
1. 데이터베이스의 역사
스토리지의 역사

처음 저장장치는 자기 드럼(Magnetic Drum) 이였고
금속 원통에 자성을 기록하는 방식이다.
프로그램을 철판 같은 데에 기록하는 방식인데 용량이 적고 느렸다

이후 자기코어 메모리(Magnetic-core memory)
가 나오면서 용량과 속도가 좋아졌다
저장방법의 역사
자기코어 메모리가 나온후 초기 컴퓨터는 데이터를 모두 파일에 저장했는데 검색이 매우 느렸다.
파일은 처음부터 끝까지 읽는 방식(순차 검색) 이라
3억 명 중 마지막 사람 찾으면 몇 시간이나 걸리기 때문이다.
그래서 그걸 보완하기 위해서 인덱스(Index)라는게 등장했는데
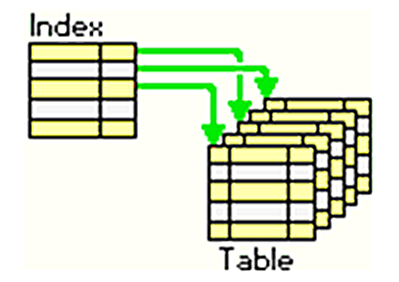
인덱스(index) 는 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다.index는 책에서도 많이 볼 수 있는데 책의 인덱스 처럼 데이터베이스의 index는 책의 색인과 같다 데이터와 데이터의 위치를 포함한 자료구조를 생성하여 빠르게 조회할 수 있도록 한다.
예:
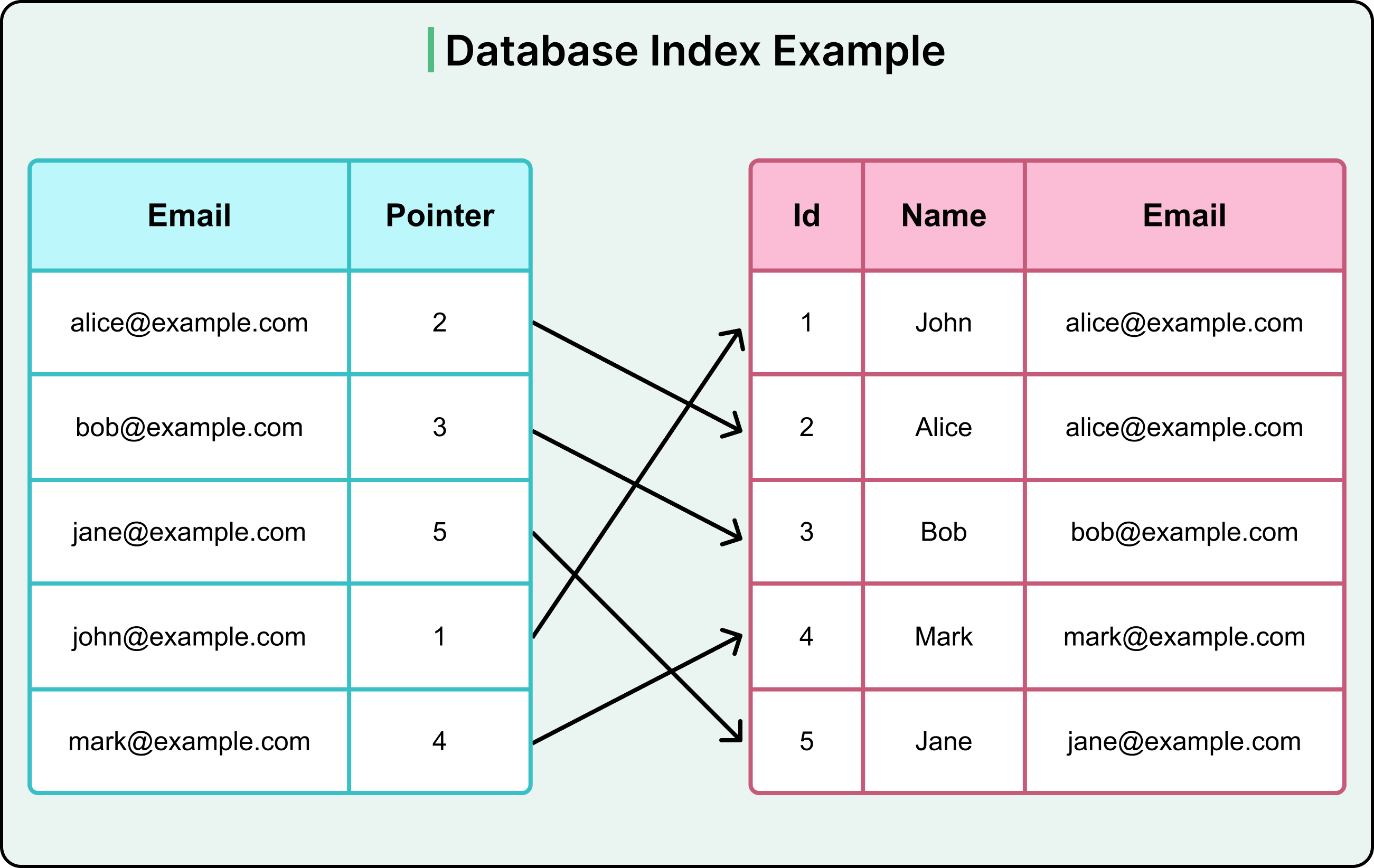
이걸로 검색 속도가 수백~수천 배 빨라졌고 이 아이디어가 현대 데이터베이스의 뿌리가 되었다.
DBMS(Database Management System) 데이터베이스의 등장

DBMS(Database Management System)는데이터를 저장하고, 인덱스 만들고, 검색하고, 수정하고, 동시에 여러 사용자 요청을 처리하는 소프트웨어를 말한다. IBM이 인덱스 +파일 관리 프로그램을 하나로 묶어서 소프트웨어를 판매하기 시작하면서 등장하게 됬고 그 이후로 시작이 지나서 우리에게도 익숙한 MySQL / Oracle / PostgreSQL 이 등장했고 서로다른문법도 공식화 됐다.
2.MySQL
2.1 DB 내부 동작: 메모리와 커밋/롤백
UPDATE / DELETE / INSERT 수행 시 DB는 다음 순서로 동작한다.
- 디스크에서 데이터를 메모리로 가져온다
메모리 세그먼트(버퍼)에 레코드를 로드한다.
실제 디스크 파일을 직접 고치는 게 아니라 메모리에서 작업함.
-
변경 전 데이터를 롤백 세그먼트에 저장
잘못 수정했을 때 복구할 수 있도록 백업본을 유지. -
메모리에서 레코드를 수정
UPDATE/DELETE는 메모리 상에서 먼저 처리된다.
디스크에는 아직 반영 안 됨. -
COMMIT 하면 디스크에 반영(확정 저장) 롤백 세그먼트 삭제
-
ROLLBACK 하면 변경 취소
롤백 세그먼트의 데이터를 다시 메모리로 복구
COMMIT 이후에는 ROLLBACK 불가능.
이 개념을 알아야 트랜잭션을 올바르게 운영할 수 있다.
2.2MySQL 주요 데이터 타입 설명
INT (정수)
음수 포함 정수
INT UNSIGNED
음수를 사용하지 않을 때 범위를 2배 넓힘
예: 가격, 수량, 회원번호처럼 음수가 필요 없는 필드에 추천
DECIMAL(p, s)
p = 전체 자리수
s = 소수 자리수
예) DECIMAL(10,2) → 12345678.90 같은 값 저장
VARCHAR(n)
가변 길이 문자열
실제 입력된 길이만큼 저장 → 메모리 절약
현대 DB에서는 거의 모든 문자 필드는 VARCHAR 사용
CHAR(n)
고정 길이 문자열
항상 n바이트를 차지함
예: CHAR(6)
‘M’ 저장 → M_ (공백으로 패딩)
길이가 항상 일정할 때(성별, 국가코드 등 극히 제한적 상황)만 사용
TEXT
매우 긴 문자열 (게시판 본문, 설명문 등)
DATE / DATETIME / TIMESTAMP
DATE = yyyy-mm-dd
DATETIME = yyyy-mm-dd hh:mm:ss
TIMESTAMP = timezone 포함된 시간
2.3LIKE 연산자와 정규 패턴
LIKE 기본 문법
WHERE name LIKE 'A%' -- A로 시작
WHERE name LIKE '%son' -- son으로 끝남
WHERE name LIKE '%kim%' -- kim 포함
특수문자
% : 0글자 이상
_ : 정확히 1글자
예) 이름이 정확히 5글자인 사람
WHERE name LIKE '_'
예) 성이 A로 시작:
WHERE name LIKE 'A%'
2.4SUBSTRING 함수
SUBSTRING(str, 시작위치, 길이)
SUBSTRING(str, -3) -- 뒤에서 3글자
예) 이름이 ‘son’으로 끝나는 사람
SELECT *
FROM employees
WHERE SUBSTRING(name, -3) = 'son';
2.5BETWEEN
숫자 범위, 날짜 범위 검색에 매우 자주 사용.
예) 월급 3000~5000 사이
WHERE salary BETWEEN 3000 AND 5000예) 2006년 입사자
WHERE hire_date BETWEEN '2006-01-01' AND '2006-12-31'2.6 NULL
절대 하면 안 되는 비교
WHERE manager_id = NULL -- 항상 false
✔ 정답
WHERE manager_id IS NULL
WHERE manager_id IS NOT NULL
2.7집합 함수(Aggregate Functions)
함수 설명
1.COUNT(*) 전체 행 수(널 포함)
1-1.COUNT(col) NULL 제외한 행 수
2.SUM(col) 합
3.AVG(col) 평균
4.MAX(col) 최대
5.MIN(col) 최소
6.DISTINCT (중복 제거)
예) 월급 분포를 확인할 때 사용.
SELECT DISTINCT salary FROM employees;