1]);
const reportedUserCount = id_list.map((user) => {
return reportedUsers.reduce((acc, cur) => {
if (cur === user) {
return acc + 1;
}
return acc;
}, 0);
}); // 신고당한 횟수 [ 1, 2, 0, 2 ], k = 2 이상 신고 받은 사람 이용정지 당함
const bannedList = id_list.filter((_elem, elemIndex) => {
return reportedUserCount[elemIndex] >= k;
}); // bannedList: [ 'frodo', 'neo' ]
let answer = new Array(id_list.length).fill(0);
reportArray.map((elem) => {
let [reportingUser, reportedUser] = [elem[0], elem[1]];
// 구조분해할당 ~ [ 'muzi', 'frodo' ]
if (bannedList.includes(reportedUser)) {
const index = id_list.indexOf(reportingUser);
answer[index]++;
}
});
return answer;
};
console.log(
solution(
["muzi", "frodo", "apeach", "neo"],
["muzi frodo", "apeach frodo", "frodo neo", "muzi neo", "apeach muzi"],
2
)
);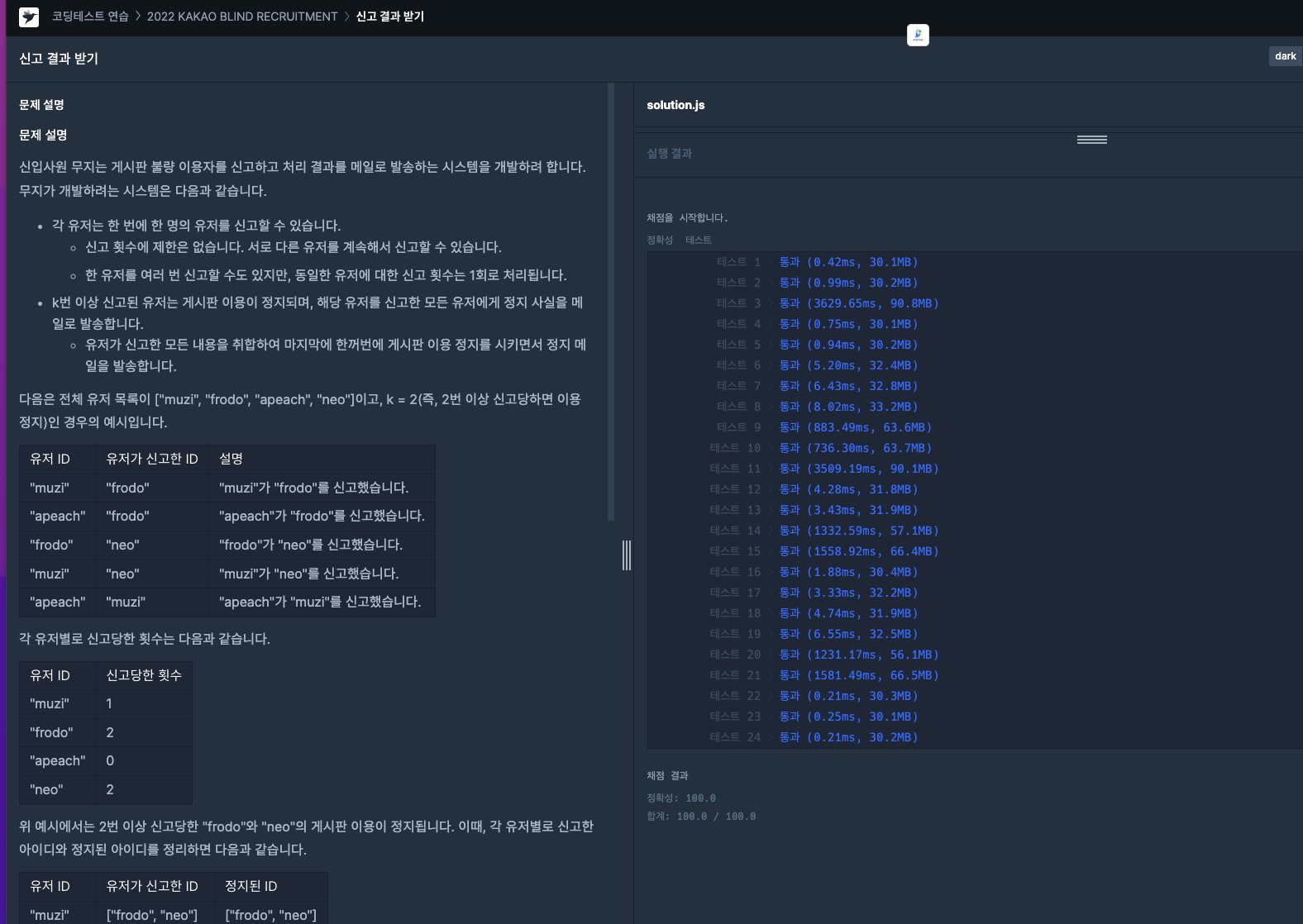
테스트 3 시간 3629ms 실화임? 아무튼..
리뷰: 문제 흐름대로 그대로 구현한 1차원적 발상에 원론적으로 보면 접근방식부터가 이상하다 느껴짐. 뭔가~ 아쉽다.
해시나 객체 써서 풀면 더 빠르고 예쁘게 풀릴 것 같다.
나중에 저녁먹고 리팩토링 함!
const reportArray = [...new Set(report)].map((elem) => elem.split(" "));
/* 출력
reportArray [
[ 'muzi', 'frodo' ],
[ 'apeach', 'frodo' ],
[ 'frodo', 'neo' ],
[ 'muzi', 'neo' ],
[ 'apeach', 'muzi' ]
]
*/set 사용해서 중복 항목 삭제하고 spread 연산자로 다시 배열로 묶어줌
나는 Set 요거 걍 중복 없애주는 객체..로만 쓰는 듯
이따가 제대로 파봐야지!
const reportedUserCount = id_list.map((user) => {
return reportedUsers.reduce((acc, cur) => {
if (cur === user) {
return acc + 1;
}
return acc;
}, 0);
}); 여기 시간복잡도 O(n^2)....
프로그래머스는 백준보다 시간 제한이 널널해서 다행이라 해야하나... 여기도 리팩토링 해야할듯
const bannedList = id_list.filter((_elem, elemIndex) => {
return reportedUserCount[elemIndex] >= k;
}); // bannedList: [ 'frodo', 'neo' ]그리고 변수 bannedList를 구할 때 filter 함수를... 저런 식으로 사용해도 되는건가?
MDN문서 보면 filter() 메서드는 주어진 함수의 테스트를 통과하는 모든 요소를 모아 새로운 배열로 반환합니다. 라고 한다.
난 해당 인자의 index만 가져와서 다른 배열의 요소와 비교해서 리턴시킴... 이게 맞나.. ㅎ 맞겠지?
사실상 객체 key-value대신 배열 인덱스로 가라친 것 같아서 찝찝하다.
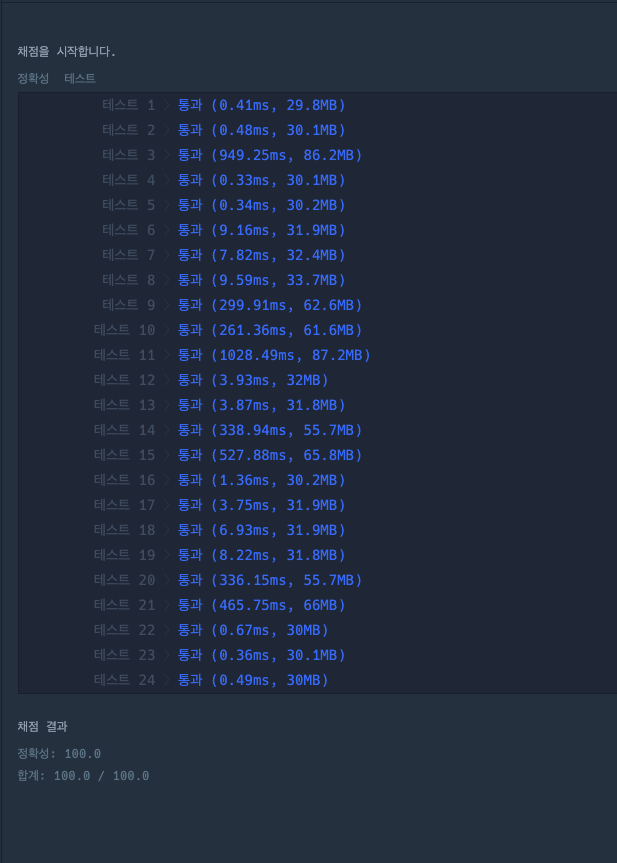
객체로 구현
- 변수명 구림, 시간복잡도 O(n^2)인데 훨씬 빠르다.
find 부분을 미리 계산해주면 시간복잡도가 더 떨어질 것이다.
=> 키워드:memoization쉽게 말해서 미리 계산시켜놓고 메모리에 저장해서 반복연산을 덜 시킨다
class Person {
constructor(name) {
this.name = name;
this.reportCount = 0;
this.emailCount = 0;
this.isBanned = false;
}
}
const solution = (idList, report, k) => {
const people = idList.map((user) => new Person(user));
const uniqueReportArray = [...new Set(report)];
const reportArray = uniqueReportArray.map((userReport) =>
userReport.split(" ")
);
const reportedPeople = reportArray.reduce((acc, cur) => {
const criminalName = cur[1];
// shallow copy
const criminal = acc.find((user) => user.name === criminalName);
criminal.reportCount += 1;
if (criminal.reportCount >= k) {
criminal.isBanned = true;
}
return acc;
}, people);
const emailPeople = reportArray.reduce((acc, cur) => {
const [reporterName, criminalName] = cur;
const criminal = acc.find((user) => user.name === criminalName);
const reporter = acc.find((user) => user.name === reporterName);
if (criminal.reportCount >= k) {
reporter.emailCount += 1;
}
return acc;
}, reportedPeople);
return emailPeople.map((user) => user.emailCount);
};- 입출력 예제
console.log(
solution(
["muzi", "frodo", "apeach", "neo"],
[
"muzi frodo",
"apeach frodo",
"frodo neo",
"muzi neo",
"apeach muzi",
"apeach muzi",
],
2
)
);코드 설명
const people = idList.map((user) => new Person(user));idList에 있는 유저들을 각자 객체로 선언해준다.
- 출력
[
Person { name: 'muzi', reportCount: 0, emailCount: 0 },
Person { name: 'frodo', reportCount: 0, emailCount: 0 },
Person { name: 'apeach', reportCount: 0, emailCount: 0 },
Person { name: 'neo', reportCount: 0, emailCount: 0 }
] // shallow copy
const criminal = acc.find((user) => user.name === criminalName);deep copy면 findIndex()함수로 써서 찾아야 하는데, 직접 돌려보니find() 함수가 shallow copy라서 이런 식으로 쓸 수 있었다.
(얕은 복사, 깊은 복사 두 용어가 자꾸 헷갈렸는데, 깊은 복사는 직접 메모리를 할당해가면서 복사를 하는 것이고, 얕은 복사는 가라친다로 이해하면 다음부터는 헷갈리지 않을 것이다.)
Nodejs 구현 공부
키워드 위주로 정리..!
- 1-24장: 글 목록 출력하기
이번 챕터 목표:
- data 디렉터리에서 파일목록 읽어오기
- 읽어온 파일 목록을 표시하는 HTML 코드를 list 변수에 저장하기
- 저장한 변수를 이용해 웹페이지에 표시하기
fs.readdir('./data', function(error, filelist) {
// 파일 목록을 가져온 다음에 실행할 코드
})readdir() 기능은 data 디렉터리에 있는 파일 목록을 가져온 다음 function 실행
let http = require("http");
let fs = require("fs");
let url = require("url");
let app = http.createServer(function (request, response) {
let _url = request.url;
let queryData = url.parse(_url, true).query;
let pathname = url.parse(_url, true).pathname;
if (pathname === "/") {
if (queryData.id === undefined) {
fs.readdir("./data", function (error, filelist) {
let title = "Welcome";
let description = "Hello, Node.js";
let list = "<ul>";
let i = 0;
for (let i = 0; i < filelist.length; i++) {
list =
list + `<li><a href="/?id=${filelist[i]}">${filelist[i]}</a></li>`;
}
list = list + "</ul>";
let template = `
<!doctype html>
<html>
<head>
<title>WEB1 - ${title}</title>
<meta charset="utf-8">
</head>
<body>
<h1><a href="/">WEB</a></h1>
${list}
<h2>${title}</h2>
<p>${description}</p>
</body>
</html>
`;
response.writeHead(200);
response.end(template);
});
} else {
fs.readdir("./data", function (error, filelist) {
let list = "<ul>";
for (let i = 0; i < filelist.length; i++) {
list =
list + `<li><a href="/?id=${filelist[i]}">${filelist[i]}</a></li>`;
}
list = list + "</ul>";
fs.readFile(
`data/${queryData.id}`,
"utf8",
function (err, description) {
let title = queryData.id;
let template = `
<!doctype html>
<html>
<head>
<title>WEB1 - ${title}</title>
<meta charset="utf-8">
</head>
<body>
<h1><a href="/">WEB</a></h1>
${list}
<h2>${title}</h2>
<p>${description}</p>
</body>
</html>
`;
response.writeHead(200);
response.end(template);
}
);
});
}
} else {
response.writeHead(404);
response.end("Not found");
}
});
app.listen(3000);
<ul>
<li><a href="/?id=HTML">HTML</a></li>
<li><a href="/?id=CSS">CSS</a></li>
<li><a href="/?id=JavaScript">JavaScript</a></li>
</ul>코드를
for (let i = 0; i < filelist.length; i++) {
list =
list +
`<li><a href = "/?id = ${filelist[i]}" > ${filelist[i]} </a></li>`;
}
list = list + "</ul>";로 바꾼다
- 함수를 이용해 중복된 코드를 모두 제거한 main.js
var http = require("http");
var fs = require("fs");
var url = require("url");
function templateHTML(title, list, body) {
return `
<!doctype html>
<html>
<head>
<title>WEB1 - ${title}</title>
<meta charset="utf-8">
</head>
<body>
<h1><a href="/">WEB</a></h1>
${list}
${body}
</body>
</html>
`;
}
function templateList(filelist) {
var list = "<ul>";
var i = 0;
while (i < filelist.length) {
list = list + `<li><a href="/?id=${filelist[i]}">${filelist[i]}</a></li>`;
i = i + 1;
}
list = list + "</ul>";
return list;
}
var app = http.createServer(function (request, response) {
var _url = request.url;
var queryData = url.parse(_url, true).query;
var pathname = url.parse(_url, true).pathname;
if (pathname === "/") {
if (queryData.id === undefined) {
fs.readdir("./data", function (error, filelist) {
var title = "Welcome";
var description = "Hello, Node.js";
var list = templateList(filelist);
var template = templateHTML(
title,
list,
`<h2>${title}</h2><p>${description}</p>`
);
response.writeHead(200);
response.end(template);
});
} else {
fs.readdir("./data", function (error, filelist) {
fs.readFile(
`data/${queryData.id}`,
"utf8",
function (err, description) {
var title = queryData.id;
var list = templateList(filelist);
var template = templateHTML(
title,
list,
`<h2>${title}</h2><p>${description}</p>`
);
response.writeHead(200);
response.end(template);
}
);
});
}
} else {
response.writeHead(404);
response.end("Not found");
}
});
app.listen(3000);
PM2 설치
node js로 만든 프로세스를 관리해주는 프로그램, 프로그램을 감시하고 있다가 의도치 않게 꺼지거나 소스가 변경될 때 자동으로 재시동함으로써 서비스를 안정적으로 유지하게 도움을 준다.
npm install pm2 -g // 설치
pm2 start main.js // 실행
name: 우리가 실행한 프로그램 이름
status: online -> 실행 중
나머지: 실행 시간을 비롯해 CPU나 메모리 등 시스템 자원을 얼마나 소비하고 있는지 보여줌
- 프로세스 감시
pm2 monit
- 소스 파일 감시
PM2가 소스 파일을 감시해서 이에 대응하는 기능인데 지금까지 소스를 고치고 프로그램을 재시동했던 방식을 자동화할 수 있어서 매우 편리하다.
pm start main.js --watch- 문제 확인
문제를 확인하는 데 도움을 주는 명령
pm2 log
HTML - form
폼에 정보 넣고 서밋하니까 url에 이렇게 뜸

<form action="http://localhols:3000/process_create">
<p><input type="text" name="title" /></p>
<p>
<textarea name="description"></textarea>
</p>
<p><input type="submit" /></p>
</form>? 기호를 기준으로 앞은 데이터를 전달한 웹 서버 주소, 뒤는 함께 전달한 쿼리 스트링이다.
사용자가 입력한 데이터를 url에 포함해서 주소 표시줄에 그대로 노출하는 방법은 좋은 방법이 아니다.
반대로 웹 서버에 있는 데이터를 가져올 때(get)는 주소 표시줄에 쿼리스트링이 노출되도 괜찮다.
단, 서버로 데이터를 전송할 때는 주소 표시줄에 입력값이 노출되게 하면 안된다.
데이터 자체가 민감한 내용일 수도 있고, 주소가 보이게 되면 의도하지 않은 데이터 조작이 이뤄질 수 있다.
이런 경우에는 눈에 보이지 않는 방식으로 전달해야 한다. post로 지정한다.
<form action="http://localhols:3000/process_create" method = "post">
<p><input type="text" name="title" /></p>
<p>
<textarea name="description"></textarea>
</p>
<p><input type="submit" /></p>
</form>post 방식을 사용하면 데이터가 주소 표시줄에 표시되지 않아서 안전하게 전송할 수 있을뿐만 아니라 아주 큰 데이터도 보낼 수 있습니다.
운영체제 챕터 4
- 시스템 내 전체 프로세스의 수를 조절하는 것으로, 장기 스케줄링 또는 작업 스케줄링이라 불리는 스케줄링 수준은 무엇인가?
고수준 스케줄링 p. 197
- 어떤 프로세스에 CPU를 할당하고 어떤 프로세스를 대기 상태로 보낼지 등을 결정하는 스케줄링 수준은 무엇인가?
저수준 스케줄링 p.198
- 어떤 프로세스가 CPU를 할당받아 실행 중이더라도 운영체제가 CPU를 강제로 빼앗을 수 있는 스케줄링은 무엇인가?
선점형 스케줄링 p.201
- 현재 입출력을 진행하는 프로세스로, 사용자와 상호작용이 가능하여 상호작용 프로세스라고도 불리는 것은 무엇인가?
전면 프로세스 p.206
- 준비 큐에 도착한 순서대로 CPU를 할당하는 비선점형 스케줄링 알고리즘은 무엇인가?
FCFS 스케줄링(First Come First Served) p.214
- 준비 큐에 있는 프로세스 중 실행시간이 가장 짧은 작업부터 CPU를 할당하는 비선점형 스케줄링 알고리즘은 무엇인가?
SJF 스케줄링(Shortest Job First) p.214
- SJF 스케줄링 알고리즘의 단점으로 크기가 큰 작업이 계속 뒤로 밀리는 현상을 무엇이라 하는가?
아사 현상 또는 무한 봉쇄 현상(Starvation, infinite blocking) p.216~218
- 아사 현상을 해결하는 방법을 성명하시오.
에이징 p.218
- 서비스를 받기 위해 대기한 시간과 CPU 사용시간을 고려하여 우선순위를 정하는 스케줄링 알고리즘은 무엇인가?
HRN 스케줄링(Highest Response Ratio Next) p.219
- 프로세스가 할당받은 시간(타임 슬라이스)동안 작업하다가 작업을 완료하지 못하면 준비 큐의 맨 뒤로 가서 당름 자기차례가 올때까지 기다리는 선점형 스케줄링 알고리즘 중 가장 단순한 것은 무엇인가?
라운드 로빈 스케줄링 p.220
- 타임 슬라이스의 크기와 문맥교환의 관계를 설명하시오.
타임슬라이스가 작으면 문맥교환이 많아짐, 타임슬라이스가 크면 문맥교환이 적어짐 p.223
- 기본적으로 라운드 로빈 방식을 사용하지만, CPU를 할당받을 프로세스를 선택할 때 남아있는 작업 시간이 가장 적은 것을 선택하는 스케줄링 알고리즘은 무엇인가?
SRT 스케줄링 p.224
- 우선순위에 따라 준비 큐를 여러 개 사용하며 고정형 우선순위를 적용하는 스케줄링 알고리즘은 무엇인가?
다단계 큐 스케줄링 p.226
- 우선순위에 따라 준비 큐를 여러개 사용하며 프로세스가 CPU를 사용한 후 우선순위가 낮아지는 특성을 가진 스케줄링 알고리즘은 무엇인가?
다단계 피드백 큐 스케줄링 p.228
- 다단계 피드백 큐 스케줄링에서 마지막 큐에 있는 프로세스(우선순위가 가장 낮은 프로세스)의 타임 슬라이스 크기는 얼마인가?
거의 무한대 p.229
- 다단계 피드백 큐 스케줄링에서 우선순위가 낮아질수록 타임 슬라이스의 크기는 어떻게 변하는가?
해당 큐의 타임 슬라이스가 커진다. p.228
- 다단계 피드백 큐 스케줄링에서 마지막 큐(우선순위가 가장 낮은 큐)는 어떤 스케줄링 알고리즘처럼 동작하는가?
FCFS 스케줄링 p.228
[심화 문제]
1. 스케줄링의 단계와 그 특징을 설명하시오.
p.199
2. 스케줄링의 목적을 설명하시오.
p.200
3. 선점형 스케줄링과 비선점형 스케줄링을 비교하여 설명하시오.
p.201, 202
4. 스케줄링 알고리즘의 선택 기준에 대해 설명하시오.
p.203, 207 -> p.212
5. FCFS, SJF, HRN 스케줄링의 특징을 설명하시오.
p.236
6. 라운드 로빈, SRT, 다단계 큐, 다단계 피드백 큐 스케줄링의 특징을 설명하시오.
p.236
7. 아사 현상과 에이징에 대해 설명하시오.
p.218
8. 타임 슬라이스 크기를 정하는 것과 시스템 효율성에 대해 설명하시오
p.223
하루 마무리
-
오늘 해낸 것
프로그래머스 문제 1개 풀기
Nodejs 구현 공부 (챕터 1-24 ~ 30)
운영체제 공부 챕터 4 -
오늘 못한 것
네트워크 공부 및 정리
배열, map, set 차이점
- 하루 반성 및 피드백
반성:
1. 구현 관련 시간이 너무 오래 걸린다.
2. 순공부 측정하기
피드백: 어쩔 수 없다.
1. 지금 하는 구현 범위는 그렇게 중요한 부분이 아니니 사소한 것에 연연하지 않는다.
2. 타이머를 잰다
- 내일 할 것
네트워크 공부 및 정리
배열, map, set 차이점 찾아보기
Nodejs 구현 공부 (챕터 1-30~ 33장)
운영체제 챕터 5
SQL 기초 문제 리트코드나 프로그래머스에서 풀기
다음달 내에 끝내고 싶은 목표!!
운영체제 복습
네트워크 3강씩 공부
SQL -> 리트코드나 프로그래머스에서 매일 꾸준히 풀기
이론으로 배우는 데이터베이스 책 완독하기
express, nest js (node js) 구현
자료구조와 알고리즘 공부하기
