Vanila recurrent neural networks

- 지금까지 배운 아키텍쳐들은(Vanilla Neural Network)위와 같은 모양의 구조
- 네트워크는 이미지 또는 벡터를 입력으로 받는다.
- 입력 하나가 Hidden layer를 거쳐서 하나의 출력을 내보낸다.
(Classification 문제 = 카테고리)
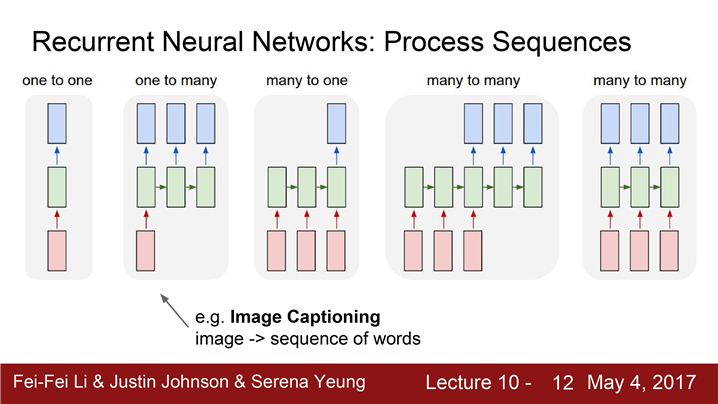
모델이 다양한 입력을 처리하는 상황을 가진다.
그래서 RNN은 네트워크가 다양한 입/출력을 다룰 수 있는 툴 제공한다.
- 단일 입력-> 가변 출력 "one to many" 모델
입력은 이미지와 같은 "단일 입력" 이지만 출력은 caption 과 같은 "가변 출력" 이다.
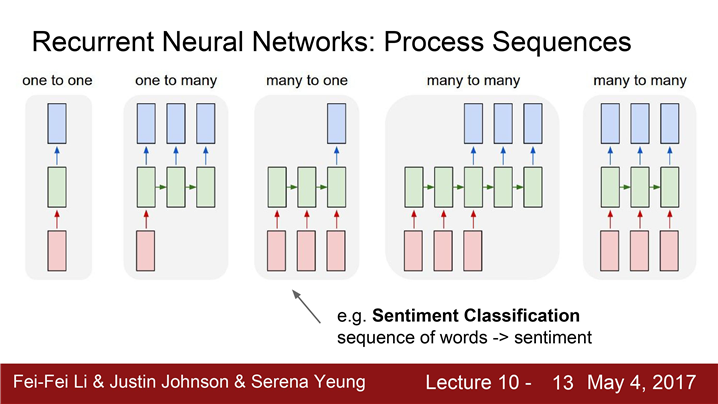
2. 가변입력 -> 단일출력 "many to one" 모델
입력이 "가변 입력"입니다.
ex)문장을 통한 감정분류, 부정적/긍적적인 문장인지를 구별한다
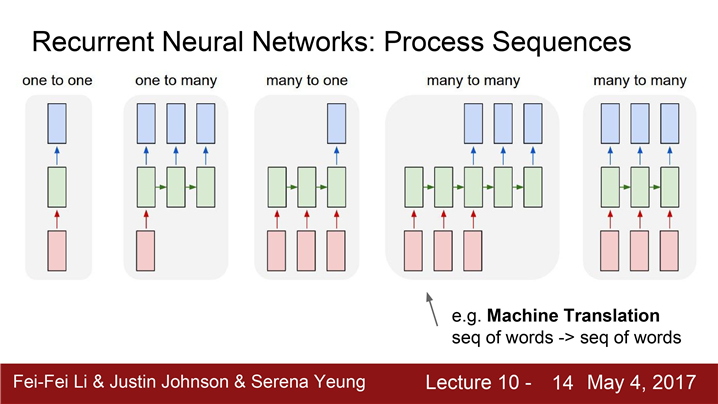
3. 가변입력 - > 가변출력
ex) Machine translation의 예
입력 : 영어문장-> 출력 :프랑스 문장
입출력 결과가 다르므로 가변 입출력 가능 모델 필요
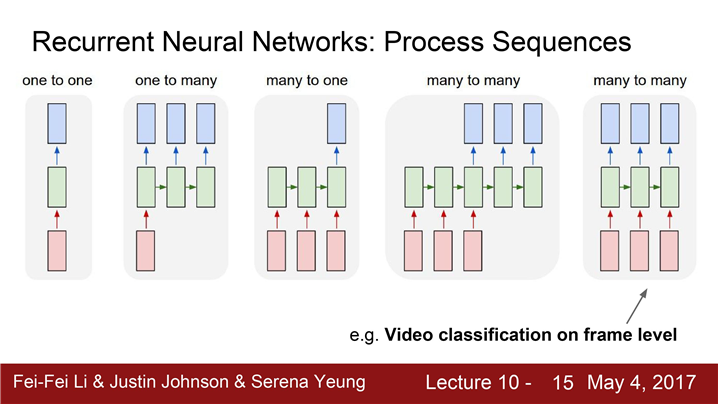
4. 가변입력 -> 프레임마다 출력
입력은 비디오와 같은 가변 입력이고 각 프레임마다 출력 값이 나와야 하는 상황
비디오가 입력이고 매 프레임마다 classification을 해야 하는 상황이 있다면 Recurrent Neural Networks를 통해 가변 길이의 데이터를 다룬다.
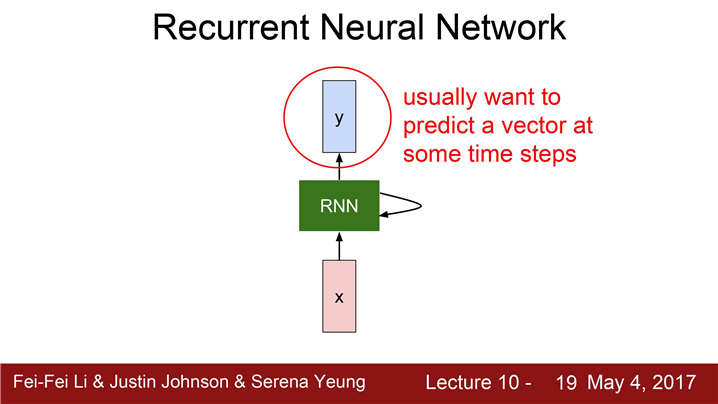
어떻게 RNN은 동작하는 것일까요?
일반적으로 RNN은 작은 "Recurrent Core Cell" 을 가지고 있습니다.
RNN의 동작
- RNN이 입력을 받습니다.
- "hidden state"를 업데이트합니다.
(RNN이 새로운 입력을 불러들일 때마다 매번 업데이트,"hidden state"는 모델에 feed back되고 이후에 또 다시 새로운 입력 x가 들어옵니다.)- 출력 값을 내보냅니다.
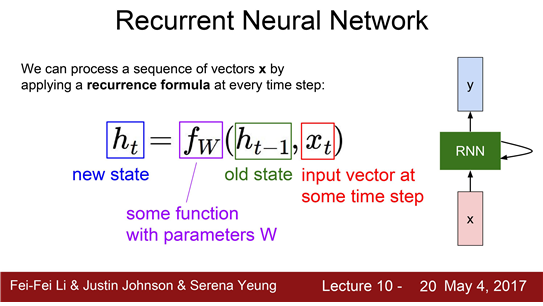
RNN 구조를 수식적으로 표현하면 어떨까요?
RNN block은 "재귀적인 관계"를 연산을 나타낸다.
fw
- h_t-1 : 이전 상태의 hidden state
- x_t : 현재 상태의 입력
- h_t : 다음 상태의 hidden state
- y :출력 값 (FC-Layer을 추가해야 한다. FC-Layer는 매번 업데이트되는 Hidden state(h_t)를 기반으로 출력 값을 결정)

Whh(가중치행렬)는 이전 state와 곱해지는 값이다.
Whx(가중치행렬)는 입력x와 곱해지는 값이다.
그리고 non-linearity를 구현하기 위해 tanh를 적용한다.
Hidden state인 h_t를 새로운 가중치 행렬 Why와 곱해주어 출력을 얻는다.

Multiple time steps을 루프를 풀어서 표현하면 이해하기 쉽다.
hidden states, 입/출력, 가중치 행렬들 간의 관계를 조금 더 명확히 이해한다.
첫 step에서는 initial hidden state인 h_0 가 있다.h_0 는 0으로 초기화시킵니다.
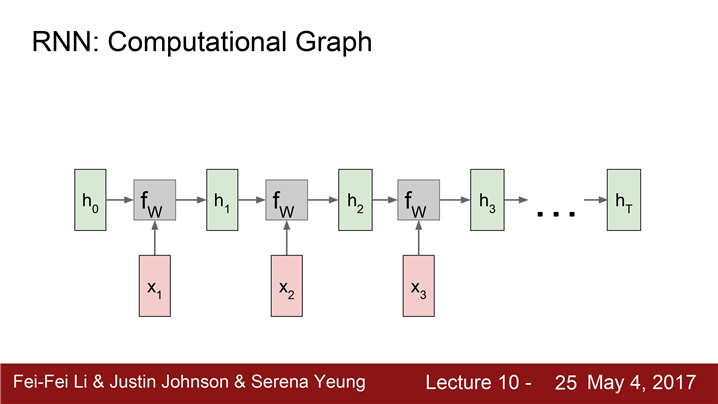
입력 :h_0와 x_1 이 함수 f_w의 으로 들어감
출력 h_1 : f_w(h_0, x_1)
이 과정이 반복한다.
이 과정을 반복하면서 가변 입력 x_t 를 받는다.
-
동일한 가중치 행렬 W가 사용된다는 점이다.
(Gradient를 구하려면 각 스텝에서 W에 대한 그레디언트를 전부 계산한 뒤에 이 값들을 모두 더하면 된다. ) -
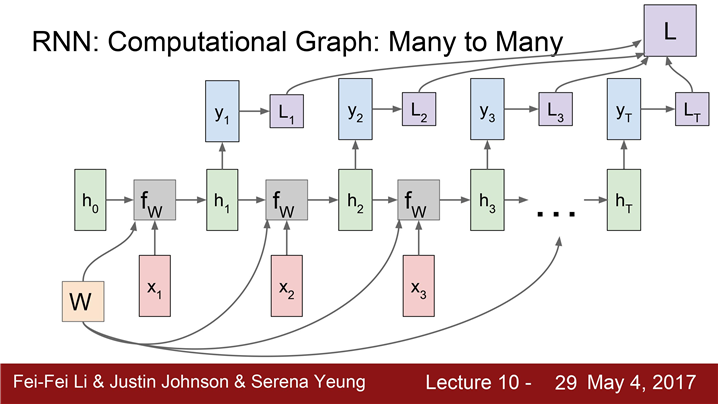
ht가 다른 네트워크의 입력으로 들어가서 y_t를 만들어 낼 수도 있다. ( class score )
-
각 스텝마다 개별적으로 y_t에 대한 Loss를 계산할 수 있다. 각 Loss의 값의 총합이 RNN의 최종 Loss이다.
"many to one"
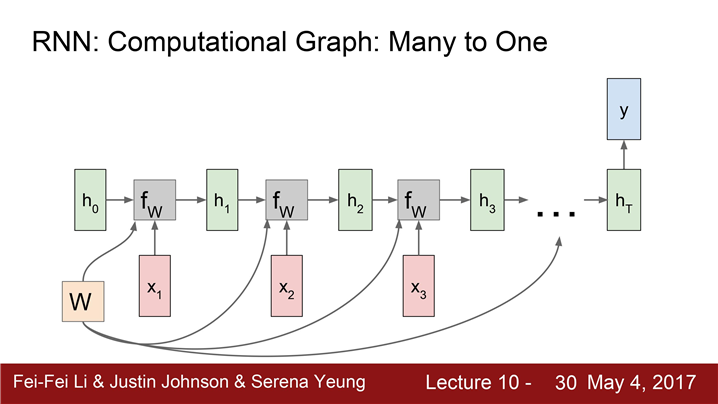
감정분석은 네트워크의 최종 hidden state에서만 결과 값이 나온다.
"one to many"
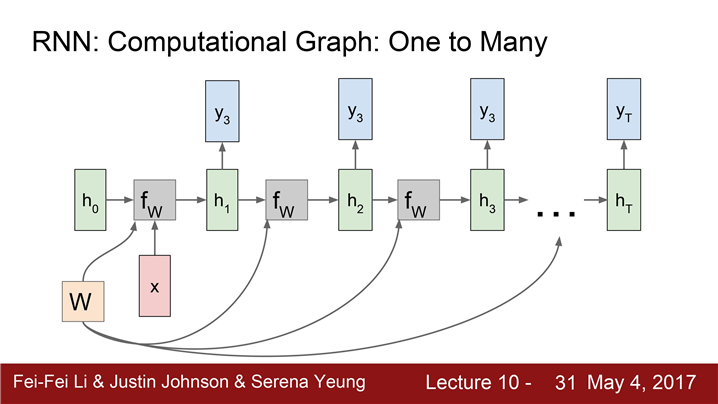
고정 입력은 모델의 initial hidden state를
초기화시키는 용도로 사용한다.
"many to one" 모델과"one to many" 모델의 결합
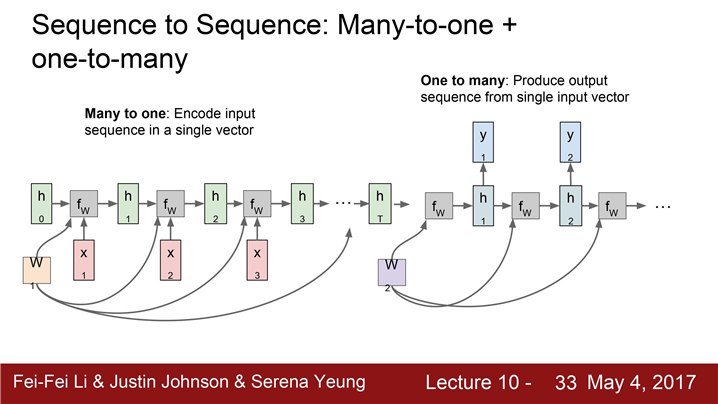
encoder와 decoder로 나눠서 볼 수 있다. encoder는 가변입력을 받는다. 예를 들어 영어 문장이 될 수 있다.
Encoder의 final hidden state를 통해 전체 sentence를 요약한다.
Decoder에서는 one to many 형태로 볼 수 있다.
입력은 하나의 벡터가 된다. decoder는 가변 출력을 내뱉는다. 다른 언어로 번역된 문장이 될 수 있다.
가변 출력은 매 스텝 적절한 단어를 내뱉는다.
Example : character-level language model
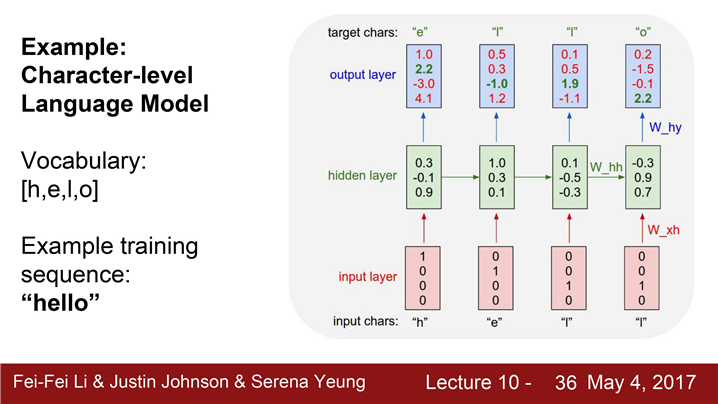
문자열을 입력으로 받고 다음으로 올 문자열을 예측해야한다.
-> softmax loss로 잘못 예측한경우
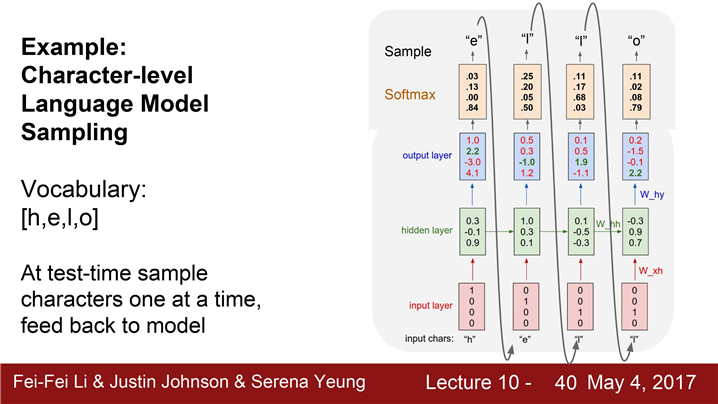
test time에서도
softmax vector의 연산이 어마어마 하므로
one hot vetor를 sparse vector operation 이용하여 처리한다.
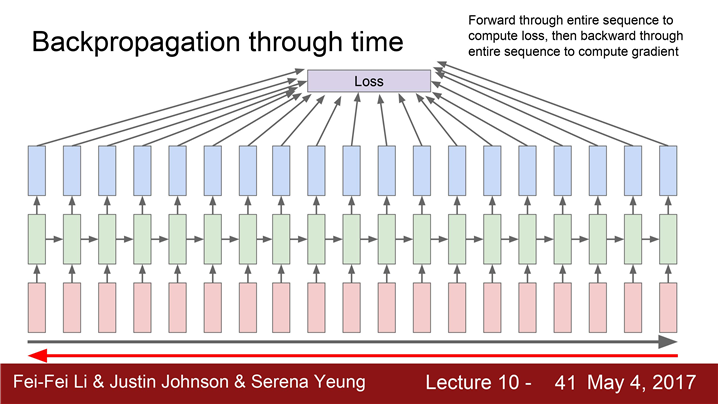
truncated backpropagation through time(매우큰 데이터의 gradient를 근사화)
진행
입력 시퀀스가 무한대라고 할지라도
Train time에 한 스텝을 일정 단위로 자른다.(약 100)100 스텝만 forward pass를 하고 이 서브스퀀스의Loss를 계산한다. 그리고 gradient step을 진행한다.위 과정을 반복한다.
RNN Language model : 세익스피어 작품 예시

학습 초기에는 모델이 의미없는 문장들만 뱉어냅니다. 학습을 시키면 시킬수록 의미있는 문장을 만들어냅니다.
학습이 잘 끝나면 상당히 셰익스피어 풍의 문장들을 만들어냅니다.

LaTex 코드(Markdown문법에서 수식입력하는 코드)를 우리가 만든 RNN Language Model로 학습시킬 수 있습니다.

linux 커널도 학습시킬수 있다.
Image Captioning Model
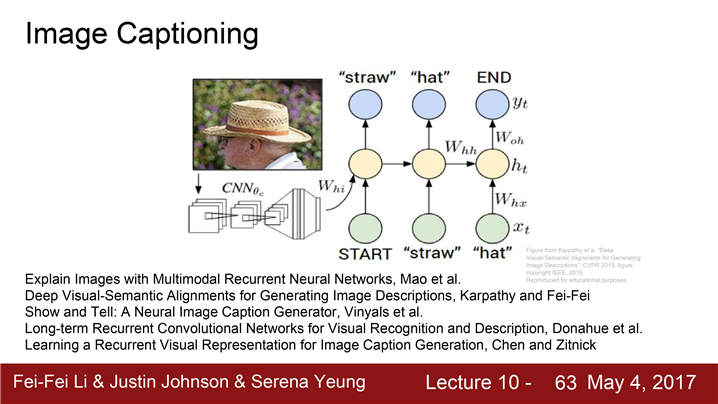
입력은 이미지
출력은 자연어로 된 Caption
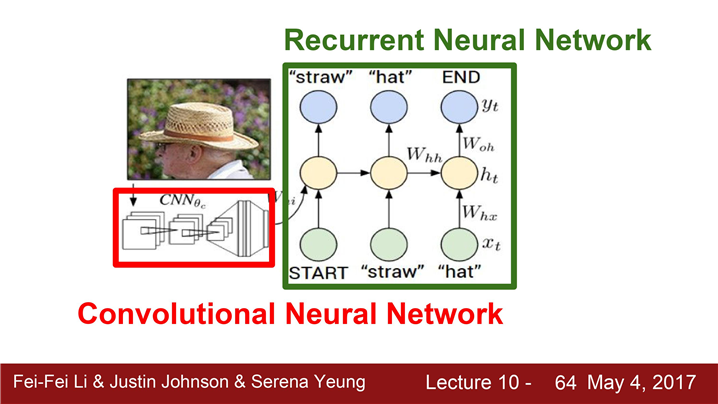
- 모델에는 입력 이미지를 받기 위한 CNN
- CNN은 요약된 이미지정보가 들어있는 Vector를 출력
- Vector는 RNN의 초기 Step의 입력들어감.
- RNN은 Caption에 사용할 문자들을 하나씩 만들어냄.
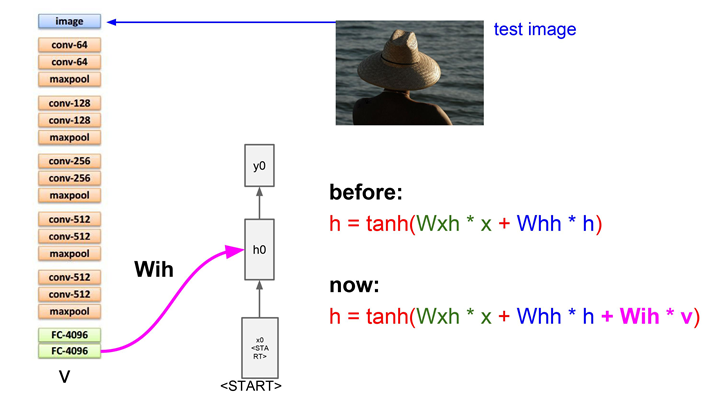
이전 까지의 모델에서는 RNN 모델이 두 개의 가중치 행렬을 입력으로 받았습니다.
-
하나는 현재 스텝의 입력과 곱할 가중치
-
다른 하나는 이전 스텝의 Hidden state 곱할 가중치
이 둘을 조합해서 다음 hidden state를 얻었습니다.
이제는 이미지 정보도 더해줘야 합니다.
★ hidden state를 계산할 때마다 모든 스텝에이 이미지 정보를 추가
vocabulary의 모든 스코어들에 대한분포를 계산
vocabulary는 엄청나게 크다!
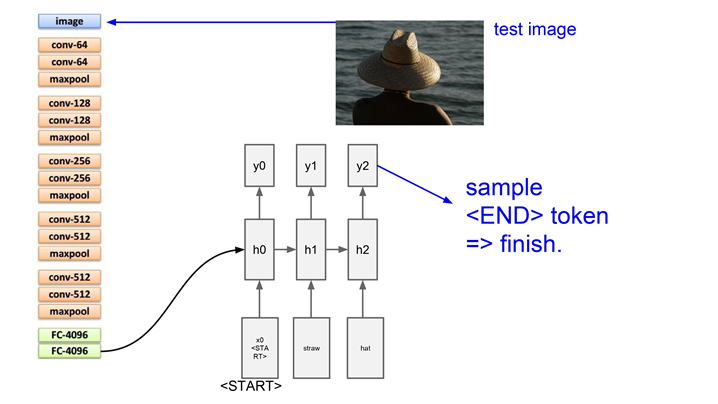
그 분포에서 샘플링을 하고 그 단어를 다음 스텝의 입력으로 다시 넣어준다.
샘플링된 단어(y0)가 들어가면 다시 vacab에 대한 분포를 추정하고 다음 단어를 만들어냅니다.
모든 스텝이 종료되면 결국 한 문장이 만들어집니다.
"END" 라는 토큰을 사용해 문장의 끝을 알려준다.이미지에 대한 caption이 완성된다

이 모델을 학습시키기 위해서는 natural language caption이 있는 이미지를 가지고 있어야 한다.
Task를 위한 가장 큰 데이터셋: Microsoft COCO 데이터셋

아직 완벽하진 않다.
Attention
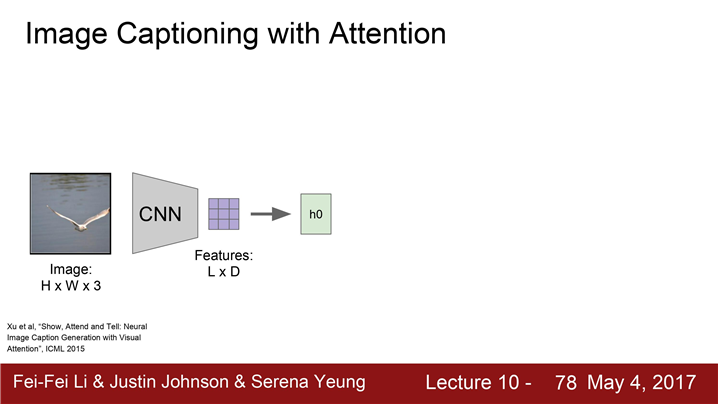
image captioning의 진보된 모델
Attention 동작과정
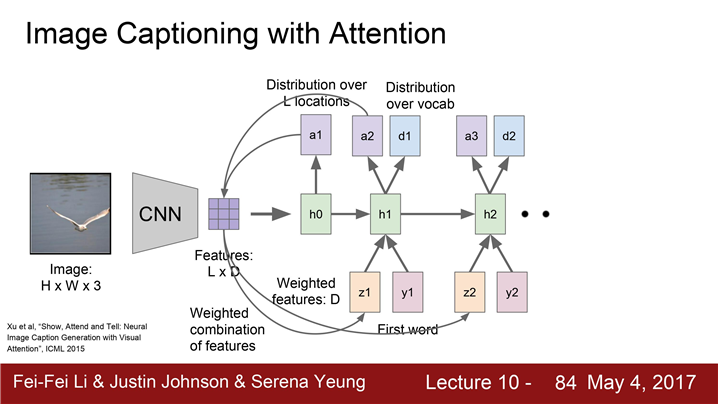
-
CNN층이 존재한다.
-
CNN로 벡터 하나를 만드는게 아니라 각 벡터가 공간정보를 가지고 있는 grid of vector를 만들어낸다.(LxD)
-
Forward pass시에 매 스텝 vocabulary에서 샘플링을 할 때 모델이 이미지에서 보고싶은 위치에 대한 분포 만들어낸다.
-
첫 번째 hidden state(h0)는 이미지의 위치에 대한 분포를 계산한다.
-
분포(a1)를 다시 벡터 집합(LxD Feature)과 연산하여 이미지 attention(z1)을 생성한다.
-
이 요약된 벡터(z1)는 Neural network의 다음 스텝의 입력으로 들어갑니다.
-
두 개의 출력이 생성됩니다. (a2, d1)
- 하나는 vocabulary의 각 단어들의 분포
- 다른 하나(a2)는 이미지 위치에 대한 분포
위 과정 반복
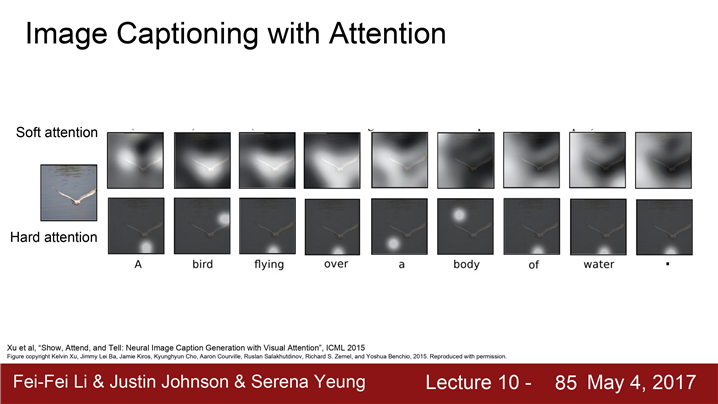
train이 끝나면 모델이 caption을 생성하기 위해서 이미지의 attention을 이동시키는 모습을 볼 수 있다.
Soft attention의 경우는 ‘모든 특징’ + ‘모든 이미지 위치’간의 Weighted combination을 취하는 경우이다.
Hard attention은 모델이 각 타임 스텝마다 단 한곳만 보도록 강제한 경우이다.
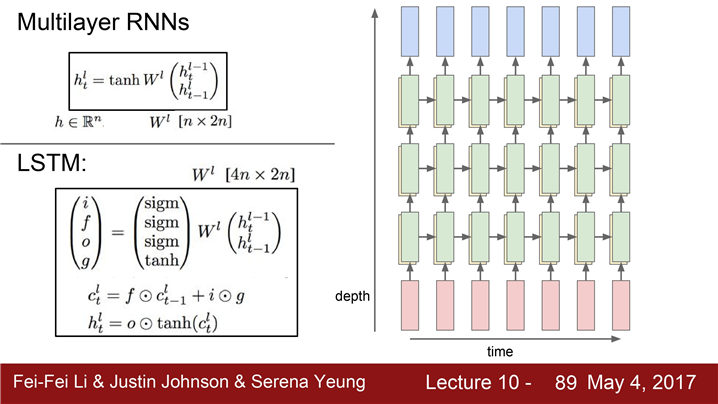
지금까지 단일 RNN을 봤고
주로 사용할 RNN은 Multi-layer RNN입니다.
3-Layer RNN
-
입력이 첫 번째 RNN으로 들어가서 첫 번째 hidden state를 만들어낸다.
-
RNN 하나를 돌리면 hidden states 시퀀스가 생긴다.
-
이렇게 만들어진 hidden state 시퀀스를 다른 RNN의 입력으로 넣는다.
-
두 번째 RNN layer가 만들어내는 또 다른
hidden states 시퀀스가 생겨납니다.
-> 레이어를 쌓아올림.모델이 깊어질수록 성능이 향상 그러나 2~4 Layer 사용
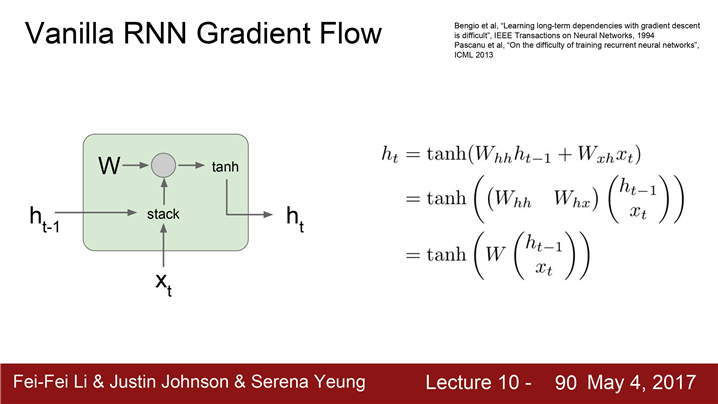 .
.
(vanilla) RNN Cell:
입력은 "현재 입력, x_t" 와 "이전 hidden state h_t-1"이다. 그리고 이 두 입력을 쌓는다.(stack).
두 입력을 쌓고 가중치 행렬 W와 행렬 곱 연산을 하고 tanh 를 씌워서 다음 hidden state(h_t)를 만든다.
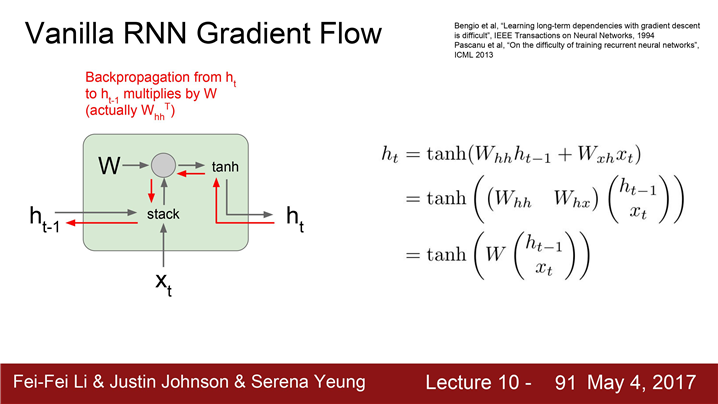
Backward pass 시 h_t에 대한 loss의 미분값을 얻는다.
계속 진행하여 최종적인 Loss에 대한 h_t-1의 미분값을 계산하게 된다.
backward pass의 전체과정은 여기 보이시는 빨간색 통로를 따르게 된다.
우선 그레이언트가 tanh gate를 타고 흘러간다.다음에 Matrix multiply gate를 통과하면서 가중치 행렬을 곱한다.
h_0에 대한 그레이언트를 구하고자 한다면 결국에는 모든 RNN Cells을 거쳐야 한다.
->h_0 의 그레디언트를 계산하는 식을 써보면 아주 많은 가중치 행렬들이 개입한다.
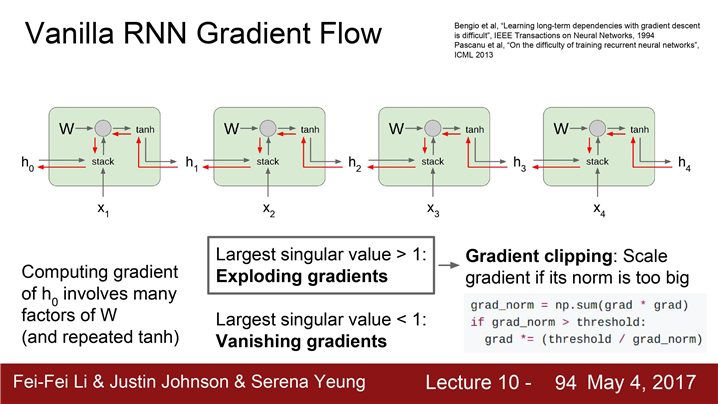
"exploding gradient problem"
- 행렬의 특이값(singular value)이 엄청 큰 행렬을 계속 곱하는 경우에도 역시 h_0의 그레디언트는 아주 커지게 된다.
"vanishing gradient problem"
- 행렬의 특이값이 1보다 작은 경우라면 정 반대의 현상이 발생한다. 기하급수적으로 그레디언트가 작아진다.
"gradient clipping" (위 문제들의 solution)
그레디언트의 L2 norm이 임계값보다 큰 경우 그레디언트가 최대 임계값을 넘지 못하도록 조정
gradient clipping은 exploding gradient는 좋지만 vanishing gradient 를 해결하기위해서는 더 복잡한 구조가 필요하다.
LSTM
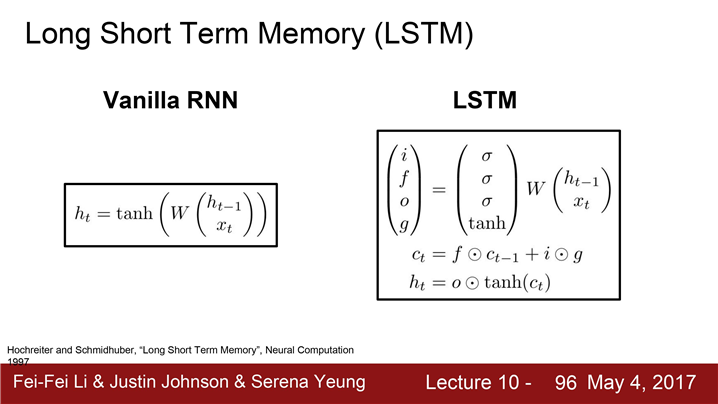
LSTM(Long Short Term Memory)은 vanishing & exploding gradients 문제를 완화시키기 위해서 디자인
LSTM의 수식
-
한 Cell 당 두 개의 Hidden state
(하나는 h_t , "Cell state" 인 c_t라는 벡터가 더있음) -
LSTM도 두 개의 입력을 받음(h_t-1, x_t) 4개의 gates를 계산
-
gates를 cell states, c_t를 업데이트하는데 이용(c_t로 다음 스텝의 hidden state를 업데이트)
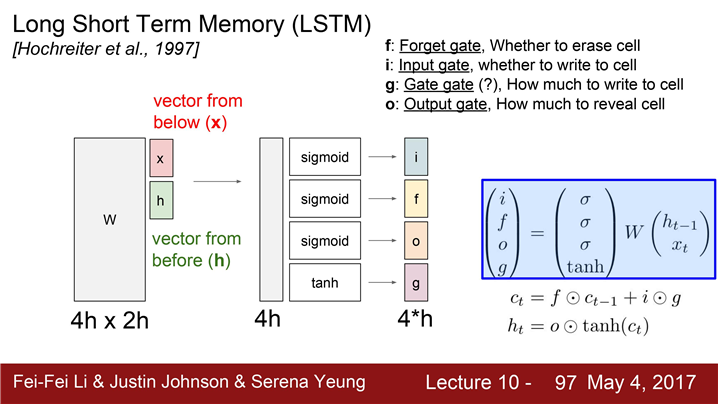
-
이전 hidden state와 입력을 받아서 쌓는다.
-
네 개의 gates의 값을 계산하기 위한
커다한 가중치 행렬을 곱한다. -
h_t-1과 x_t를 입력으로 받고 gates 4개를 계산한다.
4개의 gates
-
I : input gate, Cell에서의 입력
x_t에 대한 가중치 -
F : forget gate , 이전 스텝의 Cell의 정보를 얼마나 forget 할지에 대한 가중치
-
O : Output gate, Cell state, c_t를 얼마나 밖에 드러내 보일지에 대한 가중치
-
G : gate gate,input cell을 얼마나 포함시킬지 결정하는 가중치
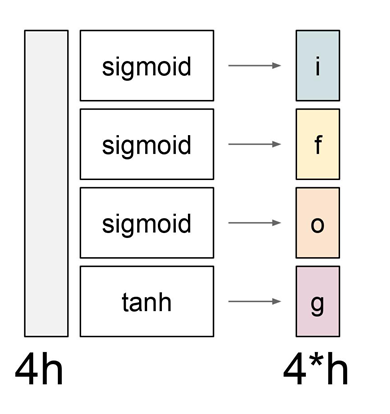
각 gate에서 사용하는 non-linearity가 다르다.
-
input/forget/output gate의 경우:
sigmoid(gate의 값이 0~1 사이) -
gate gate : tanh(gate의 값이-1 ~ +1)
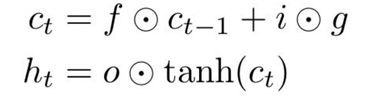
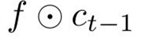
이전 스텝의 Cell states(C_t-1)는
forget gate와 element-wise multiplication 연산
-> 결과 vector는 (f*c_t-1) 0또는 1
(forget gate = 0 지우고, =1 기억)
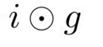
벡터 i : 0 또는 1(sigmoid) (위에 f gate와 동작방식이 같음)
gate gate : -1 또는 +1(tanh 출력)
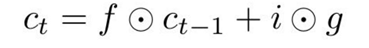
-
이전 cell state(c_t-1)을
계속 기억할지 말지를 결정한다. (f * c_t-1) -
각 스텝마다 1까지 cell state의 각 요소를 증가시키거나 감소시킬 수 있다. (i * g)

output gate :0 ~ 1(sigmoid),각 스텝에서 다음 hidden sate를 계산할 때 cell state를 얼마나 노출시킬지를 결정
-> tanh 연산 hidden state를 업데이트
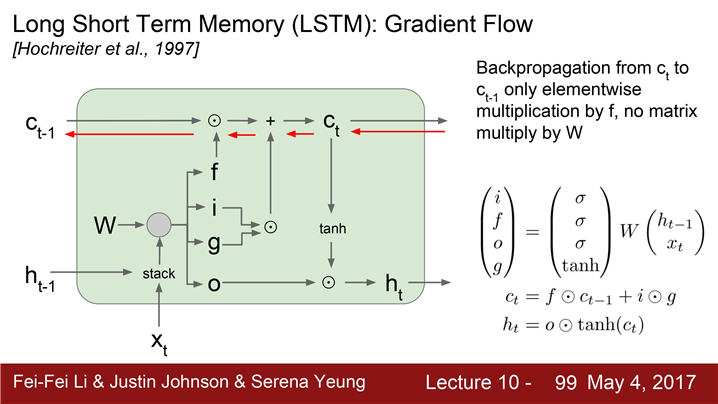
하나의 cell에서 Weight행렬을 거치지 않고도 cell 단위에서 gradient 계산을 할 수 있다.
여러 cell을 거치더라도 계산량이 크게 증가하지 않는다는 것을 알 수 있다.
즉, forget gate와 곱해지는 연산이 행렬 단위의 곱셈 연산이 아니라 element-wise (원소별 연산)이기 때문에 계산량이 크게 증가하지 않는다.
LSTM의 exploding/vanishing gradient문제
- LSTM에서는 forget gate가 스텝마다 계속 변한다
- forget gate는 sigmoid에서 나온 값이므로element wise multply가 0~1 사이의 값을 가진다(Vanila RNN의 경우 큰 수의 가중치 행렬을 곱함)
- exploding/vanishing gradient가 없다.
GRU

-
Gated Recurrent Unit
-
Vanishing gradient 문제를 회피하기 위한 element-wise multiplcation 이용
RNN CODING : using keras
https://www.kaggle.com/leeyoong/time-deeprunning-fit