나이계산
CASE WHEN EMPD.BIRT_DD IS NOT NULL
THEN TO_CHAR(FLOOR((SYSDATE-TO_DATE(EMPD.BIRT_DD,'YYYYMMDD'))/365.2422)+1) || '세'생일값이 비어있지 않다면 BIRT_DD를 연도,월,일로 인식하여 일수로 계산되고 SYSDATE 값을 뺴서 365일로 나누어 나이를 계산 후 FLOOR(소수점 내림)을 통해 소수점 날리고 날짜형이 아닌 문자형으로 변환하여 받은 후 '세'를 붙여 값을 얻는다.
TO_DATE( ) : 문자열을 날짜형 데이터로 변환
FLOOR( ) : 내림값으로 반환
TO_CHAR( ) : 숫자 또는 날짜 값을 문자열로 변환
++ SYSDATE는 2023/04/27 이런 형태로 되어있지만 계산될 때는 일수로 계산되는 점이 신기방기
오라클하고 자바하고 햇갈렸던 것
- ||
자바는 or
오라클은 값 합치기(CONCAT기능) - 와일드 카드
자바는 제너릭에서 사용하는 <?>
오라클은 값을 찾을때 사용 %
( 예시 : SELECT * FROM EMP WHERE ENAME LIKE %송똘똘%; )
iBatis LIKE 구문 쓰기
SELECT *
FROM tbl_name
WHERE column_name LIKE '%' || #value# || '%' LIKE 구문 사용시 '%' 써주자.
ibatis랑 myBatis랑 문법이 살짝 다름
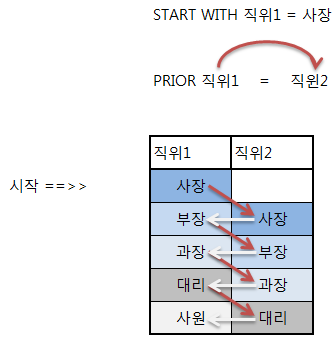
오라클 CONNECT_BY_ROOT, START WITH, CONNECT BY PRIOR
SELECT DEPM_CD, CONNECT_BY_ROOT(DEPM_CD) AS SABB_CD
, CONNECT_BY_ROOT(DEPM_NM) AS SABB_NM
, CONNECT_BY_ROOT(SORT_NO) AS SORT_NO
FROM SHRS.T_HR_DEPM
START WITH COMM_CD = #G_COMM#
AND DEPM_GU = '0018'
CONNECT BY PRIOR COMM_CD = COMM_CD
AND PRIOR DEPM_CD = TDEP_CDCONNECT_BY_ROOT( ) : 계층의 최상위 값을 표시
START WITH : 계층구조의 시작 조건을 기술
CONNECT BY : 계층구조의 전개 조건을 기술
CONNECT BY PRIOR COLUMN1 = COLUMN2 를 예로 들자면
COLUMN1이 COLUMN2를 찾아 간다.
SqlDeveloper칼럼 의미 찾기
방법1. 이클립스에서 xml 찾기
넥사크로 script에서 값을 불러온 xml형태의 쿼리문을 찾아간다. 보통 칼럼옆에 주석으로 해당 칼럼을 표시해놓는다.
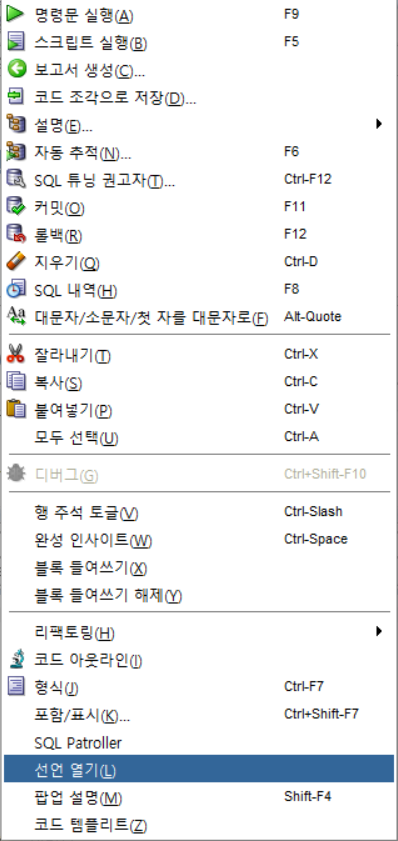
방법2. SQL Developer에서 찾기
SQL Developer 접속 후 원하는 테이블 선택 -> 마우스 오른쪽 클릭 -> 선언 열기(또는 팝업 설명) 누르면 칼럼의 이름, 타입, comments등이 나온다. comments가 칼럼 의미
dataset에 Tmp를 만드는 이유
특정 부분의 데이터값만 따로 관리할 때 같은 ds를 또 만들지 않고 기존의 데이터셋을 그대로 가져와서 사용한다. 데이터셋을 구분하여 사용할 수 있고 다시 데이터셋을 만드는 번거로움을 없앨수 있으며 칼럼명이 바뀌는 등의 개발실수를 줄일 수 있다.
오라클 DECODE 구문
DECODE(칼럼, 조건1, 결과1, 조건2, 결과2, ...)
칼럼1==조건1이면 결과1, 칼럼1==조건2이면 결과2 ....
코드로 하면
if (칼럼 == 조건1) {
return 결과1;
} else if (칼럼 == 조건2) {
return 결과2;
} 실무예시
DECODE(B.MBYM_PSCD, '0001', '1', '0') AS PSCD_0001
DECODE(B.MBYM_PSCD, '0002', '1', '0') AS PSCD_0002
DECODE(B.MBYM_PSCD, '0003', '1', '0') AS PSCD_0003
DECODE(B.MBYM_PSCD, '0004', '1', '0') AS PSCD_0004
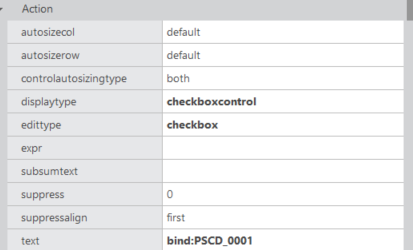
DECODE(B.MBYM_PSCD, '0005', '1', '0') AS PSCD_0005PSCD는 평가등급에 따라 0001~0005까지 값이 들어있다. 이 값을 0 또는 1로 바꾸는데 그 이유는 체크박스로 표현하기 위해서 이다.

그리드에 바인딩 하여 PSCD_0001~0005 값들을 넣어줌으로써 평가등급에 따른 체크박스를 표현할 수 있다.
CASE..WHEN..THEN 구문하고 비슷하나 DECODE는 복잡한 조건문은 만들지 못한다.
조건과 같은지만 체크하는 기능이기 때문이다.
오라클 NVL, COALESCE
NVL( 값,지정값 ) : 값이 NULL인 경우 지정값, 아니면 원래값 출력
COALESCE( 칼럼1, 칼럼2, 칼럼3.. ) : NULL값이 아닌 첫번째 칼럼값 출력( EX. 칼럼1,칼럼3이 NULL, 칼럼2는 NULL이 아닐때 칼럼2의 값 출력 )
오라클 분석함수 OVER( )
OVER( ) 사용 이유 : 서브쿼리 개선
집계함수( SUM,COUNT,AVG등 )는 단일함수 또는 집계되지 않은 칼럼과 같이 쓸 수 없기 때문에 서브 쿼리를 써야 한다. 하지만 OVER( )을 이용하면 서브쿼리 없이 쿼리를 짤 수 있다.
예시 )
SELECT
SALARY
, ( SELECT SUM(SALARY) FROM EMPLOYEES ) AS salary_total
FROM EMPLOYEES이 쿼리를
SELECT
SALARY
, SUM(SALARY) OVER() AS salary_total
FROM EMPLOYEES이렇게
++ 추가
1. 집계함수 자리에 오는 대표적 함수 : COUNT, SUM, AVG
2. OVER( )절은 FROM, WHERE, GROUP BY, HAVING절 이후에 계산
3. OVER절 괄호안의 구문 : PARITION BY(GROUP BY사용), ORDER BY(정렬), 세부분할기준(추가분할기준)
MERGE
MERGE
INTO (테이블)
USING (테이블)
ON (조건절)
WHEN MATCHED THEN
UPDATE SET ....
WHEN NOT MATCHED THEN
INSERT ....하나의 쿼리로 업데이트, 인서트, 딜리트등을 동시에 처리하고 싶을 때 사용
공백 방지
RETI_DD == null ? "" : "cell_Mark_UnderLine" 이렇게 짜도 기능상 문제 없지만 데이터 이관 혹은 빈칸 입력시 빈값(null)이 아닌 공백이 들어갈 수 있다. 그러므로
String(RETI_DD).valueOf() == "undefined" ? "" : "cell_Mark_UnderLine" 이런식으로 공백 방지 해준다. 일종의 벨리데이션 체크
조건에 따른 조회 값 (Ibatis)
-
이렇게 where문에 넣어 쿼리를 짜면 반드시 회사코드가 일치하는 값들만 가지고 온다.
WHERE PROM.COMM_CD = #G_COMM# /* 회사코드 */ -
이렇게 따로 빼놓게 되면 조건에 따라 필요한 값을 가지고 올 수 있다.
예를 들어 화면에서 부서명만 입력(1)하거나 부서명과 시스템 사번 전부 입력(2)할 수 있다.
그렇게 되면 부서명이 일치하는 모든 값을 가져오거나(1) 부서명 + 시스템 사번이 모두 일치 했을 때의 디테일한 값을 가져올(2) 수도 있다.<isNotNull col="FROM_YY"> AND PROM.PROM_YY = #FROM_YY# /* 적용년월 */ </isNotNull> <isNotNull col='SESU_ID'> AND PROM.SYST_ID = #SESU_ID# /* 사원 */ </isNotNull>
CONCAT(합치기), LIKE(같은거 선택), '%' '%'(단어 앞 또는 뒤에 포함하는 값이 있는지), MyBatis(#{ }), IN(일치하는거 다가지고 오기) 조합 (MyBatis)
ACCH.DEPM_CD IN
(
SELECT DEPM_CD
FROM V_HR_DEPM_01
WHERE COMM_CD = #{gvCommCd}
AND DEPM_PH LIKE CONCAT('%', #{DEPM_CD}, '%')
)전체 : 서브쿼리안의 DEPM_CD 가지고 오기
서브쿼리 : 'V_HR_DEPM_01' 테이블안의 COMM_CD가 가지고 온 gvCommCd 값과 같고 DEPM_PH 중에 가지고온 DEPM_CD의 값이 포함되어 있는 DEPM_CD값
Oracle 개념
- 프로시저
트랜잭션 언어 - 뷰
가상 테이블 - 트리거
데이터 삽입, 갱신, 삭제 등의 이벤트 발생시 자동실행 sql - 인덱스
키,벨류 구성으로 레코드를 빠르게 접근 - 시퀀스
순차적 정수값 생성 - 클러스터
데이터 블록을 물리적으로 저장
MSSQL의 IIF, LEN
DEPM_CD = IIF
(
LEN(#{DEPM_CD}) < 1
, ( SELECT DEPM_CD
FROM T_HR_DEPM DEPM
WHERE DEPM.COMM_CD = #{gvCommCd}
AND DEPM.TDEP_CD ='*' AND DEPM.DISP_YN = '1' AND DEPM.USED_YN = '1')
, #{DEPM_CD}
)LEN : 문자열의 길이
IIF : IIF(조건식, '참', '거짓')
EX) SELECT IIF(@score >= 70, '합격', '불합격') AS score -> score가 70점 이상일시 합격, 미만이면 불합격
--> 길어지면 IIF 쓰지말고 CASE WHEN 구문 쓰자
MSSQL의 WITH문(가상테이블)
WITH T1 AS
(
SELECT TI_IDX,TR_IDX,PT_IDX,PT_ADD1
FROM BC_PERSONALTEST T
WHERE T.TR_IDX = 4248
AND T.TI_IDX = 9
)
,T2 AS
(
SELECT TI_IDX,TR_IDX,PT_IDX,PT_ADD2
FROM BC_PERSONALTEST T
WHERE T.TR_IDX = 4248
AND T.TI_IDX = 9
)
,T3 AS
(
SELECT SUM(CAST(ROUND(A.PT_ADD1 * AA.PT_ADD2, 0, - 1) AS NUMERIC(12, 0))) RATIO
FROM T1 A, T2 AA
)
SELECT (T1.PT_ADD1 + T2.PT_ADD2) AS TSUM,T1.PT_ADD1,T2.PT_ADD2,T3.RATIO
FROM T1,T2,T3
WHERE T1.TI_IDX=T2.TI_IDX
AND T1.TR_IDX=T2.TR_IDX
AND T1.PT_IDX=T2.PT_IDX마지막 SELECT문에 WITH절로 만든 가상 테이블을 이용해서 원하는 로직을 커스텀 할 수 있다.
현재 시간 GETDATE()
MO_DT = GETDATE() /* 수정일시 */오라클의 SYSDATE()하고 같음. 현재 날짜 가져오기
칼럼 수 커스텀
SUM(IIF(PR05.ROUT_CD IS NOT NULL, 1, 0)) ROUT_CT /* 라우팅수 */ SUM과 IIF를 이용하여 ROUT_CD(라우팅코드)가 몇 개인지 계산한다.
근데 쿼리에서 계산하면 속도 느려진다.
날짜 가져와서 포맷하기
날짜 데이터 가지고 올 때 : DB에 있는 date타입의 값을 쿼리에서
CONVERT(CHAR(19), SA30.IN_DT, 20) AS IN_DT이런식으로 문자형으로 바꾼 다음 원하는 날짜 형태로 바꾼다. '20' 외에 여러가지 숫자를 통해 여러가지 형태로 바꿀 수 있다.
조인
기본적으로 CO4000 테이블에 있는 값을 조회할건데 CO5000 테이블에 있는 칼럼값이 있는 값만 조회하고 싶을 때 CO4000에 CO5000을 조인하게 된다. 이때 CO5000에 있는 PK값과 원하는 조건값이 일치하는 쿼리를 짠다.
SELECT CO4000.GD_NM
FROM CO4000 CO4000
JOIN CO5000 CO5000
ON CO5000.PK_CD = CO40.PK_CD
AND CO5000.STTS_CD = 'true'GD_NM : 조회할 값
PK_CD : PK 값
STTS_CD : 상황에 따른 상태값, 조건값
기본적인 join쿼리
Decimal VS Numeric
둘 다 소수점 표현가능하고 별 차이 없다고 한다...
Group by VS Partion by
둘 다 그룹 지어주는 거지만
GROUP BY는 그룹 지어준 다음에 중복값을 제거해버리고
PARTION BY는 그룹 지어준 행들을 하나하나 조회 한다.
최근 뷰 테이블로 PARTION BY가 사용된 쿼리를 봤는데(굳이 뷰로 빼지 않아도 되긴함) 일단 상황은
등록테이블값이 변경 됬을때 변경테이블로 따로 관리해주는 상황이고 현황 테이블은 변경되지 않았으면 등록테이블에서, 변경되었으면 변경테이블에서 값을 가져와야 되는 상황이다.
WITH RANKDATA AS (
SELECT RANK() OVER (PARTITION BY PO_NO ORDER BY IN_DT DESC) AS LAST_NO,*
FROM (
SELECT *
FROM 등록테이블
UNION ALL
SELECT *
FROM 변경테이블
)
)PO_NO는 PK값이고 IN_DT는 등록날짜이다. RANK()함수에 의해 내림차순으로 조회되며 수정된 흐름을 다 보여준다.
RANKDATA 로 이름 붙여주고
SELECT * FROM RANKDATA
WHERE LAST_NO = 1;가장 최신껄로 가지고 온다.
피드백 및 조언 및 훈수 대환영입니다 !!
