❤️오답노트 활용 팁
-
원인 분석에 집중하세요: 정답 코드를 이해하는 것보다 내가 왜 틀렸는지를 한두 줄이라도 직접 글로 써보는 과정이 가장 중요합니다. '실수했다'에서 그치지 않고 '왜 실수했는지'를 파고들어야 같은 실수를 반복하지 않습니다.
-
태그를 적극적으로 활용하세요:
#JOIN,#서브쿼리,#날짜함수와 같이 태그를 꾸준히 달아두면, 나중에 특정 개념이 약하다고 느낄 때 해당 태그가 달린 문제들만 모아서 복습할 수 있습니다. -
주기적으로 다시 풀어보세요: 일주일 뒤, 한 달 뒤에 오답 노트를 보면서 코드를 보지 않고 다시 한번 풀어보세요. 완벽하게 풀 수 있다면 그 개념은 이제 당신의 것이 된 겁니다.
⭐ 오답 노트 TEMPLATE
📆 날짜: 2025-08-07
📌 문제 정보
- 출처 및 번호: [예: 리트코드/570. Managers with at Least 5 Direct Reports]
- 문제 링크: https://leetcode.com/problems/managers-with-at-least-5-direct-reports/?envType=study-plan-v2&envId=top-sql-50
📝 문제 요약
- 5명 이상의 직원을 갖고 있는 매니저 이름 조회
❌ 나의 오답 코드
-- 여기에 내가 작성했던 틀린 코드를 그대로 붙여넣으세요.
select
name
from (
select
e2.name as name,
count(*)
from
employee e1
join employee e2 on e1.id = e2.managerid
group by
1
having
count(*) >=5
) as result
🤔 오답 원인 분석
오류 메시지 또는 실패 원인: ['문법적 오류는 없으나 join 조건을 완전 반대로 적음']
근본적인 실수: [예: '
① 문제를 제대로 이해하지 않았고, 아는 문제라고 쉽다고 생각 함.
② 테이블 alias를 더 명확하게 만들었어야 함
(ex. e1, e2 라고 쓸 시 어떤 것이 직원테이블인지, 매니저 테이블인지 모름 → e,m으로 변경)
③ 조인 조건을 꼼꼼히 생각해 보는 습관 기르기']
헷갈렸던 개념: [예:'없음' ]✅ 정답 코드 및 핵심 로직
SELECT
m.name -- 3. 조건을 만족하는 매니저의 이름을 조회합니다.
FROM
Employee e -- 1. e는 직원(employee) 테이블입니다.
JOIN
Employee m ON e.managerId = m.id -- 2. 직원의 managerId와 매니저의 id를 연결합니다. m은 매니저(manager) 테이블입니다.
GROUP BY
m.id -- 매니저 ID를 기준으로 그룹을 만듭니다. (이름이 같을 수 있으니 id로 하는 것이 더 안전합니다)
HAVING
COUNT(e.id) >= 5; -- 각 매니저 그룹에 속한 직원 수가 5명 이상인 경우만 필터링합니다.
- 핵심 로직: 셀프 조인 후, 매니저 아이디로 그룹바이 이후에 직원 아이디를 카운팅 하는 조건
📚 핵심 개념 및 배운 점
-
주요 함수/문법: -
-
배운 점:
ㄴ TEST 시 긴장 하므로, 이해가 더 안될 확률이 엄청 크다. 테이블로 헷갈리지 않도록 직관적인 별칭을 써야한다.
ㄴ GROUP BY는 꼭 SELECT절에 primary key가 포함된 경우라면, primary key 하나만 써도 무방하며, select 절에 미포함 되도 primary key로 그룹핑 할 수 있다 (유일성)
*GROUP BY에 쓸 수 있는 컬럼 정리
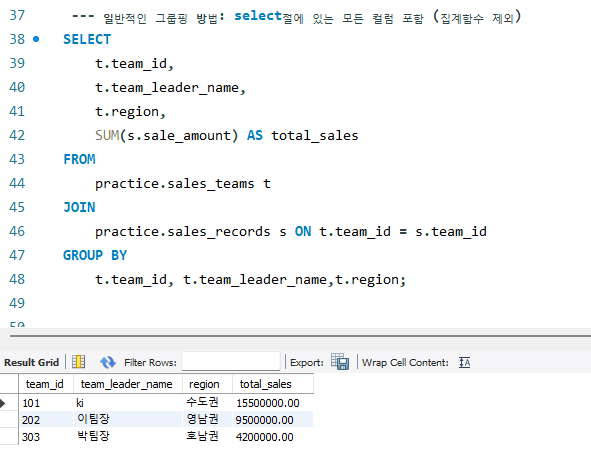
ㄴ원칙: SELECT 절의 모든 일반 컬럼은 GROUP BY 절에 포함되어야 한다.
ㄴ예외 (스마트한 데이터베이스): 하지만 최신 데이터베이스들은 GROUP BY에 기본 키(Primary Key)가 포함되면, 그 기본 키에 함수적으로 종속되는 다른 컬럼들은 이미 그룹화된 것으로 간주하여 SELECT 절에 자유롭게 사용할 수 있도록 허용
*예시
- 테이블 구성 : sales_teams, sales_record

sales_teams
sales_records
예시1: 보통의 경우 (select절에 쓰인 모든 컬럼 집계 함수 제외 똑같이 쓰기)
예시2: 예외적인 경우
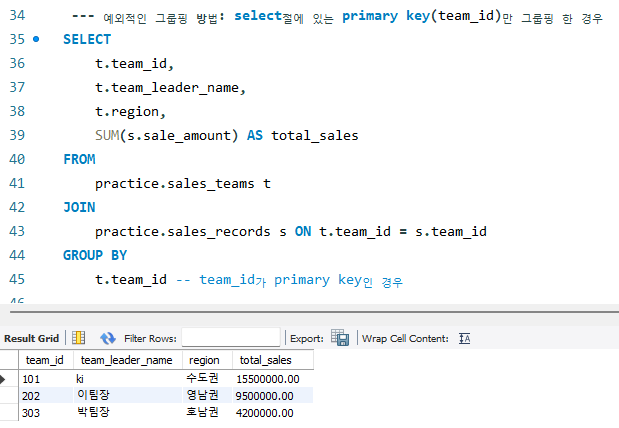
- primary key가 아닌 다른 컬럼들은 기본 키에 함수적으로 종속되어 있다 판단하여, group by절에서 생략 가능
- primary key인 team_id에 의해 team_leader_name과 region 결정됨
- 왜냐하면 team_id가 101이면 팀장 이름은 항상 '김팀장', 지역은 항상 '수도권'이므로, 여러 값 중에 고민할 필요가 없다는 것
- 만일 101의 팀장이 변경될 순 있어도, 101 이라는 team_id는 primary key이기 때문에 테이블에 중복해서 나오지 않는 unique한 값(고유성)

8/ 18 재풀이 예정