Clustering(군집화)
- 비지도 학습(Unsupervised Learning)
- 데이터의 라벨이 없는 경우, 유사한 속성끼리 그룹화 하는데 사용함
- 서로 다른 그룹은 서로 다른 특성을 갖도록 함
| 목적 | 설명 |
|---|---|
| 패턴 탐지 | 유사한 속성을 가진 데이터 그룹을 자동으로 찾습니다. |
| 데이터 요약 | 대규모 데이터를 클러스터 단위로 묶어 요약하고 해석하기 쉽게 만듭니다. |
| 사전 처리 | 지도 학습 전에 데이터 구조를 파악하고 특성 공학(Feature Engineering)에 활용합니다. |
| 이상치 탐지 | 다른 그룹에 속하지 않는 데이터를 이상치로 감지할 수 있습니다. |
- 대표적인 군집화 알고리즘
| 알고리즘 | 개념 | 주요 특징 |
|---|---|---|
| KMeans | 중심점을 기준으로 데이터를 k개의 그룹으로 분할 | 빠르고 간단하지만 클러스터 수(k)를 사전에 지정해야 함 |
| DBSCAN | 밀도가 높은 영역을 클러스터로 정의 | 클러스터 수를 지정할 필요 없고 이상치(노이즈) 감지 가능 |
| 계층적 클러스터링 | 데이터를 병합(또는 분할)하며 계층적 트리 구조 형성 | 덴드로그램 시각화를 통해 군집 구조를 직관적으로 파악 가능 |
| MeanShift | 데이터의 밀도가 높은 방향으로 중심점을 이동 | 클러스터 수 자동 결정, 복잡한 분포에 강함 |
| Spectral Clustering | 그래프 이론 기반의 고차원 분할 기법 | 비선형 구조나 복잡한 모양의 데이터 분할에 효과적 |
| Birch | 대용량 데이터를 위한 트리 기반 클러스터링 | 빠른 속도, 온라인 처리 가능 (스트리밍 데이터 적합) |
이번 실습에서는 KMeans를 사용해서 KMeans에 대한 내용만 있음
KMeans
- 데이터를 비슷한 특성끼리 묶는 알고리즘
- K는 갯수를 의미함
- 주요 특징
| 항목 | 설명 |
|---|---|
| 입력 필요 | K (클러스터 수)를 미리 지정해야 함 |
| 유형 | 비지도 학습 (Unsupervised Learning) |
| 거리 계산 | 주로 유클리드 거리(Euclidean Distance)를 사용 |
| 장점 | 구현이 간단하고 계산 속도가 빠름 |
| 단점 | K 값을 사전에 알아야 하며, 이상치에 민감함 |
실습
- Customer_Join 데이터를 이용한 실습
모델 정보
1. 클러스터링에 사용할 데이터 선택 및 전처리
# mean, median, max, min, membership_period 사용
cc = cj[['mean', 'median', 'max', 'min','membership_period']]
standardscaler = StandardScaler()
cc_scaler = standardscaler.fit_transform(cc)
df = pd.DataFrame(cc_scaler)
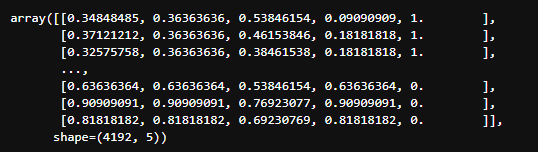
2. KMeans 클러스터링 모델 사용
# KMeans알고리즘 학습모델
# 분리하는 것을 기본으로 잡고감
Kmeans = KMeans(n_clusters = 4, random_state= 0, algorithm= 'lloyd')
cluster = Kmeans.fit(cc_scaler)
cc['cluster'] = cluster.labels_
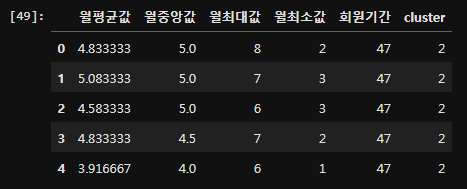
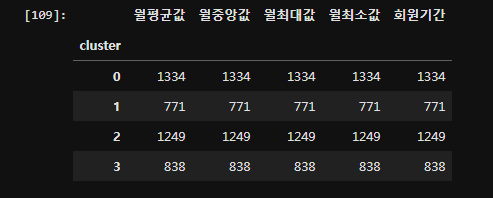
cc.rename(columns = {'mean':'월평균값', 'median':'월중앙값', 'max':'월최대값', 'min':'월최소값', 'membership_period':'회원기간'}, inplace=True)
cluster
cc.head()
cc.groupby('cluster').count()
PCA
- 차원 축소에 사용되는 기법
- 데이터를 더 작고 효율적인 형태로 바꾸고 싶을 때 사용
- 고차원을 저차원 데이터로 줄이면서, 정보 손실을 최소화 함
- 데이터 특성이 많아 분석이 어렵거나 계산이 오래걸릴 때 사용
| 항목 | 설명 |
|---|---|
| 목적 | 차원 축소, 시각화, 노이즈 제거 |
| 전처리 필요 | 표준화 (StandardScaler) 필수 |
| 작동 방식 | 분산이 큰 방향(주성분)을 따라 데이터를 재투영 |
| 주요 개념 | 고유값, 고유벡터, 공분산 행렬 |
| 결과 | 주성분 축으로 변환된 새로운 데이터셋 |
| 주의사항 | 해석이 직관적이지 않을 수 있음 (축은 원래 변수의 선형 조합이기 때문) |
X = cc_scaler.copy()
pca = PCA(n_components=2)
pca.fit(X)
x_pca = pca.transform(X)
pca_df = pd.DataFrame(x_pca)
pca_df['cluster'] = cc['cluster']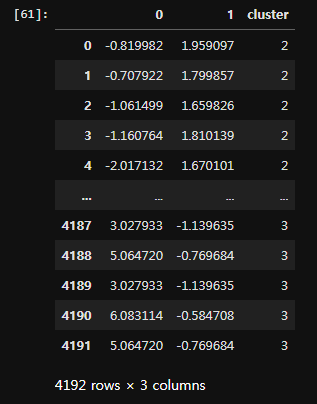
시각화
sns.scatterplot(data = pca_df ,x = 0 , y = 1 , hue = 'cluster', palette= 'Set2')
plt.show()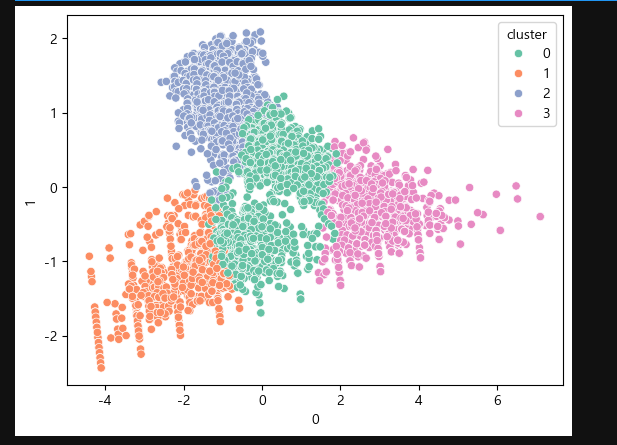
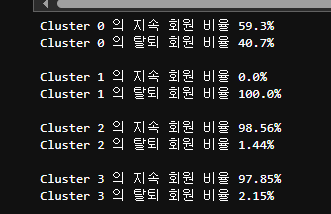
클러스터링한 결과 바탕으로 유지 회원, 탈퇴회원 계산
# cc_join = cc와 cj join
# cluster 별, is_deleted컬럼 그룹화의 갯수 count()갯수 고객아이디 customer_id
# 현재 유지, 탈퇴 관리
cc_join = pd.concat([cc, cj], axis = 1)
new_df = cc_join.groupby(['cluster','is_deleted'], as_index = False).count()[['cluster', 'is_deleted', 'customer_id']]
delete0 = (new_df['is_deleted'] == 0)# 현재 지속회원 유지
delete1 = (new_df['is_deleted'] == 1)# 현재 탈퇴회원
# 데이터 분석
# delete1변수 사용
#
for i in range(0, 4):
temp = (new_df['cluster'] == i)
print(f'Cluster {str(i)} 의 지속 회원 비율 {str(round((new_df.loc[(temp&delete0), 'customer_id'].sum() / new_df.loc[(temp), 'customer_id'].sum()) * 100,2))}%')
print(f'Cluster {str(i)} 의 탈퇴 회원 비율 {str(round((new_df.loc[(temp&delete1), 'customer_id'].sum() / new_df.loc[(temp), 'customer_id'].sum()) * 100,2))}%')
print()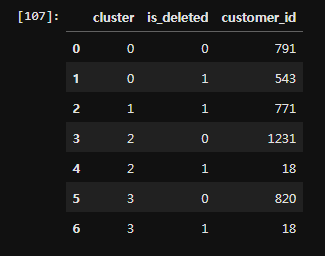

안녕하세요. 도야입니다