하루 개요
Nodejs 구현 34~38장 (저자 CRUD, 코드 정리)
운영체제 챕터 5
SQL 기초 문제 리트코드나 프로그래머스에서 풀기
알고리즘 문제 리트코드
-> https://leetcode.com/problems/longest-subsequence-with-limited-sum/
-> https://leetcode.com/problems/removing-stars-from-a-string/
풀어보고 싶음
자료구조.. 공부해야하는데 시간 남으면 보기 (망함)
자꾸 운영체제 복습 밀려서 아침에 바로 운영체제함
SQL 관계형 데이터 베이스 공부도 해야하는데... 너무 느리다 ㅠ.ㅠ 하 ...
운영체제 챕터 5: 프로세스 동기화 (IPC, Inter Process Communication)
널널한 개발자님 https://youtu.be/eELCTRdSj7o, 쉽게 배우는 운영체제 책 참고, 다른 분이 이것 저것 알려주신 키워드 위주로 추가로 찾아보면서 학습용으로 쓴 글입니다.
흐름이 엉킨 것 같은데.. 참고한 링크, 원문 위주로 보시고 제 글은 안보시는게 도움 될 듯
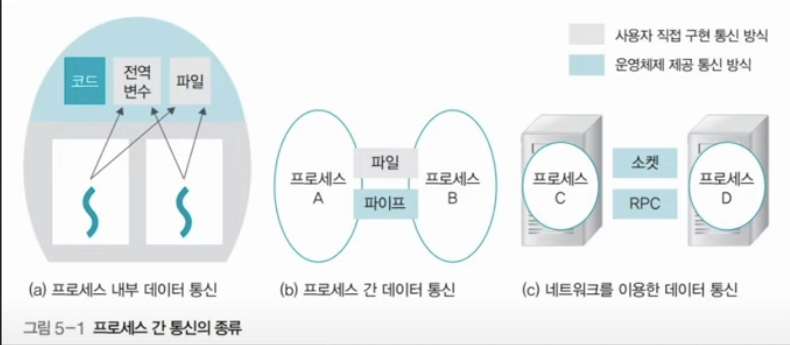
(a) 프로세스 내부 데이터 통신: 전역변수, 파일 이용
(b) 프로세스 간 데이터 통신: 공용 파일 또는 운영체제가 제공하는 파이프 사용하여 통신
(c) 네트워크를 이용한 데이터 통신: 소켓, 원격프로시저 호출 (Remote Procedure Call, RPC)
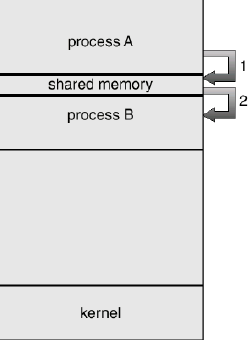
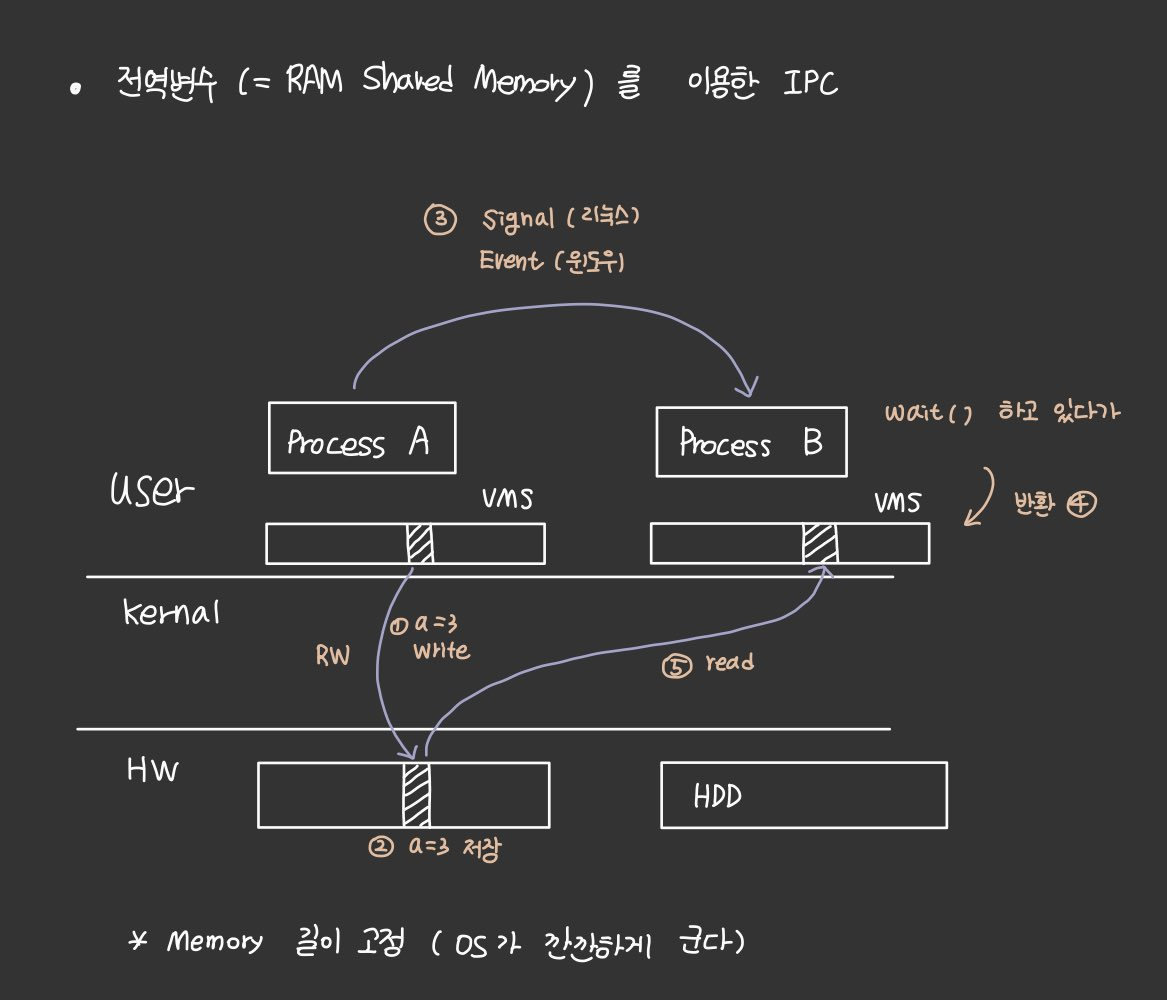
전역변수 (= 공유메모리, RAM shared memory)를 이용한 IPC
커널 영역에 메모리 공간을 만들고, 해당 공간을 변수처럼 쓰는 방식
message queue처럼 FIFO 방식이 아니라, 해당 메모리 주소를 마치 변수처럼 접근하는 방식
공유 메모리의 key를 가지고, 여러 프로세스가 접근 가능
-
서로다른 프로세스가 공통된 메모리 공간을 사용할 수 있도록 운영체제에서 제공되는 서비스
-
System V계열에서는 공유메모리 기법을 제공하며, BSD계열에서는 메모리맵(mmap) 기법을 제공하나 동작방식은 유사 (아니 유닉스가 system V, BSD 계열로 찢어졌다.는건 알겠는데 또 더 찾아보기 귀찮아서 대충 키워드만..)
-
메시지 큐(블로그 글 뒤에 나옴)와는 달리 트랜젝션의 개념이 없음(동시 접근에 따른 데이터 깨짐이 발생)
-
동시접근 문제를 해결하기 위해 별도의 기법이 필요
(예: 세마포어(Semaphore) ~ 공유된 자원 데이터에 대한 최대 허용치 값을 두어 프로세스나 스레드의 동시 접근을 막는 것, 상호배제 원리를 보장하는 알고리즘)추가 ... Concurrency Hazards MS문서
동시성 (Concurrency) 이 존재하는 프로그래밍, 쉽게 말해 스레드 혹은 프로세스 등으로 인해 동시에 실행되는 로직을 작성할 시 고려해야 하는 각종 위험 (Hazard) 들과 그에 대한 해결 방안이 적혀 있다.
상당히 오래된 MSDN 매거진임에도, 동시성 프로그래밍을 처음 시작하는 분들이 유발할 수 있는 각종 위험들과 이에 대한 대응책이 예제와 함께 상세하게 적혀 있어서 참고해서 읽어볼만함
사용 절차:
1) 프로세스 A : 공유메모리 생성
2) 프로세스 A : 생성된 공유메모리 영역을 자신의 메모리 영역에 첨부(Attach)
3) 프로세스 A : 첨부된 영역에 접근(Read/Write)
4) 프로세스 B : 생성된 공유메모리 영역을 자신의 메모리 영역에 첨부(Attach)
5) 프로세스 B : 첨부된 영역에 접근(Read/Write)
6) 프로세스 A & B : 첨부된 영역을 분리(Detach)
Shared Memory 방식의 경우 프로세스별 동기화를 책임지지 않기 때문에 워터마크로 각 프로세스가 접근할 수 있는 영역을 나누는 것이 아니면 추가적인 동기화에 대한 구현이 요구된다.
Shared Memory 방식의 경우 하나의 물리적 페이지를 다수의 프로세스 가상 메모리 영역에 할당하는 방식으로 이루어진다.
물리적 페이지를 매핑하기 위해서 shmem이나 CreateFileMapping 등을 이용하여 Shared Memory 방식을 이용할 시 키 값을 요구한다.
Shared Memory 방식은 mmap 혹은 CreateFileMapping을 이용, File을 직접 가상 메모리에 매핑하는 방식으로도 이용이 가능하다.
허나 이럴 경우, 파일의 내용과 Memory 상에 Mapping되어진 내용이 다를 수 있기 때문에 msync 혹은 FlushFileMapping을 통한 파일의 내용과 메모리에 매핑된 내용과의 추가적인 동기화가 요구된다.
Shared Memory : (MSDN) https://docs.microsoft.com/en-us/windows/win32/api/winbase/nf-winbase-createfilemappinga
리눅스의 공유 메모리에 관련한 문서:
https://man7.org/linux/man-pages/man7/shm_overview.7.html
Accessing shared memory objects via the filesystem
On Linux, shared memory objects are created in a (tmpfs(5))
virtual filesystem, normally mounted under /dev/shm. Since
kernel 2.6.19, Linux supports the use of access control lists
(ACLs) to control the permissions of objects in the virtual
filesystem.
-
추가로 더 찾아봄
공유 메모리가 핵심같음메모리 매핑, 파일 매핑 (File Mapping Object) 참고자료
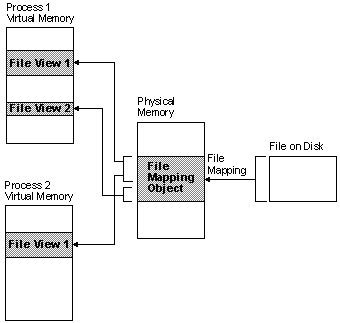
CreateFile
디스크에 존재하는 파일(커널 객체)에 대한 핸들 hFile 을 얻는다.CreateFileMapping
hFile 을 전달 받아 파일을 물리 메모리에 매핑 시키고 파일 매핑 오브젝트(File Mapping Object) 핸들 hMappingObject 를 얻는다MapViewOfFile
CreateFileMapping이 물리 메모리에 모든 영역을 올리는 것이라면, MapViewOfFile은 해당 물리 메모리를 프로세스의 가상 메모리에 매칭시키는 역할
-> 그래서 물리 메모리의 일부분만 가상 메모리로 가져올 수 있는 것
< Memory Map File>
파일 -> 물리메모리 매핑 오브젝트 -> 가상메모리 매핑 뷰
유저모드는 매핑뷰를 얻어 사용.
원문 출처,
파일 매핑 관련 ms 문서
Memory Mapped File 은 프로세스간 메모리를 공유하는 유일한 방법이다.
프로세스간 통신은 여러가지 방법이 있지만 결국 내부적으로는 모두 Memory Mapped File 을 활용한다.
윈도우즈는 물리적인 메모리(RAM)가 부족할 경우 하드 디스크의 페이징 파일(Paging File)을 메모리 대신 사용한다.
마치 페이징 파일이 물리적인 메모리의 일부인 것처럼 프로세스의 주소 공간에 맵하여 사용하며 필요할 경우 RAM으로 읽어오므로 응용 프로그램의 입장에서 볼 때 페이징 파일은 속도가 좀 느릴 뿐 RAM과 전혀 다를 것이 없다.
운영체제가 하드 디스크의 페이징 파일을 RAM 대용으로 사용하는 것이 가능하다면 일반 파일도 RAM 대용으로 사용하여 주소 공간에 Mapping 할 수 있을 것이다.
일반 파일도 정보를 저장하고 읽고 쓸 수 있으므로 이론적으로 전혀 문제가 없다.
메모리 맵 파일(Memory Mapped File)은 이런 이론에 기반하여 하드 디스크에 존재하는 파일의 내용을 프로세스의 주소 공간에 연결(Map)하는 기법이다.
요약하자면 파일을 마치 메모리인 것처럼 사용하는 기법이라 하겠다.
이처럼 가상 주소 공간에 파일을 맵한 후 그 포인터를 사용하면 파일의 내용을 마치 메모리 다루듯이 똑같이 사용할 수 있다.
파일을 열고 닫고 파일 포인터를 옮기고 버퍼를 유지하는 복잡한 처리를 할 필요없이 마치 메모리에 있는 데이터를 읽고 쓰듯 *ptr = data; 등과 같이 간편하게 파일 조작을 할 수 있는 것이다.
파일을 메모리처럼 사용해도 그 뒷처리는 운영체제가 철저하게 책임진다.
포인터로 파일을 액세스하면 RAM으로 스왑할 것이고 오랫동안 사용하지 않으면 다시 파일에 기록하며 파일 맵핑을 닫을 때 대기중인 모든 출력이 파일에 완전히 기록된다.
메모리 맵 파일은 편리함뿐만 아니라 아주 여러 가지 용도로 가지고 있다.
운영체제가 실행 파일을 읽어오고 실행하는 내부적인 방법도 바로 메모리 맵 파일이다.
실행 파일을 메모리로 읽어올 필요없이 디스크의 이미지를 곧바로 프로세스의 주소 공간에 맵한 후 바로 실행할 수 있다.
물론 그 배경에서 시스템은 실행 파일 이미지에서 당장 필요한 부분을 물리적인 RAM으로 읽어보고 더 이상 필요하지 않은 부분을 RAM에서 제거하는 복잡한 처리를 할 것이다.
운영체제가 이런 식으로 파일 맵핑을 통해 실행 파일을 로드하기 때문에 로딩 속도가 대단히 빠르며 가상 메모리를 절약할 수 있다.
실행 파일 이미지의 대부분은 읽기 전용이므로 파일 자체를 주소 공간에 맵해서 사용해도 별 상관이 없는 것이다.
100M 넘는 큰 파일을 실행해도 순식간에 실행되는 이유가 바로 파일을 곧바로 맵핑하기 때문이다.
단, 플로피나 CD-ROM, 이동식 디스크 같은 착탈식 미디어는 언제 제거될지 알 수 없으므로 가상 메모리로 전부 읽어들인 후에 실행한다.
또한 메모리 맵 파일은 Win32에서 프로세스간 메모리를 공유하는 유일하고 합법적인 방법이다.
두 개의 프로세스가 하나의 메모리 맵 파일을 동시에 액세스할 수 있기 때문에 메모리 맵 파일을 통해 데이터를 주고받을 수 있고 동시에 한 메모리 영역을 액세스할 수도 있다.
프로세스간 통신에 사용되는 여러 가지 기술들도 내부적으로 모두 메모리 맵 파일을 활용한다.
- 파일을 이용한 통신
참고자료 https://devraphy.tistory.com/176?category=988503
직렬화된 데이터 보낼 때 유리함,
파일을 열고(open) 쓰기(write) 또는 읽기(read) 연산을 한 후 파일을 닫는다.(close)
open() 함수는 fd(file descriptor)를 반환 => 해당 파일에 접근할 수 있는 일종의 열쇠
쓰기 읽기 연산 맨 앞에는 언제나 fd를 사용함
ex: write(fd, "Test", 5) fd(com.txt)파일에 Test라는 문자열을 쓰라는 의미, "Test" 문자열 크기가 5B이기 때문에 5 명시 (문자열 끝을 알리는 null포함해서 총 5B)
파일을 이용한 통신은 부모-자식 관계 프로세스 간에 많이 사용함.
운영체제가 프로세스 동기화를 제공하지 않고 프로세스들끼리 지 알아서 동기화함.
보통 부모 프로세스가 wait() 함수 써서 프로세스 작업 끝날 때까지 기다렸다가 작업을 시작함
#Include <unistd.h>
#Include <sys/types.h>
#Include <sys/stat.h>
#Include <fcntl.h>
Int main()
{
int fd;
fd = open("data.txt".O_RDONLY);
if(fd == -1)
{
printf("Error: can not open file\n");
/* 파일을 열지 못하므로 그냥 종료 */
return 1;
}
else
{
printf("File opened and now close_\n");
close(fd);
return();
}
}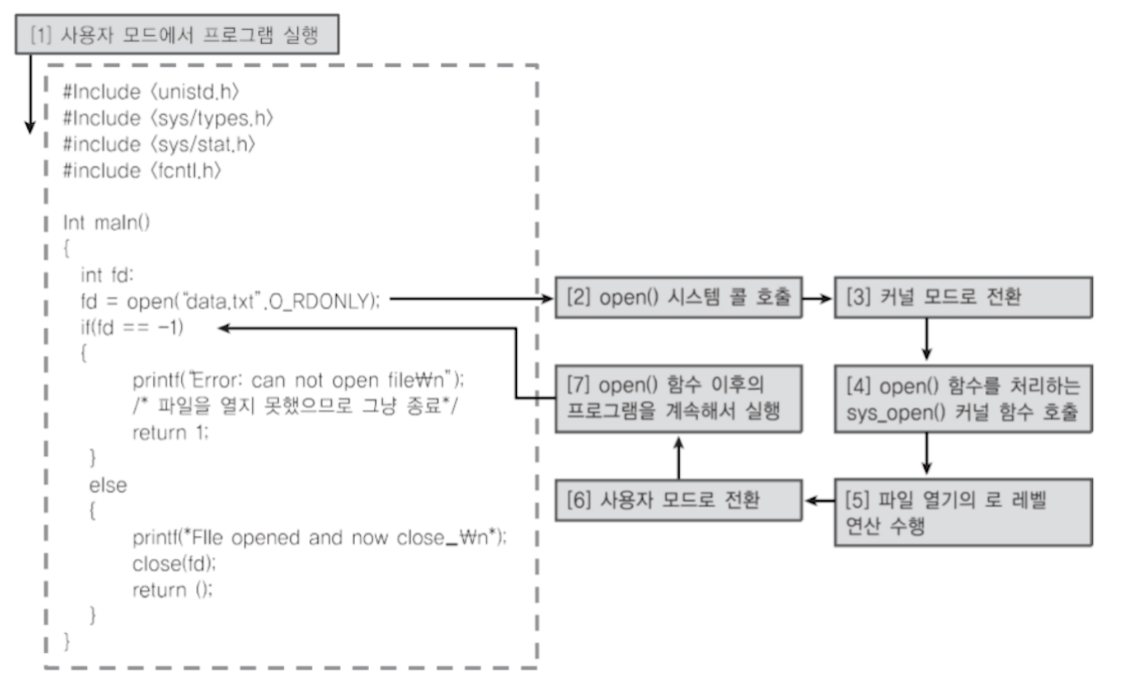

효율적인 자원(CPU) 사용을 위하여 파일을 불러오는 동안 해당 프로세스는 waiting 상태로 전환된다.
컨텍스트 스위칭이 발생하고, 다른 프로세스가 CPU를 할당 받아 사용한다.
파일을 불러오는 과정이 완료되고나면, 컨텍스트 스위칭을 위해 인터럽트가 발생한다. (프로세스 상태 = ready)
컨텍스트 스위칭이 완료되면, 프로세스가 재실행 된다. (프로세스 상태 = running)
소스코드가 다 읽히고 나면 프로세스는 종료된다. (프로세스 상태 = terminated)
출처: https://devraphy.tistory.com/176?category=988503 [개발자를 향하여:티스토리]
- 파이프를 이용한 통신
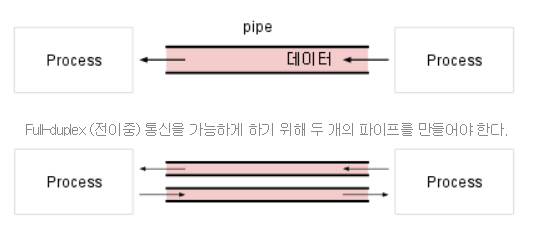
운영체제가 제공하는 동기화 통신 방식
파일 입출력이랑 비슷하게 open() 함수로 fd 기술자를 얻고 작업하고 close() 함수로 마무리
대기가 있는 통신(동기화 통신, 데이터 도착할 때 까지 대기 상태에 있음, 계속 왔나 확인 안해도 됨)
파이프에는 익명 파이프 와 명명된 파이프의 두 가지 유형이 있다.
익명 파이프는 명명된 파이프보다 오버헤드가 적지만 제한된 서비스를 제공한다.
개념적으로 파이프에는 두 개의 끝이 있다.
단방향 파이프를 사용하면 한쪽 끝의 프로세스가 파이프에 쓸 수 있으며 다른 쪽 끝의 프로세스가 파이프에서 읽을 수 있다.
양방향(또는 이중) 파이프를 사용하면 프로세스가 파이프의 끝에서 읽고 쓸 수 있다.
여기서 사용되는 파이프라는 용어는 파이프가 정보 통로로 사용됨을 의미한다.
Anonymouse pipe
일반적으로 파이프라고 하면 이름 없는 파이프(익명 파이프) 의미한다.
일반적으로 부모 프로세스와 자식 프로세스 간에 데이터를 전송하는 명명되지 않은 단방향 파이프다.
익명 파이프는 항상 로컬이므로 네트워크를 통한 통신에는 사용할 수 없다.
또는 양방향 통신을 사용하며, 핸들을 기반으로 통신한다.
따라서 핸들을 주고받을 수 있는 프로세스들 (흔히 부모-자식)처럼
특별한 관계가 있는 프로세스들끼리만이 통신할 수 있는 기법이다.
Named Pipe
파이프 서버와 하나 이상의 파이프 클라이언트 간의 통신을 위해 명명된 단방향 또는 이중 파이프다.
Named Pipe는 파이프의 이름만 알고있다면 어떠한 관계에 있는 프로세스라도 통신이 가능하게 된다.
명명된 파이프의 모든 인스턴스는 동일한 파이프 이름을 공유하지만 각 인스턴스에는 자체 버퍼와 핸들이 있으며 클라이언트/서버 통신을 위한 별도의 통로를 제공한다.
인스턴스를 사용하면 여러 파이프 클라이언트에서 동일한 명명된 파이프를 동시에 사용할 수 있다.
FIFO라 불리는 특수파일, 서로 관련없는 프로세스 간 통신에 사용된다.
더 자세히 얘기하자면 리눅스에서는 Named Pipe를 mkfifo를 통해서 임시 파일을 만드는 방식으로 사용하지만 윈도우는 아예 내부 객체를 만들어서 구현한다고 한다.
더 찾아봄..
https://docs.microsoft.com/ko-kr/windows/win32/ipc/synchronous-and-overlapped-input-and-output 여기 대박 잘나와있음

참고자료: https://sosal.kr/659 [so_sal :티스토리]
- 메시지 큐 (Message Queue) 방식
위에도 적었듯이 Shared Memory 방식의 경우 프로세스별 동기화를 책임지지 않기 때문에 워터마크로 각 프로세스가 접근할 수 있는 영역을 나누는 것이 아니면 추가적인 동기화에 대한 구현이 요구된다.
이런 Shared Memory 방식의 동기화 문제에 대해 메시지 큐 방식은 비교적 자유롭기 때문에 여러 프로세스가 하나의 작업 공간에 대해서 접근하는 게 아니라면 Shared Memory 방식보다는 메시지 큐 방식이 더 유리하다고 한다.
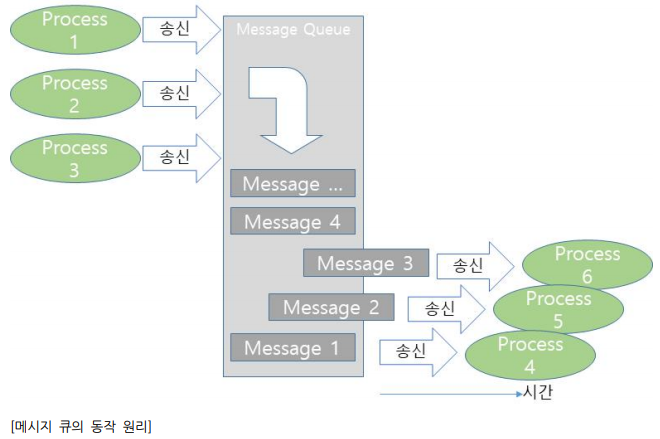
-
사용절차
1) 프로세스 A : 메시지 큐를 생성
2) 프로세스 A : 메시지를 메시지 큐에 송신 (운영체제가 보관)
3) 프로세스 B : 메시지 큐를 생성
4) 프로세스 B : 메시지 큐에서 수신(운영체제는 삭제)

-> 파이프와 메세지 큐 기법의 차이
- message queue는 부모/자식 관계없이 어떤 프로세스라도 데이터 송수신이 가능하다.
- FIFO 정책으로 먼저 삽입된 데이터가 먼저 읽힌다.
- message queue는 양방향 통신이 가능하다.
- 프로세스 A, B 간의 양방향 통신을 위해서는 메세지 큐가 2개 필요하다.
- 메세지 큐가 하나라면, 프로세스 A가 보낸 데이터를 프로세스 A가 읽을 수 있기 때문이다.
- 파이프와 메세지 큐 모두 커널 영역에서 작동한다는 것을 잊지말자.
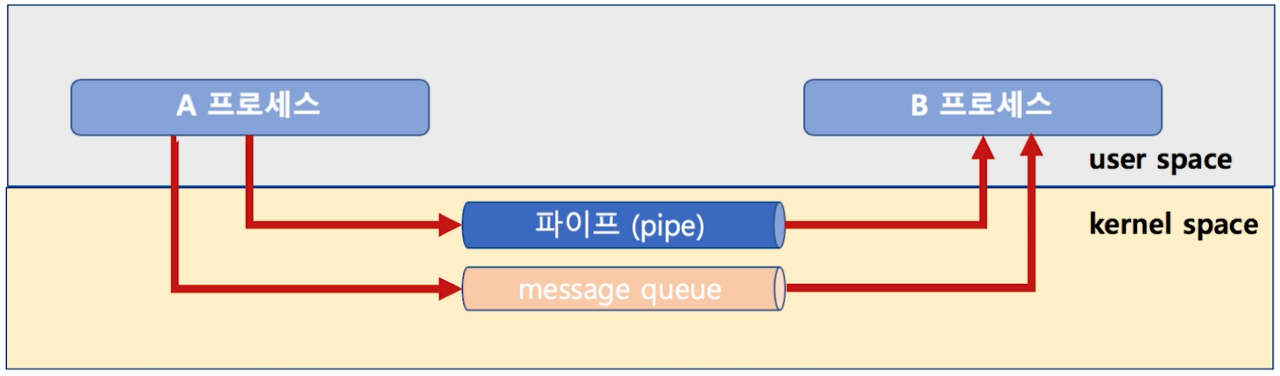
참고자료: https://tttsss77.tistory.com/234 // 구현 코드도 읽어보기!
https://devraphy.tistory.com/173
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=dkwlsrhstm&logNo=222049062773
- 윈도우 운영체제에서 프로세스 통신

- 소켓을 이용한 통신
다른 컴퓨터에 있는 프로세스와 통신(네트워킹)소켓은 양방향 통신, 프로세스 동기화를 지원하므로 데이터 받는 쪽에서 바쁜 대기(계속 왔나 확인하는 것) 안해도 됨
같은 컴퓨터 내 프로세스끼리도 소켓을 이용해서 통신할 수 있다. 127.0.0.1 루프백 ip주소를 사용하면 된다. 다만 소켓을 사용하려면 많은 전처리를 해야하기 때문에 다른 프로세스 간 통신방법보다 느리다.
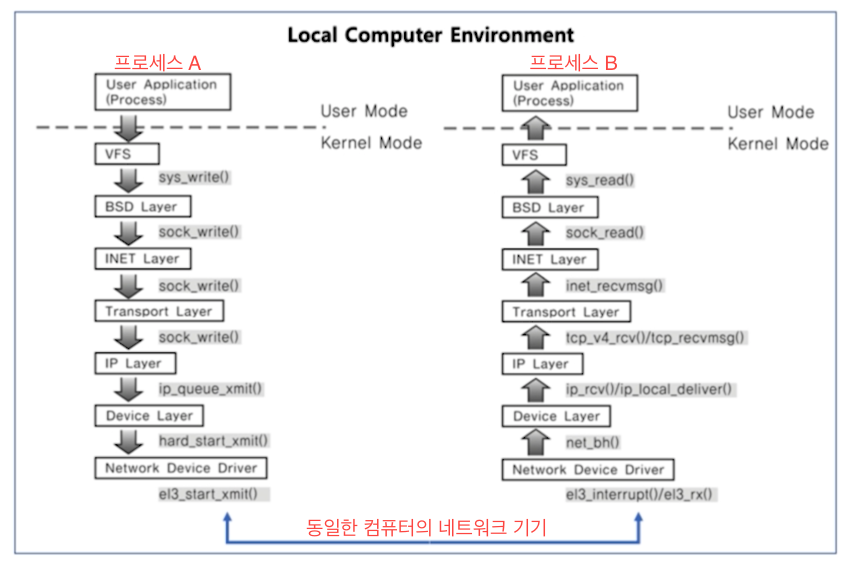
- 그 외에도 시그널 이런 통신도 있음
시그널 (Signal)
특징 : 프로세스 ID를 통해 특정 프로세스에게 메시지를 전달하는 방식
시그널 ID에 따라 어떤 이벤트인지 알 수 있다.
나머지 운영체제 개념 정리는 여기 참고하면 된다.
새삼 필기 중구난방이네 어휴.. 흐름나 내용을 완벽히 이해못했다는 증거인듯
뻘짓..
named pipe 찾아보면서 https://docs.microsoft.com/ko-KR/windows/win32/api/winbase/nf-winbase-createnamedpipea 여기 문서 살짝 읽었는데(문서 이해 하나도 못했지만) 글에 나온 키워드중에 하나 궁금해서 서칭해봄...
용어 정리:
NonPaged Pool
윈도우즈에서 내부적으로, 시스템이 사용하려는 메모리 공간을 제한되게 확보하는 것들이 있는데, 그 중에서 하나가 Non-Paged Pool이다.
Non-Paged Pool 메모리는 물리 메모리에만 할당 되는 것으로, 페이지 폴트가 없이 접근하기 위한 메모리 영역이다.
페이지 폴트가 없다보니, 접근 속도도 물론 빠르다.
커널이 메모리를 할당할때 메모리가 paging이 되는 페이지드 풀과 paging 되면 안되는 non paged pool 두 가지로 할당함

- 참고자료: https://elky.tistory.com/314
http://msdn.microsoft.com/en-us/library/aa366778.aspx
쉬운 설명... https://ssaturn.tistory.com/173
page fault 관련해서 나오는 개념같은데 따로 정리해야겠다..
https://blog.daum.net/99lib/290
https://docs.microsoft.com/en-us/windows/win32/memory/memory-pools
구글링해보니 page fault 관련 키워드도 같이 나와서 살짝 적어둠
page fault: 페이징 되는 애들 중에 접근했는데 아직 실메모리에 없을 때 알려주는 메커니즘
챕터 뒤에 나오는데 그때 다시 정리함..
쉽게 배우는 운영체제 챕터 5 연습/심화문제 답
- 연습문제
- 프로세스 간 통신에서 데이터를 양방향으로 전송 가능하지만 동시 전송은 불가능하고 특정 시점에 한쪽 방향으로만 전송할 수 있는 통신 방식은 무엇인가?
반양방향 통신 p.295
- 상태 변화를 살펴보기 위해 반복문을 무한 실행하며 기다리는 것을 무엇이라 하는가?
바쁜대기 (busy waiting) p.245
-
프로세스 간 통신에서 대기가 없는 통신과 대기가 있는 통신의 예를 각각 제시하시오.
대기가 없는 통신(비동기화): 전역변수, 파일
대기가 있는 통신(동기화): 소켓, 파이프p.246
-
파이프를 이용하여 통신할 때 파이프를 2개 사용하는 이유는 무엇인가?
파이프를 이용한 통신은 단방향이기 때문에 양방향 통신을 위해서는 2개가 필요하다.p.251
-
공유 자원을 병행적으로 읽거나 쓰는 상황을 무엇이라 하는가?
경쟁조건 (race condition)p.255
-
공유 자원의 접근 순서에 따라 실행 결과가 달라지는 프로그램의 영역은 무엇인가?
임계구역 (critical sectio)p.255
-
임계구역 해결 조건 중 한 프로세스가 임계구역에 들어갔을 때 다른 프로세스는 임계구역에 들어갈 수 없는 조건을 무엇이라 하는가?
상호배제 (mutual exclusion)p.258
-
임계구역 해결 조건 중 한 프로세스가 다른 프로세스의 진행을 방해해서는 안 된다는 조건을 무엇이라 하는가?
진행의 융퉁성 (progress flexibility)p.258
-
임계구역 문제를 하드웨어적으로 해결한 방식으로, 하드웨어의 지원을 받아 명령어를 실행하는 도중에 타임아웃이 걸리지 않도록 하는 방식을 무엇이라 하는가?
검사와 지정 코드 (Test and Set 방식)p.264
-
세마포어의 Semaphore(n)에서 n은 무엇을 가리키는가?
공유 가능한 자원의 수p.268
-
세마포어에서 내부 변수를 RS라고 할 때 세마포어 P()의 내부코드를 쓰시오.
if RS > 0 then RS=RS-1; else block();p.269
-
세마포어에서 내부변수를 RS라고 할 때 세마포어 V()의 내부코드를 쓰시오.
RS=RS+1; wake_up();p.269
-
세마포어가 제대로 작동하지 않는 경우를 설명하시오.
프로세스가 세마포어를 사용하지 않고 바로 임계구역에 들어간 경우P()를 두번 사용하여 wake_up신호가 발생하지 않는 경우P()와 V()를 반대로 사용한 경우
p.271
-
세마포어의 내부 코드도 타임아웃이 걸리면 문제가 발생할 수도 있다. 그래서 내부 코드는 무엇으로 보호받는가?
검사와 지정p.269 -
공유 자원을 내부적으로 숨기고 공유 자원에 접근하기 위한 인터페이스만 제공함으로써 자원을 보호하고 프로세스 간에 동기화를 시키는 것으로, 세마포어의 단점을 해결하면서 임계 구역 문제를 해결한 방식은 무엇인가?
모니터p.272
- 심화 문제
- 프로세스 간 통신을 통신 방향에 따라 분류하여 설명하시오.
p.246 - 대기가 있는 통신과 대기가 없는 통신의 의미를 설명하고 적절한 예를 제시하시오.
p.246 - 실생활의 예를 들어 임계구역 문제를 설명하시오.
p.255, 공용 화장실 - 다음 코드의 문제점을 설명하시오.
p.261 - 다음 코드의 문제점을 설명하시오.
p.264
Node.js 구현: 1-34~38장 (저자 CRUD, 코드 정리)
1-34 App - 글 수정 (수정 링크 생성)
function templateHTML(title, list, body, control) {
return `
<!doctype html>
<html>
<head>
<title>WEB1 - ${title}</title>
<meta charset="utf-8">
</head>
<body>
<h1><a href="/">WEB</a></h1>
${list}
${control}
${body}
</body>
</html>
`;
}templateHTML 함수에 control argument 추가하고
저 함수 갖다쓰는 곳으로 가서 control 변수에다가
`<a href="/create">create</a>
<a href="/update?id=${title}">update</a>`적당히 추가한다
(해당 title을 가진 글에서 update누르면 id = 제목인 쿼리스트링을 갖는다)
1-35 App - 글 수정 (수정할 정보 전송)
생성한 update링크를 클릭했을 때 보여줄 화면을 만들고, 이 화면에서 수정한 내용을 서버로 전송하는 방법을 알아보자.
- 경로가 /update일 때 처리하는 else if문 추가
else if (pathname === "/update") {
// 수정화면 처리
// 수정 폼 필요
//우리가 수정하고자 하는 데이터를 미리 넣어야 하므로 파일을 읽는(Read) 기능 있어야함.
// 따라서 파일 읽기 기능인 fs.readdir 부분을 그대로 복사해서 넣음
fs.readdir("./data", function (error, filelist) {
fs.readFile(`data/${queryData.id}`, "utf8", function (err, description) {
let title = queryData.id;
let list = templateList(filelist);
let template = templateHTML(
title,
list,
`<form action="/update_process" method="post">
<p><input type="hidden" name="id" placeholder="hidden_title, 기존 제목" value="${title}"></p>
<p><input type="text" name="title" placeholder="title, 새로 넣을 제목" value="${title}"></p>
<p>
<textarea name="description" placeholder="description">${description}</textarea>
</p>
<p>
<input type="submit">
</p>
</form>`,
`<a href="/create">create</a>
<a href="/update?id=${title}">update</a>`
);
response.writeHead(200);
response.end(template);
});
});
} 바로 업데이트하면 서버에서 처리할 때 뭘 바꿔야할 지 모르니까
기존, 업뎃 두가지 폼을 냅둔다
그리고 기존 폼은 숨김처리해둠
1 - 36 App - 글 수정 (수정된 내용 저장)
else if (pathname === "/update_process") {
// 수정 내용을 저장하는 코드 작성 (create_process 코드 재활용)
let body = "";
request.on("data", function (data) {
// 조각조각 나눠서 데이터를 수신할 때마다 호출되는 콜백 함수
// 데이터를 처리하는 기능을 정의
body = body + data;
});
request.on("end", function () {
// 더이상 수신할 정보가 없으면 호출되는 콜백함수
// 데이터 처리를 마무리하는 기능을 정의
let post = new url.URLSearchParams(body);
let id = post.get("id"); // 기존 title
let title = post.get("title"); // 새로운 title
let description = post.get("description");
fs.rename(`data/${id}`, `data/${title}`, function (error) {
fs.writeFile(`data/${title}`, description, "utf-8", function (err) {
response.writeHead(302, { Location: `/?id=${title}` });
response.end();
});
});
});
} console.log(post);
// 출력 결과:
// URLSearchParams { 'id' => 'title', 'title' => 'title3', 'description' => 'description\r\n' }- Nodejs에서 파일 이름을 변경하는 법
https://www.geeksforgeeks.org/node-js-fs-rename-method/

에러처리하는 콜백함수는 실무에서 매우 신경써야 함
대박 신기
대박~~
1 - 37 App - 글 삭제 (삭제 버튼 구현)
- 글 목록 중 하나를 선택했을 때
delete버튼 표시
if (pathname === "/") {
if (queryData.id === undefined) {
// 홈 화면일 때 표시
} else {
// 경로가 홈이면서 쿼리스트링이 undefined가 아닐 때
fs.readdir("./data", function (error, filelist) {
fs.readFile(
`data/${queryData.id}`,
"utf8",
function (err, description) {
let title = queryData.id;
let list = templateList(filelist);
let template = templateHTML(
title,
list,
`<h2>${title}</h2><p>${description}</p>`,
`<a href="/create">create</a>
<a href="/update?id=${title}">update</a>
<a href="/delete?id=${title}">delete</a>` <- 여기 추가
);
response.writeHead(200);
response.end(template);
}
);
});
}
}

update,delete와 같이 수정을 가하는 방식은 절대로 GET 방식으로 구현하면 안됨.
위에서 글 수정 기능 만들 때도 update 링크를 눌러 이동한 페이지에서 폼을 제공하고 Submit 버튼을 이용해서 POST 방식으로 처리함.
마찬가지로 삭제 기능도 링크로 구현하면 안되고 폼 버튼을 이용해 POST 방식으로 처리해야함
- 폼 버튼을 이용해 POST 방식으로 처리
let template = templateHTML(
title,
list,
`<h2>${title}</h2><p>${description}</p>`,
`<a href="/create">create</a>
<a href="/update?id=${title}">update</a>
<form action = "delete_process" method = "post" onsubmit = "return confirm('정말로 삭제하시겠습니까?');">
<input type = "hidden" name = "id" value = "${title}">
<input type = "submit" value = "delete">
</form>`
);첫 번째 <input> : hidden 속성으로 사용자에게 보이지 않게 숨기고 소스 코드에서 해당 개체를 식별하는 이름 (name)을 id로 지정
두 번째 <input>: [submit] 버튼에 delete 표시되게 value를 delete로 지정.
<form action = "delete_process" method = "post"> 버튼 누르면 삭제 요청을 delete_process가 처리하게 소스코드 추가함
onsubmit = "return confirm('정말로 삭제하시겠습니까?');" 삭제 알림창 띄워줌
1 - 38 App - 글 삭제 기능 완성
fs.unlink 의 첫번째인자는 파일경로+파일명, 두번째는 콜백함수 이다.
콜백함수엔 에러가 발생했을 경우의 err 인자를 줄 수 있다.
이 명령어는 파일을 지울 수 있다.
파일이 없다면 에러가 발생하므로 먼저 파일이 있는지를 꼭 확인해야 함!

이런 메서드도 있어서 궁금해서 찾아봄
fs.rmdir(path[, options], callback)
폴더를 지울 수 있다. 폴더 안에 파일이 있다면 에러가 발생하므로 먼저 내부 파일을 모두 지우고 호출해야 함.

- 삭제 요청을 처리하는 부분을 추가
else if (pathname === "/delete_process") {
let body = "";
request.on("data", function (data) {
body = body + data;
});
request.on("end", function () {
let post = new url.URLSearchParams(body);
let id = post.get("id"); // 기존 title
fs.unlink(`data/${id}`, function (err) {
response.writeHead(302, { Location: `/` });
response.end();
});
});
} 삭제가 끝난 다음 콜백함수 리다이렉션하는 코드 써줌
완성 코드
let http = require("http");
let fs = require("fs");
let url = require("url");
let qs = require("querystring");
const { title } = require("process");
const { list } = require("pm2");
function templateHTML(title, list, body, control) {
return `
<!doctype html>
<html>
<head>
<title>WEB1 - ${title}</title>
<meta charset="utf-8">
</head>
<body>
<h1><a href="/">WEB</a></h1>
${list}
${control}
${body}
</body>
</html>
`;
}
function templateList(filelist) {
let list = "<ul>";
for (let i = 0; i < filelist.length; i++) {
list = list + `<li><a href="/?id=${filelist[i]}">${filelist[i]}</a></li>`;
}
list = list + "</ul>";
return list;
}
let app = http.createServer(function (request, response) {
let _url = request.url;
let queryData = url.parse(_url, true).query;
let pathname = url.parse(_url, true).pathname;
if (pathname === "/") {
if (queryData.id === undefined) {
fs.readdir("./data", function (error, filelist) {
let title = "Welcome";
let description = "Hello, Node.js";
let list = templateList(filelist);
let template = templateHTML(
title,
list,
`<h2>${title}</h2><p>${description}</p>`,
`<a href="/create">create</a>`
);
response.writeHead(200);
response.end(template);
});
} else {
fs.readdir("./data", function (error, filelist) {
fs.readFile(
`data/${queryData.id}`,
"utf8",
function (err, description) {
let title = queryData.id;
let list = templateList(filelist);
let template = templateHTML(
title,
list,
`<h2>${title}</h2><p>${description}</p>`,
`<a href="/create">create</a>
<a href="/update?id=${title}">update</a>
<form action = "delete_process" method = "post" onsubmit = "return confirm('정말로 삭제하시겠습니까?');">
<input type = "hidden" name = "id" value = "${title}">
<input type = "submit" value = "delete">
</form>`
);
response.writeHead(200);
response.end(template);
}
);
});
}
} else if (pathname === "/create") {
fs.readdir("./data", function (error, filelist) {
let title = "WEB - create";
let list = templateList(filelist);
let template = templateHTML(
title,
list,
`
<form action="/create_process" method="post">
<p><input type="text" name="title" placeholder="title"></p>
<p>
<textarea name="description" placeholder="description"></textarea>
</p>
<p>
<input type="submit">
</p>
</form>
`,
""
);
response.writeHead(200);
response.end(template);
});
} else if (pathname === "/create_process") {
let body = "";
request.on("data", function (data) {
// 조각조각 나눠서 데이터를 수신할 때마다 호출되는 콜백 함수
// 데이터를 처리하는 기능을 정의
body = body + data;
});
request.on("end", function () {
// 더이상 수신할 정보가 없으면 호출되는 콜백함수
// 데이터 처리를 마무리하는 기능을 정의
let post = new url.URLSearchParams(body);
let title = post.get("title");
let description = post.get("description");
fs.writeFile(`data/${title}`, description, "utf-8", function (err) {
response.writeHead(302, { Location: `/?id=${title}` });
response.end();
});
});
} else if (pathname === "/update") {
// 수정화면 처리
// 수정 폼 필요
//우리가 수정하고자 하는 데이터를 미리 넣어야 하므로 파일을 읽는(Read) 기능 있어야함.
// 따라서 파일 읽기 기능인 fs.readdir 부분을 그대로 복사해서 넣음
fs.readdir("./data", function (error, filelist) {
fs.readFile(`data/${queryData.id}`, "utf8", function (err, description) {
let title = queryData.id;
let list = templateList(filelist);
let template = templateHTML(
title,
list,
`<form action="/update_process" method="post">
<p><input type="hidden" name="id" placeholder="hidden_title, 기존 제목" value="${title}"></p>
<p><input type="text" name="title" placeholder="title, 새로 넣을 제목" value="${title}"></p>
<p>
<textarea name="description" placeholder="description">${description}</textarea>
</p>
<p>
<input type="submit">
</p>
</form>`,
`<a href="/create">create</a>
<a href="/update?id=${title}">update</a>`
);
response.writeHead(200);
response.end(template);
});
});
} else if (pathname === "/update_process") {
// 수정 내용을 저장하는 코드 작성 (create_process 코드 재활용)
let body = "";
request.on("data", function (data) {
// 조각조각 나눠서 데이터를 수신할 때마다 호출되는 콜백 함수
// 데이터를 처리하는 기능을 정의
body = body + data;
});
request.on("end", function () {
// 더이상 수신할 정보가 없으면 호출되는 콜백함수
// 데이터 처리를 마무리하는 기능을 정의
let post = new url.URLSearchParams(body);
let id = post.get("id"); // 기존 title
let title = post.get("title"); // 새로운 title
let description = post.get("description");
fs.rename(`data/${id}`, `data/${title}`, function (error) {
fs.writeFile(`data/${title}`, description, "utf-8", function (err) {
response.writeHead(302, { Location: `/?id=${title}` });
response.end();
});
});
});
} else if (pathname === "/delete_process") {
let body = "";
request.on("data", function (data) {
body = body + data;
});
request.on("end", function () {
let post = new url.URLSearchParams(body);
let id = post.get("id"); // 기존 title
fs.unlink(`data/${id}`, function (err) {
response.writeHead(302, { Location: `/` });
response.end();
});
});
} else {
response.writeHead(404);
response.end("Not found");
}
});
app.listen(3000);
리트코드 알고리즘 문제 풀이
- 2389. Longest Subsequence With Limited Sum
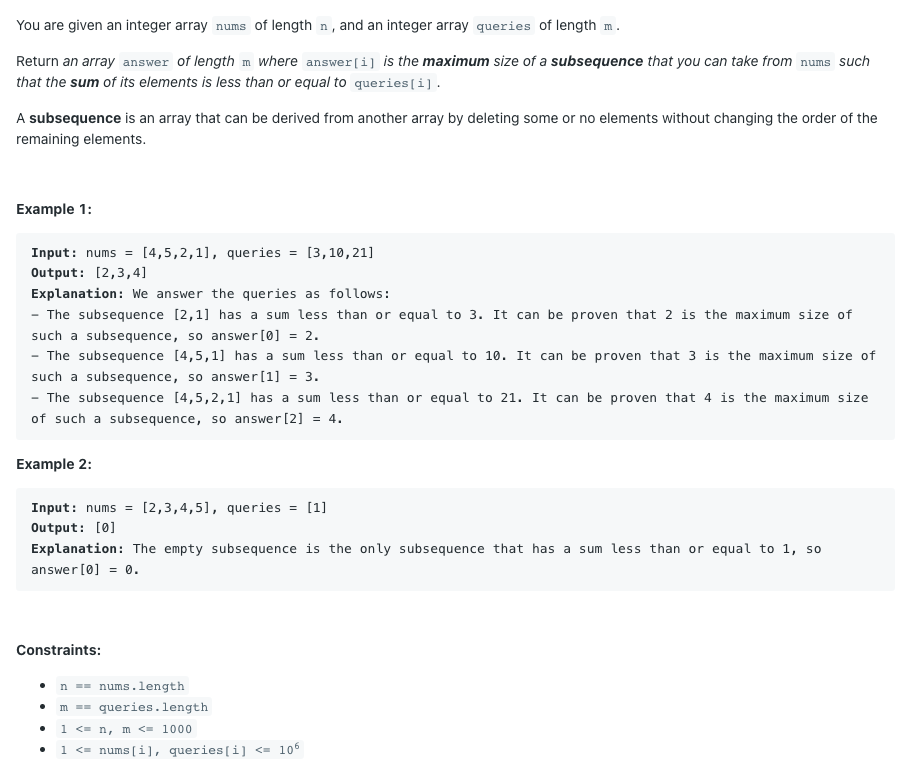
const solution = (nums, queries) => {
const n = nums.length;
const q = queries.length;
const sortedNums = nums.sort((a, b) => a - b);
let answer = [];
for (let i = 0; i < q; i++) {
let target = queries[i];
let length = 0;
let max = 0;
for (let j = 0; j < n; j++) {
if (target >= nums[j]) {
target -= nums[j];
length++;
}
max = Math.max(max, length);
}
answer.push(max);
}
return answer.length === 0 ? [0] : answer;
};
console.log(solution([4, 5, 2, 1], [3, 10, 21])); // [2,3,4]솔루션 봄
하루 회고
-
하루 한 것
Nodejs 구현 34~38장 (저자 CRUD, 코드 정리) -> 42장까지 풀이
운영체제 챕터 5
SQL 기초 문제 리트코드나 프로그래머스에서 풀기
알고리즘 문제 리트코드 https://leetcode.com/problems/longest-subsequence-with-limited-sum/
관계형 데이터베이스 이론 공부 -
못한 것
RDB 이론 내용 하나도 이해가 안간다. 원래 알고 있던 내용도 책에선 엄청 어렵게 설명해둔 것 같다..
시간을 효율적으로 사용하지 못하는 것 같다
-
피드백
RDB 책 일단 완독한다!
시간 배분을 적당히 나눠야겠다. -
내일 할 것
Node js 구현 (1-43 ~ 48)
자바스크립트 객체 ~ 클래스 개념 이해하기
운영체제 챕터 6 공부
자료구조 및 알고리즘 1문제 풀이
네트워크 공부하기 (1강)
집에 가서 관계형 데이터 베이스 이론 책 읽기
