10281150AM저장
출처& 참고 강의: 한경훈님
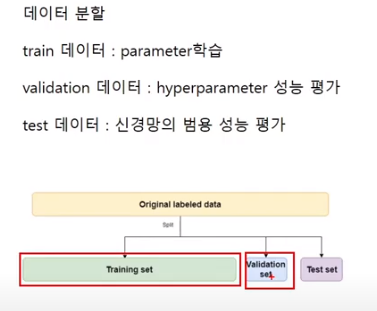
Parameter vs Hyperparameter
Parameter: 머신이 학습하는 값 from data (인간이 개입 x)
if 데이터 many, 신경망 모델 good, 머신 두 for self
-데이터 찾기 쉽지 않지만 찾아 놓으면 머신이 알아서 하니까 쉬움
Hyperparameter : 인간이 결정하는 값
ex) learning rate, 훈련 회수, 가중치 초기값 등등
-손이 많이 감 (여러 값 직접 시도 해야 함) but 몇개는 추천 or고정 되어있긴 함.
ex) 최적의 learning rate 찾기 위해 이 하이퍼파라미터 튜닝을 반복
그러니까 train 에서는 파라미터 사용.
validation 에는 하이퍼파라미터 썼으니까. v데이터도 믿을 수 x. 그래서 이제 한번도 쓰지 않은 test 데이터로 성능을 써야지 믿을만한 지표가 되는 것.
하지만 데이터가 충분하지 않으면 어떻게 하냐..?
train/val/test/ 로 3분할 하기엔 너무 적다..!
.
차선책 is
.
K-fold validation
train 데이터를 K-등분
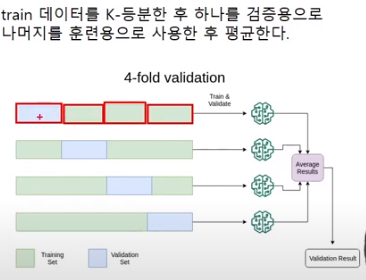
Hyperparameter 탐색

랜덤 >>그리드(초창기에 많이 씀) 이라고 밝혀짐
Why? : 하이퍼파라미터는 각각 중요도 차이가 크다.
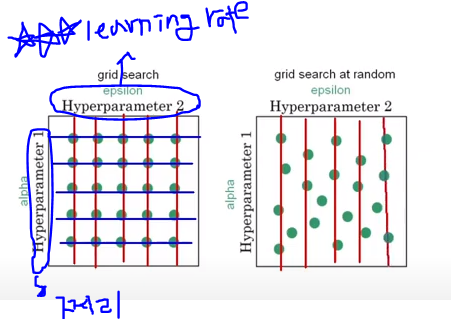
결정해야 할 hyperparameter 많은데, 그중에서 learning rate(굉장히 중요💎) 그런데, 그리드에서는 쩌리랑 같이 위 그림 처럼 5개씩 동일하게 찾아짐.
하지만 랜덤을 쓰면 오른쪽 처럼 중요도 높은 러닝 레이트를 많이 찾음.

그래서 이런식으로 줌인하면서 train/val 반복.>> 그다음 test
Like 범죄 용의자 찾기, 용의자 풀을 계속 좁혀 나감.

K-means,K-fold,, K개..등등
그런데 왜 K를 쓰나요..?
K--?? Korea..?
동기님께서 답변 해주심 ❤
수학에서 보통 임의의 정수를 k로 표현하는데.
k가 정수를 뜻하는 constant의 첫 글자의 발음처럼 들려서 쓴다고 합니다. c는 쓰이는 데가 이미 많아서 k를 쓰는 거 같네요. (아하..!)
오전 개념 정리
최적화란 (머신러닝 링고) : 훈련 데이터로 학습 시키는 것 (하이퍼파라미터 튜닝해서)
일반화 : 새로운 데이터에도 잘 예측하게 하는 것
AI /머신러닝/딥러닝 의 벤다이어 그램을 그리면?
:AI > 머신러닝 > 딥러닝

Grid: 범위 내 조합을 다~ 검증
Random: 범위 내 조합 무작위로 검증
장단점 (면접에 자주 나오는 질문)
우리는 항상 제한된 리소스를 가지고 있음.
그리드: 리소스가 많이 듬/하이퍼파라미터 지정이 애매할때
랜덤: 빠름/어떤 하이퍼파라미터가 영향력있는지 아직 애매할때 이걸 쓰는 게 좋음.
츄라이를 많이 하는게 실력 향상에 도움이 된다..!
