도커 컴포즈
단일 서버에서 여러개의 컨테이너를 하나의 서비스로 정의해 컨테이너의 묶음으로 관리할 수 있는 작업환경 제공
시스템 구축에 필요한 설정을yaml포맷으로 기재한 정의 파일을 이용해 전체 시스템을 일괄 실행 또는 종료 및 삭제 가능
정의파일 : 컨테이너나 볼륨을 '어떤 설정으로 만들지'에 대한 항목 기재
명령어
-
up:docker run과 유사,정의 파일에 기재된 내용대로 이미지를 내려받고 컨테이너를 생성 및 실행 - 환경을 한꺼번에 생성 -
down: 컨테이너와 네트워크를 정지 및 삭제 - 볼륨과 이미지는 삭제 X -
stop: 컨테이너와 네트워크를 삭제 없이 종료
Dockerfile과의 차이
만드는 대상이 다름
- Docker Compose :
docker run명령어를 여러개 모아놓은것과 같음 - 컨테이너와 주변 환경을 생성, 네트워크와 볼륨까지 만듦 - Dockerfile : 이미지를 만들기 위한 것 - 네트워크나 볼륨은 만들 수 없음
구조
version: "3"
services:
example:
depends_on:
- mysql000ex11
image: wordpress
networks:
- example000net1
ports:
- 8085:80
restart: always
environment:
example_DB_HOST=mysql000ex11
example_DB_NAME=example000db
example_DB_USER=example000kun
example_DB_PASSWORD=exampleversion: 컴포즈 파일 버전services: 컨테이너 정보 - 있는만큼depends_on: 다른 서비스와의 의존관계networks: 네트워크 관련 정보ports: 볼륨 관련 정보restart: 컨테이너 종료 시 재시작 여부 설정environment: 환경변수 설정
이미지 레이어
이미지는 한번 만들어지면 정보는 절대 변하지 않으며, 이미지를 통해 컨테이너를 만들 수 있음
이렇게 만들어진 이미지는 컨테이너 생성을 위한 모든 정보를 갖고 있기 때문에 수백 메가바이트에서 수 기가바이트가 넘음 → 이때 이미지에서 작은 변경사항이 생겨서 이미지를 변경해야 할때 한줄로 인하여 이미지를 다시 다운로드 받으면 비효율적임 → 이러한 문제를 해결하기 위해레이어개념 도입
레이어
기존 이미지에 추가적인 파일이 필요할 때 다시 다운로드 받는 방법이 안니 해당 파일을 추가하기 위한 개념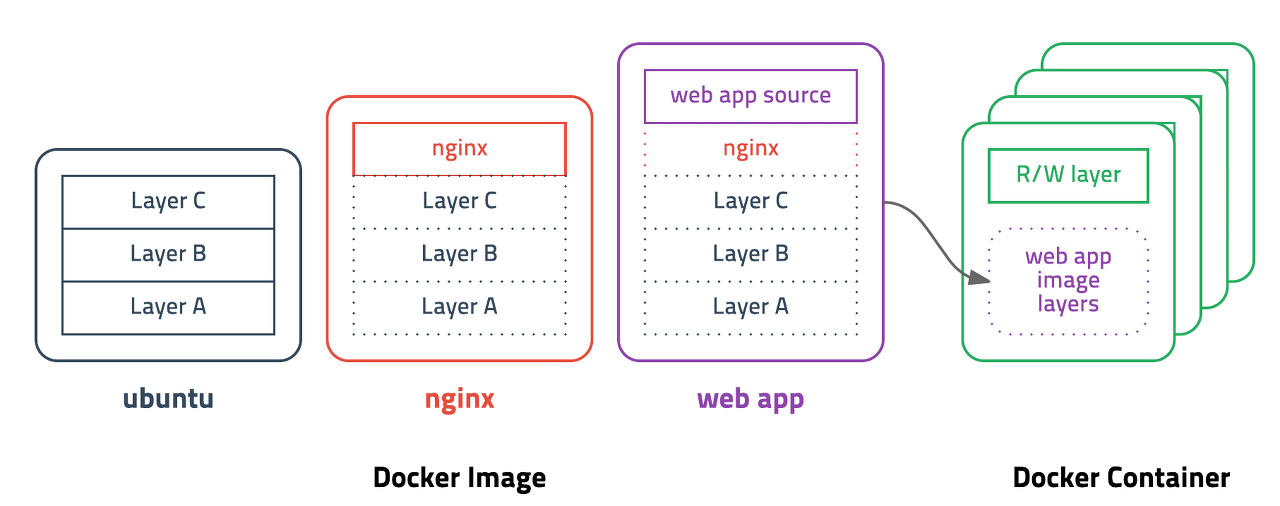
Docker 이미지는 여러 레이어로 구성되며, 각 레이어는 이전 레이어의 변경 사항을 가지고 있음
이미지에 작업이 추가되면 새로운 레이어가 생성되는 개념은 Git commit 로그와 비슷하다고 보면됨
특징
- 레이어 격리 : 각 레이어는 독립적 파일 시스템, 애플리케이션과 종속성에 대한 변경 사항만 포함
- 레이어 재사용 : 동일한 레이어를 여러 이미지에 공유 → 이미지 빌드 시간과 저장소 사용량 줄임
- 레이어 버전 관리 : 레이어를 생성할 때마다 새로운 버전이 만들어짐, 이미지 업데이트시에도 이전 버전의 레이어 유지 → 변경 이력 관리 가능
Dockerfile기반 레이어 생성 :Dockerfile에서 작성된 명령어들이 실행될때마다 새로운 레이어가 만들어짐 - 변경 사항 추적 가능
작동 원리
- 이미지 생성시,
Dockerfile을 사용하여 이미지 레시피 정의 Dockerfile에 기술된 명령어들이 순서대로 실행- 명령어가 실행될 때마다 새로운 레이어 생성, 변경 사항 레이어 저장
- 이미지 실행 시, 해당 이미지의 모든 레이어 연결 - 전체 파일 시스템 구성 - 실행 컨테이너는 모든 레이어의 데이터에 접근 가능
- 컨테이너 내에서 변경해 저장한 것은 컨테이너의 최상단 레이어에 저장되며 이미지의 레이어에는 영향을 주지 않음
컨테이너 오케스트레이션
컨테이너의 배포, 관리, 확장, 네트워킹 자동화
- 프로비저닝 및 배포
- 구성 및 일정 조정
- 리소스 할당
- 컨테이너 가용성
- 컨테이너 스케일링 또는 제거
- 로드 밸런싱 및 트래픽 라우팅
- 컨테이너 모니터링
- 실행된 컨테이너 기반 애플리케이션 설정
- 컨테이너 간 보안유지
도커 스웜
도커에서 만든 컨테이너 오케스트레이션 툴
여러 대의 도커 호스트에 컨테이너를 배포하고 관리하는 기능을 제공하여 애플리케이션의 가용성과 확장성 향상
여러 대의 서버를 하나의 클러스터로 묶어 리소스 병렬 확장
컨테이너 오케스트레이션 : 여러 호스트의 컨테이너 배포 및 관리, 제어를 자동화하는 것
사용 이유
운영 중 서비스의 덩치가 커져 서버 자원이 부족할 경우 → 더 좋은 사양의 서버를 사면 되지만 서버의 구매, 교체 등은 부담이 됨
도커 스웜을 통해 여러 서버를 하나의 클러스터(군집)로 묶어 자원을 병렬로 확장 하게 도와주는 역할
다른 호스트의 여러 컨테이너를 하나로 묶어 하나의 호스트처럼 사용
장점
- 암호화된 분산 클러스터 스토어
- 암호화된 네트워크
Mutual TLS- 보안을 위한 클러스터 조인 토큰
- 인증서 관리 및 재발급을 쉽게 해주는
PKI - 노드를 중단 없이 추가/제거
구성
-
분산 코디네이터: 여러 개의 도커 서버를 하나의 클러스터로 구성하기 위해 각종 정보를 저장 및 동기화 -
에이전트: 각 서버 제어 -
노드: 텍스트 클러스터에 속한 도커 서버 단위 → 보통 한 서버에 하나의 도커 데몬 실행(노드 = 서버) -
매니저 노드: 클러스터 내의 워커 노드 관리, 무조건 1개 이상 존재, 워커 노드 역할도 함
- 클러스터의 상태 유지 : 뗏목 알고리즘 → 여러 서버 중 일부에 장애가 생겨도 나머지 서버가 정상적인 서비스를 할 수 있도록 해줌- 스케줄링 서비스 :
워커 노드에게 컨테이너 배포 → 특정 노드만 배포 가능 - 스웜 모드 제공
- 7개 이상의 노드는 성능 저하를 일으킬 수 있다고 함
- 스케줄링 서비스 :
-
워커 노드: 컨테이너가 생성되고 관리되는 실제 도커 서버
- 반드시 하나 이상의매니저 노드를 가져야 함 -
스택: 하나 이상의서비스로 구성된 다중 컨테이너 애플리케이션 묶음 -yaml파일로 스택 배포 진행 -
서비스: 노드에서 수행하고자 하는 작업들을 정의해놓은 것, 클러스터 안에서 구동시킬 컨테이너 묶음을 정의한 객체 -도커 스웜에서 기본적인 배포 단위로 취급 - 하나의 서비스는 하나의 이미지를 기반으로 구동, 각각 전체 애플리케이션의 구동에 필요한 개별적 마이크로서비스로 기능 -
태스크: 서비스를 구동시킬 때, 서비스의 요구사항에 맞춰 마이크로서비스가 동작할 도커 컨테이너를 구성하여 노드에 분배 - 하나의 서비스는 여러개의 태스크를 가질 수 있고, 각각의 태스크에는 컨테이너 하나씩 포함 -
스케줄링: 서비스 명세에 따라태스크를 노드에 분배 →도커 스웜에서는 균등 분배 방식만 지원
명령어
docker swarm init: 새로운 스웜 만들기docker swarm join-token: 워커노드와 매니저 노드를 스웜에 포함시키기 위한 명령과 토큰 발급docker node ls: 스웜 내의 모든 노드 나열docker service create: 새로운 서비스 만들기docker service ls: 실행 중인 서비스 나열docker service ps <service>: 특정 서비스에 대한 자세한 정보docker service inspect: 서비스에 대한 매우 상세한 정보docker service scale: 서비스의 복제본 수를 확장하거나 수축docker service update: 실행 중인 서비스의 속성 업데이트docker service logs: 서비스 로그 확인docker service rm: 스웜에서 서비스 삭제 --> 확인안하니까 조심
뗏목 합의 알고리즘
여러 서버 중 일부 서버에 장애가 생겨도 제 기능을 유지하도록 하는
합의 알고리즘
합의 알고리즘
- 다수의 참여자들이 동일된 의사 결정을 하기 위해 사용되는 알고리즘
- 한 서버에서 명령을 실행하기 위해 다른 서버에게 합의를 요청, 다른 서버들은 자신의 서버에 문제가 없는지 판단하고, 해당 명령을 실행하여 모두 동일한 상태 유지
장애 허용 분산 시스템
- 시스템 중 일부에 오류가 발생해도 정상적으로 작동할 수 있도록 하는 시스템
- 뗏목의 일부 나무가 손상되어도 제 기능 유지
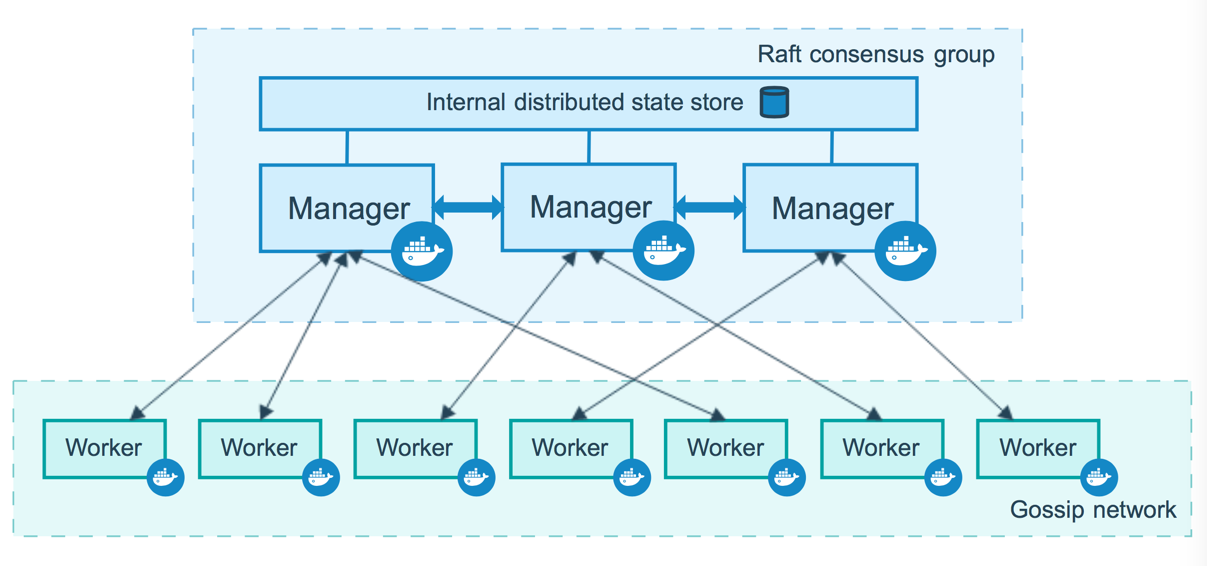
매니저 노드는 클러스터의 모든 정보 포함 → 매니저 노드가 죽게되면 클러스터도 다운
→ 뗏목 합의 알고리즘을 이용한 멀티 매니저 노드 기능 지원
- 여러 개의 매니저 노드 생성
- 한 매니저 노드가 죽어도 다른 매니저 노드를 생성하여 서비스 안정적 상태로 복원
- 이를 위해서 모든 매니저 노드가 동일한 상태를 유지하고 있어야 함
동작 원리
- 로그
- 시스템의 처리 내용과 이용 상황을 시간 흐름에 따라 기록- 로그에 있는 명령을 합의하는 데에 사용
- 상태 시스템
- 각 상태를 조건에 따라 연결- 어떤 조건이 충족되거나 이벤트가 발생하면 현재 상태에서 다음 상태로 이동
- 로그로부터 입력
- 오류를 허용 → 특정 서버에 장애가 생겨도, 클라이언트는 정상 작동하는 다른 상태 시스템과 상호작용
한 서버가 명령을 실행할 때 명령을 실행해도 되는지 다른 서버에게 합의를 구함
합의를 한 서버는 같은 명령을 실행하고 동일한 상태 유지 - 합의를 한 서버는 명령 실행을 위해 다시 합의를 구할 필요가 없음
오류가 발생한 서버가 절반 이상이면 해당 명령의 진행 중단
오류가 발생한 서버가 명령으로 인한 잘못된 결과는 반환 X
도커 스웜에서는 매니저 노드의 절반 이상에 장애가 발생한 경우, 장애가 생긴 매니저 노드가 복구될 때까지 클러스터의 운영 중단
매니저 노드 사이에 네트워크 파티셔닝이 발생할 경우, 매니저 노드가 짝수 개면 운영이 중단될 수 있지만, 홀수 개로 구성했을 경우 과반수 이상이 유지되는 매니저에서 운영 가능 - 매니저 노드는 가능한 한 홀수 개로 구성 권장네트워크 파티셔닝
네트워크 오류가 발생하면 클러스터의 호스트 중 일부가 관리 네트워크를 통해 다른 호스트와 통신 불가
→ 클러스터에서 여러개의 파티션 발생 가능
스웜 클래식과 도커 스웜모드
스웜 클래식(도커 1.6 이후 버전)
- 여러 서버를 단일 접근점 제공
- 일반 도커 명령어 및 API로 서버 제어/관리
- 분산 코디네이커/에이전트 별도 실행
도커 스웜모드(도커 1.12 이후 버전)
클러스터링을 위한 모든 도구가 도커 엔진 자체 내장
- 마이크로 서비스 아키텍처 컨테이너를 다루기 위한 클러스터링
- 유동적 컨테이너 수 조절 가능
- 같은 컨테이너를 동시에 여러 개 생성해 필요에 따라 유동적으로 컨테이너 수 조절, 로드밸런싱 지원
- 확장성과 안전성 뛰어남
- 서비스 장애에 대비한 고가용성
차이
스웜클래식은 여러대의 도커 서버를 하나의 지점에서 사용하도록 단일 접근점 제공
스웜모드는 마이크로서비스 아키텍처의 컨테이너를 다루기 위한 클러스터링 기능에 초점
공식문서에서도 도커 스웜모드를 권장함
참고 블로그
https://gngsn.tistory.com/269
https://velog.io/@younghwan/docker-swarm
https://yoo11052.tistory.com/182
