1. 서론
RNN, LSTM과 GRU는 sequence modeling과 transduction(기계번역, 언어 모델링)에서 SOTA model이었다. 많은 노력으로 recurrent language model들과 encoder-decoder 구조에 행해지고 있다.
Recurrent model들은 보통 input과 output sequence들의 symbol position에 따라 계산이 고려되었다. 계산 시간의 step에 따라 위치를 정렬하는데, model들은 hidden states인 를 생성한다. 본질적으로 순차적인 특성으로 인해 training example에서 paralleization(병렬화)는 불가능하며, memory constraint가 example에 따라 메모리 제약으로 인해 일괄 처리가 제한되므로 이는 sequence length가 길이가 길수록 안 좋은 영향을 미친다.
최근 연구는 factorization trick과 conditional computation를 통해 계산 효율의 향상시키고 있다. 하지만 sequential computation의 한계는 여전하다.
Transformer는, 모델 아키텍쳐는 recurrence(되풀이)를 피하고 대신 global한 의존성을 input과 output 사이에 지니기 위해 전체적으로 attention mechanism에 의존한다.
결과적으로 더 많은 pallerization P100 GPU 8대로 12시간 학습 후 번역 품질에서 SOTA모델로 등극했다.
2. Model Architecture
encoder: input sequence의 symbol 표현인 -> 연속 값의 sequence 로 변환.
decoder: 가 주어졌을 때, output sequence 생성한다.
각 step의 모델은 auto-regressive(자동회귀)일 때, 이전 생성된 symbol들은 다음 생성 시 추가적인 input으로 사용된다.
Transformer 전체 구조
- self-attention, point-wise를 쌓은 block
- 양쪽
encoder와decoder를 위해 fully connect layer
2.1 Encoder과 Decoder Stack
Encoder
encoder는 6개의 동일한 layer 쌓임.
- 각 layer는 2개의
sub layer를 가짐.
1.multi-head self-attentionmechanism
- residual connection 적용
- layer normlization
2. feed-forward network와 연결된position wise
- residual connection 적용
- layer normlization
- 즉 각
sub-layer는 - 모든 sub-layer는 residual 연결이 가능하기 위해 embedding layer뿐만 아니라, 가 output 차원이다.
Decoder
3.2 Attention
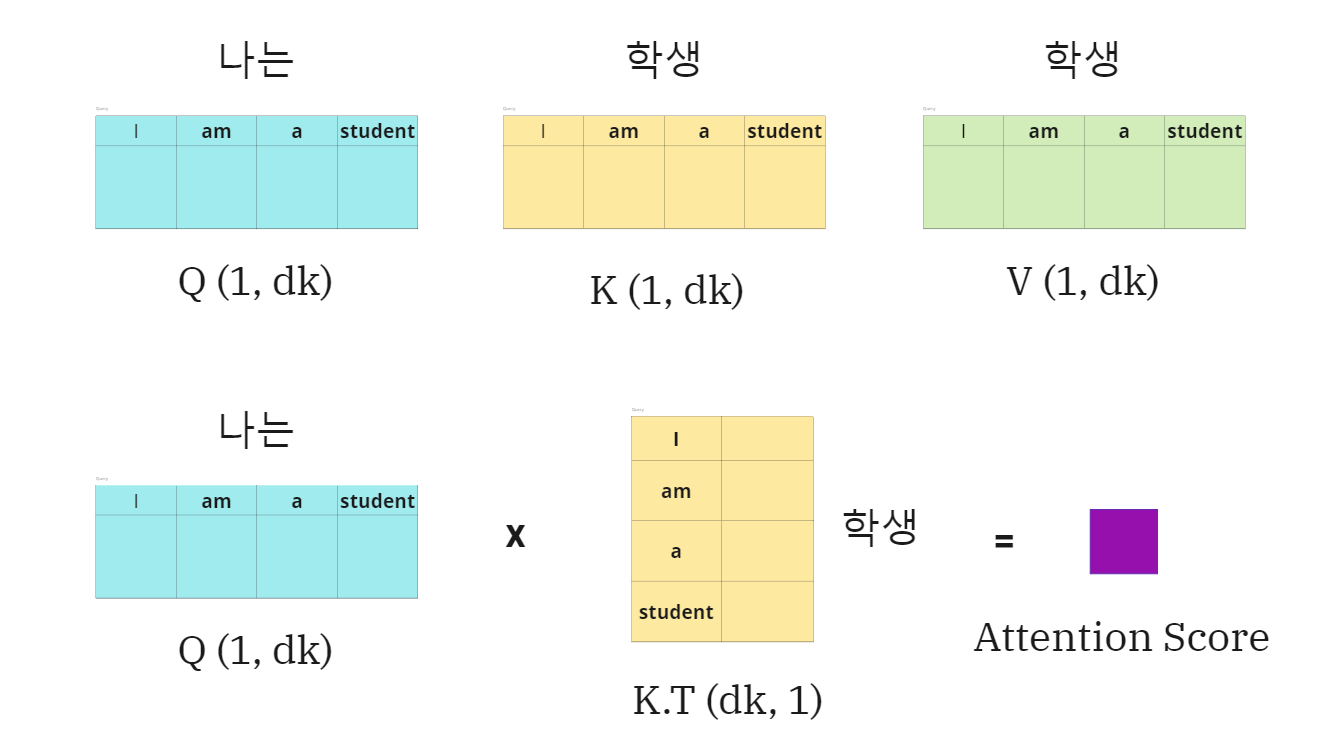
I am a student에서 student의
- Query: 각 단어의 연관성을 물어보는 주체(student)
- Key: 각 단어(I, am, a)
- Value:
attention 함수는 query, key-value 쌍 set을 output으로 맵핑(모두 vector인)
output은 key에 대응되는 query의 compatibility fuction에 의해 계산된 각 value()에 할당된 weight()의 합으로 계산된다.
3.2.1 Scaled Dot-Product Attention
input은 차원이 인 query, key들과 차원이 인 value로 구성됨.
1. 모든 key와 query의 내적 곱을 계산
2. sqrt()로 나누기
3. value에서 weight를 구하기 위해 softmax 함수 통과
실제로, Q는 query들이 묶인 행렬이다. key는 K, value는 V.
가장 일반적으로 사용되는 attention function에서 추가된 점.
1. additive attention
- feed-forward network를 사용하여 compatibility 함수 값을 계산.
2. dot-product attention (multiplicative)
- scailing factor가 추가됨.
이론적으로 2개가 동등한 복잡도이지만, dot-product attention이 실제로 빠르고 공간효율성 높음. 최적화된 행렬곱 연산 코드 때문에. Additive Attention은 Q와 K 사이의 선형 결합으로 계산하여 학습을 통해 가중치를 조절.
가 작을 때는 두 개 mechanism이 비슷한데,
더 큰 값에 대한 scaling이 없다면 additive attention이 dot product attention을 성능을 능가함. 그 이유를 분석하면 의 큰 값에 대해 내적의 크기가 커짐으로 softmax가 gradient vanishing 영역으로 감.
이 효과를 피하기 위해, 로 나눠줌.
- 내적을 커지는 이유를 설명하기 위해 q,k의 성분이 평균이 0이고 분산이 1인 독립랜덤변수라고 가정하자.
- 그러면 dot product = 는 평균이 0이고, 분산은 이다.
Example
I am a student, =4
-
나는이 query이고학생이 key:value일 때 연산 그림
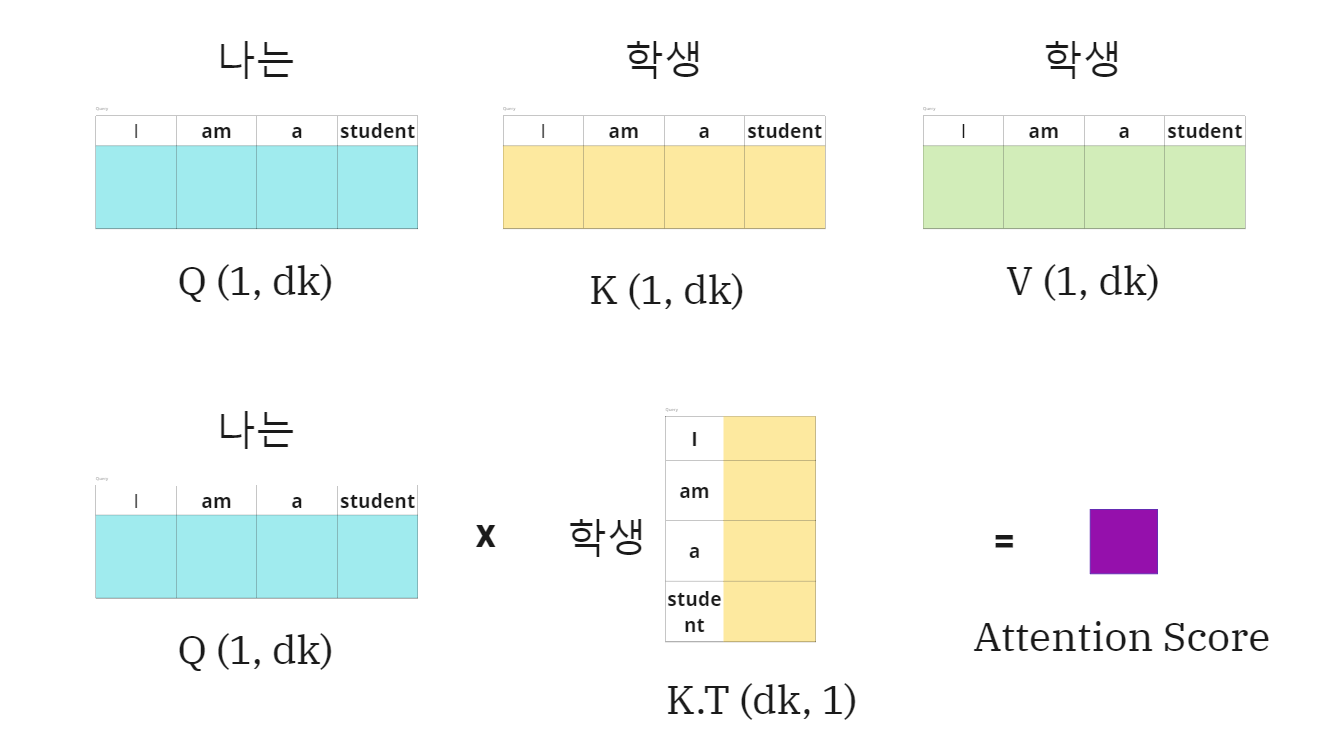
-
나는이 query이고 key:value가 [나는,학생,입니다]일 때,
나는(query)에 대한 Attention 값을 구하는 그림
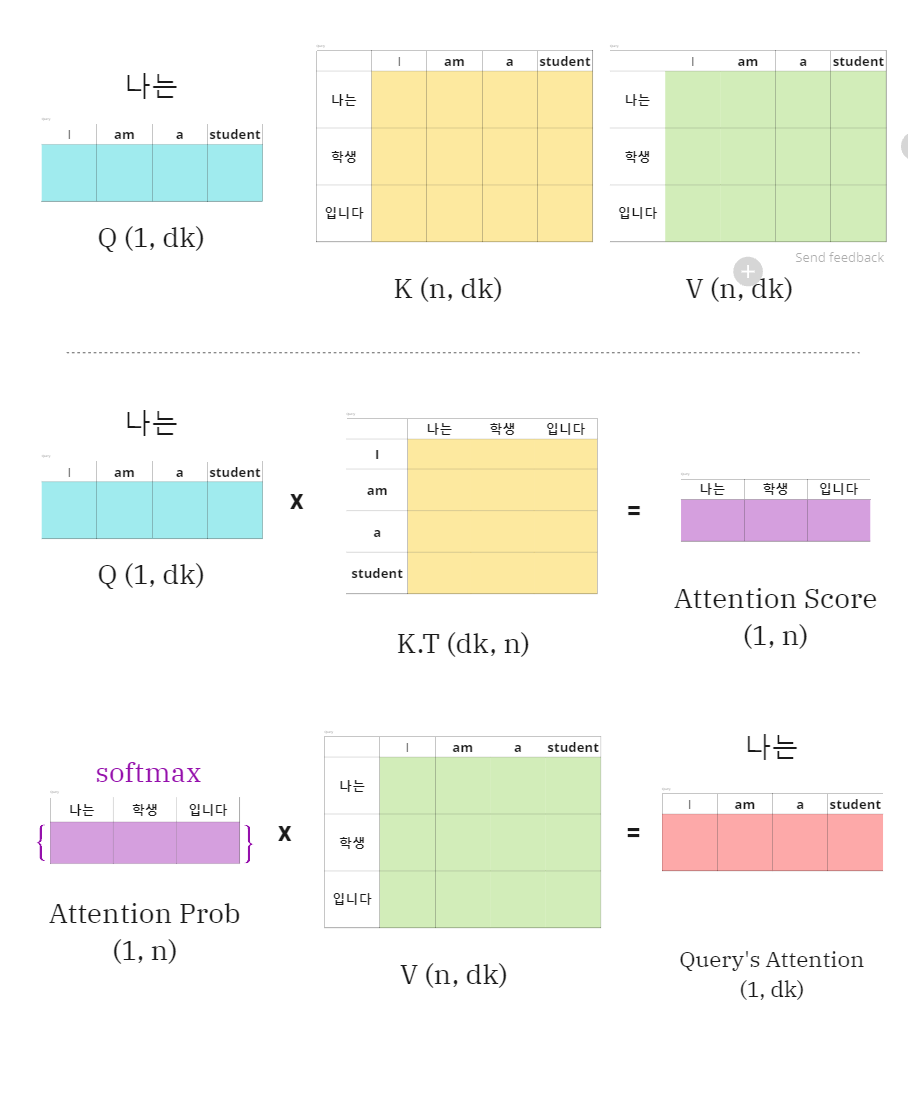
-
query가 [
나는,학생,입니다]가 모인 set여서 한번에 query에 대한 Attention 값을 구하는 그림
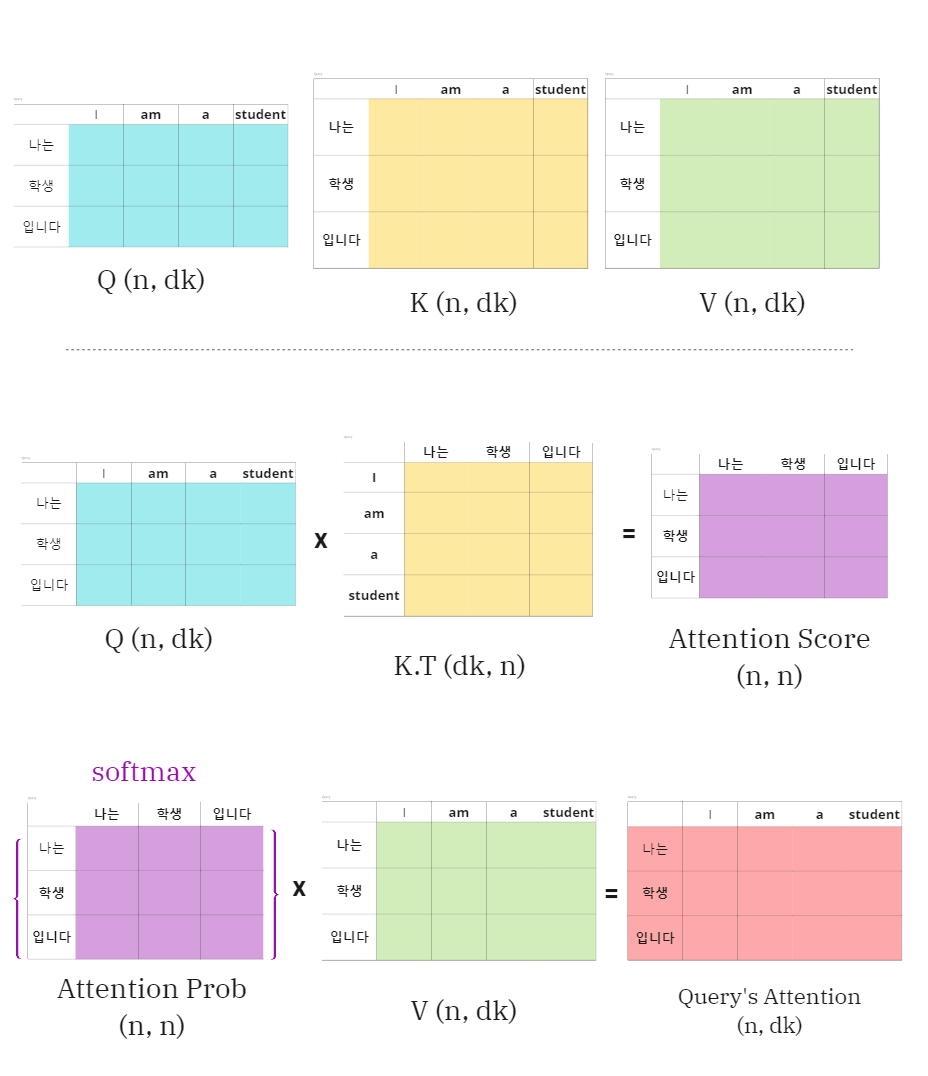
Q에 대해 Attention의 차원은 처음과 같은 결과를 볼 수 있음.
- , scalar 값.
- scaling은 로 해줌.
- 함수 통과 후 행렬과 곱함.
3.2.2 Multi-head attention
인 keys, values와 queries를 사용하여 single attention 함수를 수행하는 대신,
h개의 다른 keys, values와 queries 각각 서로 다른 학습된 차원으로 linearly project하는 것이 유익하다.
queries, keys와 values의 project된 version에 병렬적으로 attention function을 수행한다. 차원 출력 값을 생성. 이것을 연결해서 붙이고 다시 projected하면 최종 값이 나온다.
model이 서로 다른 표현 subspace의 정보에 함께 참여할 수 있다. 위치. 즉 single attention head를 사용하면 평균화가 이를 억제.
projection으로 쓰이는 parameter 행렬 차원
- → ()
- → ()
- → ()
- → (d{hv}, d{model})$
3.3 Position-wise Feed-Forward Networks
encoder와 decoder에서 각 layer는 각 위치에 개별적으로 동일하게 적용되는 fully connected feed-forward network를 포함. 이는 ReLU activation 사이에 2개의 선형 변환이 포함.
선형변환은 다른 위치에서 서로 동일하지만, layer에서 layer일 때 다른 parameter들을 사용한다. 이것은 마치 kernel size=1의 convolution 연산을 2번 하는 것이다.
input과 output의 차원은 이고 inner-layer는 차원이다.
