문자열 부분 가져오기 (left, mid, right)
MySQL에서 문자열에 일부분을 가져오는 함수는 대표적으로 3가지가 존재합니다.
- LEFT : 문자에 왼쪽을 기준으로 일정 갯수를 가져오는 함수.
- MID : 문자에 지정한 시작 위치를 기준으로 일정 갯수를 가져오는 함수.
- RIGHT : 문자에 오른쪽을 기준으로 일정 갯수를 가져오는 함수.
- 참고로 MID 함수는 SUBSTR과 SUBSTRING 함수의 동의어입니다.
사용법
LEFT
LEFT(문자, 가져올 갯수)
예시
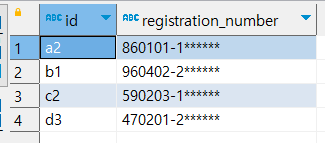
select left('860101-1******',6) -- 주민번호 앞저리 6자리만 가져옴 860101MID
MID(문자, 시작위치, 가져올 갯수)
-- 또는 SUBSTR(문자, 시작 위치, 가져올 갯수);
-- 또는 SUBSTRING(문자, 시작 위치, 가져올 갯수);
예시
select mid('860101-1******',8,1) -- 주민번호 뒷자리 첫번째 자리 가져오기 1RIGHT
RIGHT(문자, 가져올 갯수)
SELECT RIGHT('abcdefg', 3) -- efg
if 삼항 연산자
조건 연산자라고 하며, if문(조건,참일때의 값, 거짓일때의 값) 순으로 인자를 넣어준다.
사용법
select if(조건,참,거짓)
예시
-- registration number의 8번째 자리가 1이면 남자, 2면 여자인 조건문의 쿼리를 생성하시오
select *, if(mid(registration_number,8,1)=1,'M','W') as 'gender'
from hr.example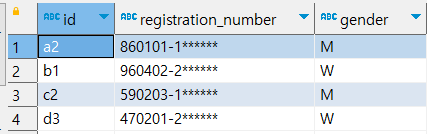
Recursive 함수 (sql 재귀함수)
with recursive 테이블 or 뷰 as(
초기 SQL문 -- SELECT 문
UNION ALL
반복할 SQL문 -- SELECT문 + WHERE문
)
SELECT문 +FROM 테이블 or 뷰
- 원리 설명
- 초기 SQL문(Anchor member)을 실행하면 recursive문을 선언할 때 기재한 테이블이나 뷰에 담긴다
- 반복할 SQL문의 FROM 절에 앞선 테이블이나 뷰명을 이용해서 처리한다
- UNION 혹은 UNION ALL 연산을 한다
- 반복할 SQL문에서 단 하나의 레코드가 나오지 않을때, 반복문을 탈출한다
- recursive문을 탈출한 후 결과가 테이블 혹은 뷰에 담기게 되고 조회를 한다
예시
with recursive temp_01 as
(select 0 as hour --- 1. temp_01 테이블에 hour이란 컬럼으로 0이 담김
union all --- 2. 위의 테이블과 아래의 테이블을 중복 포함 합침
select hour +1 -- 3. temp_01의 hour 값을 참고하여 0+1 = 1의 값을 담음. 이후 hour이 1의 값으로 기억이 되며 이를 반복함
from temp_01
where hour<24 -- 4. hour이 24까지 담길때 까지 3번을 반복함
)
select * from temp_01;
aggregate 함수 + group by / window 함수 비교
집계함수는 여러행의 수치를 단 1개의 수치로 반환할때 사용
AVG() : 여러 행의 수치의 평균 값을 반환합니다.
SUM() : 여러 행의 수치의 총 합을 반환합니다.
MAX()와 MIN() : 여러 행의 수치 내에서 각각 최댓값과 최솟값을 반환합니다.
COUNT() : 여러 행의 수치의 총개수를 반환합니다.
- 집계함수 단독으로 쓰일 때
select avg(amount), count(*), max(amount) -- 집계함수는 여러행의 수치를 단 1개의 수치로 반환
from nw.order_items ;

- 집계함수 + group by
-- aggregate + group by = unique 한 order id 별로 그룹핑, 즉, 여러개의 행을 합쳐 order_id 행별로 1개의 값을 반환
select order_id , sum(amount) as amount_sum_order_id, count(*)
from nw.order_items
group by order_id ;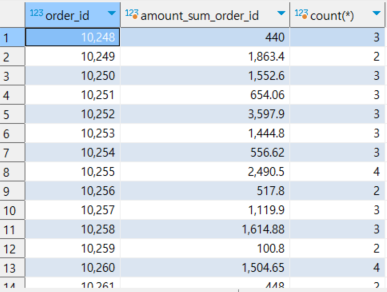
- 집계함수 + window 함수
윈도우 함수는 각 행마다 1개의 값을 반환하여 원래 집합 레벨을 유지시킨다
order by절을 사용해여 순차적인 누적합을 사용할 수 있는 등의 윈도우 함수를 활용한 쿼리가 훨씬 보기 간편하고 작성이 편한 장점이 있음
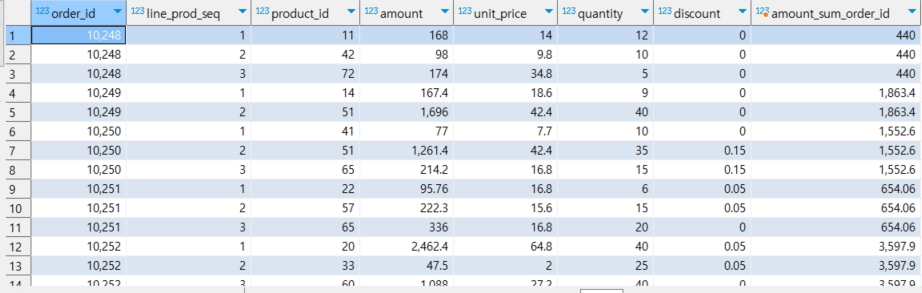
-- aggregate + 윈도우 함수 = 모든 order id가 전부 나옴(컬럼의 레벨 유지), 즉, 각행마다 1개의 값 반환
select *,sum(amount) over (partition by order_id) as amount_sum_order_id
from nw.order_items
LPAD() / RPAD()
LPAD(): 왼쪽부터 특정 문자를 원하는 자리수 만큼 채워서 반환
사용법: LPAD(원본문자열 , 원하는 자리수, 채울 문자열)
예시
SELECT LPAD('ABC',10,'0')
-- 0000000ABC
RPAD : 오른쪽에 특정문자를 원하는 자리수만큼 채워서 반환
사용법 : RPAD(원본문자열 , 원하는 자리수, 채울 문자열)
SELECT RPAD('ABC',9,0)
-- ABC000000예제) example_accounts 테이블의 계좌 번호를 9자리로 만들어라. (숫자 부족시에는 0을 왼쪽 부터 채우시오)
Column 설명: a_num은 '-'를 포함한 숫자 9자리의 계좌번호, name은 이름, property는 재산
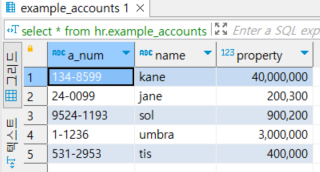
select LPAD(a_num,9,0), name, property
from hr.example_accounts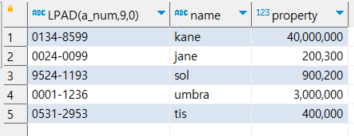
집계 함수 vs 집계 함수 + over() vs 집계함수 +over(인자)
- 집계함수만 단독 사용
- 1개의 값만 나옴
-- 1. 집계함수 단독 사용 --> 1개의 값만 나옴
select *, sum(amount)
from nw.order_items
limit 10
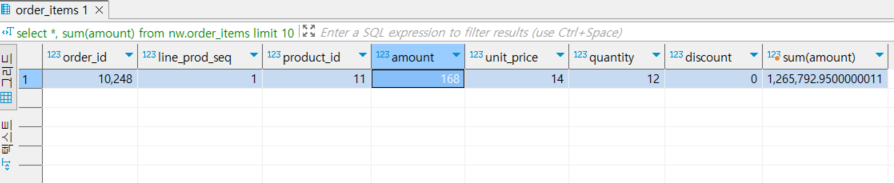
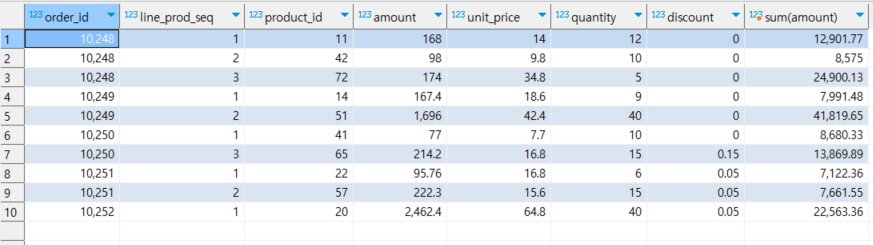
1.1 집계 함수 + group by
- 그룹핑 된 컬럼의 unique한 레벨로 조회
select *, sum(amount)
from nw.order_items
group by product_id
limit 10
- 집계 함수 + 윈도우 함수에 아무것도 넣지 않기
- 윈도우 함수가 모든 행의 값을 가져오는 것 처럼 집계 함수 단독으로 쓰였을때와 비교해 봤을때, 모든 행에 값이 붙게 됨. 단, 그룹핑이 되지 않은 상태
--- 2. 윈도우 함수에 인자를 넣지 않고 실행시 모든 행에 값이 붙음, 단 그룹핑은 안된상태
select *, sum(amount) over()
from nw.order_items
limit 10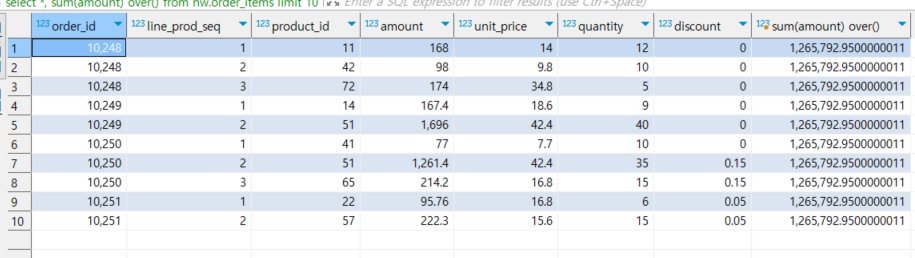
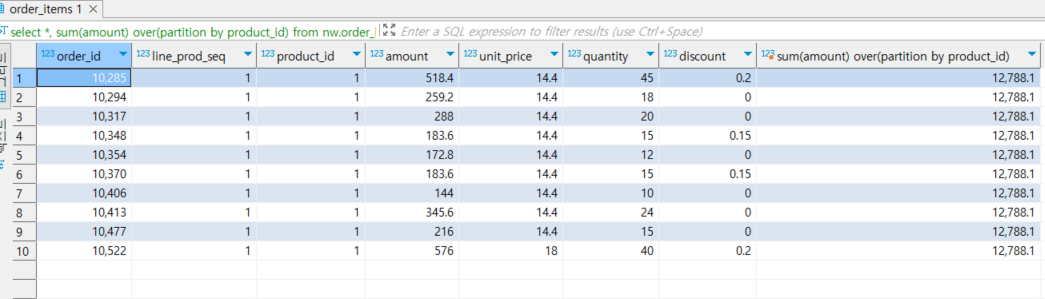
- 집계 함수 + 윈도우 함수(인자)
- 윈도우 함수에 그룹핑할 인자(partition by product_id)를 넣을 시 해당 컬럼에 맞게 product_id별로 amount를 sum 한 값이 모든 행에 붙게됨
--- 3. 그룹핑할 대상을 정해주고 모든 행에 값이 붙게 하기
select *, sum(amount) over(partition by product_id)
from nw.order_items
limit 10
예시
select * from nw.order_items;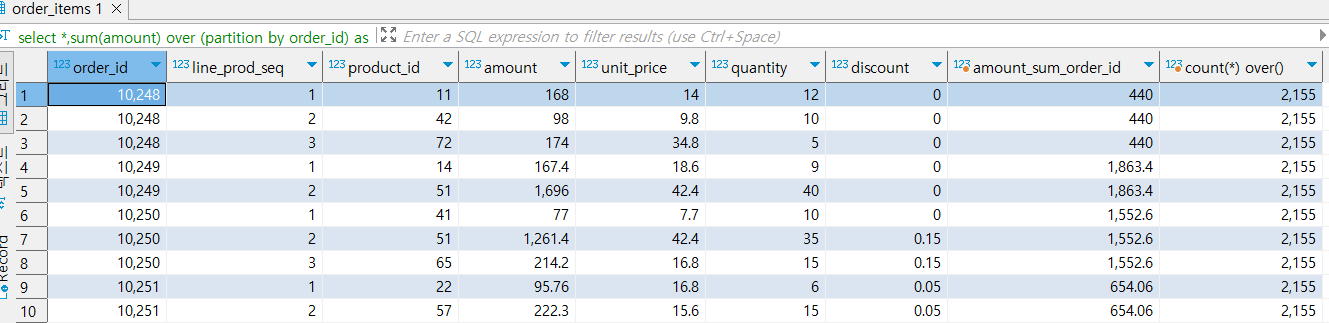
- 집계함수 + window 함수
- order_id의 집합 레벨 m을 유지함
select order_id , sum(amount) over(partition by order_id)
from nw.order_items 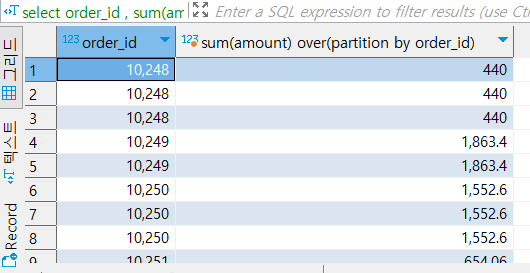
- 집계 함수 + window함수 *
- count( ) 만 적용시 1개의 행만 반환됨. 그러므로 꼭 count() over() 을 적어줘야 총 몇개의 행이 존재하는지 붙게됨
select order_id, sum(amount) over(partition by order_id), count(*) over()
from nw.order_items 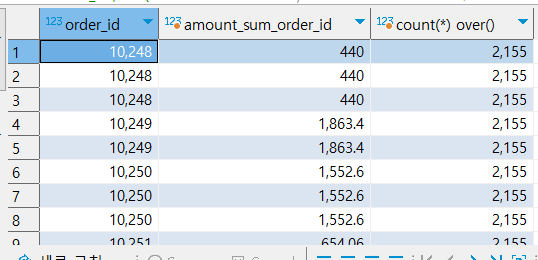
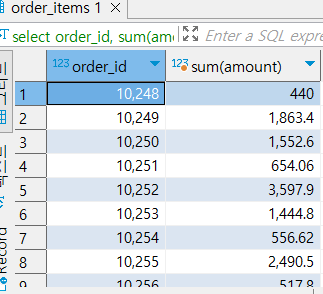
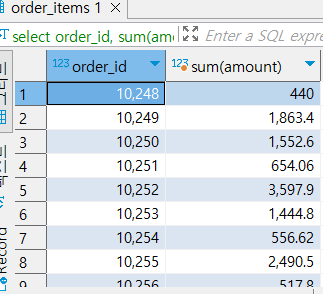
- 집계함수 + group by
order_id의 집합 레벨 unique을 유지함select order_id, sum(amount) from nw.order_items group by order_id
- 집계 함수 + group by(2)
- count(*) 만 써도 그룹핑이 되어 있기 때문에 order_id에 해당하는 rows의 갯수를 반환
select order_id , sum(amount) as amount_sum_order_id, count(*) -- order_id의 갯수를 셈
from nw.order_items
group by order_id ;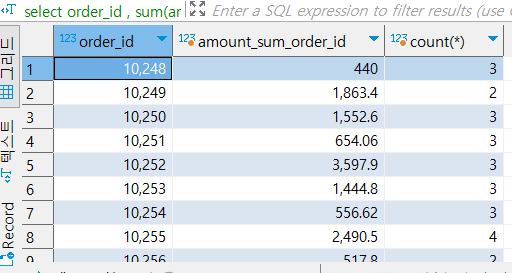
dbeaver 테이블로 내보내기
디비버의 기능중 쿼리를 하다가 원하는 데이터가 가공되면 그 상태 그대로 데이터를 추출하는 강력한 기능이 있다. 이는 csv파일로 내보낼 수 도 있고, 디비버의 데이터베이스 중에서 원하는 데이터 베이스 안에 테이블 형식으로 내보낼 수도 있다.
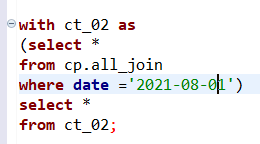
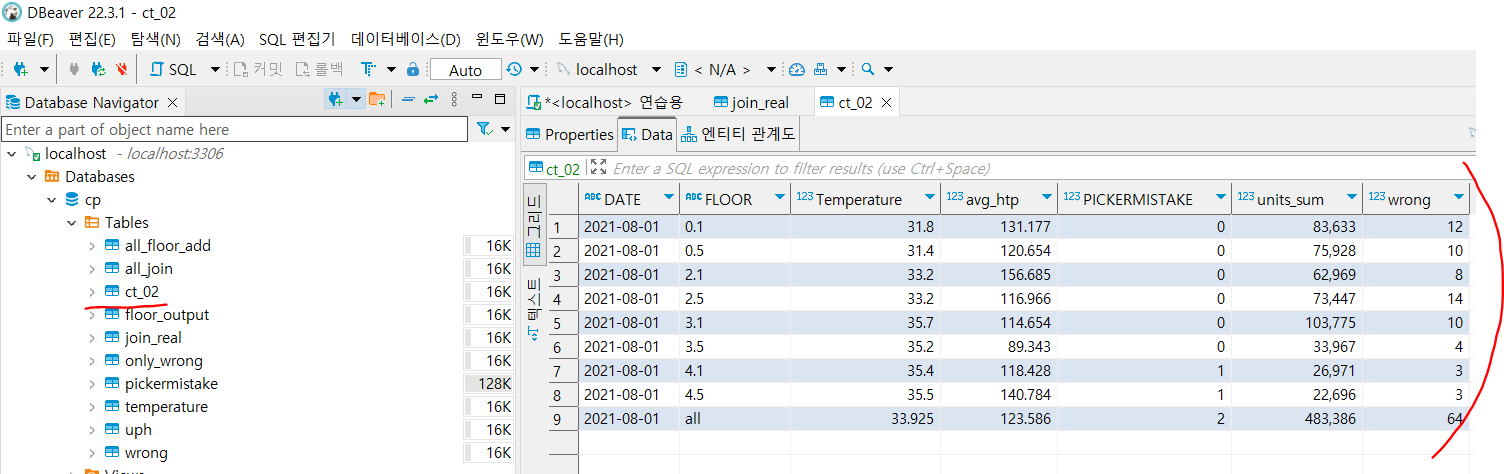
cp 데이터 베이스의 all join 조건중에서 21년도 8월 1일만 추출한 데이터를 새로운 테이블로 만들고 싶은 상황이다. 이때 임시테이블 with을 사용해서 저렇게 원하는 db에 넣어 ct_02라는 테이블로 만들어 또다른 테이블의 데이터를 조작하여 사용할 수 도 있다.
단, 꼭 임시테이블로 해야 테이블이 만들어지며, 원래 있는 테이블을 참고하여 만들었을 경우 원래 테이블에 덮어써지므로 주의해야함.
- ex_)
select *
from cp.all_join
where date ='2021-08-01' -- all_join이 해당 조건값으로 변경됨라는 쿼리를 치고 데이터 추출>테이블 보내기를 누르면, all_join 테이블이 해당 조건의 값으로 덮어써짐
date_format()와 str_to_date() 함수는 꼭 타입을 맞추지 않아도 된다
- date_format 함수는 date타입을 format을 사용하여 str 타입으로 바꿔주는 함수며 str_to_date 함수는 str 타입의 컬럼을 date 타입으로 변경해주는 함수이다. 하지만, date 타입처럼 생겼으면 그 컬럼이 int이건 str이건 date건 상관없이 함수를 실행한다.
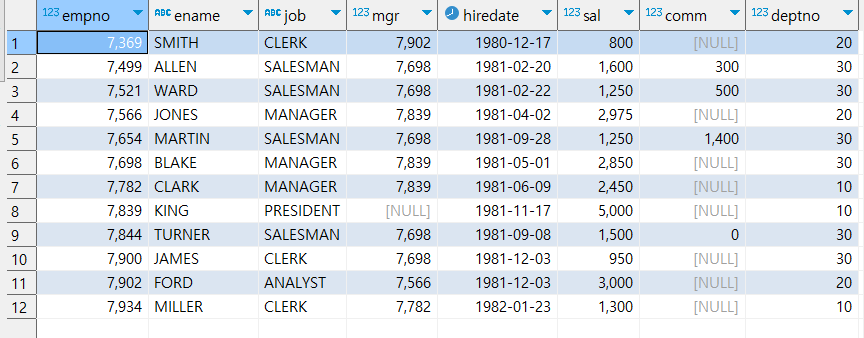
hr 데이터 베이스의 emp 테이블이다. hiredate 컬럼은 실제 데이터 타입이 date 타입이며 이를 활용해서 구별이라는 컬럼을 만들 수 있다.
또한 empno는 4가지 숫자로 구성된 컬럼인데 인느 4자리 년수라고 인식되며 이를 str_to_Date 함수에 넣고 년에 해당하는 컬럼으로 바꾸라고 쿼리를 실행해 본다.
select * , date_format(hiredate ,'내부인') as '구별'
, STR_TO_DATE(empno,'%Y')
from hr.emp ;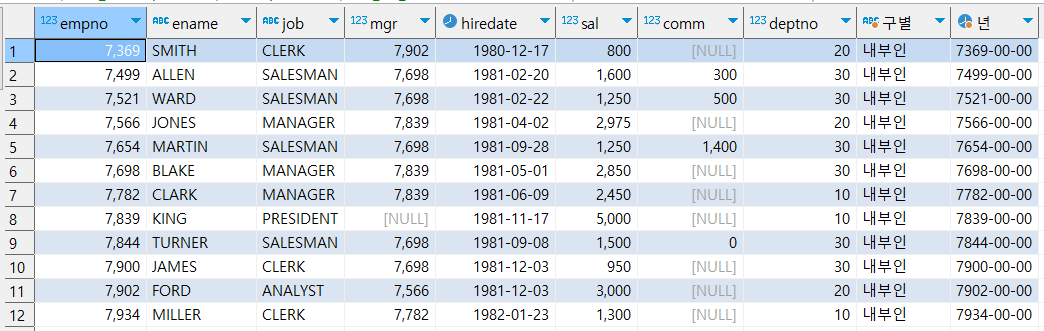
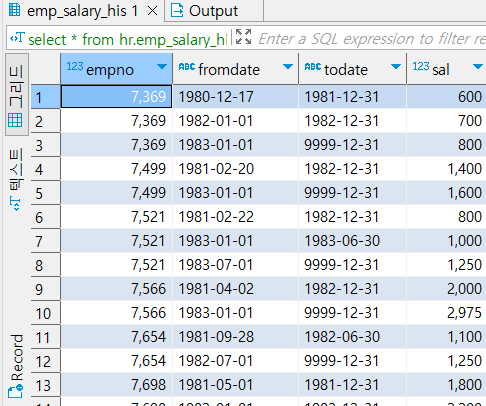
또다른 예시로 hr 데이터 베이스의 직원들의 sal history 테이블이다. 이 테이블의 fromdate 컬럼은 생긴건 date 타입같지만 실제로 str 타입의 컬럼이다. 이를 이용하여 새로운 컬럼을 추가해본다. 또한 정상적인 str_to_date 함수를 활용하여 년만 추출할 수 있다
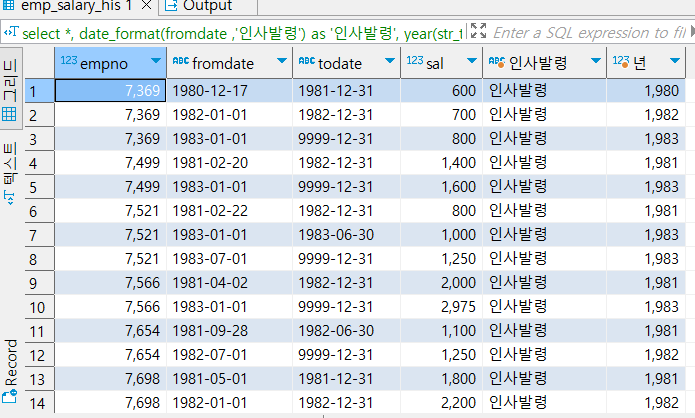
select *, date_format(fromdate ,'인사발령') as '인사발령',
year(str_to_date(fromdate,'%Y-%m-%d')) as '년'
from hr.emp_salary_his;
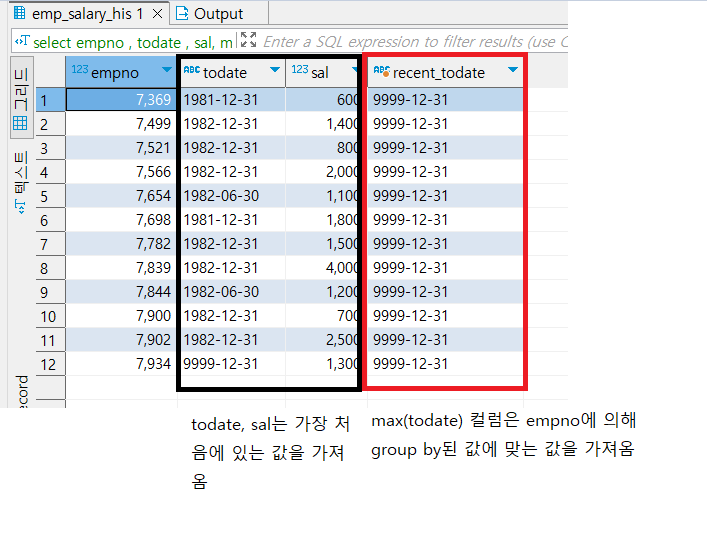
group by는 집계함수 값만을 group by한 컬럼에 맞게 가져온다 ****
예를들어, hr.emp_salry_his 테이블에서 가장 최근의 todate를 보고 싶은 상황이다.

select empno , todate , sal, max(todate) as 'recent_todate'
-- empno 별로 가장 최신의 todate, empno와 todate, sal는 가장 처음의 값을 가져옴
from hr.emp_salary_his
group by empno
만일 각 empno 별로 가장 최신의 todate에 맞는 sal를 조회하고 싶다면 집계 함수를 써서 가져올 수 있다
with ct_01 as(
select *, max(sal) over (partition by empno order by todate desc) as 'recent_sal'
from hr.emp_salary_his)
select empno , fromdate , todate , recent_sal
from ct_01
group by empno
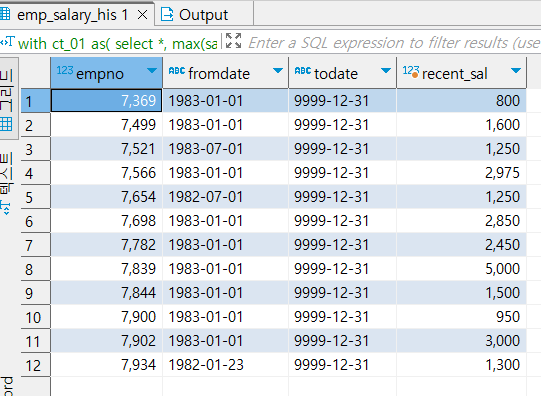
max(sal) 값은 단순히 가장 큰 값이 아니라, empno별로 todate의 내림차순 순으로 정렬하여 가장 큰 값을 가져오도록 했다. 집계함수를 쓴 이유는 모든 행에 값이 반영되게 하기 위함도 있다.
