- 로켓 system에서 deadlock을 풀기위한 방법
- memory leak만큼 deadlock은 치명적
- deadlock은 경쟁이 붙어서 멈춰버린 상황이라 누구의 탓을 할 수 없다.
- System에 있는 R(resource)
Ri의 resource가 Wi개만큼 있다.
- request, use, release
- 이러다가 deadlock 발생
Deadlock 발생 조건
- 다음 4가지가 동시에 만족되었을 때 일어날 수도 있다.(항상 발생은 아님)
- Mutual exclusion: 오직 하나의 프로세스만 하나의 자원을 사용할 수 있다. 적어도 하나의 자원은 공유가 불가능한 자원이다.
- no preemeption: 중간에 끊을 수 없는 상황, 이미 할당된 자원이 갑자기 반납되어서는 안된다. 프로세스가 스스로 반납.
- Hold and wait: 적어도 하나의 자원을 보유한 프로세스가 다른 프로세스의 자원을 추가로 얻기를 기다릴 때
- circular wait: 프로세스들이 자원을 소유하고 요청하는 형태가 원형을 이룰 때를 말한다.
각 프로세스에는 하나의 자원이 할당되어있고, P1은 P2자원을 기다림, P2는 P3자원을 기다림, P3는 P1자원을 기다릴 때 원형을 이룬다.
Handling Deadlocks
1) deadlock이 절대 발생하지 않도록 설계
-
deadlock prevention: OS에서 deadlock이 발생하지 않도록 4가지 조건 중 최소 1가지를 절대 만족시키지 않도록 한다. → 요청 방법에 제한을 둔다.
-
mutal exclusion: 공유 가능한 자원들은 deadlock에 걸리지 않지만 근본적으로 공유가 불가능한 자원들 때문에 이 조건을 어겨 예방하는 것은 불가능하다.
-
hold and wait: 자원을 요청할 때 다른 자원들을 점유하지 않을 것을 보장하면 된다.
- 프로세스가 모든 자원을 확보했을 때만 실행되도록 한다.
- 프로세스가 어떠한 자원도 없을 때만 자원을 요청한다. ex) 1번, 2번 resource를 동시에 잡을 수 있을 때만 요청하도록 한다.
→ 할당된 모든 자원이 바로 사용되지 않기에 자원의 이용도가 낮을 수 있다.
→ 기아 상태 유발 가능 최소한 하나가 항상 다른 프로세스에게 할당되어 있기 때문에 -
no preemeption: 1번 resource를 잡고있는 process가 2번 resource를 요청했을 때 바로 받을 수 없다면 1번과 (다른 프로세스에게 할당된) 2번 모두 release 하도록 한다. release함으로써 preemption이 되어버린다.
또한, 프로세스는 요청 중인 새로운 자원을(2번) 할당받고 또한 대기 중에 선점되었던(끊겼던) 모든 자원(1번)을 회복할 때에만 다시 시작할 수 있다. -
circular wait: resource에 ordering(순서)을 부여하여 순서에 맞게 resource를 요청할 수 있고 할당받을 수 있게 한다. 동시에 요청 불가능하기에 원형을 이룰 수 없다.
-
→ 장치의 이용률 저하, 시스템 처리율(throughput) 감소의 문제점
-
deadlock avoidance: deadlock 상황을 회피 → 자원이 어떻게 요청될 지에 대한 추가 정보를 제공하도록 요구한다.
-
특정 process에 대한 사전 정보가 있다고 가정
(어떤 프로세스에 대한 자원 요청 순서 정보) -
시스템이 항상 safe satae에 있도록 보장하는 것을 말한다. 단, unsafe state라고 해도 deadlock이 꼭 발생하는 것은 아니다.
-
safe state: deadlock에 걸릴 수 없는 상태
어떤 순서로 프로세스들이 (최대 요구)자원을 요청하더라도 deadlock을 야기시키지 않고 차례로 모두 할당해 줄 수 있는 상태 -
unsafe state: deadlock에 걸릴 가능성이 있는 상태 (무조건은 아님 !)
How ?
- single instance
- Resource-Allocation graph scheme
graph를 통해 어떤 상황이 발생할지 예측: 뭐가 받아들여질 때 cycle이 완성되는지를 확인. (인스턴스가 하나일 때)
-
claim edge(예약 간선) , 단 점선으로 표시
-
request edge(요청 간선)
-
assignment edge(할당 간선)
사이클을 형성하지 않을 때에만 요청을 허용한다.
- Banker’s algorithm : worst case에서조차 deadlock에 빠질 것 같은 것을 피한다. (multiple instance)
- Available: 자원의 종류 별로 가용한 자원의 개수
Available[j] = k → j번째 R에는 k개만큼의 인스턴스를 사용할 수 있다. - Max: 각 프로세스가 최대로 필요하는 자원의 개수
Max[i, j] = k → i번째 P가 j번째 R의 인스턴스를 최대 k개만큼 요청할 수 있다. - Allocation: 각 프로세스에 현재 할당된 자원의 개수
Allocation[i, j] = k → i번째 P가 j번째 R의 인스턴스를 k개만큼 할당 받았다. - Need: 향후 요청할 수 있는 자원의 개수
Need[i, j] = k → i번째 P가 작업을 완료하기까지 j번째 R을 k개 더 필요하다.
-
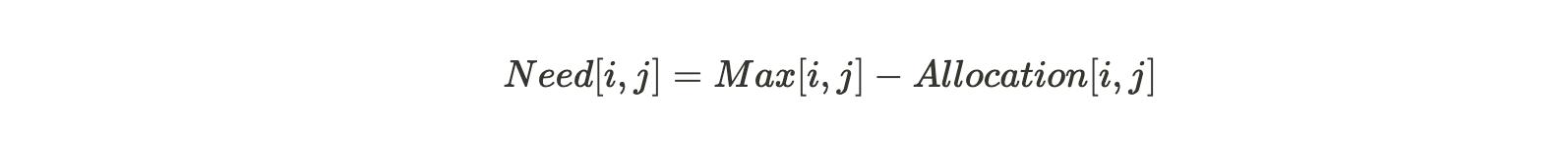
2) deadlock이 발생했을 때 최대한 recover
3) daedlock 무시(reboot) -deadlock은 드물게 발생하여 이 방법은 비용이 적게 든다.
deadlock detection - wait-for 그래프 (Pi->Pj): Pi가 Pj를 기다릴 때 1) single instance
주기성을 가짐(deadlock인지 계속 확인)
- 주기 결정
- 얼마나 자주 발생?
- 한 번 수행하는데 얼마만큼의 복잡도?
- roll back: 프로세스를 이전 상태로 돌려놓는 것
- 공동 책임이라 다 종료시키는 방법
- 하나씩 프로세스를 종료시키고 deadlock이 풀렸는지 확인. (아니라면 roll back)
- 자원을 많이 쓰고 있는 프로세스를 종료시키기
- 많은 자원을 요청하는 프로세스를 종료시키기
- Recovery from deadlock
- selecting a victim
- total rollback: 하나씩 자원을 뺏어가면서 safe state에 있는지 확인(rewind)하며 완전히 처음으로 돌아가는 것(roll back의 worst case)
- starvation: 잡았던 자원을 계속 풀 수 있어서
- deadlock은 발생하면 매우 치명적(자원을 잡고 멈춰버리기에)
