
- 정규화 ,NF
- 정규화
- 목적
- 삽입 , 수정, 삭제의 이상현상제거
- DB를 잘못설계하면 불필요한 데이터 중복으로 인해 공간 낭비됨 ->이상(ANOMALY)현상
- 데이터의 중복 최소화
- 대부분 3차 정규화까지만 진행
- 삽입 , 수정, 삭제의 이상현상제거
- 반정규화 : 정규화 된걸 합치는 것
- 너무 분리하면 복잡해짐.. 적당한 정규화가 필요함
- 목적
- 1차 정규화(1NF)
- 하나의 컬럼에 값이 1개씩만 있어야 함, 반복적인 컬럼 값이 나타나는 경우
- 상품명: 바지1, 바지2, 바지3 ... 검색이 힘듦
- 하나의 컬럼에 값이 1개씩만 있어야 함, 반복적인 컬럼 값이 나타나는 경우
- 2차 정규화(2NF)
- 테이블의 모든 컬럼이 서로 관계가 있어야 함
- 모든 컬럼이 서로 관계가 없는 경우 (분리해서 관련 있는 것끼리 엮기)
- USER
이름 나이 상품명
- USER
- 3차 정규화
- 이름 , 시 ,구 , 동, 우편번호
- →수집시 우편번호로 시, 구, 동을 알 수 있기에 중복된 데이터 생길 가능성 o
- 이름 , 시 ,구 , 동, 우편번호
- 조합키
-
PK두개를 합침
CONSTRAINT CAR_PK PRIMARY KEY(ID, BRAND); -> 두개가 같이 중복되지만 않으면 됨
-
- 이상현상(ANOMALY)
- 삽입이상 : 새데이터 삽입을 위해 불필요한 데이터도 삽입해야 함
- (담당 프로젝트가 정해지지 않은 사원이 있다면 ,프로젝트 코드에 NULL을 작성할 수 없으므로 '미정'이라는 코드를 따로 만들어서 삽입해야함)
- 갱신이상: 중복 행 중 일부만 변경하여 데이터가 불일치하게 되는 모순의 문제
- 한 명의 사원은 반드시 하나의 부서에만 속할 수 있음-> 만약 한동석이 보안팀으로 부서를 옮길 시 3개 모두 갱신해주지 않는다면 개발팀인지 보안팀인지 알 수 없음..
- 삭제이상: 행을 삭제하면 꼭 필요한 데이터까지 함께 삭제됨
- 이순신이 담당한 프로젝트를 드랍한다면 이순신 행을 모두 삭제하게 됨
- 삽입이상 : 새데이터 삽입을 위해 불필요한 데이터도 삽입해야 함
→이러한 현상이 발생하는 이유: 테이블이 정규화 되어있지 않기때문
-정규화를 위해서는 각 컬럼간의 관련성 파악, 관련성=함수적 종속성(FUNCTIONAL DEPENDECY)
따라서 하나의 테이블에서는 하나의 함수적 종속성만 존재하도록 정규화
-
함수: X-> Y
- X: 결정자 ->X가 Y를 결정
- Y: 종속자 -> Y가 X에 종속
-
NULL
값은 없으나 주소를 가짐
정의되지 않은 값, 빈 값대신 미정값을 부여할 때 사용(PK는 불가능, FK는 가능) -
NOT NULL 제약 조건
ALTER TABLE 테이블명 MODIFY 컬럼명 NOT NULL; -
제약조건 삭제
ALTER TABLE 테이블명 DROP CONSTRAINT 제약조건 이름; -
조건식
컬럼명 IS NULL: NULL이면 참
컬럼명 IS NOT NULL: NULL이 아니면 참 -
UNIQUE
- 중복불가능,NULL 가능 (무결성: 데이터의 정확성 유지)
- NAME NUMBER(4) NOT NULL UNIQUE , -> 동시에 사용 가능
- CHECK - > NULL 허용
- null
- NULL 값을 다른 값으로 변경
- NVL() : NULL 값 대신 다른 값으로 변경 후 검색
SELECT NVL("POSITION", '미정') FROM PLAYER WHRER "POSITION" IS NULL; SELECT NVL("POSITION", '미정') FROM PLAYER; - NVL2(): NULL일 때의 값, NULL이 아닐 때의 값을 각각 설정
SELECT NVL2("POSITION", '확정', '미정') FROM PLAYER; SELECT PLAYER_NAME "선수이름" ,NVL2("POSITION", '확정', '미정') AS 포지션 FROM PLAYER;
- NVL() : NULL 값 대신 다른 값으로 변경 후 검색
-함수
- 1.숫자형 함수(DUAL) -정수 또는 실수 NUMBER를 대상으로 하는 함수
- 오라클 임시테이블 - 수식, 함수 결과값 확인 가능
- 절대값
SELECT ABS(-10) FROM DUAL; ABS로 감싸면 음수여도 양수가 됨 - 양의정수 (1), 영(0), 음의 정수 (-1) 판단
SELECT SIGN(-234), SIGN(0), SIGN(123) FROM DUAL; 결과 -> -1 , 0 , 1 - 나머지(% 모듈러스)
SELECT MOD(10,3) FROM DUAL; 결과->1 (남은값) - 값보다 큰 최근접 점수(올림)
SELECT CEIL(3.14), CELI(-3.14) FROM DUAL -> 4, -3 - 값보다 작은 최근접 점수(내림)
SELECT FLOOR(3.14), FLOOR(-3.14) FROM DUAL ->3, -4 - 반올림
SELECT ROUND(3.5515) FROM DUAL; ->4
SELECT ROUND(3.5515,1) FROM DUAL; (숫자, 반올림 자릿수) ->3.6 - 소수점 버림
SELECT TRUNC(3.9) FROM DUAL; ->3 - 코드
-ABS(N) 절대값 --실수->실수 -TRUNC(숫자, 자리수):소수점 이하 자리수 맞추기 위해서 버림 3.177567->3.17 SELECT TRUNC(3.177567,2) FROM dual; -ROUND(숫자, 자리수) SELECT ROUND(3.177567,2) FROM dual; --실수->정수 --CEIL(숫자): 실수를 정수로 올림으로 변환 SELECT CEIL (3.177567) FROM DUAL; --4 --FLOOR(숫자): 실수를 정수로 내림으로 변환 SELECT FLOOR(3.177567) FROM dual; --3
- 절대값
- 오라클 임시테이블 - 수식, 함수 결과값 확인 가능
- 2.문자열 함수 실제로는 테이블의 컬럼으로 실행 SELECT LOWER(컬럼명) FROM 테이블명
SELECT INITCAP('hello') FROM DUAL; --INITIAL capital: 첫번째 대문자 SELECT UPPER('hello') FROM DUAL; --대문자로 변환 SELECT LOWER('OraCle')FROM DUAL; --소문자로 변환 SELECT LENGTH ('oracle') FROM DUAL; --문자열길이 SELECT SUBSTR('java program',3,5) FROM DUAL; ---부분 추출(문자열, 위치, 길이) 결과/ 오라클에서 인덱스는 1부터시작 SELECT SUBSTR('java program',-5,3) FROM DUAL; --부분추출결과 : 위치 음수이면 문자열 뒤에서부터(뒤에서부터 5번째 3개) SELECT REPLACE('java progam','pro','프로') FROM DUAL; --문자열 바꾸기 . java 프로gram SELECT INSTR ('java program','og') FROM DUAL;; --자바의 indexof/ 해당 문자열이 없으면 결과0 SELECT trim (' java program ')FROM DUAL; --공백(불필요한 앞뒤 공백)제거 SELECT LENGTH (' java program ') FROM dual; --공백포함 16 SELECT LENGTH (trim(' java program ')) FROM dual; --공백제거 12 -
날짜함수: TO_CHAR(날짜형식을 문자열로 변환) TO_DATE(문자열을 날짜형식으로 변환)
SELECT SYSDATE ,SYSTIMESTAMP FROM DUAL; -SYSTIMESTAMP는 표준시와의 시차(타임존) 표시 SELECT TO_CHAR(SYSDATE,'YYYY-MM-DD') FROM DUAL; --기호는 상관없음 -기호는 상관없음, 한글은 x 사용하려면 'YYYY"년"' ""를넣어야함 -자동캐스팅해줄 수 있는 패턴은 YYYY-MM-DD만 가능 YYYY-MM-DD HH24:MI:SS 24시간기준 YYYY-MM-DD HH:MI:SS AM 12시간기준(AM,PM)
-
문자열은 패턴을 알려줘야 변경할 수 있다 TBL_MEMBER에 JOIN_DATE 인서트
INSERT INTO TBL_MEMBER VALUES (2,'박나연','parkny@gmail.com', TO_DATE('2022-10-24 13:24:55','YYYY-MM-DD HH24:MI:SS')); INSERT INTO TBL_MEMBER VALUES (10,'홍길동','GDhONG@gmail.com',TO_DATE('20240109','YYYYMMDD')); -
날짜 찾기
WHERE TO_CHAR(BUYDATE,'YYYY-MM')='2022-04' WHERE BUY_DATE BETWEEN TO_DATE('2023-07-01','yyyy-mm-dd')AND TO_DATE('2023-12-31','yyyy-mm-dd') WHERE BUY_DATE BETWEEN '2023-07-01' AND '2023-12-31'
-
- 3-1. 날짜 계산 -’월’만 계산할때 수식 사용.. 일과 년은 그냥 더하면 됨
SELECT ADD_MONTHS(SYSDATE,3) FROM DUAL; -오늘날짜 +3개월이후. 첫번째 인자는 날짜형식, 두번째는 더해지는 값 SELECT TO_CHAR(ADD_MONTHS(SYSDATE,3),'YYYY/MM/DD') FROM DUAL; -문자열 패턴 기호 - 또는 / 또는 구분기호 없음 가능 SELECT MONTHS_BETWEEN(SYSDATE, TO_DATE('2022-09-23')) FROM DUAL; -지정된 2개의 날짜 사이에 간격(월). 결과는 소수점 SELECT TRUNC(SYSDATE) - TO_DATE('20240110','YYYYMMDD')FROM DUAL;-2개의 날짜형식 값 간격(일) 날짜끼리 뺄셈 SELECT TRUNC(SYSDATE) FROM DUAL; - 2개의 날짜의 간격(일). TRUNC(SYSDATE)는 일(DAY)까지로 변환 SELECT SYSDATE +5 FROM DUAL; - 집계(개수, 최대값, 최소값, 합계, 평균) 함수 - 그룹함수
- 집계함수: 여러개의 값을 하나의 값으로 집계하여 나타냄 → NULL은 제외됨.. 평균 구할때 조심
- WHERE 절에서는 사용 X , HAVING에서 가능
- GROUP BY 구문과 주로 쓰임, 집계함수는 다른 컬럼과 함께 조회하려면 GROUP BY가 필요
- AVG(): 평균
MAX(): 최대값
MIN(): 최소값
SUM(): 총 합
COUNT(): 개수 - 예시
- 성적 테이블의 과목 컬럼 중 국어 값을 가는 전체 행 개수
- 1)성적 테이블의 전체 행 개수
- *SELECT COUNT()** FROM TBL_SCORE ;
- 2) 성적 테이블의 과목 컬럼 중 국어 값을 가는 전체 행 개수
SELECT COUNT() FROM TBL_SCORE ts WHERE SUBJECT = '국어';
- 조회된 함수결과에 컬럼명을 주려면 AS "컬럼명"
SELECT COUNT() AS "COUNT" FROM TBL_SCORE ts WHERE SUBJECT = '국어';
- 오류: 집계함수는 다른 컬럼과 함께 조회하려면 GROUP BY가 필요
SELECT SUBJECT, COUNT() FROM TBL_SCORE ts ;
- 조회 칼럼에 SUBJECT 추가 가능
SELECT SUBJECT ,COUNT(**) FROM TBL_SCORE ts GROUP BY SUBJECT ;
- *오류 SELECT SUBJECT ,COUNT(**) FROM TBL_SCORE ts GROUP BY STUNO ; - 3) 성적 테이블의 'JUMSU' 컬럼의 합계
- SELECT SUM(JUMSU) FROM TBL_SCORE ts ;
- 4) 특정 과목(국어점수)
- SELECT SUM(JUMSU) FROM TBL_SCORE ts WHERE SUBJECT = '국어' ;
- 5) 평균
- SELECT AVG(JUMSU) FROM TBL_SCORE ts ;
- 6) 최대값
- SELECT MAX(JUMSU) FROM TBL_SCORE ts ;
- 7)최솟값
- SELECT MIN(JUMSU) FROM TBL_SCORE ts ;
- 8)여러개
- SELECT COUNT(*), SUM(JUMSU) "합계" ,AVG(JUMSU) "평균" FROM TBL_SCORE ;
- GROUP BY는 그룹화 컬럼명1, 그룹화 컬럼명2... 로 할 수 있음
- 1)성적 테이블의 전체 행 개수
- 성적 테이블의 과목 컬럼 중 국어 값을 가는 전체 행 개수
-ORDER BY
- ORDER BY: 정렬
- ASC: 오름차순
DESC: 내림차순 - 정렬 기준을 두개로 만들때, 컬럼명이 어려울때 코드
-정렬 기준을 두개로 만들때 SELECT PLAYER_NAME, HEIGHT, WEIGHT FROM PLAYER ORDER BY 2,3; -> 키순으로 정렬 한 후 몸무게 순으로 정렬함 -컬럼명이 어려울때-> 컬럼의 순서(인덱스)로 지정 가능 (SELECT에서는 X) SELECT *FROM PLAYER ORDER BY 12 DESC;
- ASC: 오름차순
-CASE
-
CASE
-
CASE WHEN 조건식 THEN '참 값' ELSE '거짓 값' END
- 예시 코드
--SAL이 3000이상이면 HIGH, 1000이상은 MID 다아니면 LOW SELECT ENAME, SAL CASE WHEN SAL >=3000 THEN ' HIGH'; WHEN SAL >=1000 THEN 'MID' ELSE 'LOW' END FROM EMP;
- 예시 코드
-
ELSE는 생략 가능, WHEN 여러번 가능.. (IF문 처럼)
-
중첩케이스문
-
코드
SELECT ENAME, SAL CASE WHEN SAL >=3000 THEN 'HIGH'; ELSE( CASE WHEN ELSE END ) END '연봉' ->연봉: AS FROM EMP;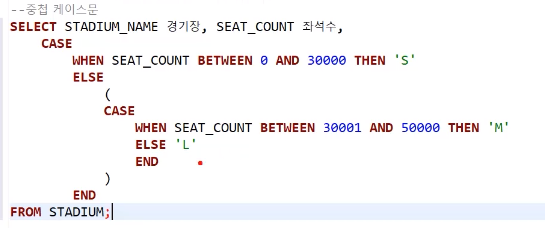
S - 1번째 기준 , M 두번째기준, 그 이외: L
-
-

:) GITHUB: https://github.com/YJ2123412