
- 테이블 작업의 기본 흐름: CREATE TABLE → INSERT → UPDATE (WHERE 주의)
- 정렬:
ORDER BY는 여러 컬럼을 순서대로 정렬할 수 있음 - 집계:
GROUP BY는 반드시COUNT/SUM/AVG/MIN/MAX같은 집계 함수와 함께 - 숫자 함수: CEIL / FLOOR 사용 목적과 차이 이해
- 문자 함수:
||,CONCAT,SUBSTR,INSTR로- 이름 분리, 문자열 검색, 조합 등을 구현 가능
1. INSERT 문 구조
INSERT 문에는 두 가지 방식이 있음
INSERT INTO 테이블명 (컬럼1, 컬럼2, 컬럼3)
VALUES (값1, 값2, 값3);OR
INSERT INTO 테이블명
VALUES (값1, 값2, 값3);컬럼명을 생략해도 되는 경우
값 넣을 때, NOT NULL 아닌 컬럼은 생략 가능
기본값(DEFAULT) 이 있는 경우에도 생략 가능
NOT NULL인 컬럼은 반드시 값이 들어가야 함
PRIMARY KEY 등 제약 조건도 함께 고려해야 함(PRIMARY KEY인 경우 반드시 값을 넣어야 함)
2. UPDATE 문 구조
UPDATE 테이블명
SET 컬럼1 = 값1,
컬럼2 = 값2
WHERE 조건;
UPDATE 할 때 중요한 부분
WHERE 절을 반드시 넣어야 함
안 넣으면 테이블 전체 데이터가 수정됨 (대형 사고)
3. ORDER BY 정렬
하나의 컬럼 기준 정렬
ORDER BY 컬럼명;여러 컬럼 정렬 방식
ORDER BY A, B;먼저 A 컬럼 기준으로 정렬
같은 A 그룹 안에서 B 기준으로 다시 정렬
EX)
지역 → 도시명 순서로 정렬
전화번호 앞자리 → 뒤자리 순서로 정렬
4. GROUP BY + 집계 함수
GROUP BY는 단독으로 쓰면 의미 없음.
반드시 집계 함수(Count, Sum, Avg, Min, Max) 와 같이 사용해야 함.
SELECT 지역, COUNT(*)
FROM 고객
GROUP BY 지역;집계 함수 종류
| 함수 | 설명 |
|---|---|
| COUNT() | 행 개수 |
| SUM() | 합계 |
| AVG() | 평균 |
| MIN() | 최소값 |
| MAX() | 최대값 |
| STDDEV() | 표준편차 |
| VARIANCE() | 분산 |
5. DISTINCT (중복 제거)
컬럼의 대표값(고유값)만 보고 싶을 때 사용
SELECT DISTINCT 컬럼명 FROM 테이블;
예: 고객이 사는 지역 목록만 보고 싶을 때
6. 문자열 함수
문자열 다룰 때 매우 많이 사용되는 함수들.
CONCAT (문자열 붙이기)
CONCAT(컬럼A, 컬럼B)SUBSTRING (일부 문자만 추출)
SUBSTRING(컬럼명, 시작위치, 길이);INSTR (특정 문자열 위치 찾기)
INSTR('Good Morning', 'Morning'); 찾지 못하면 0 반환.
(성/이름 분리)
예: “홍 길동”
공백 위치 찾기
SELECT INSTR(name, ' ') FROM employee;성만 추출
SUBSTRING(name, 1, INSTR(name, ' ') - 1)이름 추출
SUBSTRING(name, INSTR(name, ' ') + 1)7. 수학 함수
은행, 정산 시스템에서 자주 사용됨.
| 함수 | 설명 | 예 |
|---|---|---|
| CEIL(x) | x보다 크거나 같은 최소 정수(올림) | CEIL(3.14) → 4 |
| FLOOR(x) | x보다 작거나 같은 최대 정수(버림) | FLOOR(3.14) → 3 |
| POWER(x,y) | x^y | POWER(4, 2) → 16 |
| ROUND(x,n) | 반올림 | ROUND(3.1415, 2) → 3.14 |
고객에게 줄 때는 CEIL (고객에게 손해 안 보게 뒷자리까지 신경써서 반올림)
은행이 받을 때는 FLOOR (굳이 소수점 뒷자리 까지 안 받아먹고 반올림 안함)
이런 방식으로 실제 금융권에서 많이 사용됨.
| 개념 | 핵심 내용 |
|---|---|
| INSERT | NULL/DEFAULT 컬럼은 생략 가능 |
| UPDATE | WHERE 없으면 전체 수정됨 |
| ORDER BY | 다중 컬럼 정렬 가능 (A → B 순서) |
| GROUP BY | 집계함수와 반드시 함께 사용 |
| DISTINCT | 대표값만 추출 |
| SUBSTRING, INSTR | 문자열 자르기/찾기 |
| CEIL / FLOOR | 금융권에서 필수로 쓰는 정수 처리 |
8. 날짜(Date) 타입
MySQL 날짜 타입
타입 내용
DATE 날짜만 저장 (YYYY-MM-DD)
DATETIME 날짜 + 시간 (YYYY-MM-DD HH:MM:SS)테이블에서 흔히 보이는 create_date, update_date 같은 컬럼이 이 타입이다.
날짜는 “문자열처럼” 넣는다
UPDATE employees
SET update_date = '2025-12-08';
시간까지 넣고 싶으면:
SET update_date = '2025-12-08 14:30:00';8-2. 현재 날짜 / 현재 시간 입력
CURRENT_DATE() -- 오늘 날짜
CURRENT_TIME() -- 현재 시각
NOW() -- 날짜 + 시간
예:
UPDATE employees SET update_date = NOW();
8-3. 날짜 연산(Date Add / Date Diff)
DATE_ADD (날짜 더하기)
SELECT DATE_ADD(NOW(), INTERVAL 10 DAY);
SELECT DATE_ADD(NOW(), INTERVAL 2 MONTH);
SELECT DATE_ADD(NOW(), INTERVAL 1 YEAR);DATE_SUB (날짜 빼기)
SELECT DATE_SUB(NOW(), INTERVAL 30 DAY);날짜 차이 구하기
SELECT DATEDIFF('2025-01-01', '2024-01-01');9. IF / IFNULL / NULLIF / CASE
IF (MySQL 전용 조건문)
SELECT IF(salary >= 10000, 'HIGH', 'LOW')
FROM employees;
중첩 가능:
SELECT IF(salary >= 10000, 'HIGH',
IF(salary >= 5000, 'MID', 'LOW')) AS gradeNULL 처리 함수
IFNULL(A, B) A가 NULL이면 B 반환 IFNULL(manager_id, '없음')
NULLIF(A, B) A=B이면 NULL, 아니면 A NULLIF(col, 0)NULL 값은 일반 비교가 안 되기 때문에 이런 함수들이 중요함.
9-2. CASE WHEN (조건 분류할 때 가장 중요한 문법)
범위 체크, 다단 조건 구문에서 가장 많이 씀.
SELECT salary,
CASE
WHEN salary >= 10000 THEN 'HIGH'
WHEN salary >= 5000 THEN 'MID'
ELSE 'LOW'
END AS grade
FROM employees;CASE 문은 IF보다 장점이 많음
가독성 좋음
여러 조건 표현 쉬움
모든 SQL에서 사용 가능 (표준 문법)
10. HAVING
HAVING은 그룹화된 결과에 조건을 걸 때 사용한다.(where이랑 '비슷'하긴함) GROUP BY를 쓴후 조건을 넣고싶을때 사용
WHERE는 그룹화 전에 실행되므로 집계함수(COUNT, SUM 등)를 사용할 수 없다.
HAVING은 GROUP BY 이후 실행되므로 집계함수 조건이 가능하다.
SELECT dept_id, COUNT(*)
FROM employees
GROUP BY dept_id
HAVING COUNT(*) >= 5;
11. 임시 테이블 (Inline View)
SELECT 결과는 화면에 출력되기 전에 내부적으로 임시 테이블 형태가 된다.
이 임시 테이블은 외부 쿼리에서 다시 사용할 수 있다.
SELECT dept_id, COUNT(*) AS cnt
FROM employees
GROUP BY dept_id;12. JOIN 기본 개념
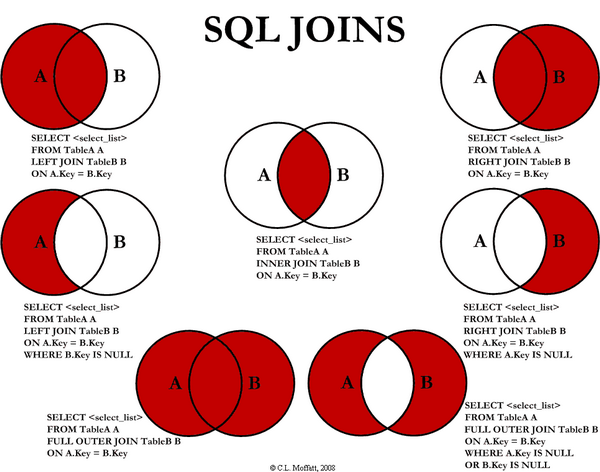
JOIN은 두 테이블을 결합하여 의미 있는 데이터를 조회하기 위한 방식이다.
기본 동작 순서는 다음과 같다.
두 테이블의 모든 조합(Cartesian Product)을 만든다.
(Cartesian Product)
카테시안 곱(곱집합)은 두 개 이상의 집합에서 각각 원소를 하나씩 뽑아 만들 수 있는 모든 가능한 순서쌍(튜플)들의 집합으로, 각 집합의 모든 원소들이 서로 짝을 이루도록 조합하여 새로운 집합을 만드는 연산이다

이 사진처럼 곱한다고 생각하면 된다.
ON 또는 WHERE 조건을 통해 필요한 행만 필터링한다.
SELECT 절에서 필요한 컬럼만 가져온다.
SELECT e.emp_name, d.dept_name
FROM employees e
JOIN departments d
ON e.dept_id = d.dept_id;13. SELF JOIN
같은 테이블을 두 번 사용하여 조인할 때 사용한다.
대표 예시는 직원과 직원의 매니저 정보를 찾는 경우이다.
SELECT e.emp_name, m.emp_name AS manager_name
FROM employees e
JOIN employees m
ON e.manager_id = m.employee_id;14. 다중 JOIN
세 개 이상의 테이블을 조인하여 더 많은 정보를 결합할 수 있다.
직원의 이름, 부서명, 직책명 등을 동시에 가져올 수 있다.
SELECT e.emp_name, d.dept_name, j.job_title
FROM employees e
JOIN departments d
ON e.dept_id = d.dept_id
JOIN jobs j
ON e.job_id = j.job_id;15. ERD (Entity Relationship Diagram)
PK(Primary Key)와 FK(Foreign Key)의 관계를 표현한 도식이다.
employees.dept_id는 departments.dept_id를 참조한다.
employees.job_id는 jobs.job_id를 참조한다.
employees.manager_id는 employees.employee_id를 참조한다.
ERD의 목적:
테이블 간 관계를 시각적으로 이해한다.
PK/FK 구조가 정확히 잡혀 있어야 조인이 깨지지 않는다.
16. PK / FK 제약 조건
Primary Key 위반
이미 존재하는 값을 넣는 경우
NULL을 넣는 경우
예:
INSERT INTO dept(id) VALUES(10);
(10이 이미 존재한다면 에러 발생)
Foreign Key 위반
참조하는 테이블에 없는 값을 넣는 경우
예:
INSERT INTO employees (name, dept_id)
VALUES ('홍길동', 999);
(dept_id 999가 departments에 없으면 에러 발생)
FK를 설정하는 이유:
잘못된 데이터 입력을 방지
조인할 때 항상 정확한 매칭이 가능하도록 보장

댓글