목표
오늘은 youtube API에서 영상목록을 검색해서 받아올때 nextPageToken을 이용해서 추가로 영상목록을 받아오고 이를 무한스크롤과 함께 적용해 보았습니다:)
nextPageToken 이용하기
우선 설명하기에 앞서 YouTube Data API 먼저 살펴보겠습니다. 공식문서에서 사용해 볼 수 있어요.(사용은 맨 아래쪽!)
필수매개변수 part에 snippet을 주고 q(string, q 매개변수는 검색할 검색어를 지정합니다.) 에는 검색할 단어를 입력합니다.

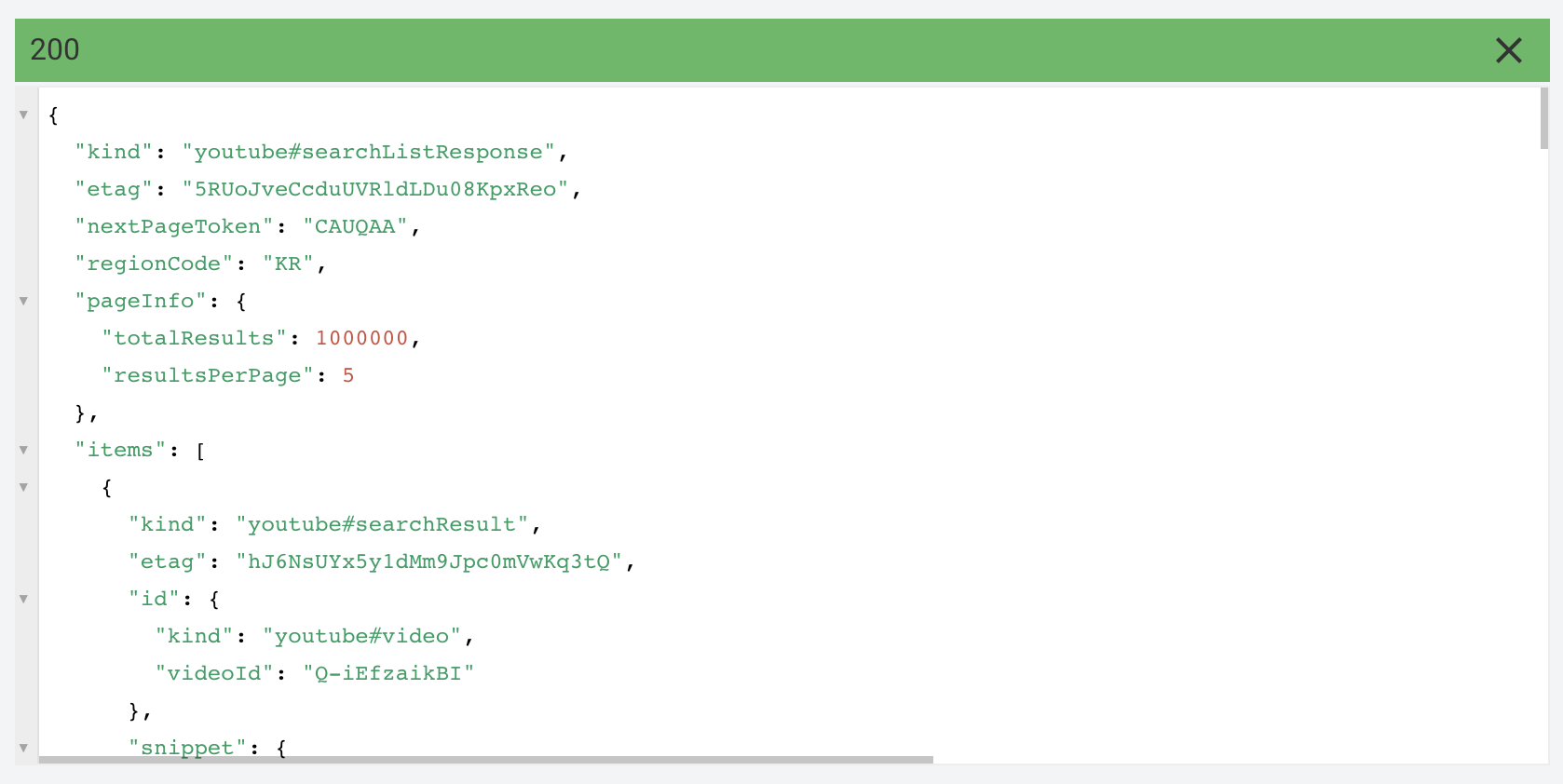
위와 같은 정보를 json으로 전달받습니다. nextPageToken이 보이고 그 밑에 items 안에 5개의 영상 정보가 들어 있습니다.
nextPageToken으로 다음 목록을 받아올때에는 똑같이 part에 snippet,q에는 검색했던 검색어, 그리고 추가로 pageToken에 저장해두었던 nextPageToken을 넣어주면 됩니다.

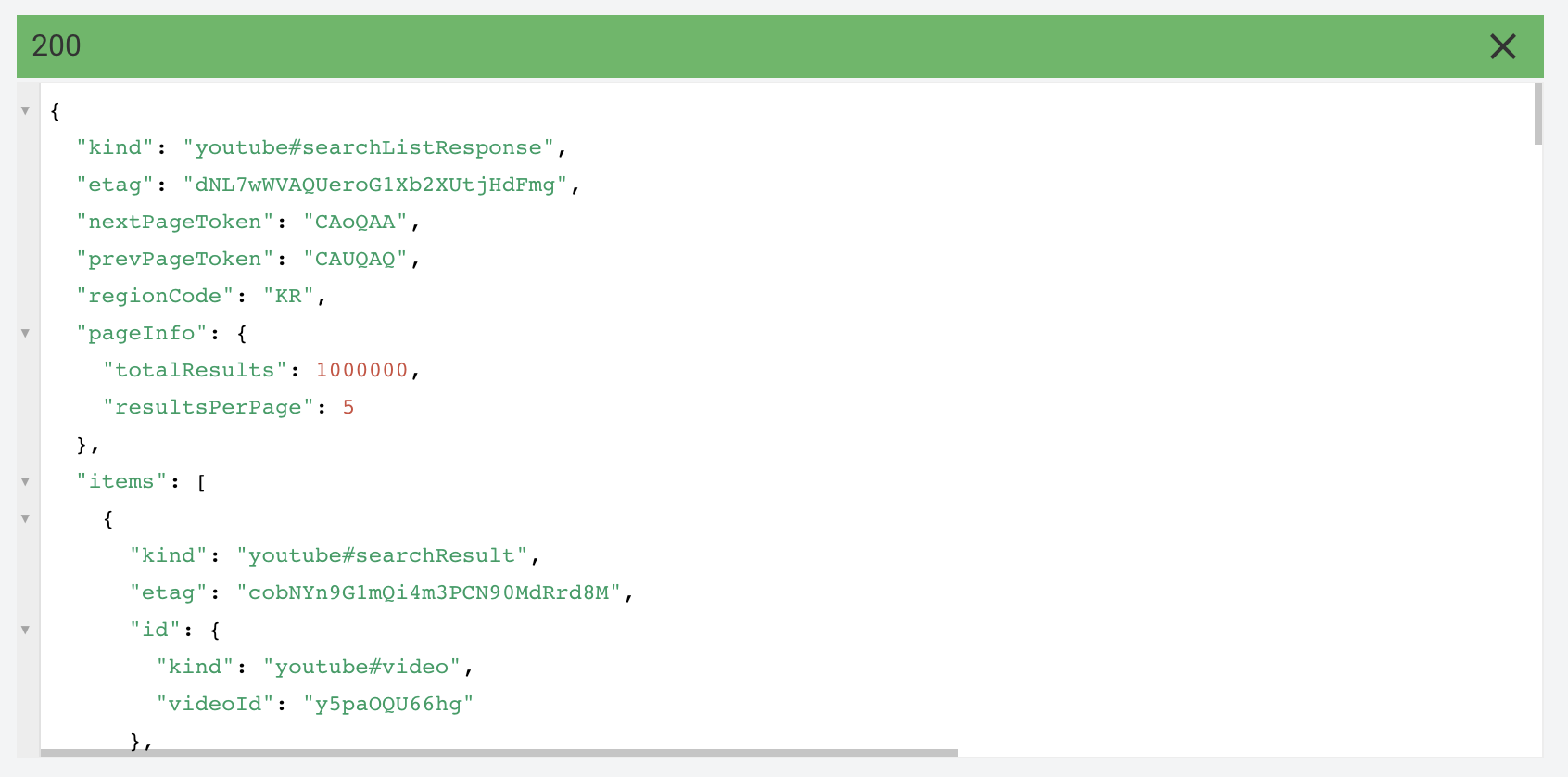
nextPageToken을 통해 위와 같은 json을 받아왔습니다. 전과는 다르게 prevPageToken도 보입니다.
하지만 추가되는 목록을 받아와 기존 목록 밑에 추가해 줄 것이기 때문에 이번에는 사용하지 않습니다.
nextPageToken 적용하기
이제 프로젝트에 적용해보겠습니다.
4가지 state를 사용했습니다.
//state
const [list, setList] = useState(); //영상목록 저장
const [searchQ, setSearchQ] = useState(); //마지막으로 검색한 단어를 저장,nextPageToken 사용할 때 필요
const [nextPageTok, setNextPageTok] = useState(); //nextPageToken을 저장
const [isLoading, setIsLoading] = useState(false); //로딩중 애니메이션을 위한 State처음 영상을 검색할 때 searchQ와nextPageToken을 저장해둡니다.
//처음 검색해서 영상목록을 받아오는 코드
//URI가 들어오면 영상목록을 검색하지 않고 바로 추가함.
const onSearch = (event) => {
event.preventDefault();
const value = inputRef.current.value;
if (value === '') return;
if (modalOn === 'video') {
const videoIdFromURI =
value.split('?v=').length > 1 ? value.split('?v=')[1].split('&')[0] : false;
console.log(videoIdFromURI);
if (videoIdFromURI) addVideo(videoIdFromURI, nemo);
//URI가 아니면 영상을 검색한다.
if (!videoIdFromURI)
//이곳에서 영상목록을 저장하면서 searchQ와nextPageToken도 같이 저장해둡니다.
youtube.searchVideo(value).then((videos) => {
setSearchQ(value);
//youtube API에서 영상목록을 JSON으로 받을때 nextPageToken이 같이 반환되는데,그것을 저장해줍니다.
setNextPageTok(videos.nextPageToken);
setList(videos.items);
});
}
formRef.current.reset();
};위에서 사용된 youtube Class의 코드입니다. searchVideo말고도 여러함수가있지만 생략했습니다.
import axios from 'axios';
class Youtube {
constructor(key) {
this.youtube = axios.create({
baseURL: 'https://youtube.googleapis.com/youtube/v3',
params: { key: key },
});
}
async searchVideo(submit, pageToken) {
const response = await this.youtube.get('search', {
params: {
part: 'snippet',
maxResults: 9,
q: submit,
type: 'video',
pageToken: pageToken && pageToken,
},
});
return response.data;
}
}
export default Youtube;
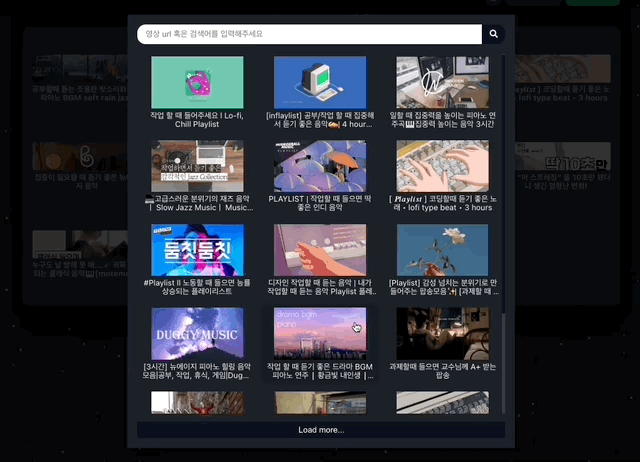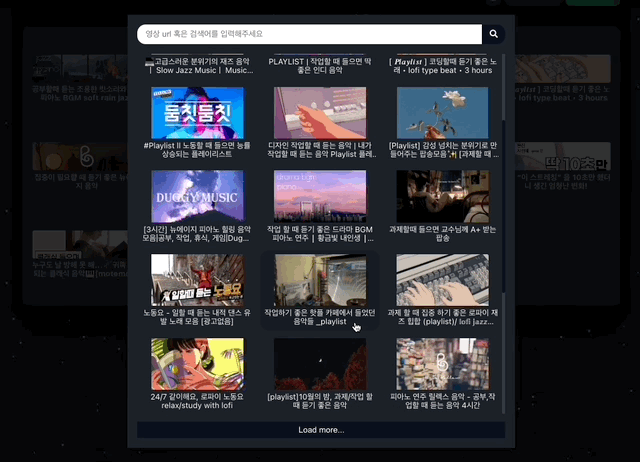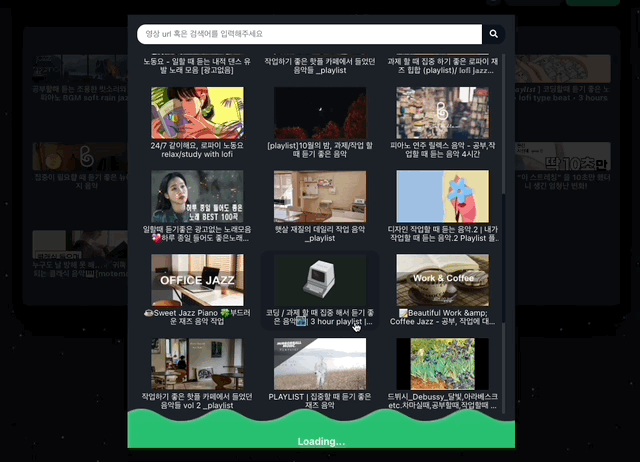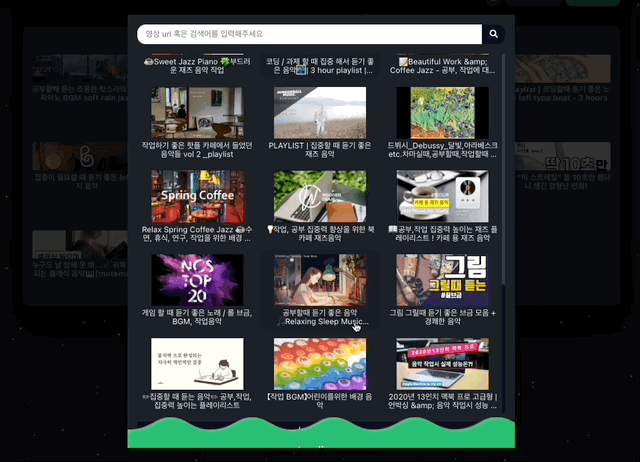
이제 list에 영상목록이 저장되었습니다.
nextPageToken을 이용해 loadMore함수를 구현합니다.
const loadMore = () => {
setIsLoading(true);
//아까 저장해두었던 searchQ(검색어),nextPageTok을 이용해서 다음 영상목록을 받아옵니다.
youtube.searchVideo(searchQ, nextPageTok).then((videos) => {
setNextPageTok(videos.nextPageToken);//새로운 nextPageToken을 저장합니다.
setList([...list, ...videos.items]);//기존 영상목록 뒤에 새로받아온 영상들을 추가합니다.
});
setTimeout(() => {
setIsLoading(false);
}, 1000);//요청이 너무 빨리 처리되어서 애니메이션을위해 1초의 시간을 주었습니다.
}; load more 기능이 추가된 모습. 이제 목록이 많아져 스크롤이 생겼을 때 무한스크롤을 구현하면 됩니다!
load more 기능이 추가된 모습. 이제 목록이 많아져 스크롤이 생겼을 때 무한스크롤을 구현하면 됩니다!
무한스크롤 구현하기
코드로 넘어가기전 scrollHeight, scrollTop, clientHeight를 먼저 이해합시다.
 [출처:https://ko.javascript.info/size-and-scroll]
[출처:https://ko.javascript.info/size-and-scroll]
일단 전체 내용의 높이는 scrollHeight이고 스크롤 된 높이는 scrollTop, 그리고 보여지는 높이는 clientHeight입니다.
여기서 스크롤된 높이 + 보여지는 높이 = 전체 내용의 높이 일때 아래 끝까지 스크롤 되었다는 것을 유추할 수 있다.
이를 이용해서 구현해보자!
//검색한 영상목록이 담겨있는 컨테이너의 스크롤 정보를 가져오기 위한 ref와 스크롤시 실행할 함수를 등록
<ul ref={modalRef} onScroll={modalScroll}>
<li>영상목록</li>
<li>영상목록</li>
...
</ul>
//스크롤시 실행될 함수를 성능을 위해 lodash 라이브러리의 debounce 함수로 감싸주었다.
//debounce함수는 _.(함수,딜레이)으로 이루어지는데 딜레이가 끝난 후 함수가 실행된다.
//딜레이 중에 함수가 호출된다면 이전에 호출된 함수가 사라지고 다시 딜레이가 시작됨=>그래서 스크롤이벤트가 수많이 실행되더라도 마지막 한번만 실행이된다.
const modalScroll = _.debounce(() => {
//스크롤시 영상이 담긴 모달의 scrollHeight,scrollTop,clientHeight를 가져오고,
const { scrollHeight, scrollTop, clientHeight } = modalRef.current;
//스크롤된 높이(scrollTop)+보여지는 높이(clientHeight)> 영상목록의 전체 높이(scrollHeight)-10px 일때 loadMore()함수를 실행.
if (scrollHeight - 10 < scrollTop + clientHeight) loadMore(); //scrollHeight -10px은 끝까지 스크롤안해도 10px정도 여유있게 동작하게 하기위해서 주었다.
}, 200);간단하게 onScroll을 이용해 구현하고 debounce를 통해 성능을 개선했지만,
다른 방법으로는 useIntersectionObserver 인터섹션옵저버를 이용해서 구현하는 방법(참고 사이트)도 있다.
