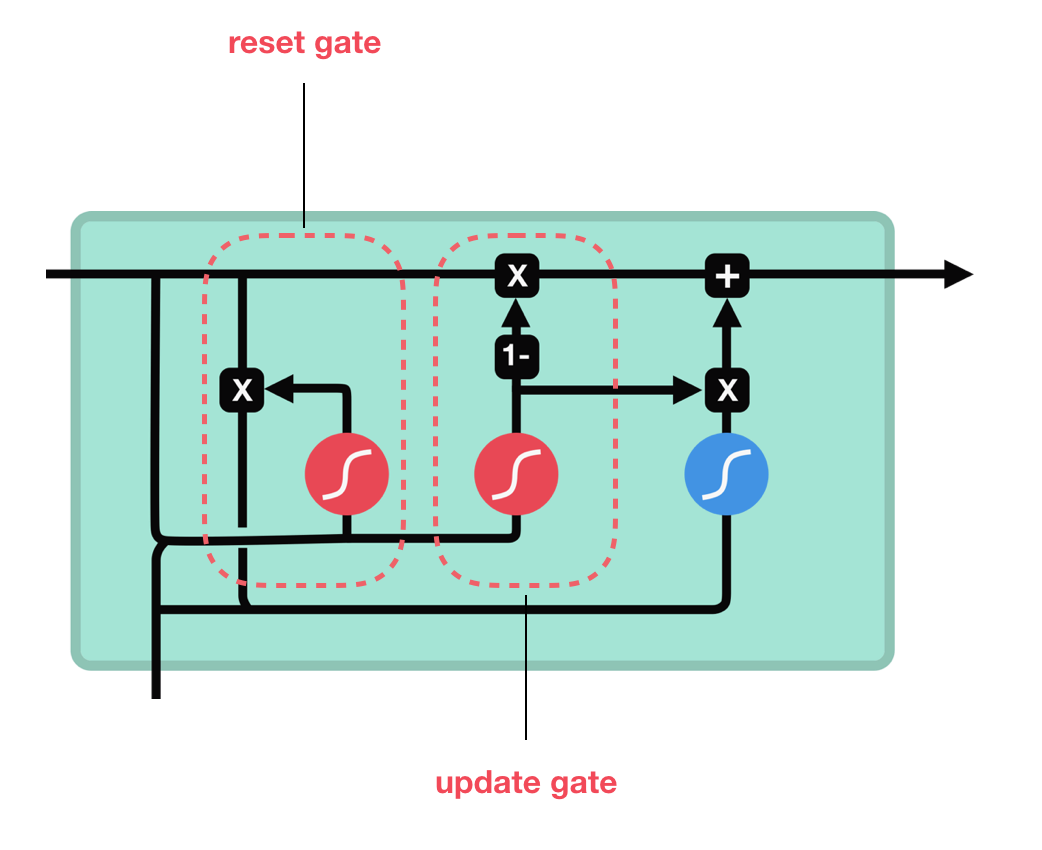
1. GRU 개념
2. Library
!pip install unidecodeimport torch
import torch.nn as nn
import unidecode
import string
import random
import re
import time, math2. Data
1) character 가져오기
!rm -r data
import ostry:
os.mkdir("./data")
except:
pass!wget https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/tinyshakespeare/input.txt -P ./dataall_characters = string.printable
print(all_characters)
# 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
n_characters = len(all_characters)
print(n_characters)
# 1002) text data 가져오기
유니코드 문자열을 ASCII로 변환하는 코드
file = unidecode.unidecode(open('./data/input.txt').read())
file_len = len(file)
print('file_len =', file_len)
print(type(file)) # class str3. Functions for text processing
1) Random Chunk
chunk_len = 200
def random_chunk():
start_index = random.randint(0, file_len-chunk_len)
end_index = start_index+chunk_len
return file[start_index:end_index]
print(random_chunk())2) Character to Tensor
def char_tensor(string):
tensor = torch.zeros(len(string)).long()
for c in range(len(string)):
tensor[c] = all_characters.index(string[c])
return tensor
print(char_tensor('ABCdef'))3) Chunk into input & label
def random_training_set():
chunk = random_chunk()
input = char_tensor(chunk[:-1])
label = char_tensor(chunk[1:])
return input, label, chunk[1:]4. Model & parameters & optimizer
1) parameters
num_epochs=2000
print_every = 100
plot_every = 10
hidden_size = 100
batch_size = 1
num_layers = 1
embedding_size = 70
lr = 0.0022) Model
class RNN(nn.Module):
def __init__(self, input_size, embedding_size, hidden_size, output_size, num_layers=1):
super(RNN, self).__init__()
self.input_size = input_size
self.embedding_size = embedding_size
self.hidden_size = hidden_size
self.output_size = output_size
self.num_layers = num_layers
self.encoder = nn.Embedding(self.input_size, self.embedding_size)
self.rnn = nn.GRU(self.embedding_size, self.hidden_size, self.num_layers)
self.decoder = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, hidden):
# chat_tensor(): A -> [36]
# input.view(1,-1): [36] -> [[36]]
# encoder(): [[36]] -> [[[, , , , , , ]]] (1,1,70)
out = self.encoder(input.view(1,-1))
# hidden [[[,,,,,]]] (num_layers, batch_size, 100)
# rnn(): (1,1,100) -> (1,1,100), (1,1,100)
out, hidden = self.rnn(out, hidden)
# out.view(1,-1): (1,1,100) -> (1,100)
# decoder(): (1, hidden_size) -> (1, n_characters)
out = self.decoder(out.view(batch_size,-1))
return out, hidden
def init_hidden(self):
hidden = torch.zeros(self.num_layers, batch_size, self.hidden_size)
return hidden
model = RNN(n_characters, embedding_size, hidden_size, n_characters, num_layers)2.1) model Test
input = char_tensor("A")
print(input) # tensor([36])
hidden = model.init_hidden()
print(hidden.size()) # (1,1,100)
out, hidden = model(input, hidden)
print(out.size())3) Loss & Optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
loss_func = nn.CrossEntropyLoss()4) Test function
def test():
hidden = model.init_hidden()
# 시작 문자 랜덤으로 잡기
start_str = "b"
input = char_tensor(start_str)
x = input
print(start_str, end="")
for i in range(chunk_len):
output, hidden = model(x, hidden)
# .view(-1): 1D 벡터로 평탄화
# .div(0.8): 0.8로 원소들 나누기
# .exp(): e의 지수승으로
output_dist = output.detach().view(-1).div(0.8).exp()
# torch.multinomial() 다항분포로부터 sampling
# output_list: [e1, e2, e3, ..., en] 은 확률로 해석될 수 있는 tensor
# num_samples: sampling할 갯수
# sampling된 index 값이 반환.
top_i = torch.multinomial(output_dist, num_samples=1)[0]
# 예측된 문자
predicted_char = all_characters[top_i]
print(predicted_char, end="")
x = char_tensor(predicted_char)5. Train
for i in range(num_epochs):
# random한 chunk 가져오기
input, label, label_string = random_training_set()
# recurrent할 hidden vector 초기화
hidden = model.init_hidden()
# loss tensor 정의
loss = torch.tensor([0]).type(torch.FloatTensor)
optimizer.zero_grad()
for j in range(chunk_len-1):
x = input[j]
y_ = label[j].unsqueeze(0).type(torch.LongTensor)
y, hidden = model(x, hidden)
loss += loss_func(y, y_)
loss.backward()
optimizer.step()
if i % 100 == 0:
print("\n", f"{i}번째 문자 당 평균 {(loss/chunk_len).detach().item()}", "\n")
test()
print("\n********************")
print(label_string)
print("\n", "="*100)
Don't hesitate!