Basic SQL (Structural Query Language)
SQL의 기초 (구조 쿼리 언어)
본 장에서 알아볼 항목은 아래와 같다.
1. SQL의 기원
2. SQL Data 정의와 Data 타입
3. SQL에서 제약조건 설정하기
4. DB에서 자료를 추출하는 SQL
5. DML ( Data Manipulation Language = INSERT, DELETE, UPDATE)에 대해 알아보기
1. Sql의 기원
-
SQL (Structured Query Language)는 본래 SEQUEL 이라고 불린다.
-
SEQUEL (Structured English QUEry Language) - 한국어 씨-퀄
-
IBM의 Dadabase System인 SYSTEM R.에서 처음 개발되고 사용되었음.
-
현재 RDBMS의 표준이 되었다.
2. SQL Data 정의와 Data 타입
Schema 와 Catalog 개념 in SQL
SQL Schema
-
SQL Schema는 같은 DB그룹에 속해있는 테이블이나 구조를 묶기 위해 있다.
-
Schema 이름에 의해서 구별된다. ex) University
-
1) 인증 식별자를 포함한다. - Schema 소유주
-
2) 각각의 Element에 대해 Descriptors(기술자)를 포함한다. - CREATE TABLE...)
Schema Element는 테이블(Relation), 제약조건, views, domains 등을 포함한다.
각각의 Statement(구문)은 세미클론 (;)으로 끝을 낸다.
스키마를 생성하는 법에 대해
CREATE SCHEMA (Schema Name) AUTHORIZATION (Schema owner)
ex) CREATE SCHEMA UNIVERSITY AUTHORIZATION KIM를 입력하세요이때 모든 유저가 스키마를 생성할 권리를 위임받지는 않는데, 해당 권한은 DBA에 의해서 부여받아야한다.
Catalog
: 스키마 집합의 이름
카탈로그 안의 스키마들의 이름을 나타내고, 해당 요소들에 대한 상세한 설명을 포함한다.
같은 Catalog 에 속한 Schema에 속해 있을 때에만 Relation들에 대해 무결성 제약조건이 정의될 수 있다
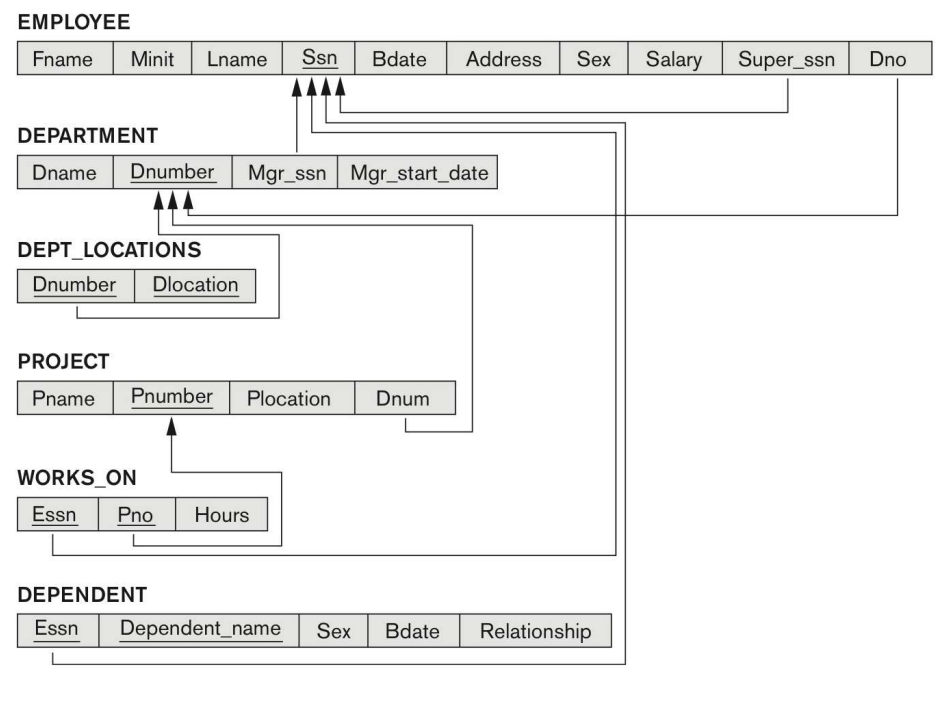
CREATE TABLE 명령어
새로운 Relation (R)을 지정하는 명령어이다.
R의 Attribute 값과 그들의 Data Type(domain), 초기 제약조건등을 설정한다.
제약조건은 NOT NULL, UNIQUE 등을 포함한다.
CREATE TABLE COMPANY.EMPLOYEE (explicit하게)
CREATE TABLE EMPLOYEE (implicit하게)Relation이 정의된 이후에 키 속성, 엔터티 무결성, 참조 무결성 제약조건 등이 Command에 의해 속성에 부여될 수 있다.
- 이 경우, ALTER TABLE을 이용한다.
Base Table (Base relations)
- 테이블과 이것들의 튜플 즉, 속하는 행들은 DBMS에 의해 파일로 저장된다.
Virtual Relations (Views)
-
CREATE VIEW로 생성된다
-
읽기 전용이며, 복잡한 Query를 완화하고 공간 절약을 위해서 사용된다.
-
추후에 자세하게 다룸.
Query문을 이용해서 직접 구축해보자
Relation Model of COMPANY
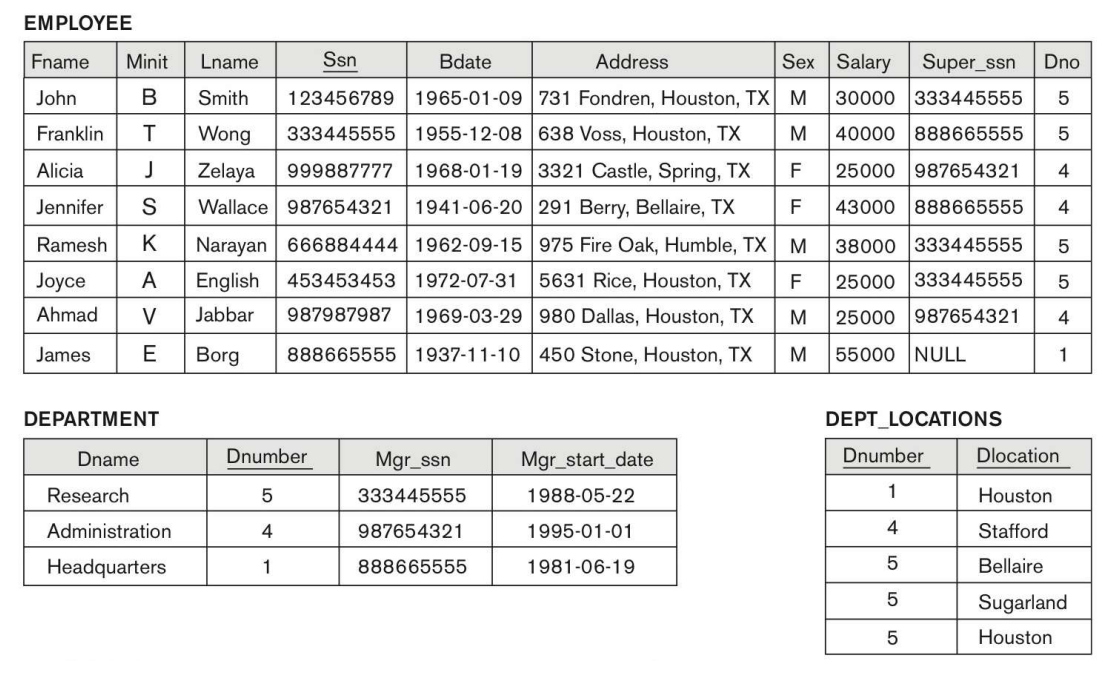
Database State (Tuple)
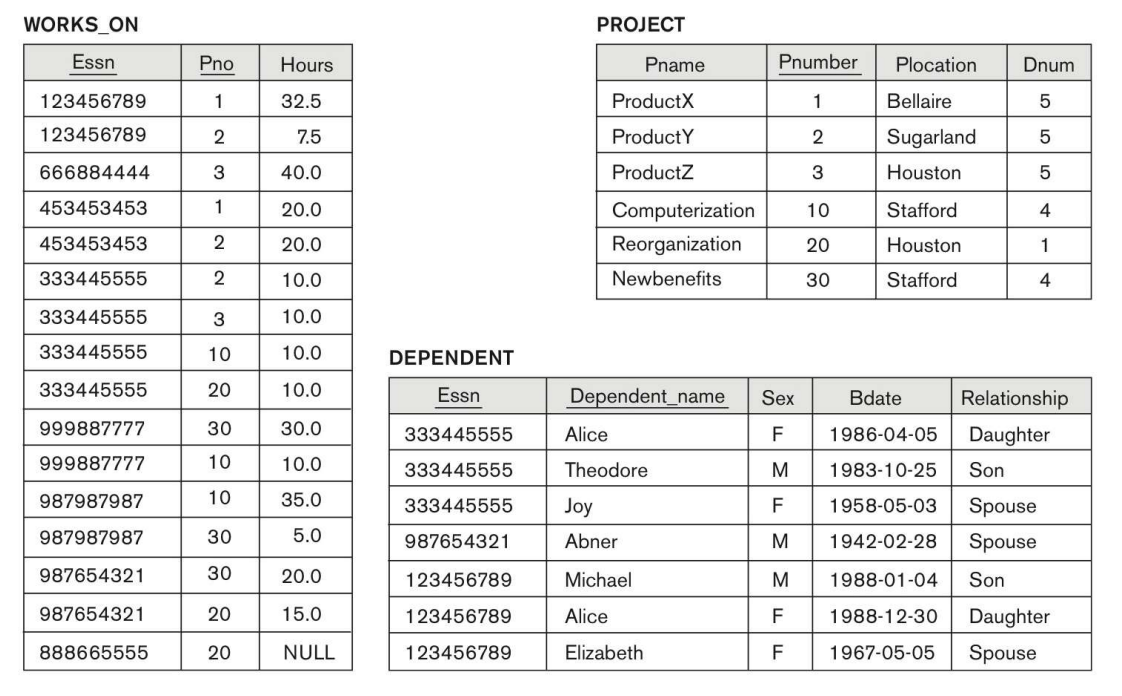
위 DB에 대한 DDL

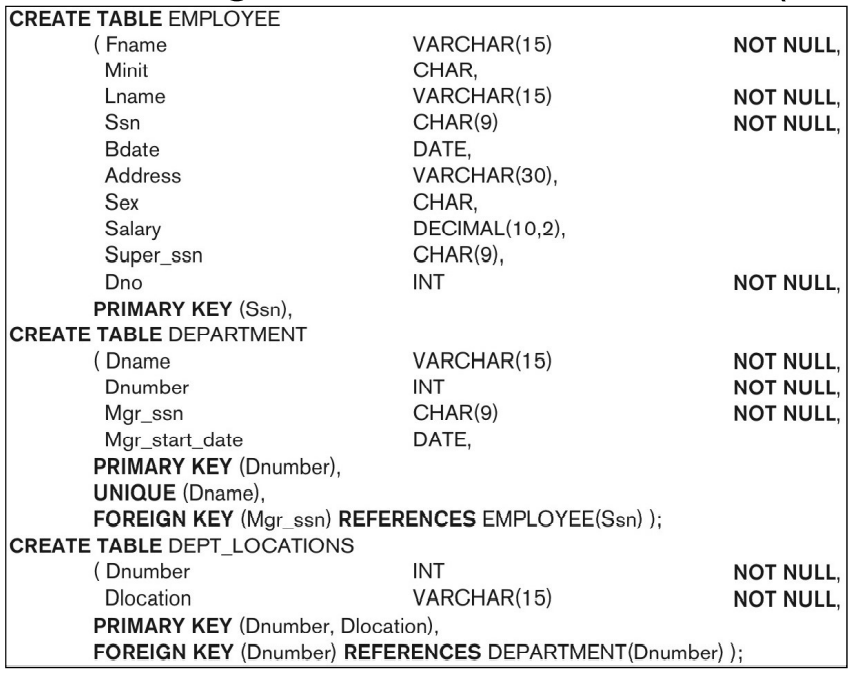
이때 Foreign Key 선언에 에러(순환 참조)가 발생한다.
- 순환 참조란 ?
EMPLOYEE 부분의 Super_ssn (super_ssn가 같은 Table의 ssn을 참조해서)
또한 Employee의 Dno가 생성되지 않은 Department Dnumber를 참조해서
이 경우 ALTER TABLE을 이용해서 TABLE 생성 후 조정을 해준다.

DATA TYPE 과 DOMAIN
Numeric
-
정수형 INT, INTEGER, SMALLINT
-
NUMBER (DECIMAL)
-
실수형 FLOAT, REAL, DOUBLE, PRECISION
-
Decimal형 - DECIMAL(i,j) - > i는 총 길이, j는 소수점의 자리 갯수
Character String
- CHAR(n), CHARACTER(n), n은 최대 길이를 뜻한다.
CHAR와 VARCHAR의 차이- CHAR
- 선언한 길이에 대한 크기 고정, CHAR값을 저장할 때는 문자열의 우측에 공백(tailing space)을 넣어 지정된 길이를 맞춤
- 최대길이 255
- VARCHAR
- 가변적 길이를 가진다.
- 65,535 까지 길이 가능
- 길이에 대한 정보를 저장하는 byte필요
- 255 이하는 1byte, 이상은 2byte의 추가 크기가 필요하다.
- CHAR
- VARCHAR(n), CHAR VARYING(n) ....
Bit Stirng
- BIT(n) n개의 비트를 나타낸다.
Boolean
- True, False, NULL을 가진다.
DATE
-
YEAR, MONTH, DAY, YYYY-MM-DD
-
E.g) DATE '2014-09-27'
-
Oracle에서는 TO_DATE()문이 'DATE'명령어를 대신한다.
TIME
-
HOUR, MINUTE, SECOND , HH:MM:SS
-
E.g) TIME '09:12:47'
Timestamp
- DATE와 TIME의 합
- INTERVAL
- 간격을 조절 ex ) INTERVAL 1 YEAR
DOMAIN
-
CREATE DOMAIN으로 사용 가능
-
Schema의 가독성을 올려줌
-
E.g) CREATE DOMAIN SSN_TYPE AS CHAR(9);
Type
객체를 저장하는 용도
UDTs를 생성하는데에 사용
객체 기반 Applications 지원
3. SQL에서 제약조건 설정하기
3번에 앞서 제약 조건들에 대해서 다시 떠올려보자
1. Key Constraint
: Primary Key는 중복되어선 안 된다.
Entity Constraint
: Primary Key는 NULL이 되어선 안 된다.
Referential Integrity Constraints
: 왜래키는 이미 존재하는 Priamary Key를 값으로 가져야하며 NULL이 될 수 있다.
Attribute 제약 조건
-
DEFAULT - 초기값을 설정하는 조건이다
-
NULL - 선언문 옆에 NULL 혹은 NOT NULL을 기입
-
CHECK 범위의 지정
(Dnumber INT NOT NULL CHECK (Dnumber > 10 and Dnumber <20)
Key Constraint
Primay Key

Unique

Foreign Key
-
Violation을 일으키는 Update를 Reject하는 것이 기본 세팅이다.
-
따라서, 참조 트리거 액션절을 추가해줘야한다.

-
SET NULL or SET DEFAULT을 처리하는 DBMS의 과정은
-
ON DELETE & ON UPDATE에서 동일하다.
-
CASCADE는 참조하는 tuples를 모두 삭제한다
- CONSTRAINT (제약조건 이름) 을 통해서 유저 지정 제약조건도 만들 수 있다.
3. DB에서 자료를 추출하는 SQL
기본적인 추출 SQL의 골자는 아래와 같다.

SELECT - 탐색하고자하는 Table의 Attribute 값들.
FROM - 탐색하고자하는 TABLE.
WHERE - 조건문
E.g) Employee Table의 나이가 20이상인 사람의 Name을 추출.

추출 SQL은 얼마든지 복잡해질 수 있는데,
복잡함을 야기하는 원인으로는 Join이 있다.
Join은 두 테이블을 이어야할때 사용되는 기법이다.
예시들로 살펴보자.
1.Simple (No Join)
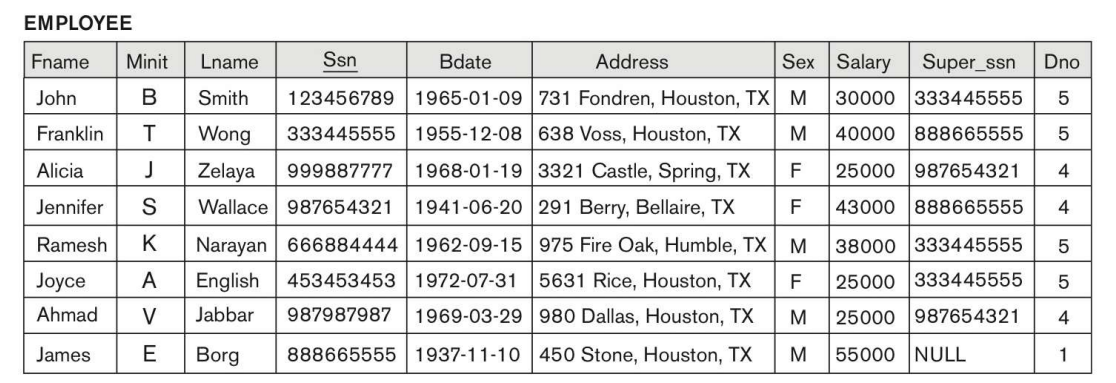
이름이 John B Smith인 사람의 생일과 주소를 출력


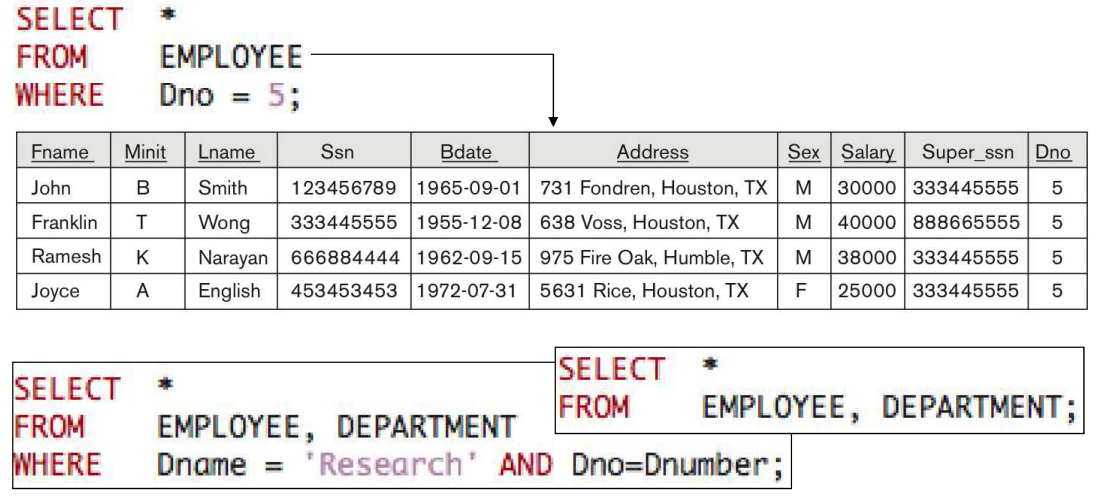
2. 2 way Join
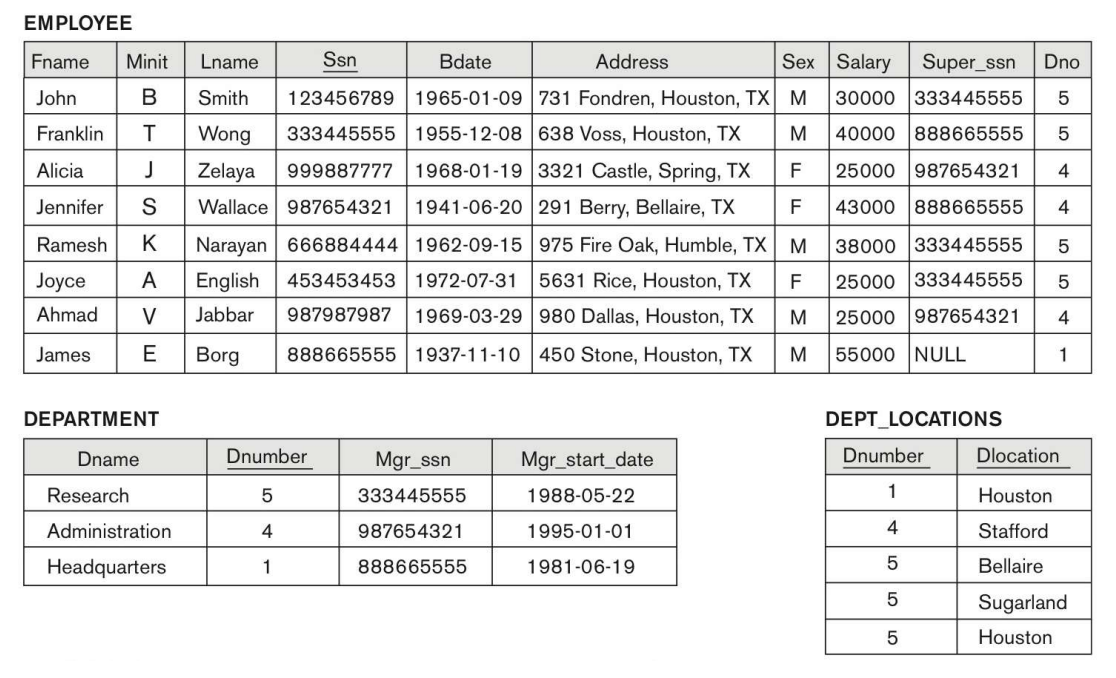
Research 부서에서 일하는 사람의 이름과 주소를 출력해라.

하단의 AND구문이 Join을 해주는 부분이다.
Employee Table의 Dno와, Department Table의 Dnumber을 이음으로써
두 테이블을 엮어줬다.

3. 3 way Join
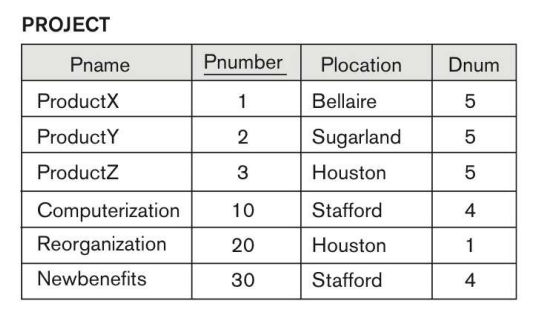
Project의 Location이 Stafford인 곳의 프로젝트 넘버와 해당 프로젝트를 담당하는 부서, 담당하는 사람의 이름과 주소, 생일을 추출하라.


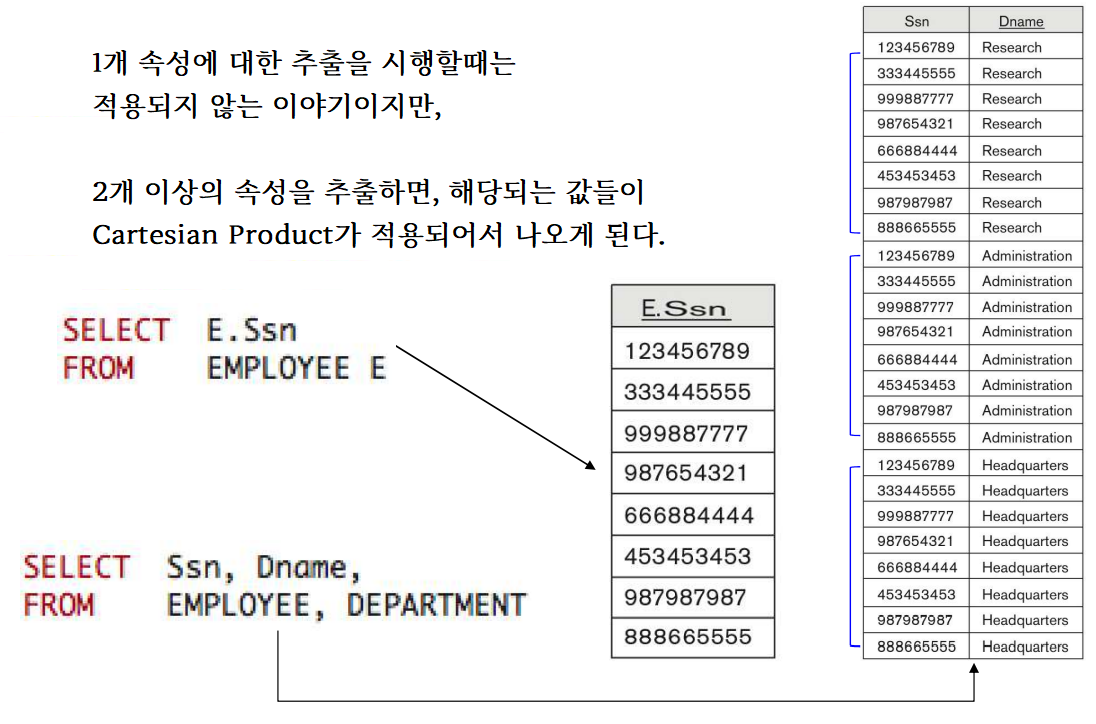
만약 다른 테이블 간, 같은 이름의 Attribute를 가진다면?
예시. Dno를 Dnumber로 Department의 Dnumber와 겹치게
Lname과 Dname을 둘 다 Name으로 고쳐버린다면 어떡할까.
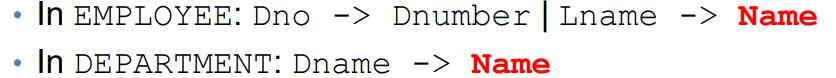

SQL에서는 테이블의 클래스 참조자 ( . ) 을 찍음으로서 이를 구분할 수 있다.
또한, Aliasing을 통해 이름을 변경시켜줄 수 있다.
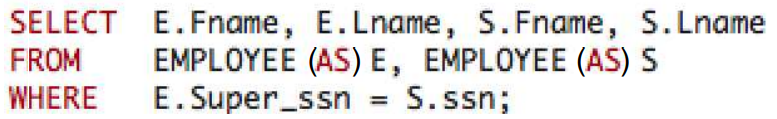
Aliasing을 할때, 테이블의 첫 철자를 대문자로 변경해서 쓰거나
Attribute 값을 변경할때는 E_Fname 같은 형식으로 짓는다.
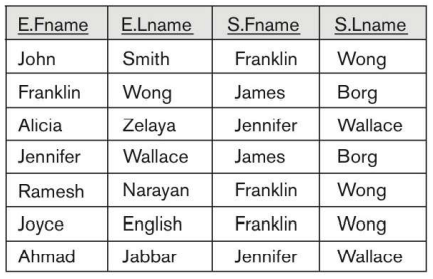
From절에서 Attribute 값들에 대해서 Renaming을 할 수도 있고, SELECT절에서도 가능하다.
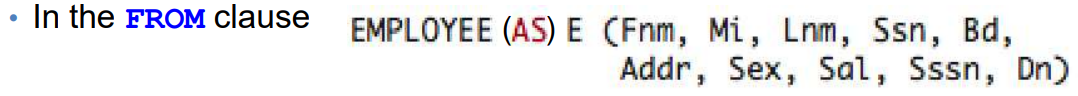

추출에 있어서 주의할 점이 있다.
Asterisk ( * )의 사용
Astreisk는 모든 Tuple을 추출하는 명령어이다.
아래와 같이 사용할 수 있다.
특별한 주문이 없으면 중복을 제거하지않는 SQL
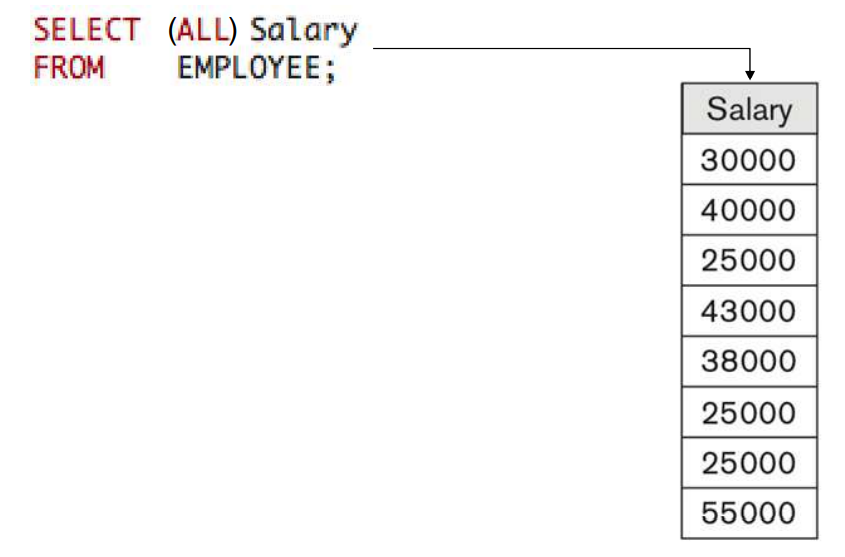
왜 자동적으로 중복을 제거하지 않을까??
-
중복 (dupliacation) 제거 작업은 Cost가 높은 동작이다
-
유저가 제거되지 않은 정보를 원할 수도 있다.
-
집계 함수 (SUM, AVG...) 등이 적용될때는 중복도 고려해야한다.
중복을 제거하기 위해서는 SELECT에 DISTINCT를 넣어주면 된다.

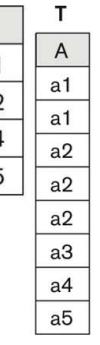
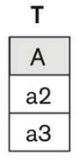
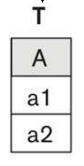
집합 연산 (UNION, EXCEPT, INTERSECT)
- 두 Relation R(A)와 S(A)에 대해서
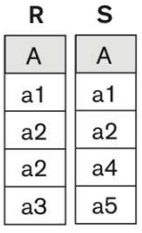
- R(A) UNION ALL S(A) --- 단순 합
- R(A) EXCEPT ALL S(A) --- R(A)에서 S(A)를 뺀 것
- R(A) INTERSECT ALL S(A) --- 공통 부분만 출력
E.g)
뒷 이름이 'Smith'인 사람이 Employee & Manager로 참가한 프로젝트의 Pnumber를 출력하라

특정 문자열을 포함한 구문을 출력
- Like와 %를 사용한다.
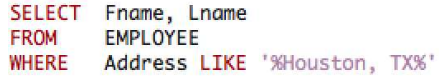
작은 따옴표 '' 사이에 포함을 체크할 문자열을 넣고 %로 감싼다.
%문자를 그대로 쓰려면 Escape 문자 \를 넣으면 됨.
특정 문자열 시작하는지 여부는 '~~~%'
특정 문자열로 끝나는지 여부는 '%~~~'
BETWEEN

ORDER BY (ASC, DESC)

ORDER BY절은 생략되면 ASC (오름차순 정렬이다)
뒤에 ASC, DESC에 따라 각각 오름차순, 내림차순 정렬을 할 수 있다.
여러개를 설정 값으로 넣을시, 앞에 온 요소를 우선으로 정렬한다.
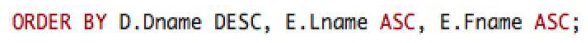
2. DML에 대해 알아보기
DML ( Data Manipulation Language = INSERT, DELETE, UPDATE)에 대해 알아보기
INSERT
: Tuple을 Table(Relation)에 넣기 위해서 사용됨
위 방식은 Attribute의 순서가 지켜져야 한다.

내가 지정한 값만 넣을 수 있는데 나머지 값들은 default값 혹은 NULL로 채워진다.

위 예시처럼 Query 문의 결과를 INSERT 할 수도 있다.
LIKE를 통한 TABLE 복사, 그리고 Asterisk를 이용한 데이터 이동
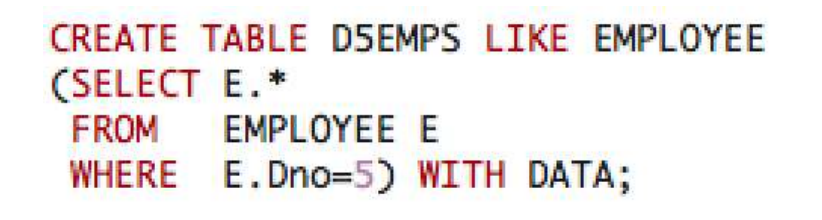
UPDATE
: Table안의 Tuple을 수정할때 사용된다.UPDATE할 Tuple을 구분하기 위해 WHERE절을 사용한다.

바뀐 후의 모습은 SET을 통해서 설정한다.
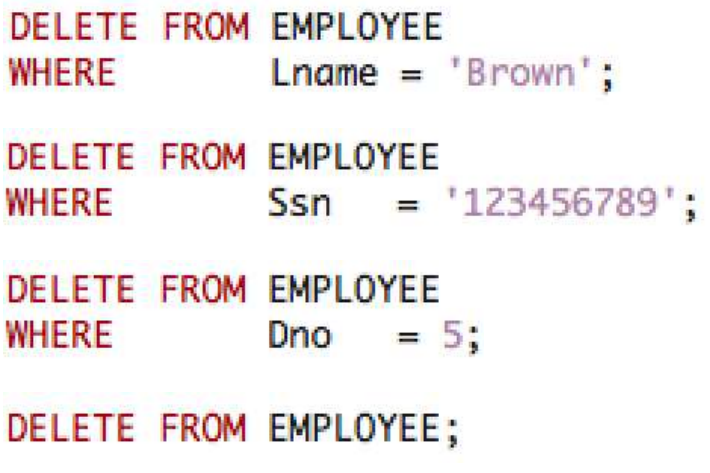
DELETE : Tuple을 삭제할때 사용한다.
삭제할 Tuple을 구분하기 위해서 WHERE절을 사용한다.
CASCADE를 붙이면 참조 무결성을 무시하고 강행한다.
그리고 삭제될 Tuple을 참조하는 다른 Tuple들 역시 삭제된다.