1. 서설
엔터티를 대표하는 속성(업무 식별자)을 찾은 후에 , 대상 속성이 종속이 됐는지 여부를 판단해야 한다.
2. 정규화란? 📕
- 업무 요건에 필요한 속성을 묶어서 엔터티를 설계하는 것
- 부정확한 종속성을 없애는 것
3. 함수 종속
📚 데이터 종속성 : 정규화를 수행하는 도구이지만 검증의 도구이기도 하다.
- 함수 종속
- 다가 종속 : 같은 종류의 값을 여러개 가지는 속성
- 조인 종속
- 파생 종속
함수 종속이란?
- 릴레이션 내에 존재하는 속성 간의 종속성을 분석해 집합을 분리하기 위한 것
- 업무 요건에 종속된다.
- 집합이 잘 분해됐는지 좋은 모델을 구별하는 기준이 된다.
4. 결정자와 종속자
결정자(Key) : 종속성을 분석 할 때 기준
종속자(Non-Key) : 결정자의 값에 의해 정해질 수 있는 값
- X -> Y : 속성 Y가 속성 X에 함수적으로 종속된다 = X의 값을 이용해 Y의 값을 유일하게 식별 할 수 있다.
ex) 주민등록번호 (결정자), 이름, 휴대전화번호, 주소 - X -> Y -> Z : 이행종속
X,Y,Z를 하나의 엔터티로 포함하면 안된다. X->Y / Y->Z 로 설계해야하며 3정규형과 관련된다.
5. 함수 종속과 폐포
🤔Q. 폐포는 무엇을 의미하는가?
-> 부분 집합을 포함하는 가장 작은 닫힌집합?
- 키가 아닌 모든 속성은 키에 직접 종속되도록 분해하는 것이 정규화이다.
- R{A,B,C,D,E} 의 함수 종속이 A->C / B->D / A,B->E 일 때
폐포는 A+ = A,C / B+ =B,D /(A,B)+=A,B,C,D,E
6. 함수 종속과 정규화
정규화 방법
- 정규화는 함수 종속에 의해 수행된다.
- 릴레이션 키 도출 -> 도출 후 2,3정규화
- 릴레이션에 존재하는 모든 함수 종속 도출
7. 비정규화
- 비정규형이더라도 정규화 과정을 거쳐서 정의가 되었는지 확인되어야 한다.
8. 등산과 정규화
등산 : 정규화
하산 : 비정규화
9. 정규화의 장점
1. 완정성
- 중복 데이터 제거로 인한 아노밀라 방지
- 데이터 무결성이 높아지며 품질이 좋아진다.
- 데이터 안정성과 신뢰도가 높아진다.
2. 확장성
- 데이터의 성격에 맞는 엔터티가 설계된다.
- 정체성이 반영된 모델 구조에서는 업무가 수정되거나 추가돼도 엔터티의 반영이 쉽다.
10. 아노말리(Anomaly)
- 데이터 무결성에서 가장 피해야 할 부분이다.
- 중복데이터로 인한 의도하지 않은 현상 (일부만 처리되는 경우)
- 정규화로 처리하지 않더라도 어플리케이션에서 처리 해주는 경우가 있다.
11. 정규형의 종류
📚 정규형
- 1정규형
- 2정규형
- 3정규형
- 보이스코드 정규형(BC 정규형)
- 4정규형
- 5정규형
- 모델링은 위의 순서대로 진행되는 것만은 아니다.
- 함수 종속에 의해 3정규형이나 BC정규형이 바로 도출 될 수 있다.
- 하지만 정규형은 일종의 체계를 의미하므로 , 3정규형이 되었다는 것은 1,2 정규형도 만족하는 것을 의미한다.
12. 1정규화와 원자 값
📕 1정규화 : 모든 속성이 반드시 하나의 값을 가져야 한다.
다가 속성
- 모델로만 봐서는 다가속성을 구별하기 어렵다. 반드시 값을 봐야 알 수 있다.
[고객] 테이블의 #고객번호, 고객명, 주민등록번호, 취미코드가 있는 경우 취미코드가 여러개 일 때
[고객취미]로 정규화를 해야 한다.
복합 속성
-
하나의 속성이 여러개의 속성으로 분리 될 수 있을 때를 의미한다.
-
업무에 의해 판단이 달라 질 수 있다.
[고객] 테이블의 #고객번호, 고객명, 전화번호, 주소로 있을 때
주소를 시/구/동/번지로 데이터를 관리하면 복합속성이다.
주소에서 동 데이터를 자주 사용한다면
[주소] 주소(시), 주소(구), 주소(동), 주소(번지) 로 속성을 늘린다. -
날짜(년/월/일)가 대표적인 복합 속성이다.
13. 1정규화 대상
📚
- 다가 속성 사용
- 복합 속성 사용
- 유사 속성이 반복 사용
- 중첩 사용 : 주 식별자가 존재하면 2정규형 위배, 주 식별자가 존재하지 않으면 1정규형 위배
- 동일 속성이 여러 릴레이션에 사용
14. 1정규형과 비정규형
- 업무 요건에 따라 비정규형을 만들 수도 있지만 되도록이면 정규형을 만들도록 하는 것이 원칙이다.
- 이 부분은 미래까지 고려해야 한다.
- 그래도 비정규형을 사용하려면, 성능 문제가 생겨야 하고, 현재의 업무 요건이 불변이어야 한다.
- 비정규형은 하위 엔터티를 관리하기 거의 불가능해진다.
15. 반복 속성으로 인한 1정규형 위반 사례
1. 속성 명 뒤에 숫자를 붙히는 경우
ex) 상품번호 1, 주문수량 1, 상품번호 2, 주문수량 2
-> 숫자가 같은 속성은 같이 사용되므로 쌍을 맞춰서 관리해야 한다.
- 여러 속성이 묶여서 반복되었다는 것은 일대 다를 의미한다 (1:M)
2. 하나의 속성이 반복되는 경우
- 하나의 속성이 반복되는 경우이다.
ex) [고객] #고객번호 , 고객명, 전화번호1, 전화번호2, 전화번호3
-> [고객] #고객번호, 고객명, 지역전화번호,국전화번호,개별전화번호
16. 2정규화
주식별자가 2개 이상인 릴레이션에서 생긴다.

17. 2정규화 위반인가?
- 속성 명이나 엔터티 명을 잘못 사용해 의도한 것과 다르게 모델을 설계하는 경우도 주의해야 한다.
18. 3정규화
식별자가 아닌 일반 속성 간에 종속성이 존재해서는 안된다. = 이행 종속 속성을 없애야 한다.
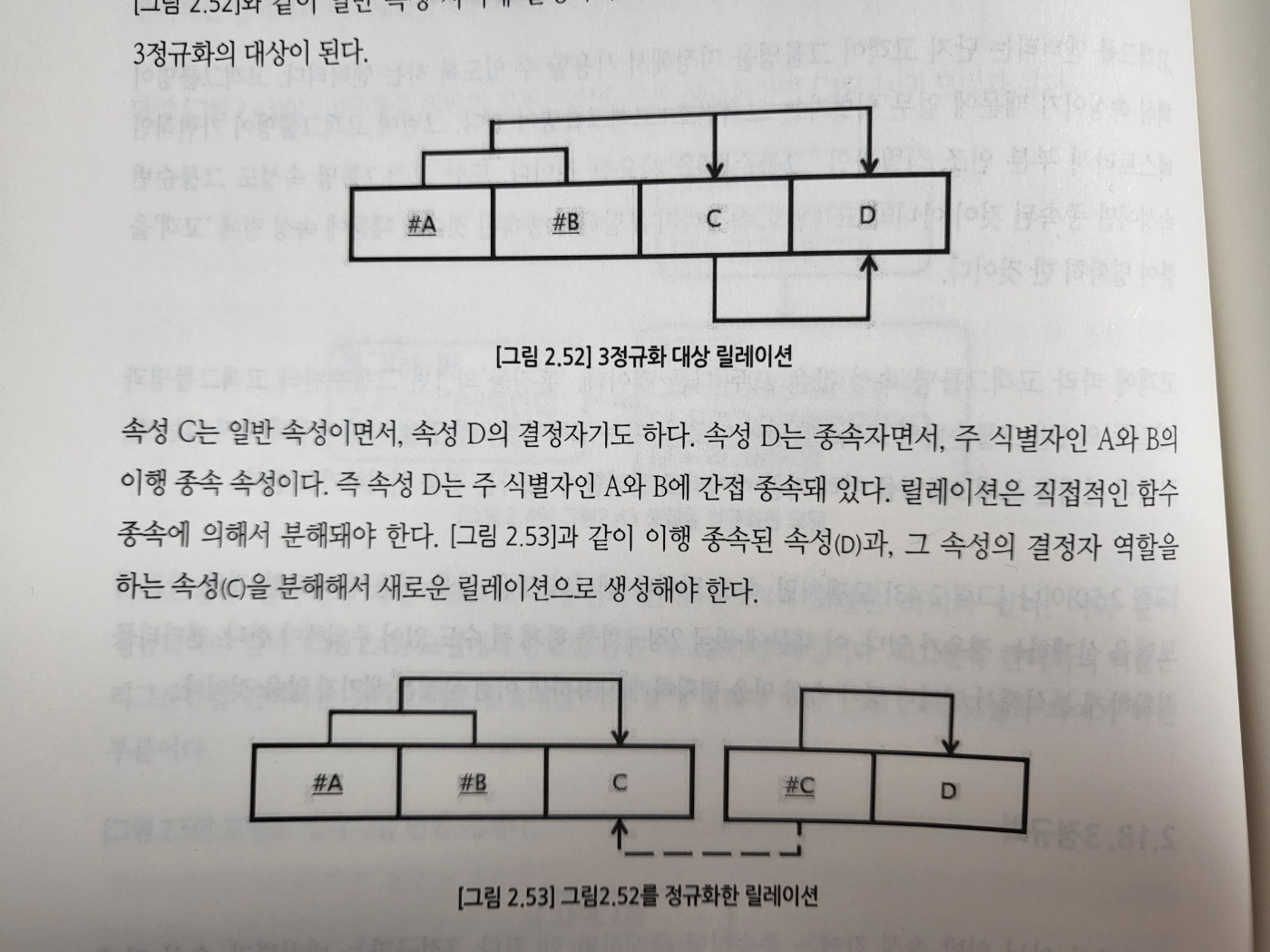
19. BC정규화
3정규형을 보강한 정규형으로 모든 결정자는 주 식별자여야 한다.
3정규형과 구분되는 점은 릴레이션에 존재하는 종속자는 후보 식별자가 아니어야 한다고 정의 할 수 있어야 한다.
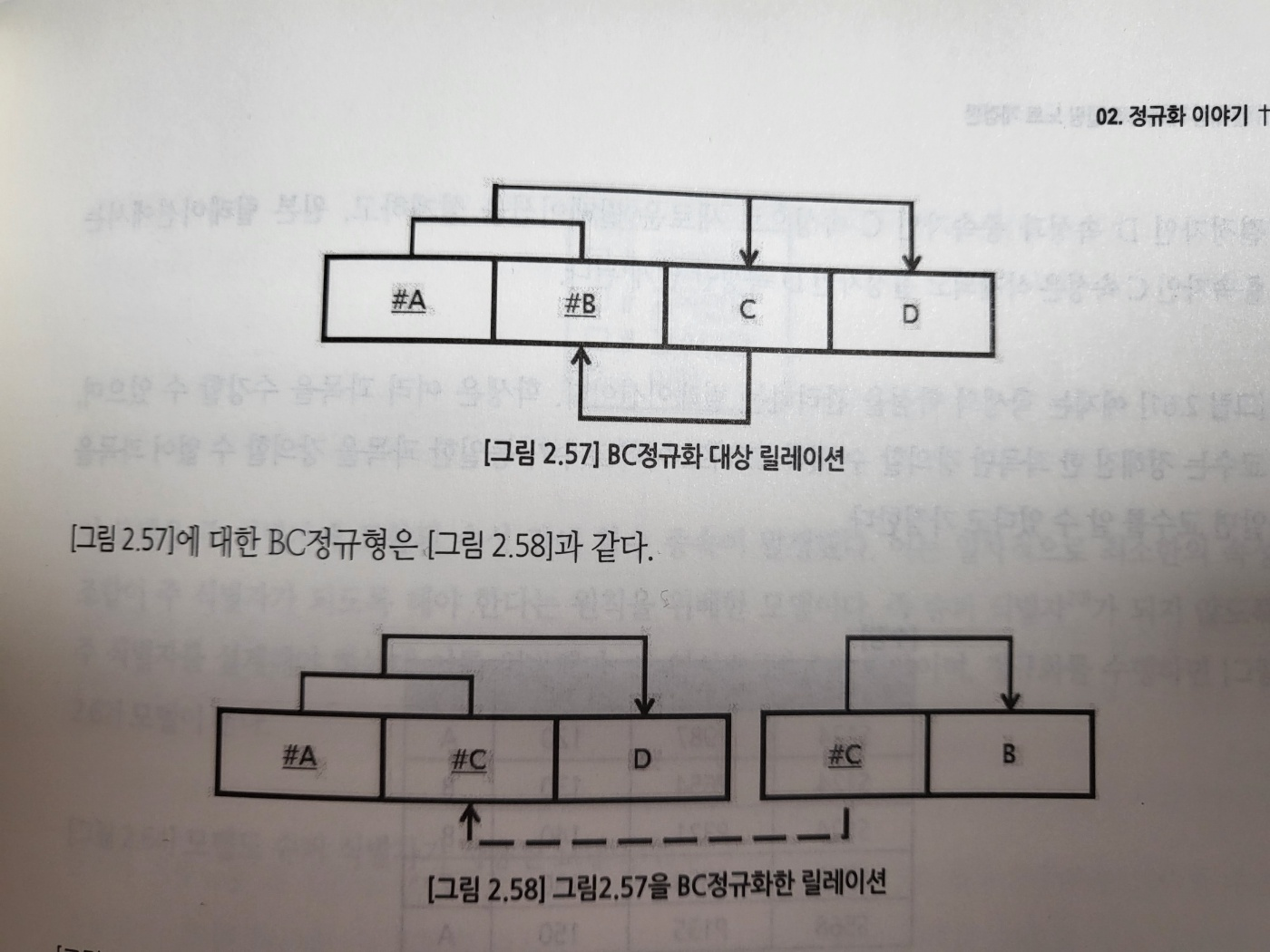
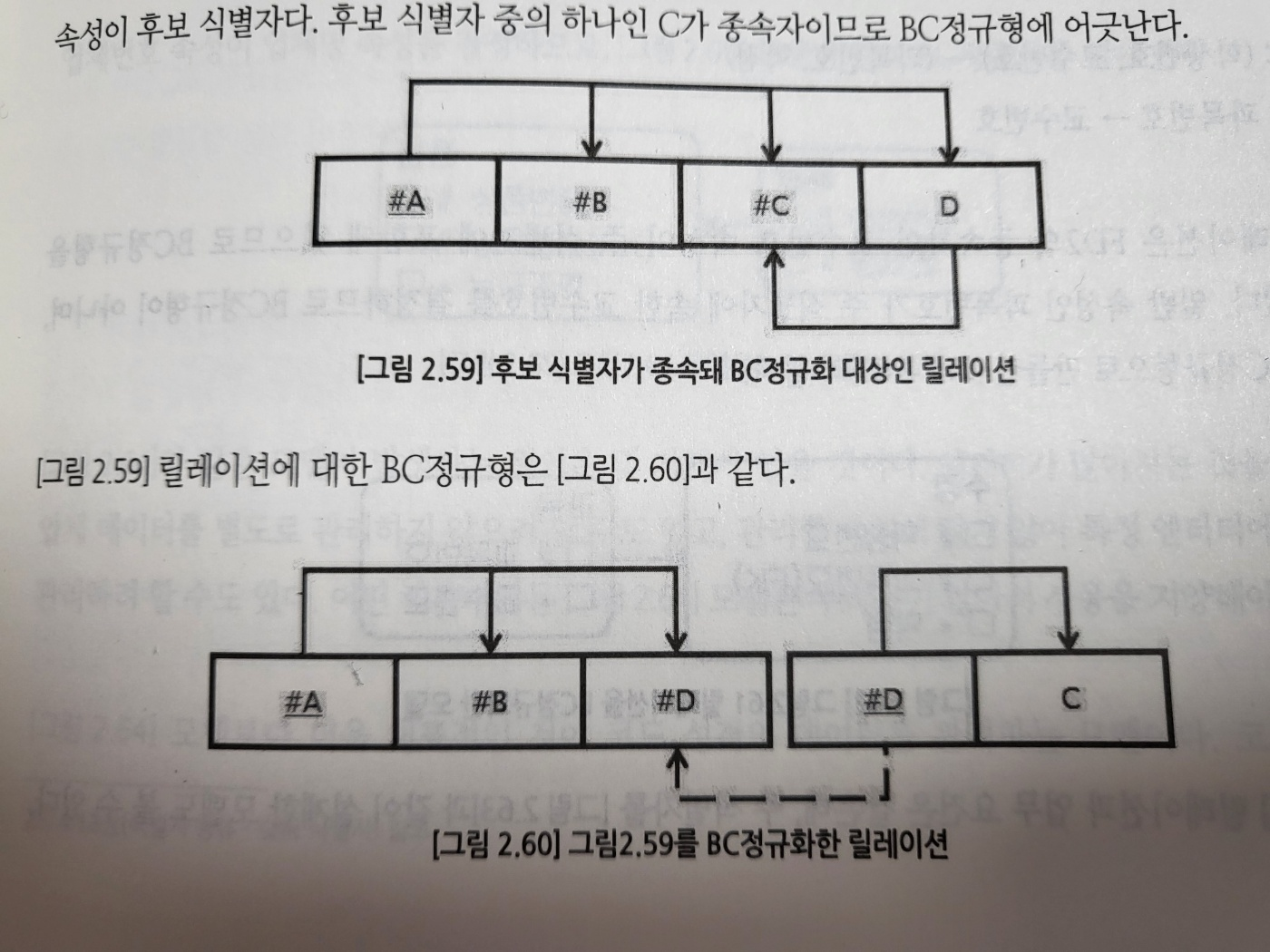
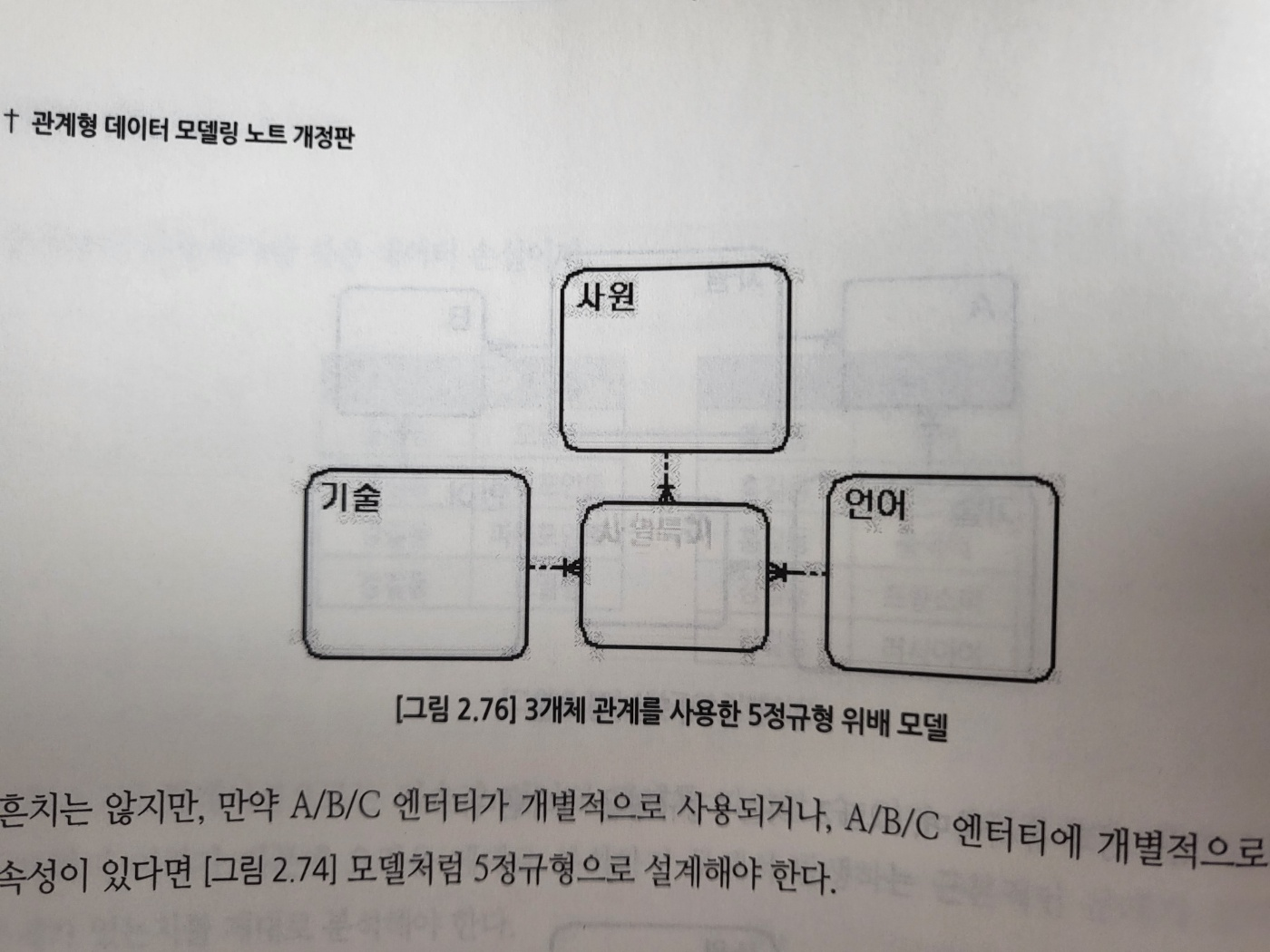
20. 4정규화
다가 종속 개념이 기반이 되는 정규형이다. (M:M)
#사원, #기술, #언어 3가지가 존재 할 때 사원+기술+언어가 아닌 사원+기술 / 사원+언어로 구분하는 것이 4정규형이다.
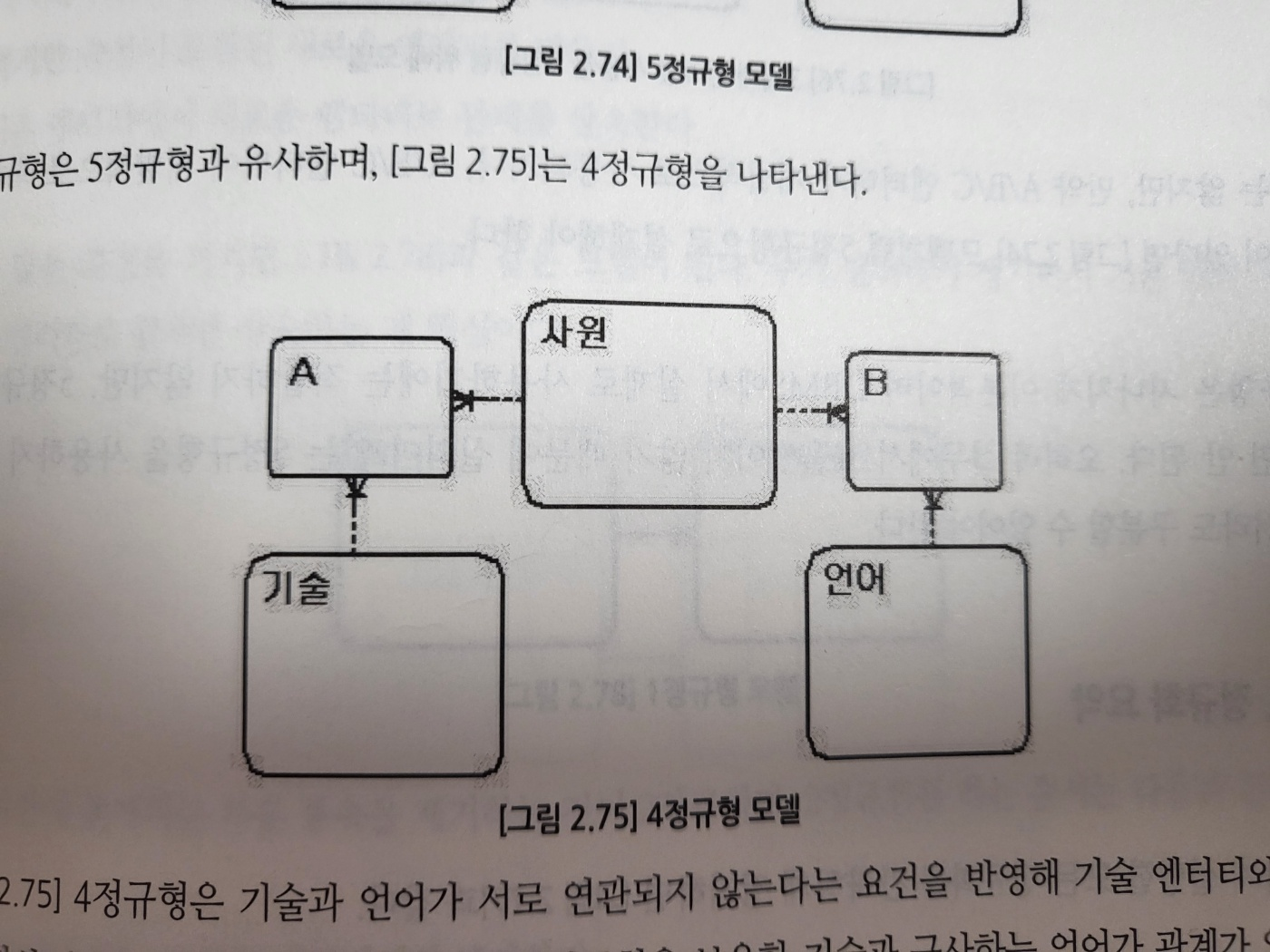
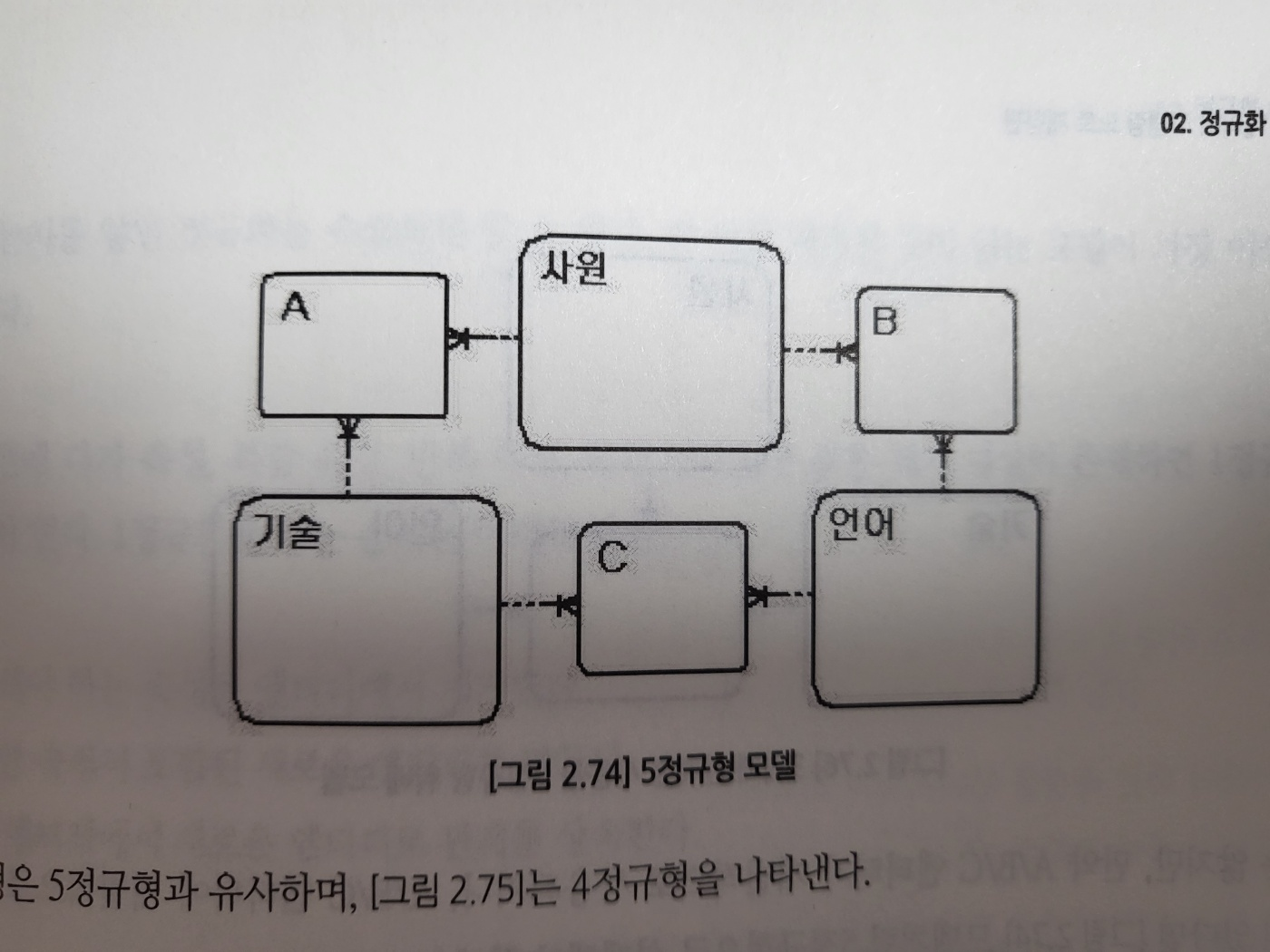
21. 5정규화
조인 종속 개념이 기반이 되는 정규형이다
위의 사원+기술+언어에서 사원+기술 / 사원+언어 / 기술+언어로 분해하는 것이 5정규형이다.
- 오히려 중복 성격이 데이터가 생기고 엔터티가 늘어난다.
- 어차피 조인해야 하기 때문에 실익이 없다.
22. 정규화 요약

1정규화
- 제거해야 하는 속성을 엔터티에서 제거
- 제거한 속성이 포함된 새로운 엔터티 생성
- 기존 엔터티에서 새로운 엔터티로 관계 상속
2정규화
- 제거해야 하는 속성 엔터티에서 제거
- 제거한 속성이 포함된 새로운 엔터티 생성
- 새로만든 엔터이에서 기존 엔터티로 관계(식별관계)를 상속
3정규화
- 제거해야 하는 속성 엔터티에서 제거
- 제거한 속성이 포함된 새로운 엔터티 생성
- 새로만든 엔터이에서 기존 엔터티로 관계(비식별관계)를 상속
BC정규화
- 후보 식별자 속성 중 종속자 속성을 엔터티에서 제거
- 제거한 속성과 그 속성의 결정자 속성을 새로운 엔터티로 생성
- 새로 만든 엔터티에서 기존 엔터티로 관계 상속
4정규화
- 제거해야하는 대상인 다가 종속에 포함된 속성을 엔터티에서 제거
- 제거한 속성이 포함된 새로운 엔터티를 다가 속성 개수만큼 생성
- 기존 엔터티와 새로 만든 엔터티와의 교차 관계 엔터티 생성
23. 3정규화까지만 수행하면 된다?
- 3정규화까지 적용하면 대부분의 중복을 해결 할 수 있기 떄문이다.
- BC정규화는 슈퍼 식별자와 연관되어 있기에 수행하지 않는다면 데이터 아노말리가 생길 수 있다.
- 4정규화는 업무 요건과 연관되어 있기 때문에 반영이 필요하다.
24. 정규화와 성능
- 성능적인 부분에서 비정규화를 고려 할 수 있다.
- 하지만 비정규형이 정규형보다 성능이 좋아진다는 보장은 없다.
