람다식이란?
- 메서드를 하나의 식으로 표현한 것
- 메서드를 람다식으로 표현하면 메서드의 이름과 반환값이 없어지므로 익명함수(anonymous function)라고도 한다.
int[] arr = new int[5];
int method() {
return (int)(Math.random() * 5) + 1;
}🔺 method()를 람다식으로 표현하면 하기와 같다.
int[] arr = new int[5];
Arrays.setAll(arr, (i) -> (int)(Math.random() * 5) + 1);🔺 보다 간결해지고 이해하기 쉬워졌다.
람다식의 등장배경
-
람다식은 수학자 알론조(Alonzo Church)가 발표한 람다 계산법에서 사용된 식으로, 이를 제자 존 매카시(John Macarthy)가 프로그래밍 언어에 도입하여 탄생했고 Java 8 버전부터 람다식을 지원하게 되었다.
-
람다식은 익명함수(anonymous function)을 생성하기 위한 식으로 객체 지향 언어보다는 함수 지향 언어에 가깝다.
-
이전에도 함수형 프로그래밍 언어들이 있었지만, 학계에서만 호응받고 말았는데 최근에 병렬처리와 이벤트 지향 프로그래밍에 적합하고 딥러닝이나 빅데이터등 분야에서 일종의 문법적 트렌드처럼 관심을 받기 시작하고 있다.
람다식의 장단점
장점
- 1️⃣ 코드의 간결성 - 람다를 사용하면 불필요한 반복문의 삭제가 가능하며 복잡한 식을 단순하게 표현할 수 있다.
- 2️⃣ 지연연산 수행 - 람다는 지연연산을 수행 함으로써 불필요한 연산을 최소화 할 수 있다.
- 3️⃣ 병렬처리 가능 - 멀티쓰레디를 활용하여 병렬처리를 사용 할 수 있다.
단점
- 1️⃣ 람다식의 호출이 까다롭다.
- 2️⃣ stream() 에서 람다를 사용할 시에 단순 for문 혹은 while문 보다 성능이 떨어진다.
- 3️⃣ 불필요하게 너무 사용하게 되면 오히려 가독성을 떨어 뜨릴 수 있다.
람다식 작성
- 익명함수답게 메서드에서 이름, 반환타입을 제거하고 매개변수 선언부와 바디 {} 사이에
->를 추가한다.
반환타입 메서드이름(매개변수 선언) {
문장들
}
⇩
반환타입 메서드이름(매개변수 선언) -> {
문장들
}
예시 메서드 max()를 람다식으로 변환하기
int max(int a, int b) {
return a > b ? a : b;
} (int a, int b) -> {
return a > b ? a : b;
}🔺 반환값이 있는 메서드의 경우 return문도 람다식으로 대체할 수 있다.
(int a, int b) -> { return a > b ? a : b; } // return문
(int a, int b) -> a > b ? a : b // 식(expression)🔺 이때는 문장(return문)이 아닌 식이므로 끝에 세미콜론(;)을 붙이지 않는다.
- 람다식에서 선언된 매개변수의 타입이 만약 추론이 가능하다면 생략할 수 있다.
(람다식에 반환타입이 없는 이유도 항상 추론이 가능하기 때문이다.)
(int a, int b) -> a > b ? a : b
(a, b) -> a > b ? a : b // 매개변수의 타입 생략🔺 2개 이상의 매개변수 중 어느 하나의 타입만 생략하는것은 불가하다.
- 만일 선언된 매개변수가 하나뿐이라면, 괄호()도 생략이 가능하다.
(단, 매개변수의 타입이 있다면 생략할 수 없다.)
(int a) -> a * a
a -> a * a // Ok.
int a -> a * a // error.- 바디 {}안의 문장이 하나일때도 괄호를 생략할 수 있다.
(문장의 끝에 세미콜론(;)을 붙이지 말아야 한다.)
(String name, int i) -> {
System.out.println(name + " = " + i);
}
(String name, int i) ->
System.out.println(name + " = " + i)- ❌ 하지만 바디 {}안의 문장이 return문이라면 생략이 불가하다.
(int a, int b) -> { return a > b ? a : b; } // return문 Ok.
(int a, int b) -> return a > b ? a : b // return문 error.
(int a, int b) -> a > b ? a : b // 식(expression)함수형 인터페이스(Functional Interface)
- 람다식은 다음과 같이 익명 클래스의 객체와 동일하다고 볼 수 있다.
(int a, int b) -> a > b ? a : b
// 위(람다식)와 아래(익명 클래스의 객체 내부 메소드)와 같다
new Object(){
int max(int a, int b){
return a > b ? a : b;
}
}- ❓ 그럼, 람다식으로 정의된 익명 객체의 메서드는 어떻게 호출하는걸까?
- 호출하기 위해선 참조변수가 있어야 하므로, 익명 객체의 주소를 f라는 참조변수에 저장해보자
타입 f = (int a, int b) -> a > b ? a : b;- 그럼, 참조변수 f의 타입은 어떤것이어야 할까?
- 참조형이므로, 클래스 or 인터페이스가 가능하다.
- 더하여, 람다식과 동등한 메서드가 정의되어 있는 타입이어야 한다.
- 그래야만 참조변수로 익명객체(람다식)의 메서드를 호출할 수 있기 때문이다.
예시 max() 라는 메서드가 정의된 MyFunction 인터페이스가 정의되어 있다.
interface MyFunction{
public abstract int max(int a, int b);
}🔺 위 인터페이스를 구현한 익명클래스의 객체는 다음과 같이 생성할 수 있다.
MyFunction f = new MyFunction(){
public int max(int a, int b){
return a > b ? a: b;
}
}
int big = f.max(5, 3);🔺 익명 객체를 람다식으로 대체하면 다음과 같다.
MyFunction f = (int a, int b) -> a > b ? a : b; // 익명 객체를 람다식으로 대체
int big = f.max(5,3); // 익명 객체의 메서드를 호출 타입 f = (int a, int b) -> a > b ? a : b;- MyFunction 인터페이스를 구현한 익명객체를 람다식으로 대체가능한 이유는 람다식도 실제로는 익명 객체이고, MyFunction 인터페이스를 구현한 익명 객체의 메서드 `max()와 람다식의 매개변수의 타입과 갯수, 그리고 반환값이 일치하기 때문
- 이와 같이 하나의 메서드가 선언된 인터페이스를 정의하여 람다식을 다루게 되면 자바 규칙을 어기지 않고 자연스럽게 다를 수 있다.
- 그러므로, 람다식을 인터페이스를 통해 다루기로 결정하게 되었고, 람다식을 다루기 위한 인터페이스를 함수형 인터페이스라고 부른다.
@FunctionalInterface
interface MyFunction {
public abstract int max(int a, int b);
}- ❗️ 단, 함수형 인터페이스는 오직 하나의 추상 메서드만 정의되어 있어야 한다는 조건이 있으므로
@FunctionalInterface애너테이션을 사용하여 에러를 방지하자.
함수형 인터페이스 타입의 매개변수와 반환타입
- 아래와 같이 정의된 함수형 인터페이스 MyFunction을 통해 알아보자.
@FunctionalInterface
interface MyFunction {
void myMethod(); // 추상 메서드
}- 메서드의 매개변수가 함수형 인터페이스인 MyFunction타입이면, 이 메서드를 호출할 때 람다식을 참조하는 참조변수(f)를 매개변수로 지정해야 한다.
void aMethod(MyFunction f) {
f.myMethod(); // MyFunction에 정의된 메서드 호출
}
...
MyFunction f = () -> System.out.println("myMethod()");
aMethod(f);- 또는 참조변수 없이 다음과 같이 직접 람다식을 매개변수로 지정하는것도 가능하다.
aMethod(() -> System.out.println("myMethod()"));- 메서드의 반환타입이 함수형 인터페이스 타입이라면, 해당 함수형 인터페이스의 추상메서드와 동등한 람다식을 가리키는 참조변수를 반환하거나 람다식을 직접 반환할 수 있다.
MyFunction myMethod() {
MyFunction f = () -> {};
return f;
// 위 두줄을 한줄로 줄이면, return () -> {};
}람다식의 타입과 형변환
- 함수형 인터페이스로 람다식을 참조할 수 있는것일 뿐, 람다식의 타입과 함수형 인터페이스의 타입이 일치하는것은 아니다.
- 람다식은 익명 객체이고, 익명 객체는 타입을 컴파일러가 임의로 이름을 정하기 때문에 알 수가 없다.
- 그러므로, 대입 연산자 사용 시 양 변의 타입을 일치시키기 위해 형변환이 필요하다.
(하지만, 생략도 가능)
@FunctionalInterface
interface MyFunction {
void method();
}
// 형변환
MyFunction mf = (MyFunction)(() -> {});
// 생략 가능함
MyFunction mf = (() -> {});
// 단, Object로의 형변환은 불가,
// 오직 함수형 인터페이스로만 형변환 가능
Object obj = (Object)(() -> {});
// Object로 굳이 형변환을 하고 싶다면?
// 함수형 인터페이스로 변환한 뒤에 가능하다.
Object obj = (Object)(MyFunction)(() -> {});
String str = ((Object)(MyFunction)(() -> {})).toString();변수 캡쳐(Variable Capture)
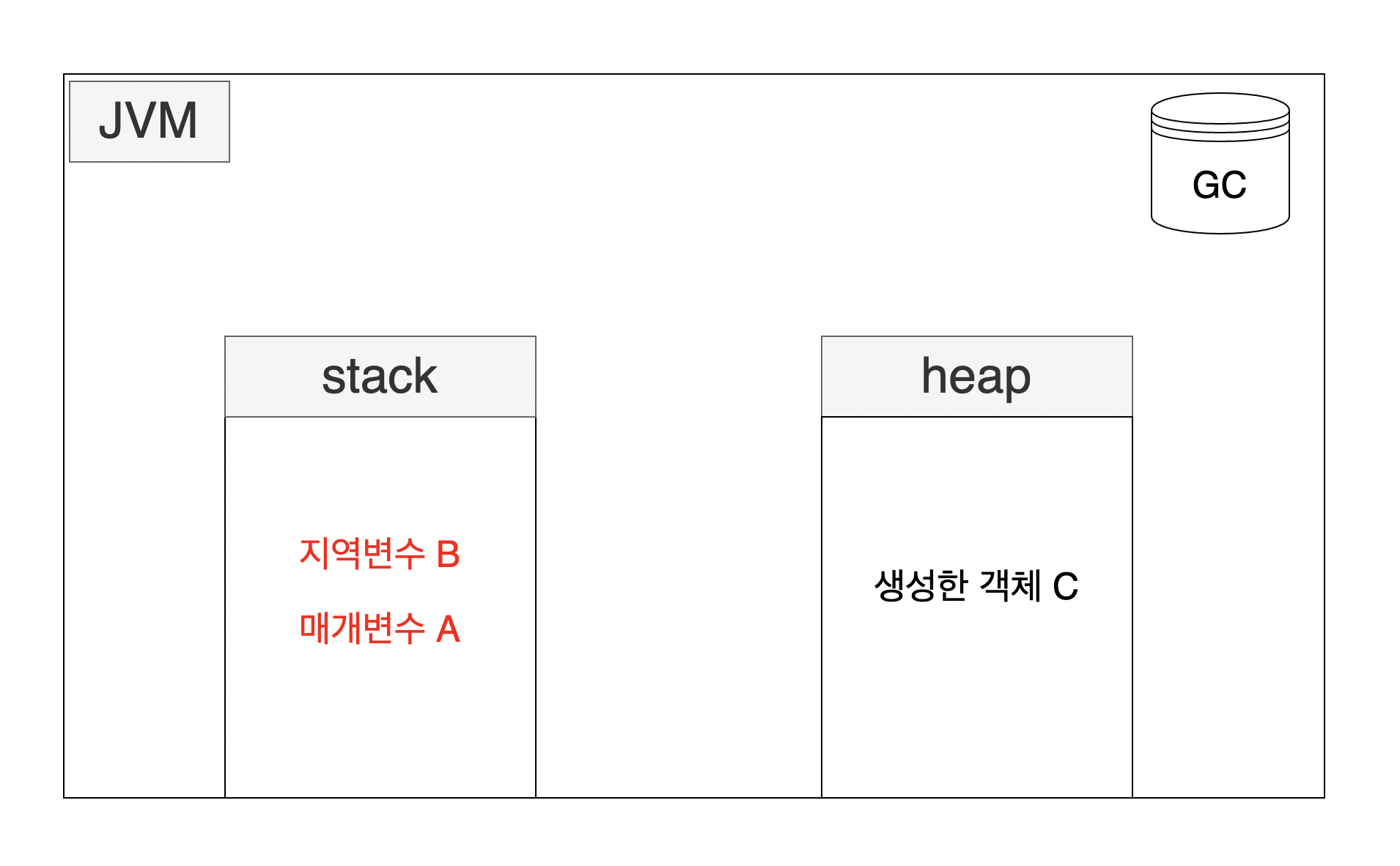
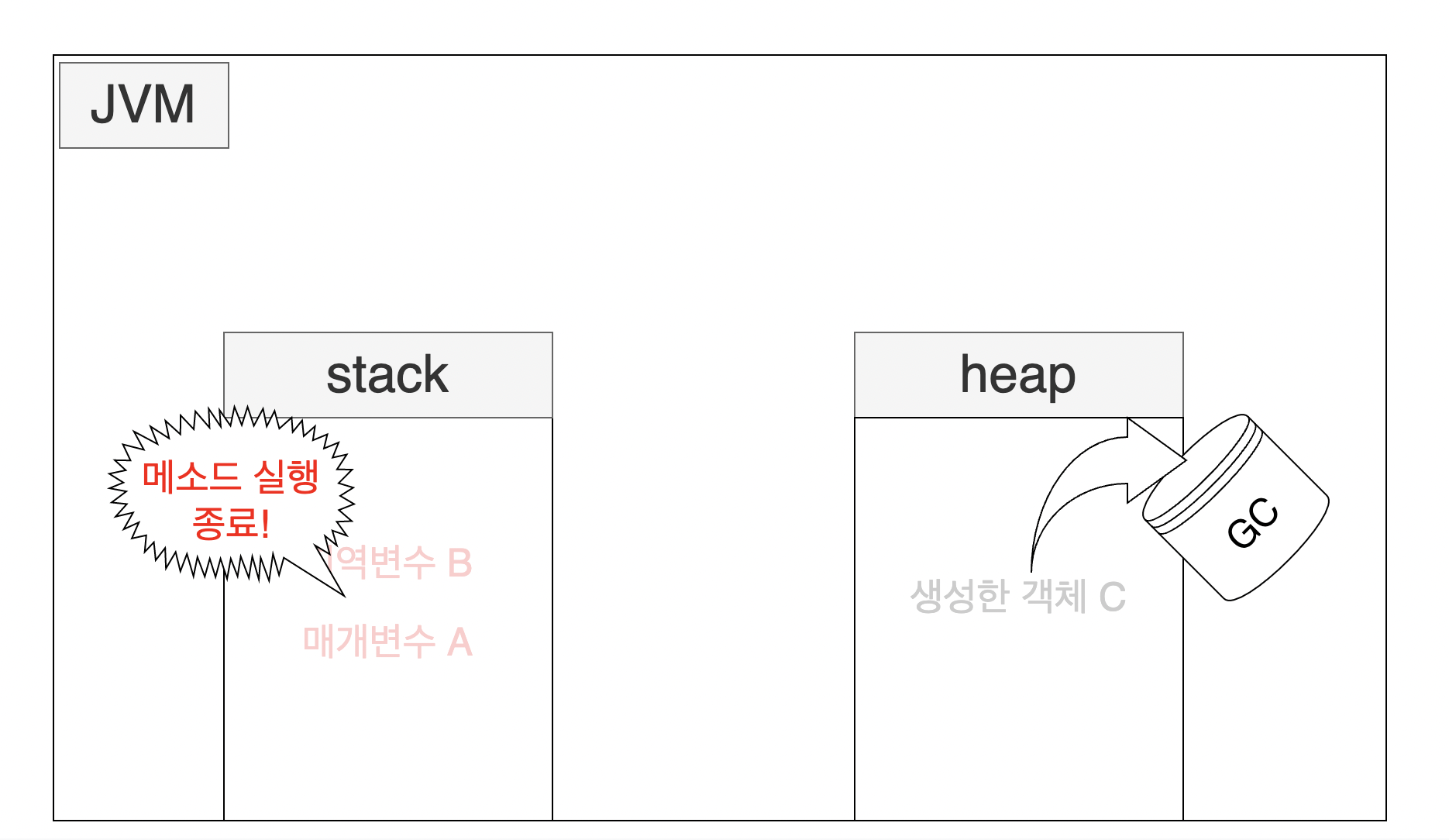
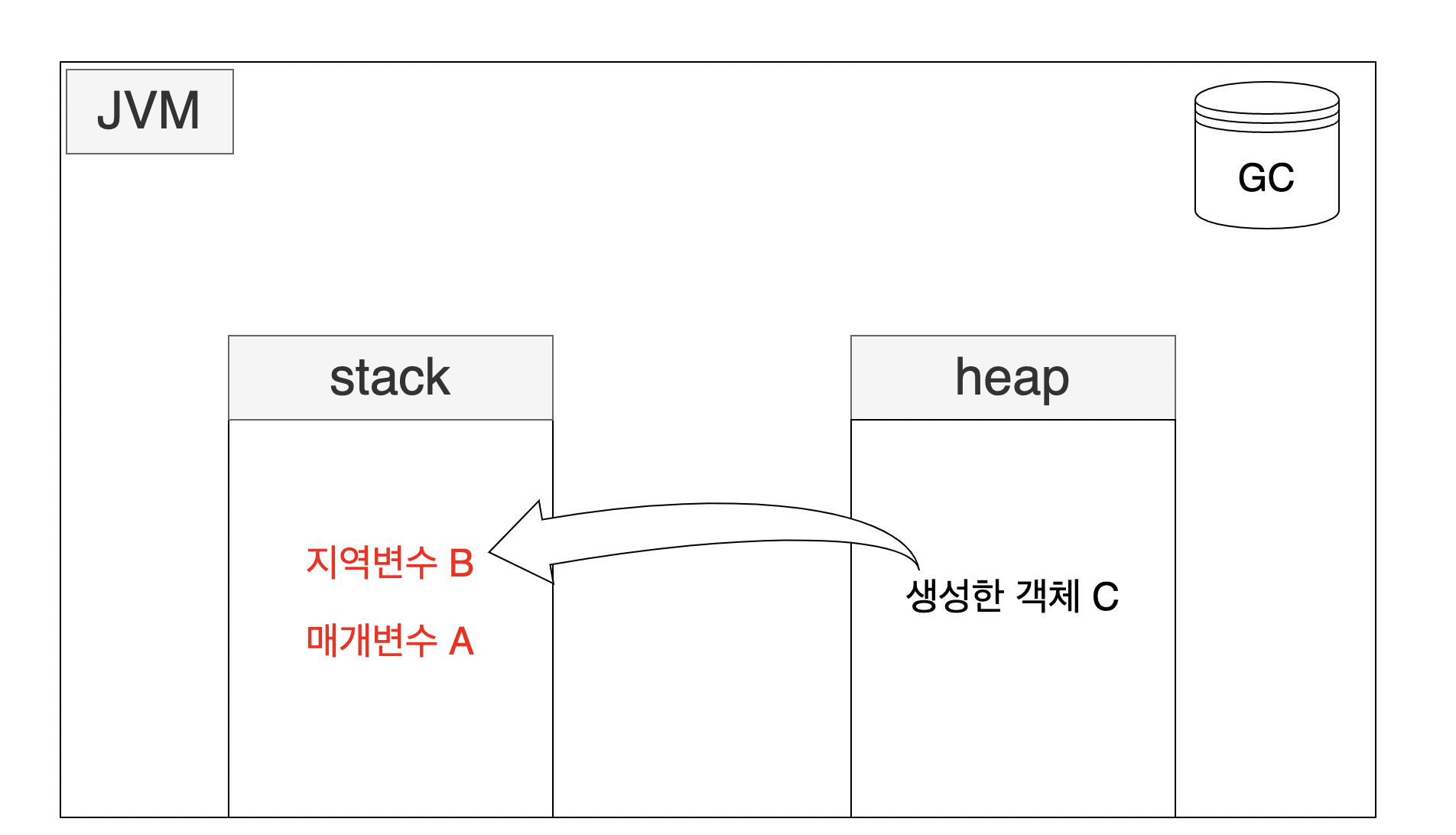
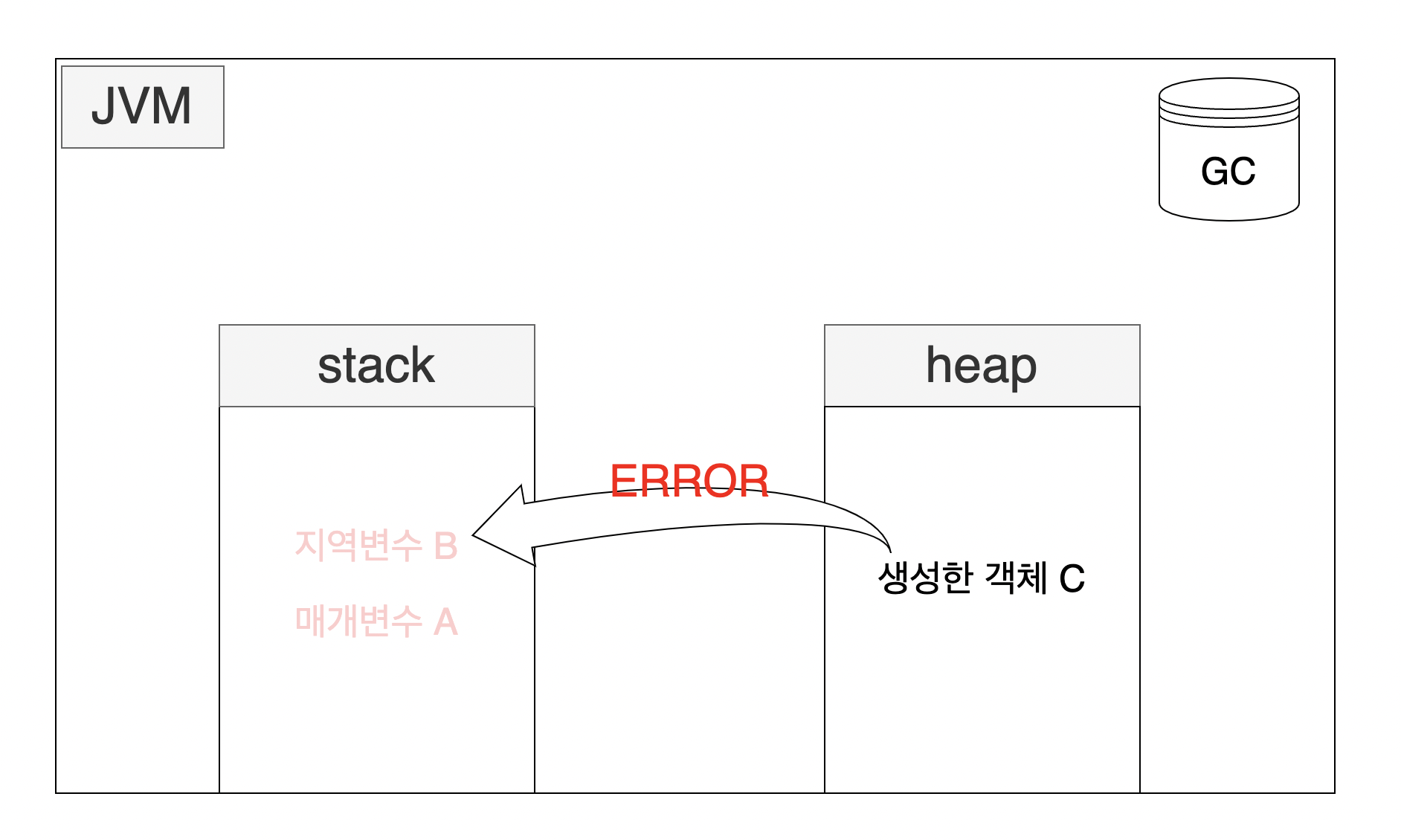
- 컴파일 시점에 멤버 메소드의 매개변수나 지역변수를 멤버 메서드 내부에서 생성한 객체가 사용할 경우 객체 내부로 값을 복사해 사용하는것.
Variable Capture 등장배경
public class 클래스 {
멤버 필드;
멤버 메소드(매개변수 A){
지역변수 B;
생성한 객체 C = new C();
}
}
로컬 변수 캡쳐
import java.util.function.*;
public class Foo {
public static void main(String[] args) {
Foo foo = new Foo();
foo.run();
}
private void run() {
int baseNumber = 10; // 사실상 Final인 변수(effective final)
IntConsumer printInt = (i) -> {
System.out.println(i + baseNumber);
};
printInt.accept(10);
}
}
- 람다 바디에서는 파라미터외에 바디{} 외부에 있는 변수를 참조할 수 있는데,
이런 행위를 람다 캡쳐링(Lamda Capturing) 혹은 로컬 변수 캡쳐라고 부른다. - 캡쳐가 가능하기 위해서는, 위 예시의
baseNumber가 Final로 명시되어 있거나
effective final(사실상 변하지 않아 final과 같은 성격을 지닌 변수)인 경우에만 가능하다. - ❗️ Java 8 이전에는 항상 반드시 final이 붙어있어야 했다.
- ❗️ effective final은 익명 클래스 구현체 또는 람다에서 참조할 수 있는 공통점이 있지만,
람다는 익명 클래스 구현체와 달리쉐도잉하지 않는다.
쉐도잉
- 함수밖의 함수가 가려지는것을 말한다.
- 로컬클래스, 익명클래스, 람다클래스의 스코프에 따라 쉐도잉 범위가 달라진다.
import java.util.function.*;
public class Foo {
public static void main(String[] args) {
Foo foo = new Foo();
foo.run();
}
private void run() {
int baseNumber = 10; // 사실상 Final인 변수(effective final)
//로컬 클래스
Class LocalClass {
void printBaseNumber() {
System.out.println(baseNumber);
}
}
//익명 클래스
Consumer<Integer> integerConsumer = new Consumer() {
@Override
public void accpet(Integer integer) {
System.out.println(baseNumber);
}
};
//람다
IntConsumer printInt = (i) -> {
System.out.println(i + baseNumber);
};
printInt.accept(10);
}
}
- 위 예제를 통해 클래스별 쉐도잉을 그림으로 나타내보면 하기와 같다.
로컬클래스, 익명클래스
import java.util.function.*;
public class Foo {
public static void main(String[] args) {
Foo foo = new Foo();
foo.run();
}
private void run() {
int baseNumber = 10; // 사실상 Final인 변수(effective final)
//로컬클래스
Class LocalClass { // 로컬클래스의 Scope 범위 시작
void printBaseNumber() {
int baseNumber = 11; //참조하고있는 외부 변수와 동일한 변수명을 스코프 내에서 재정의
System.out.println(baseNumber); // 10이 아닌 11이 출력된다.
}
} // 로컬클래스의 Scope 범위 끝
//익명클래스
Consumer<Integer> integerConsumer = new Consumer() { // 익명클래스의 Scope 범위 시작
@Override
public void accpet(Integer baseNumber) { // 파라미터 이름을 참조하고 있는 외부 변수와 동일한 이름으로 변경
System.out.println(baseNumber);
}
}; // 익명클래스의 Scope 범위 끝
printInt.accept(10);
}
}


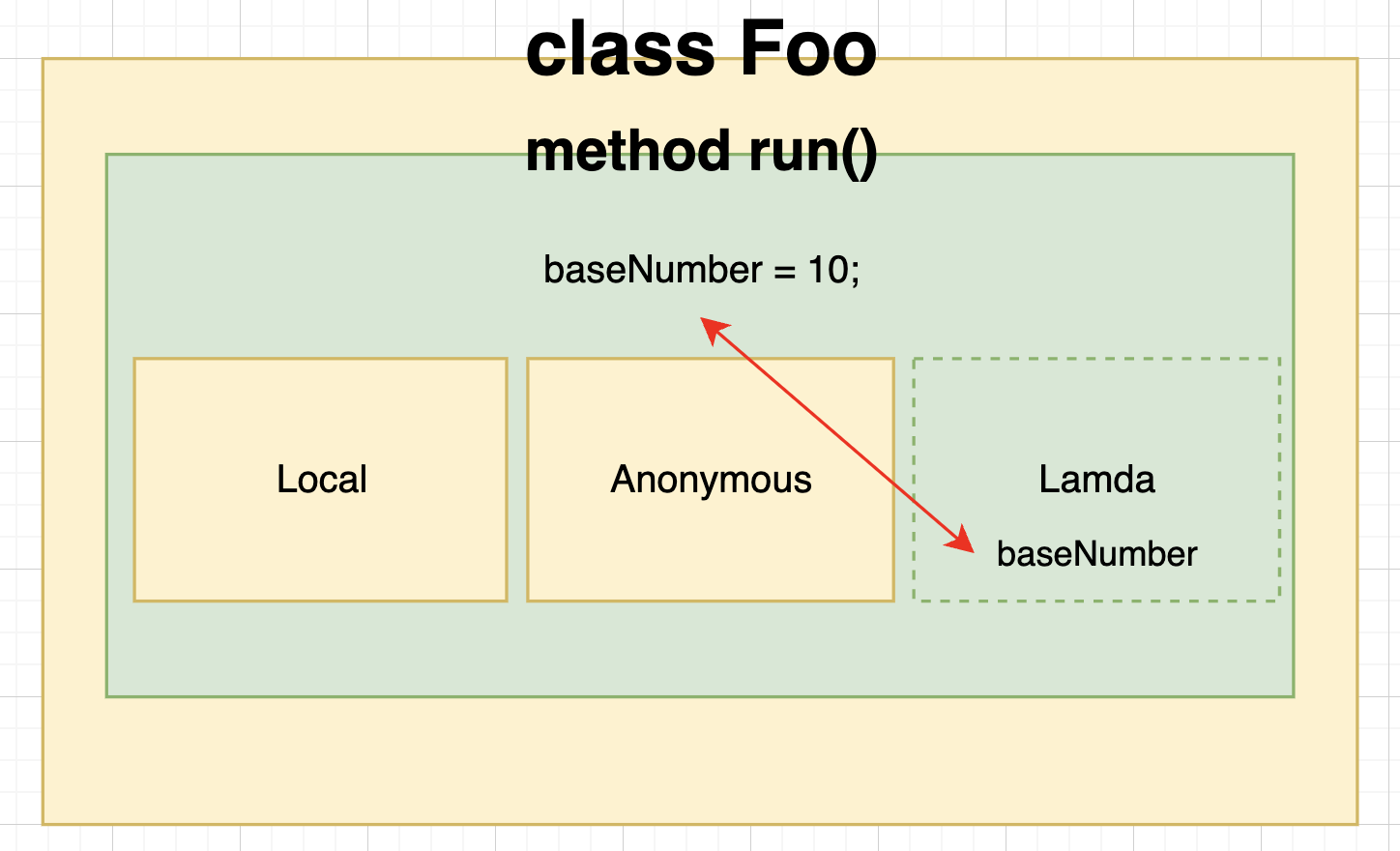
- 그림과 같이 로컬클래스와 익명클래스는 자신의 스코프 안에서 외부 참조하고 있는
변수명과 동일한 변수명으로 재정의 하게 되면,자신의 스코프 내부의 재정의한
변수가 외부 참조하고 있던 변수명을 가려버린다.
람다
import java.util.function.*;
public class Foo {
public static void main(String[] args) {
Foo foo = new Foo();
foo.run();
}
private void run() { // 람다의 Scope 범위 시작
int baseNumber = 10; // 사실상 Final인 변수(effective final)
//람다
IntConsumer printInt = (baseNumber) -> { // 같은 변수명을 사용할 경우 컴파일 에러가 난다.
System.out.println(baseNumber);
};
printInt.accept(10);
} // 람다의 Scope 범위 끝
}
- 사실상 람다의 스코프 범위는 외부 메소드의 범위와 같으므로 동일한 변수명을 2개 못쓰는것이다.
왜?? 다르지
익명클래스는 익명 "객체"로 볼 수 있지만, 람다는 객체가 아니여서 그렇다.
즉, 익명클래스 내에서 this는 자기 자신을 가리키지만 람다에서의 this는 자신을 선언한 클래스를 말한다.
메소드 참조(Method Reference)
- 이미 람다식을 통해 코드가 간결해졌지만, 람다식을 더욱 간결하게 표현할 수 있는 메소드 참조라는 방법이 있다.
- 메소드를 참조하는 방법들
- 스태틱 메소드 참조 → 클래스 이름::메소드
- 특정 객체의 인스턴스 메소드 참조 → 클래스 이름::메소드
- 임의 객체의 인스턴스 메소드 참조 → 인스턴스 변수::메소드
- 생성자 참조 → 타입::new
1️⃣ 스태틱 메소드 참조 → 클래스 이름::메소드
- 문자열을 정수로 바꿔주는 람다식을 메서드로 표현하면 다음과 같다.
Integer wrapper(String s) {
return Integer.parseInt(s);
}- 여기서 wrapper 메서드는 값을 받아서
Integer.parseInt()에게 넘겨주는 역할만 한다. 이를 람다식과 메서드 참조로 바꿔보면 다음과 같다.
람다식
Function<String, Integer> f = (String s) -> Integer.parseInt(s);메서드 참조
Function<String, Integer> f = Integer::parseInt;Integer의parseInt()는static 메서드이다.- 메서드 참조과정에서 람다식의 일부가 생략되어 간략해졌지만, 컴파일러는 생략된 부분을 알아낼 수 있다.
- 우변의 parseInt 메서드의 선언부, 또는 좌변의 Function 인터페이스에 지정된 제네릭 타입으로부터 알아내는 것이다.
2️⃣ 특정 객체의 인스턴스 메소드 참조 → 클래스 이름::메소드
- 다음의 람다식을 메서드 참조로 변경해보며 다른 경우를 살펴보자
BiFunction<String, String, Boolean> f = (s1, s2) -> s1.equals(s2);- 참조변수 f의 타입을 보면 두 개의 String 타입의 매개변수를 람다식이 받는다는것을 알 수 있으므로, 람다식의 매개변수들은 없어도 된다.
- 위 람다식에서 매개변수들을 제거한 메서드 참조는 다음과 같다.
BiFunction<String, String, Boolean> f = String::equals;- s1,s2를 생략하면 equals만 남게 되는데, 두 개의 String을 받아 Boolean으로 반환하는 equals라는 이름의 메서드는 다른 클래스에서도 존재할 가능성이 있으므로 equals앞에 클래스 이름(String)이 반드시 필요하다.
3️⃣ 임의 객체의 인스턴스 메소드 참조 → 인스턴스 변수::메소드
- 이미 생성된 객체의 메서드를 람다식에서 사용하는 경우에는 클래스 이름 대신 해당 객체의 참조변수를 적어줘야 한다.
MyClass obj = new MyClass();
Function<String, Boolean> f = (x) -> obj.equals(x); // 람다식
Function<String, Boolean> f2 = obj::equals; // 메서드 참조4️⃣ 생성자 참조 → 타입::new
- 생성자를 호출하는 람다식도 메서드 참조로 변환이 가능하다.
Supplier<MyClass> s = () -> new MyClass();
Supplier<MyClass> s = MyClass::new;- 매개변수가 필요한 생성자라면, 매개변수의 갯수에 따라 알맞은 함수형 인터페이스를 사용하면 된다.
(필요에 따라 함수형 인터페이스를 새로 정의해야 한다.)
Function<Integer, MyClass> f = (i) -> new MyClass(i);
Function<Integer, MyClass> f2 = MyClass::new;