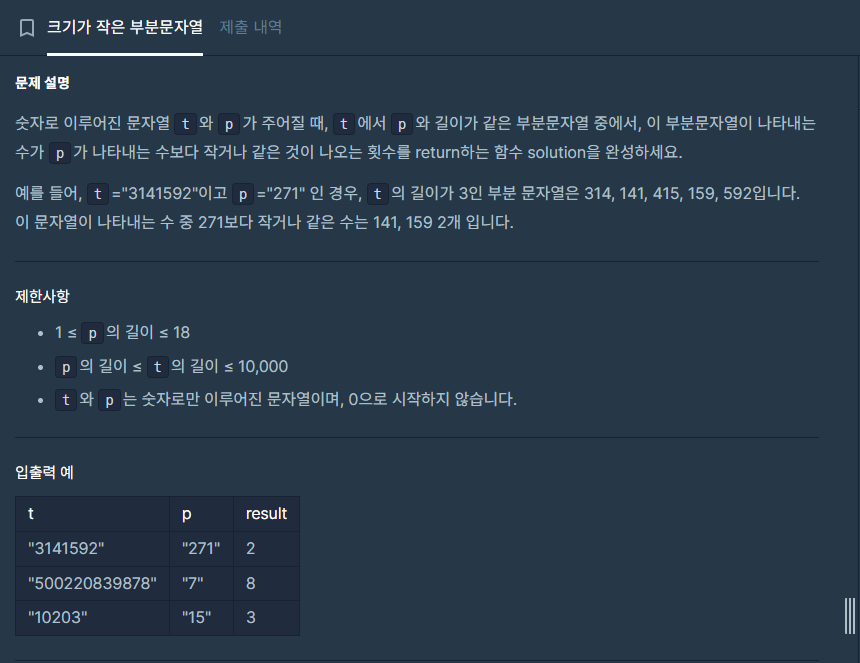
Algorithm: 크기가 작은 부분 문자열
| 문제 링크 / Github 링크 |
|---|
 |
import Foundation
func solution(_ t: String, _ p: String) -> Int {
return 0
}처음 짠 코드
import Foundation
func solution(_ t: String, _ p: String) -> Int {
var mutableT = t
var resultCount = 0
let intP = Int(p)!
while mutableT.count != p.count {
var numString = ""
for char in mutableT {
numString.append(char)
if numString.count == p.count { break }
}
if Int(numString)! <= intP { resultCount += 1 }
mutableT.removeFirst()
}
if Int(mutableT)! <= intP { resultCount += 1 }
return resultCount
}개선할 수 있는 점들
- 불필요한 루프와 문자열 조작
mutableT에서 매번 첫 글자를 제거하며p.count길이의 부분 문자열을 만들어 확인하는 로직은 비효율적이다.mutableT.removeFirst()로 문자열을 매번 수정하는 부분은 O(n) 연산이다. 전체적인 시간 복잡도가 높아질 수 있다.
- 중복 코드
- 마지막
if문에서mutableT의 길이가p.count와 같은지 확인 후 비교하는 코드는 앞의 로직과 유사하여 중복 코드로 간주될 수 있다.
- 마지막
- 효율성 개선
- 슬라이딩 윈도우(sliding window) 기법을 활용하면 더 효율적으로 문제를 해결할 수 있다.
개선한 코드
import Foundation
func solution(_ t: String, _ p: String) -> Int {
let intP = Int(p)!
let pCount = p.count
var resultCount = 0
for i in 0...(t.count - pCount) {
let startIndex = t.index(t.startIndex, offsetBy: i)
let endIndex = t.index(startIndex, offsetBy: pCount)
let substring = String(t[startIndex..<endIndex])
if let intSubstring = Int(substring), intSubstring <= intP {
resultCount += 1
}
}
return resultCount
}Sliding Window 기법
슬라이딩 윈도우 기법은 연속적인 데이터에서 특정 구간(윈도우)을 효율적으로 처리하기 위한 알고리즘 기법이다.
주로 배열이나 문자열과 같은 선형 데이터 구조에서 연속된 부분 구간의 합이나 최대/최소값, 특정 조건을 만족하는 부분 구간의 개수 등을 계산할 때 사용된다.
기본 개념
- 윈도우란 일정 크기의 부분 구간을 의미한다.
- 슬라이딩 윈도우는 이 구간을 처음부터 끝까지 "슬라이드"하면서 데이터를 처리한다.
- 이전 윈도우의 결과를 재활용하여 다음 윈도우를 계산하므로, 중복 계산을 최소화해 효율성을 높이는 데 목적이 있다.
사용 예시
1. 고정 크기 윈도우
예시: 배열에서 크기가 k인 부분 배열의 합을 모두 구하는 문제
비효율적인 방법 (중복 계산 O(n*k)):
func sumOfSubarrays(arr: [Int], k: Int) -> [Int] {
var sums = [Int]()
for i in 0...(arr.count - k) {
let sum = arr[i..<i+k].reduce(0, +)
sums.append(sum)
}
return sums
}슬라이딩 윈도우 방식 (O(n)):
func sumOfSubarrays(arr: [Int], k: Int) -> [Int] {
var sums = [Int]()
var windowSum = arr[0..<k].reduce(0, +) // 첫 윈도우의 합 계산
sums.append(windowSum)
for i in 1...(arr.count - k) {
windowSum = windowSum - arr[i - 1] + arr[i + k - 1] // 이전 윈도우 결과 재활용
sums.append(windowSum)
}
return sums
}2. 문자열 내 특정 패턴 찾기
문자열에서 길이 k인 부분 문자열 중 특정 조건(예: 사전 순서 최소/최대, 특정 문자 포함)을 만족하는 개수를 구하는 문제
예시: 문자열의 길이 k인 부분 문자열 중 사전순으로 가장 작은 값 찾기
func smallestSubstring(s: String, k: Int) -> String {
var smallest = s.prefix(k)
for i in 1...(s.count - k) {
let startIndex = s.index(s.startIndex, offsetBy: i)
let endIndex = s.index(startIndex, offsetBy: k)
let substring = s[startIndex..<endIndex]
if substring < smallest {
smallest = substring
}
}
return String(smallest)
}장점
- 시간 복잡도 개선: 많은 경우 반복적인 계산을 줄여 시간 복잡도를 O(n^2)에서 O(n)으로 줄일 수 있다.
- 메모리 효율성: 고정된 크기의 윈도우만 저장하므로 메모리 사용도 효율적이다.
적용 가능한 문제들
- 배열/문자열의 구간 합, 평균, 최소/최대값
- 부분 문자열 문제
- 특정 조건을 만족하는 부분 구간의 개수
- 슬라이딩 윈도우를 활용한 투 포인터 기법과 결합 (예: 두 수의 합 문제)
String.index 관련 주요 메서드
1. startIndex
- 역할: 문자열의 첫 번째 문자의 인덱스를 반환한다.
- 사용 예시:
let text = "Hello, Swift!" print(text[text.startIndex]) // "H"
2. endIndex
- 역할: 문자열의 마지막 문자 다음 위치를 나타낸다. 이 인덱스는 실제 문자를 참조할 수 없으며 범위를 벗어난 위치이다.
- 사용 예시:
let text = "Hello, Swift!" let lastIndex = text.index(before: text.endIndex) print(text[lastIndex]) // "!"
3. index(after:)
- 역할: 주어진 인덱스의 다음 인덱스를 반환한다.
- 사용 예시:
let text = "Hello" let secondIndex = text.index(after: text.startIndex) print(text[secondIndex]) // "e"
4. index(before:)
- 역할: 주어진 인덱스의 이전 인덱스를 반환한다.
- 사용 예시:
let text = "Hello" let lastIndex = text.index(before: text.endIndex) print(text[lastIndex]) // "o"
5. index(_:offsetBy:)
- 역할: 특정 인덱스에서 주어진
offset만큼 떨어진 인덱스를 반환한다. - 사용 예시:
let text = "Hello, Swift!" let index = text.index(text.startIndex, offsetBy: 7) print(text[index]) // "S"
6. index(_:offsetBy:limitedBy:)
- 역할: 특정 인덱스에서
offset만큼 떨어진 인덱스를 반환하되,limit을 넘지 않으면 해당 인덱스를 반환한다. 만약limit을 넘으면nil을 반환한다. - 사용 예시:
let text = "Hello" if let safeIndex = text.index(text.startIndex, offsetBy: 10, limitedBy: text.endIndex) { print(text[safeIndex]) } else { print("Index out of bounds") // 출력 }
7. distance(from:to:)
- 역할: 두 인덱스 간의 거리(문자 수)를 반환한다.
- 사용 예시:
let text = "Hello, Swift!" let start = text.startIndex let end = text.index(before: text.endIndex) let distance = text.distance(from: start, to: end) print(distance) // 12
8. firstIndex(of:)
- 역할: 특정 문자의 첫 번째 위치를 반환한다.
- 사용 예시:
let text = "Hello, Swift!" if let index = text.firstIndex(of: "S") { print(index) // 0번째 인덱스 print(text[index]) // "H" }
9. lastIndex(of:)
- 역할: 특정 문자의 마지막 위치를 반환한다.
- 사용 예시:
let text = "Hello, Swift!" if let index = text.lastIndex(of: "l") { print(index) // 3번째 인덱스 print(text[index]) // "l" }
10. firstIndex(where:)
- 역할: 조건을 만족하는 첫 번째 문자의 인덱스를 반환한다.
- 사용 예시:
let text = "Hello, Swift!" if let index = text.firstIndex(where: { $0.isUppercase }) { print(index) // 0번째 인덱스 print(text[index]) // "H" }
11. lastIndex(where:)
- 역할: 조건을 만족하는 마지막 문자의 인덱스를 반환한다.
- 사용 예시:
let text = "Hello, Swift!" if let index = text.lastIndex(where: { $0.isLowercase }) { print(index) // 12번째 인덱스 print(text[index]) // "t" }
12. indices
- 역할: 문자열의 모든 인덱스를 반환한다.
startIndex부터endIndex이전까지의 범위를 제공한다. - 사용 예시:
let text = "Swift" for index in text.indices { print(text[index], terminator: " ") // "S w i f t" }

Reciprocity lies in knowing enough
와 인덱스 정리 말끔.. 조아요