✅혼자 공부하는 데이터 분석 with 파이썬
진도 : Chapter 02
실습파일 : Library.ipynb

(완료) 기본 미션 : p.150의 확인 문제 1번 풀고 인증하기

(완료) 선택 미션 : p. 137 ~ 138 손코딩 실습으로 원하는 도서의 페이지 수를 추출하고 화면 캡처하기
✅Chapter 02 데이터 수집하기 (2)
웹 스크래핑 / 뷰티플수프
- yes24 사이트 활용하여 실습하기
- '도서 검색 결과'를 html로 가져온다. - requests.get()
- '도서 검색 결과' -> '도서 상세 페이지' <태그>href를 추출한다. - 개발자도구
- '도서 상세 페이지'를 html로 가져온다. - requests.get()
- '도서 상세 페이지' -> '도서 쪽수' <태그>text를 추출한다. - 개발자도구
[웹 스크래핑]
-
원하는 열만 새로운 데이터프레임으로 만들기
: 원하는 열 이름을 리스트로 만들어, 데이터프레임의 '인덱스' 처럼 사용
new_df = df[['열1', '열2', '열3']] -
데이터프레임 행과 열 선택하기 : loc, iloc 메서드
df.loc[[행], [열]] 혹은 [행 슬라이싱, 열 슬라이싱]
df.loc[[행인덱스, 행인덱스] , [열 이름, 열 이름]]
=df.iloc[[행인덱스, 행인덱스] , [열 인덱스, 열 인덱스]]
requests.get() 함수를 통해 반환한 응답 객체를 사용,
도서 검색 결과 페이지 'HTML을 출력'
-> r.text[뷰티플수프]
개발자 도구 > SELECT > HTML 위치 파악 > 뷰티플수프로 파싱.
from bs4 import BeautifulSoup
# 클래스 객체 생성 : BeautifulSoup(parshing할 HTML문서, parser)
soup = BeautifulSoup(r.text, 'html.parser')
# 태그 위치 찾기 : find(태그이름, attrs={_속성:속성값_})
prd_link = soup.find('a', attrs={'class':'gd_name'})
---
print(prd_link)
> 해당되는 html만 출력된다.
print(prd_link['href']
> 해당되는 html의 'href'만 출력된다.
---
# href_(=Hypertext Reference)_
url2 = 'http://www.yes24.com' + prd_link['href']
r2 = requests.get(url)
print(r2.text)
---
# 쪽수 text
soup2 = BeautifulSoup(r2.text, 'html.parser')
prd_detail = soup2.find('div', attrs={'id':'infoset_specific'})
print(prd_detail)def get_page_cnt(isbn):
## 도서 검색 페이지
url = 'http://www.yes24.com/Product/Search?domain=BOOK&query={}'
## 도서 검색결과 페이지
# HTML 추출 : requests.get()
r = requests.get(url.format(isbn))
# HTML 파싱 : BeautifulSoup()
soup = BeautifulSoup(r.text , 'html.parser')
# href(hyperlink ref)를 만드는 <a> 태그 파싱하기 : find() => 제품정보로 들어가는 href 얻기
prd_href = soup.find('a', attrs={'class':'gd_name'})
if prd_href == None :
return ''
## 도서 상세 페이지로 진입
# HTML 추출 : requests.get()
# HTML 파싱 : BeautifulSoup()
url = 'http://www.yes24.com' + prd_href['href']
r = requests.get(url)
soup = BeautifulSoup(r.text ,'html.parser')
# 품목정보 위치찾기
prd_detail = soup.find('div', attrs = {'id':'infoset_specific'})
# 쪽수 위치찾기
prd_tr_list = prd_detail.find_all('tr')
# 쪽수 출력
for tr in prd_tr_list:
if tr.find('th').get_text() == '쪽수, 무게, 크기':
return tr.find('td').get_text().split()[0]
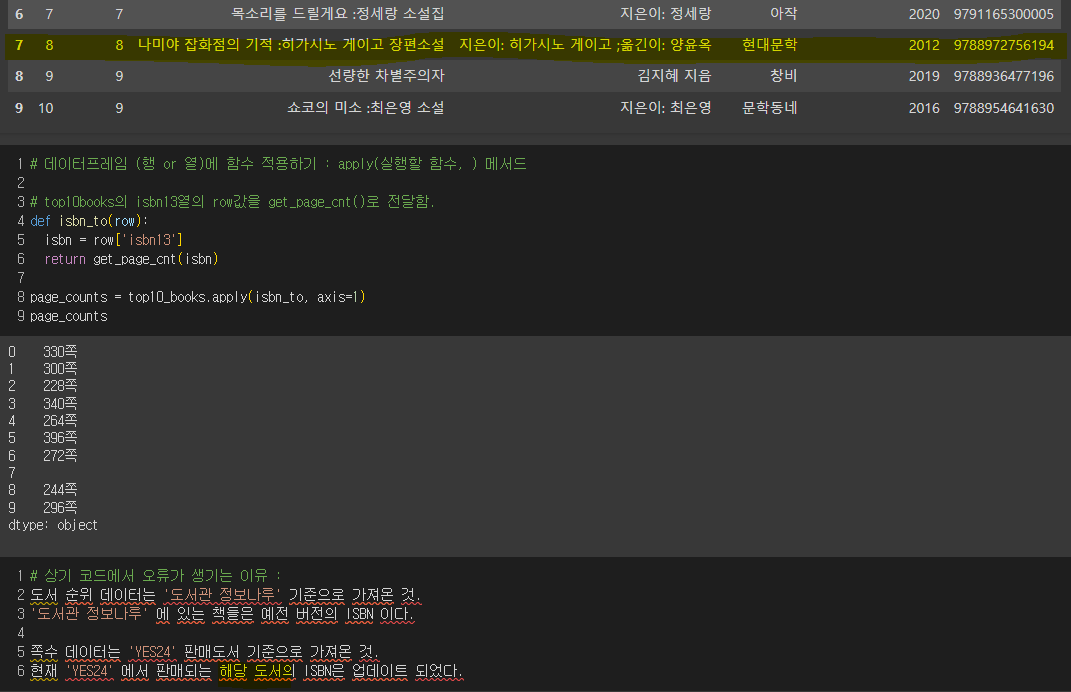
return''top10_books = books.head(10)
top10_books
# 데이터프레임 (행 or 열)에 함수 적용하기 : apply(실행할 함수, axis=) 메서드
# top10books의 isbn13열의 row값을 get_page_cnt()로 전달함.
def isbn_to(row):
isbn = row['isbn13']
return get_page_cnt(isbn)
page_counts = top10_books.apply(isbn_to, axis=1)
page_countsmerge() 함수의 매개변수.
# 객체이름 지정 # 쪽수 리스트 'page_counts'객체를 df의 열로 합치기 page_counts.name = 'page_cnts' print(page_counts)
두 객체의 인덱스 기준으로 합치는 경우,
#left_index & right_index = True top10_with_page_cnts = pd.merge(top10_books, page_counts, left_index=True, right_index=True) top10_with_page_cnts
df1 = ['col1'(abc), 'col2'(123)]
df2 = ['col1'(abc), 'col3'(10 20 30)]on 매개변수 : 합칠 때 기준이 되는 열
pd.merge(df1, df2, on='col1') >df = ['col1', 'col2', 'col3'] 합치려하는 열 이름 다른경우 left_on = df1의 열이름 right_on = df2의 열이름how 매개변수 : 합쳐질 방식
#기본 값 - inner (값이 같은 행만 합침) left(df1 기준으로 df2를 합침. df2에 없으면 NaN값) right(df2 기준으로 df1를 합침. df1에 없으면 NaN값) outer(모든 행을 유지하면서 합침. 없으면 NaN값)
**웹 스크래핑 시 주의점.**
1) 웹사이트에서 스크래핑을 허락하였는지 확인
: 대부분의 웹사이트는 검색 엔진이나 스크래핑 프로그램이 접근가능한 페이지, 접근불가한 페이지를 명시한 'robots.txt' 파일을 가지고 있다. ex) http://www.yes24.com/robots.txt
2) HTML 태그를 특정 불가능한 경우, 웹 스크래핑이 어려움.
HTML 대신 자바스크립트를 이용하는 웹 페이지인 경우, 셀레니움 등을 사용해야 함.
CHEER UP :)