프로세스
✔️ 프로세스 정의
- 실행중인 프로그램
- 하드디스크에 있는 명령어 집합인 프로그램이 메모리에 적재될 때, 프로그램이 프로세스가 된다.
프로그램, 프로세스는 다른 것이다.
- 프로그램은 명령어 집합이 디스크에 저장된 실행 파일이고, 수동적인 특성을 가진다.
- 프로세스는 다음에 실행할 명령어를 지정하는 프로그램 카운터와 관련 자원 집합을 가지는, 능동적인 특성을 가진다.
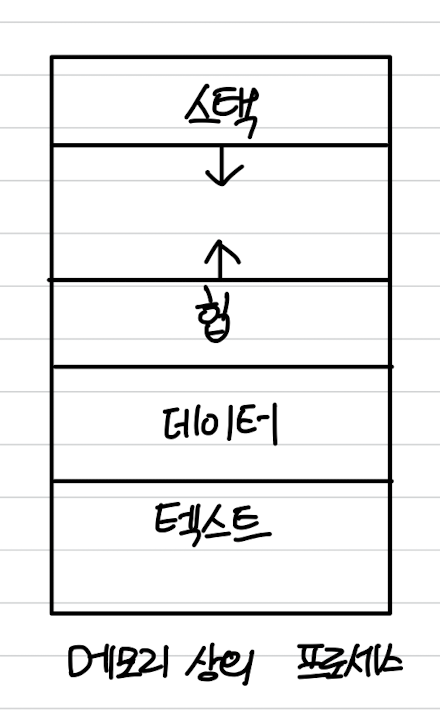
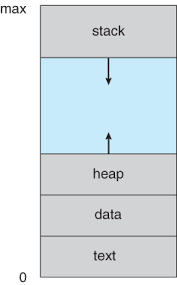
프로세스는 메모리에서 아래와 같은 구조로 저장된다.
- 텍스트 섹션: 프로그램 코드 공간
- 스택: 함수의 매개변수, 복귀 주소, 로컬 변수와 같은 임시적인 데이터를 저장하는 공간
- 데이터 섹션: 전역 변수들을 저장하는 공간
- 힙: 프로세스 실행 중에 동적으로 할당되는 메모리 공간
✔️ 상태
프로세스는 실행되면서 상태가 변한다.
프로세스는 아래 상태들 중 하나에 있게 된다.
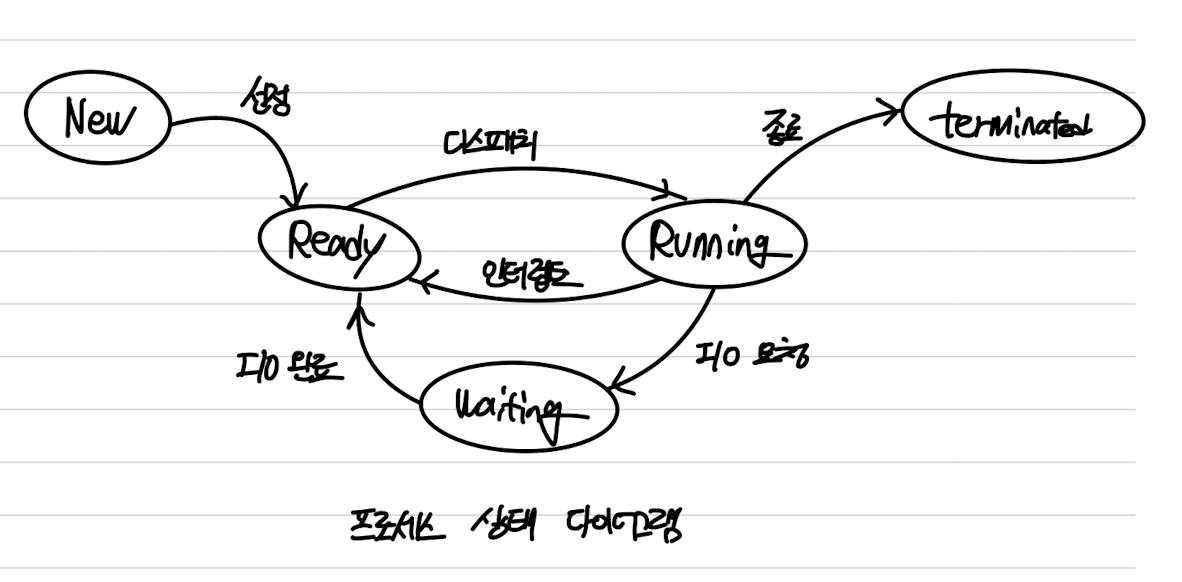
- New: 프로세스가 생성 중이다.
- Running: 명령어들이 실행되고 있다.
- Ready: 프로세스가 CPU에 할당되기를 기다린다.
- Waiting: 프로세스가 어떤 사건(입출력 또는 신호)이 일어나기를 기다린다.
- Terminated: 프로세스의 실행(명령어)이 종료되었다.
운영체제마다 이름들이 임의적이지만 의미는 비슷하다.
CPU는 어느 한 순간에는 오직 하나의 프로세스만 실행할 수 있음을 명심하자. 즉, 1개의 CPU에 1개의 코어는 하나의 프로세스만 실행할 수 있다.
✔️ PCB(Process Control Block)
메모리 상에서 프로세스는 코드,데이터,힙,스택영역으로 구성되어 있다는 것은 알겠다.
그러면 OS가 프로세스를 어떤식으로 관리를 할까?
OS는 프로세스를 PCB(Process Control block)이라는 자료구조를 사용하여 관리한다.

- 프로그램 카운터: 프로세스가 다음에 실행할 명령어의 주소
- CPU 레지스터: 컨텍스트 스위칭이 발생할 때 여기에 저장된 정보로 Switching 한다.
- CPU 스케줄링 정보:
- 프로세스의 우선순위
- 스케쥴링 큐에 대한 포인터
- 메모리 한계:
- 기준 레지스터 값
- 한계 레지스터 값
- 입출력 상태 정보
- 스레드에 대한 정보 등등
즉, PCB는 프로세스마다 달라지는 모든 정보를 저장하는 자료구조이다.
언제 생성
- 프로그램이 메모리에 적재되면 운영체제가 해당 프로세스에 대한 PCB를 만들고 초기화한다.
어디에 위치
- 일반적으로 PCB는 운영 체제의 커널 영역에 위치한다.
- 커널 영역에 저장되어야 운영체제가 직접 접근하여 PCB 정보를 읽고 업데이트할 수 있기 때문이다.
언제 삭제
- 프로세스가 종료되면 PCB가 사용하던 메모리와 자원을 해제한다.
프로세스 스케줄링
Multi Programming의 목적
- CPU 효율을 높이기 위해 Multi Programming 한다.
- Multi Programming은 항상 프로세스가 실행될 수 있도록 메모리에 여러 프로세스를 할당한다.
시분할의 목적
- 프로세스가 실행되는 동안 사용자가 상호 작용할 수 있도록 하기 위해서이다.
- 시분할 프로그래밍은 프로세스를 time-slice 기준으로 CPU를 빈번하게 할당하는 것이다.
모든 목적은 CPU 효율을 높이기 위해서이다.
그럴려면 현재 실행하고 있는 프로세스 다음에 실행할 프로세스를 선택하는 스케쥴링 과정이 필요하다.
그 역할을 하는 것이 프로세스 스케쥴러이다.
- 프로세스 스케쥴러는 운영체제의 소프트웨어 컴포넌트이다.
- 커널 영역에 구현되어 있다.
✔️ 스케쥴링 큐
- 프로세스가 시스템에 들어오면, 큐에 위치하게 된다.
- CPU를 할당받고 어느정도 실행을 하다가 인터럽트 되거나, I/O를 요청할 때 등등 프로세스 상태에 따라 위치하는 큐가 달라진다.
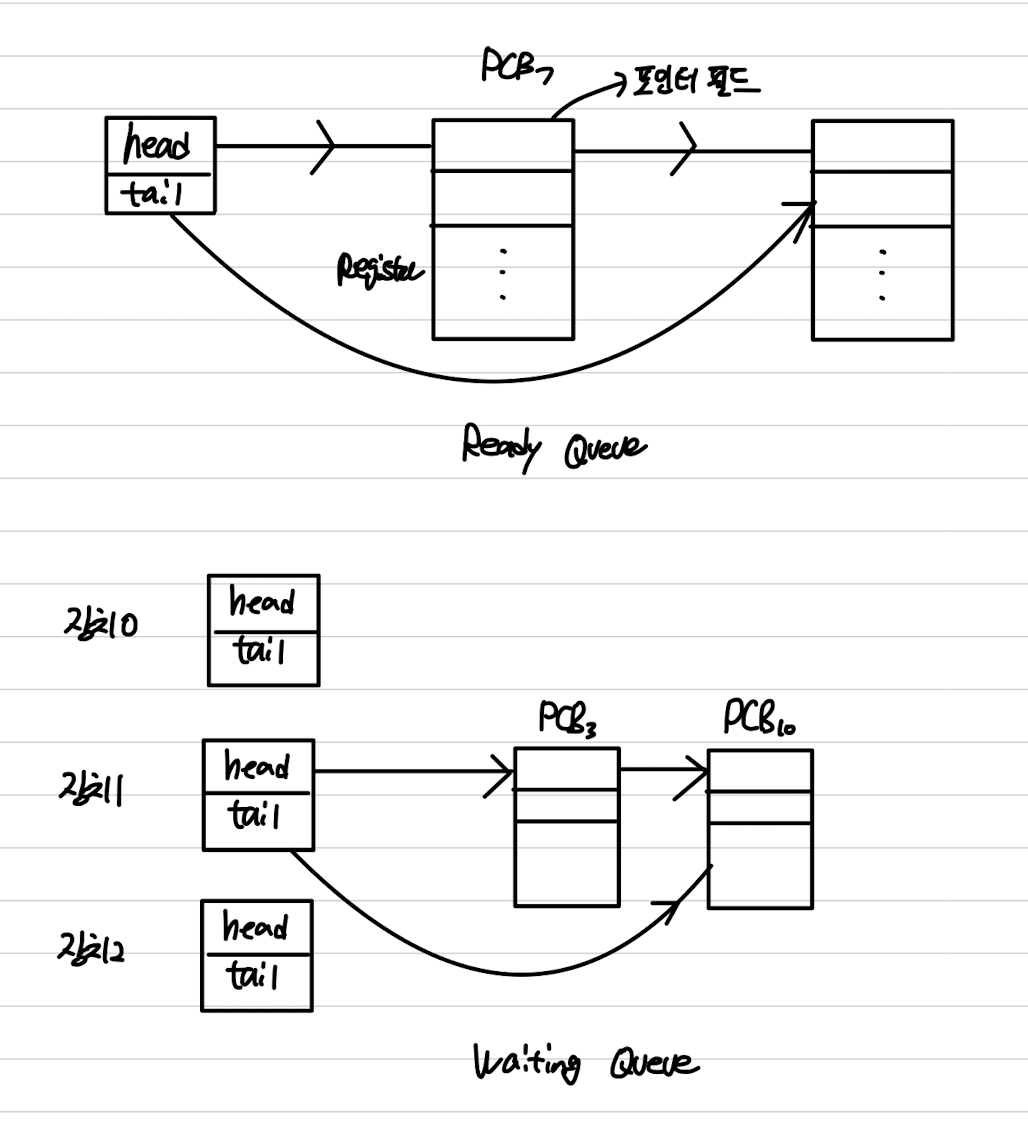
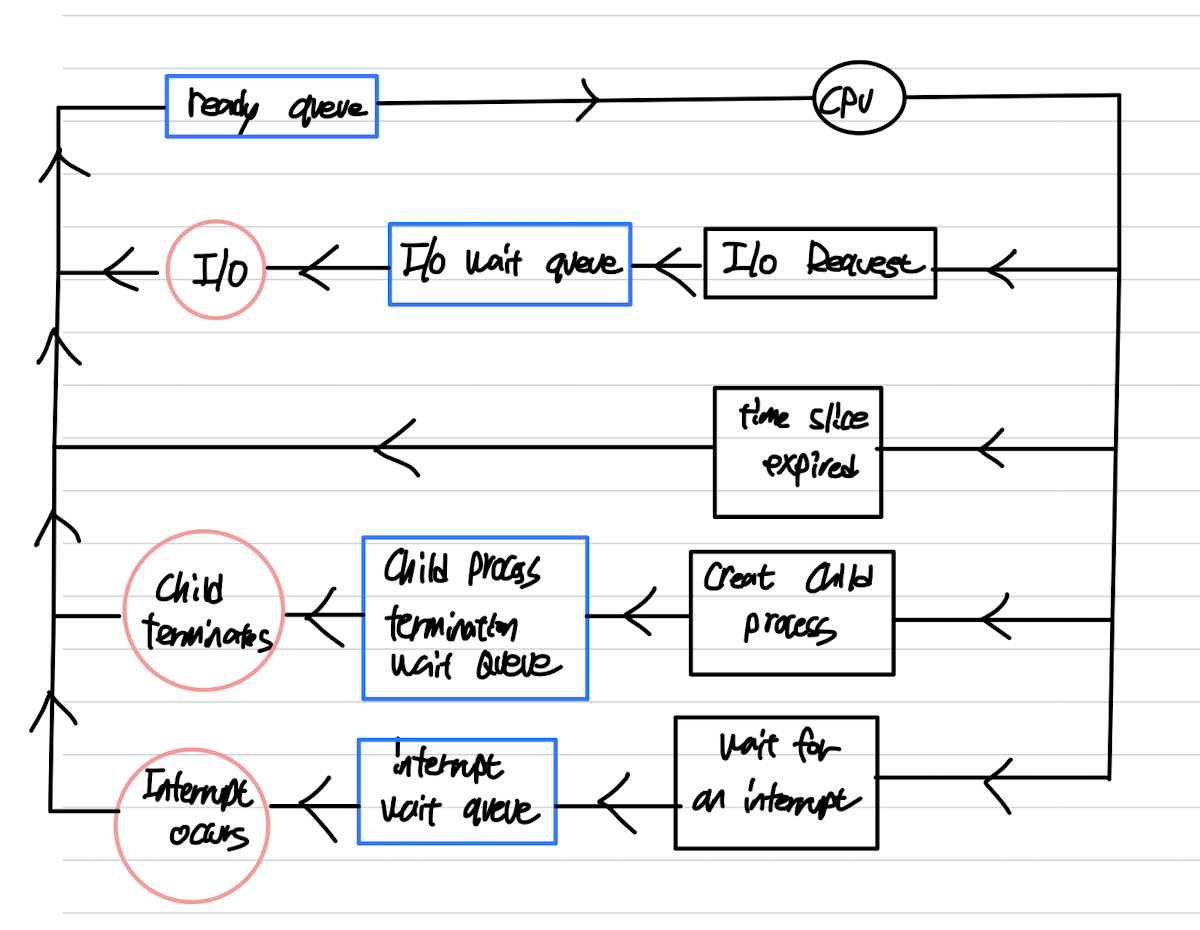
큐는 주로 운영 체제의 커널 영역에 위치한다.
-
Ready Queue:
- 스케줄러: CPU 스케줄러
- 실행 가능한(CPU 할당을 받을 수 있는) 프로세스들이 대기하는 큐이다.
- CPU를 할당받을 때까지 Ready 큐에 위치한다.
- 커널 내부의 스케줄러에서 관리하고, OS마다 스케줄러 알고리즘은 다르다.
-
I/O Waiting Queue
- 스케줄러: I/O 스케줄러
- I/O 작업을 대기하는 프로세스들이 대기하는 큐
- I/O 디바이스마다 별도의 디바이스 큐가 있다.
- 디바이스 큐는 디바이스 컨트롤러 또는 드라이버에 의해 관리된다.
- 일반적으로 커널 영역에 위치한다.
- 입출력 작업이 완료되면 입출력 관리자에 의해 대기 큐에서 준비 큐로 이동한다.
✔️ 스케쥴러
프로세스는 일생 동안에 다양한 스케줄링 큐들 사이를 이주한다.
스케줄링 목적을 위해서 프로세스들은 큐에서 반드시 선택되어야 하고, 해당 역할은 스케줄러가 한다.
OS에서 스케줄러는 크게 3가지로 볼 수 있다. 장기,중기,단기 스케줄러로 구분한다.
스케줄러 간 차이점은 실행 빈도에 있다.
장기 스케줄러(Job Scheduler)
- 메모리에 적재할 수 있는 프로그램보다 더 많은 프로그램이 실행되려고할 때, 메모리에 적재될 프로세스를 스케줄링한다.
- 스케줄링 빈도수가 적다.
- 장기 스케줄러는 멀티프로그래밍 정도(메모리에 있는 프로세스의 수)를 제어한다.
- I/O Bound, CPU Bound 프로세스를 혼합해서 선택하는것이 중요하다.
- 한 쪽으로 치우쳐진 구조이면, 장치를 사용하지 않거나, CPU 효율이 떨어지거나 시스템 균형을 잃게 된다.
중기 스케줄러
- 메모리에서 CPU 할당 경쟁을 하는 프로세스들을 제거함으로써 다중 프로그래밍의 정도를 완화하도록 스케줄링한다.
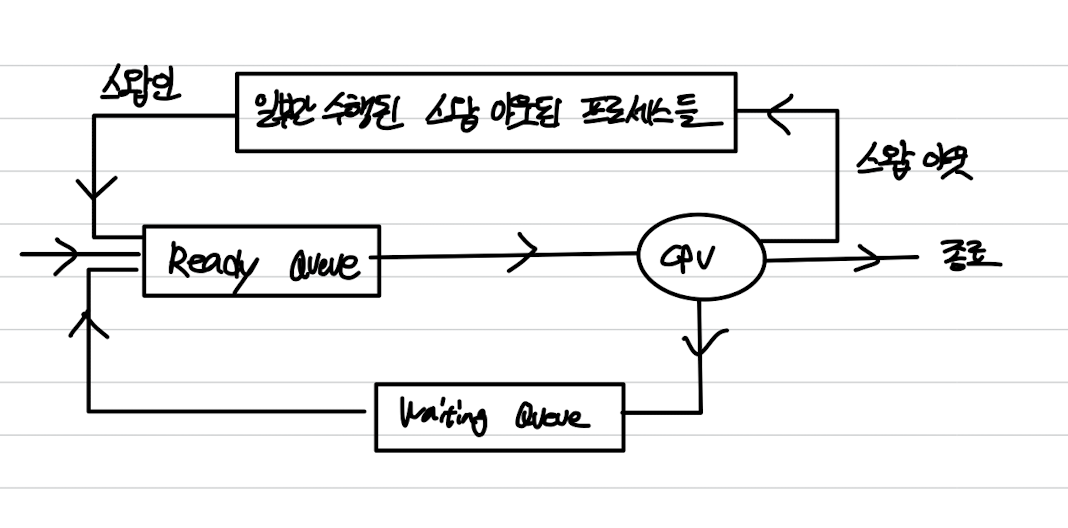
단기 스케줄러(CPU Scheduler)
레디큐에서 실행대기 중인 프로세스를 스케줄링한다.
프로세스 일생
1. New : 프로그램이 메모리에 적재되면 운영체제는 해당 프로세스의 PCB를 생성하고 초기화한다.
2. Ready :Ready Queue에서 CPU를 할당받을 때까지 대기한다.
3. Running : CPU를 할당받아 명령어를 수행한다.
4. 수행하는 도중에 아래와 같은 상황이 발생한다.
- 인터럽트/트랩 발생
- I/O 요청
- Time Slice Expired
- 자식 프로세스 생성 후 대기
- 종료
- 각 상황에 따라 자원 반납(terminated) 혹은 Ready Queue(Ready), Waiting Queue(waiting)에서 대기한다.
프로세스 연산
✔️ 프로세스 구조
- 프로세스는 트리 구조로 구성된다.
- 프로세스를 생성하는 프로세스를 부모 프로세스라고 부르고, 새로운 프로세스는 자식 프로세스이다.
- 운영체제는 프로세스를 PID(프로세스에게 할당 된 고유한 ID)로 구분한다.
- 식별자는 보통 정수이고, 고유하다.
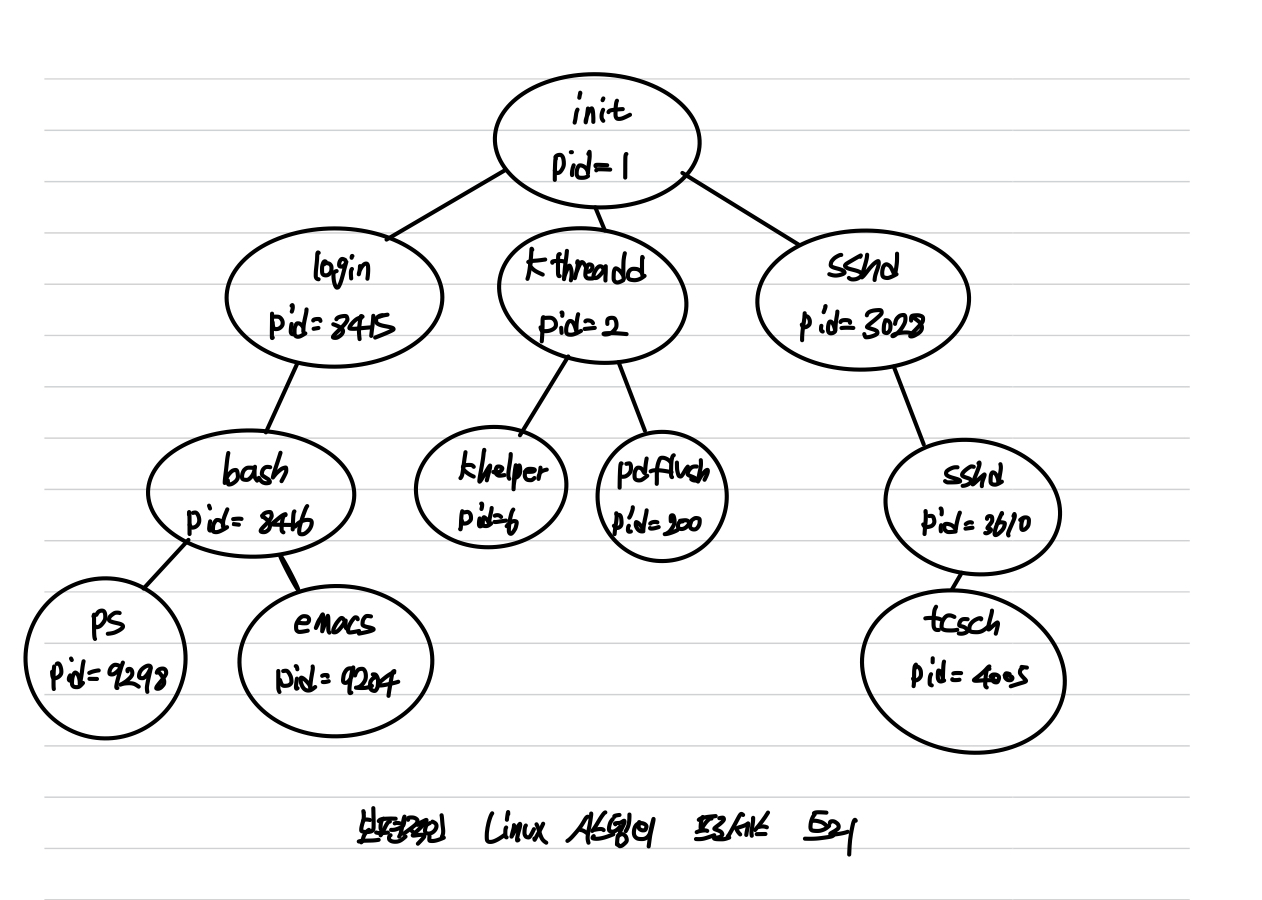
- pid=1 인
init프로세스가 모든 사용자 프로세스의 루트 부모 프로세스 역할을 수행한다. - 시스템이 부팅되면 init 프로세스가 다양한 사용자 프로세스를 생성한다.
kthread: 커널을 대신하여 작업을 수행할 추가적인 프로세스를 생성하는 책임을 진다. 위 예제에서 추가 프로세스는khelper,pdflush프로세스이다.sshd: ssh를 사용하여 시스템에 접속하는 클라이언트를 관리하는 책임이 있다.
✔️ 프로세스 생성
자식 프로세스의 자원 할당
일반적으로 프로세스가 자식 프로세스를 생성할 때, 자식 프로세스는 자원을 필요로 한다.
- 자식 프로세스는 운영체제로부터 직접 얻거나, 부모 프로세스가 가진 자원의 부분 집합만을 사용하도록 제한될 수 있다.
- 부모 프로세스는 자원을 분할하여 자식 프로세스들에게 나누어 주거나, 메모리나 파일과 같은 몇몇 자원들은 자식 프로세스들과 같이 사용하게 할 수도 있다.
부모 프로세스 실행 방식
- Asynchronous: 부모는 자식과 병행하게 실행을 계속한다.
- Synchronous: 일부 또는 모든 자식이 실행을 종료할 때 까지 기다린다.
자식 프로세스의 메모리 공간
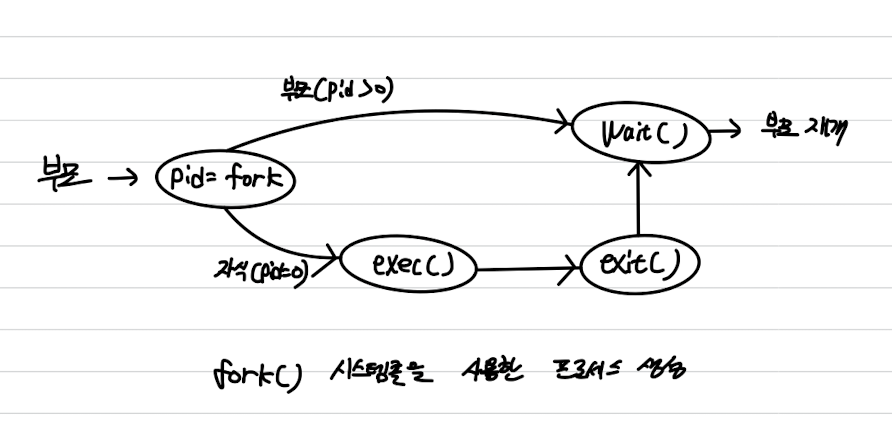
- 부모 프로세스의 복사본(부모와 똑같은 프로그램과 데이터를 가짐)
- EX)
fork()시스템콜 - 부모 프로세스가 자식 프로세스를 생성할 때, 부모 프로세스의 코드, 데이터, 힙, 스택 영역은 자식 프로세스에게 복제된다.
- EX)
- 자식 프로세스는 자신에게 적재될 새로운 프로그램을 갖고 있는 경우
- EX)
exec()시스템콜 - 생성된 자식 프로세스의 메모리 공간을 새로운 프로그램으로 초기화한다.
- EX)
자식 프로세스 생성
- 자식 프로세스가 생성될때 부모 프로세스의 PCB를 기반으로 자식 프로세스 PCB가 생성되고, 자식 프로세스만의 메모리 공간을 할당받아 사용한다.
- 즉, 부모 프로세스와 자식 프로세스 간의 메모리를 공유하지 않는다. 그러나, PCB 영역은 부모 프로세스와 자식 프로세스 간에 일부 정보를 공유할 수도 있다.
- 자식 프로세스는 열린 파일과 같은 자원뿐 아니라 특권과 스케줄링 속성을 부모 프로세스로 부터 상속받는다.
주소 복사 방식
- 복사는 대부분 가상 메모리를 통해 이루어지며, 실제로 데이터를 복사하는 것이 아닌 페이지 테이블등을 조작하여 가상 주소 공간을 공유한다.
- 이를 Copy-on-write(복사 온라인)이라고 한다.
- 복사 온라인 기법은 효율적인 자원 관리를 위해 사용되는 메모리 관리 기법 중 하나이다.
✔️ 프로세스 종료
- 자식 프로세스는
exit()시스템콜을 사용하여 운영체제에게 자신의 삭제를 요청하여 종료된다. - 이 시점에서 프로세스는 자신의 부모 프로세스에게(
wait시스템콜을 통해) 상태값(= 통상 정수값)을 반환할 수 있다.- 물리 메모리와 가상 메모리, 열린 파일, 입출력 버퍼를 포함한 프로세스의 모든 자원이 운영체제로 반환된다.
자식 프로세스 종료
부모 프로세스는 여러 가지 이유로 자식 프로세스의 실행을 종료할 수 있다.
- 자식이 자신에게 할당된 자원을 초과하여 사용할 경우
- 자식에게 할당된 태스크가 더 이상 필요 없을 경우
- 부모가
exit를 하는데, 운영체제는 부모가exit한 후에 자식이 실행을 계속하는 것을 허용하지 않을 경우- 이와 같은 경우 프로세스가 종료되면 그로부터 비롯된 모든 자식 프로세스들도 종료되어야 한다. 이를 연쇄식 종료라고 한다.
- 이 작업은 운영체제가 시행한다.
✔️ 좀비 프로세스
- 프로세스가 종료되면 사용하던 자원은 운영체제가 되찾아 간다.
- 그러나 프로세스의 종료 상태가 저장되는 프로세스 테이블의 해당 항목은 부모 프로세스가
wait()를 호출할 때까지 남아 있게 된다. - 종료되었지만 부모 프로세스가 아직
wait()를 호출을 하지 않은 프로세스를 좀비 프로세스라고 한다. - 종료하게 되면 모든 프로세스는 좀비 상태가 되지만 아주 짧은 시간 동안만 머무른다.
- 부모가
wait()를 호출하면 좀비 프로세스의 프로세스 식별자와 프로세스 테이블의 해당 항목이 운영체제에게 반환된다.
✔️ 고아 프로세스
- 부모 프로세스가 자식 프로세스가 종료되기 전에 종료되었을 때 자식 프로세스는 고아 프로세스가 된다.
- 즉, 부모 프로세스가
wait()를 호출하는 대신 종료한다면 이 상황에 처한 자식 프로세스를 고아 프로세스라고 한다. - Linux와 UNIX는 고아 프로세스의 새로운 부모 프로세스를 init 프로세스를 지정함으로써 이 문제를 해결한다.
- init 프로세스는 주기적으로
wait()를 호출하여 고아 프로세스의 종료 상태를 수집하고 프로세스 식별자와 프로세스 테이블 항목을 OS에게 반환한다.
프로세스 간 통신
✔️ 프로세스 간 통신이란
- 서로 다른 프로세스 간에 데이터를 공유할 때 두 프로세스는 통신한다고 한다.
- 프로세스 간 통신 방법에는 2가지 통신방식이 있다.
- 공유 메모리
- 메시지 전달
- 많은 시스템들이 두가지를 모두 구현한다.
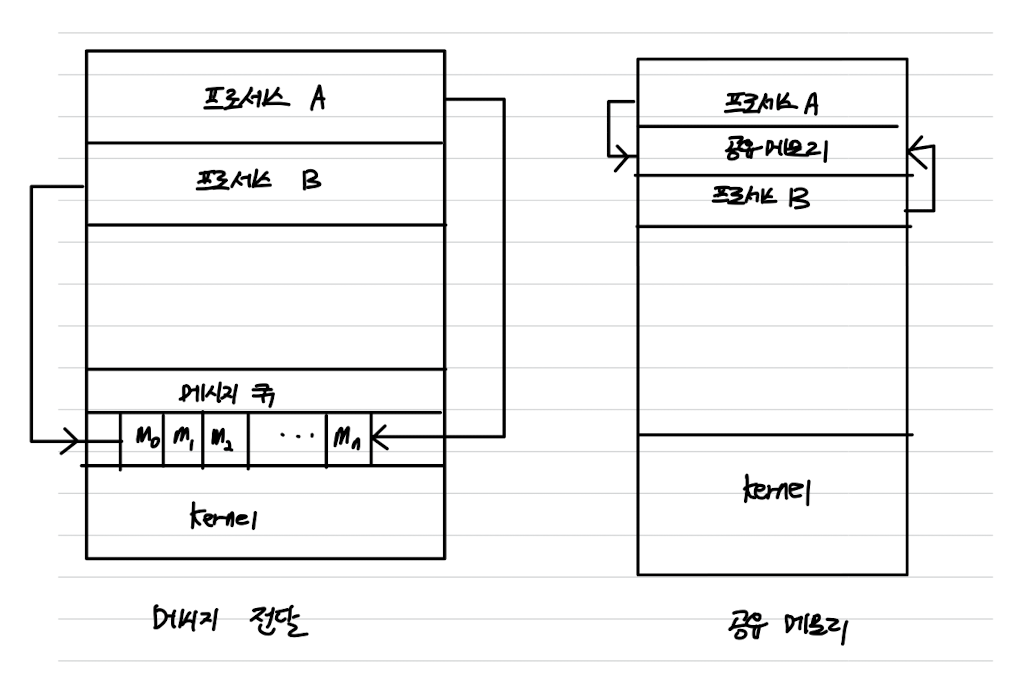
✔️ 공유 메모리
-
공유 메모리 영역을 구축하여 프로세스들은 그 영역에 데이터를 읽고 씀으로써 데이터를 공유한다.
- 공유 메모리를 구축할 때만 시스템콜 호출이 필요하다.
- 공유 메모리 영역이 구축되면 모든 접근은 일반적인 메모리 접근으로 취급되어 커널의 도움이 필요없다.
-
통상 공유 메모리 영역은 공유 메모리 세그먼트를 생성하는 프로세스의 주소 공간에 위치한다.
- 통신하는 다른 프로세스들은 이 세그먼트를 자신의 주소 공간에 추가하여 통신한다.
- 일반적으로 OS는 한 프로세스가 다른 프로세스의 메모리에 접근하는 것을 금지한다.
-
공유 메모리에 접근하고 조작하는 코드는 프로그래머에 의해 명시적으로 작성되어야 한다.
- 데이터 형식과 위치는 프로세스들에 의해 결정되며 운영체제의 소관이 아니다.
- 프로세스들은 동기화 이슈를 책임져야 한다.
-
생산자-소비자 문제는 공유 메모리를 통해 해결할 수 있다.
- 공유 메모리에 버퍼를 넣고, 생산자는 버퍼에 데이터를 채워 놓고, 소비자는 버퍼에서 데이터를 소비한다.
- 생산자와 소비자는 반드시 동기화되어야 한다.
✔️ 메시지 전달
- 동일한 주소 공간을 공유하지 않고도 프로세스들이 데이터를 공유하고 동기화할 수 있도록 운영체제가 메시지 전달 수단을 제공한다.
- 통신하는 프로세스들이 다른 호스트에 존재하는 분산 환경에서 유용하다.
- 메세지 전달은 최소한 두가지 연산을 제공해야 한다.
send(message),receive(message)
직접/간접 통신
- 직접 통신(통신의 수신자 또는 송신자의 이름을 명시하여 통신하는 방법)
send(Q,message),receive(P,message)- 통신을 원하는 프로세스 쌍들의 링크가 자동적으로 구축된다.
- 링크는 정확히 두 프로세스들 사이에만 구축된다.
- 통신하는 프로세스들의 각 쌍 사이에는 정확하게 하나의 링크만 존재한다.
- 간접 통신(메시지들은 메일박스(or 포트)로 송신되고, 수신하여 통신하는 방법)
send(A,message),receive(A,message)- 각 메일박스는 고유의 id를 가진다.
- 프로세스는 다수의 메일 박스를 통해 다른 프로세스들과 통신할 수 있다.
- 한 쌍의 프로세스들 사이의 링크는 이들 프로세스가 공유 메일박스를 가질 때만 구축된다.
- 링크는 두 개 이상의 프로세스들과 연관될 수 있다.
동기/비동기 통신
메시지 전달은 send(message), receive(message) 연산을 제공해야 한다고 위에서 언급하였다.
send(message), receive(message)을 어떻게 구현하는데 있어서 Blocking, Non-blocking 상태로 나뉠 수 있다.
-
Send- Blocking: 송신 프로세스는 메시지가 수신 프로세스 또는 메일박스에 수신될 때까지
Blocking된다 - Non-blocking: 송신 프로세스는 메시지를 송신하고 작업을 계속한다.
- Blocking: 송신 프로세스는 메시지가 수신 프로세스 또는 메일박스에 수신될 때까지
-
Receive- Blocking: 수신 프로세스는 메시지가 도착할 때까지
Blocking된다. - Non-blocking: 수신 프로세스는 유효한 메시지를 받거나
null을 받는다.
- Blocking: 수신 프로세스는 메시지가 도착할 때까지
send(),receive()가 모두 동기식으로 동작하면 Rendezvous를 이루게 된다.
✔️ 공유 메모리 VS 메시지 전달
- 속도
- 메시지 전달은 시스템콜을 사용하여 구현되므로 커널 간섭 등의 부가적인 시간 소비 작업들이 필요하기 때문에 공유 메모리 모델이 메시지 전달보다 빠르다.
- 공유 메모리 시스템에서는 공유 메모리 영역을 구축할 때만 시스템 호출이 필요하다.
- 구현
- 분산 시스템에서 메시지 전달이 공유 메모리보다 구현하기 쉽다.
- 메시지 전달은 충돌을 회피할 필요가 없기 때문에 적은 양의 데이터를 교환하는데 유용하다.
- 성능
- 많은 코어를 가진 시스템에서 메시지 전달이 공유 메모리보다 더 나은 성능을 보인다.
- 공유 메모리는 공유 데이터가 여러 캐시 사이에서 이주하기 때문에 발생하는 캐시 일관성 문제로 인하여 성능 저하가 발생한다.
✔️ 파이프
- 파이프는 초기 UNIX 시스템에서 제공하는 IPC 기법 중 하나이다.
- 파이프를 구현하기 위해서는 4가지 이슈를 고려해야 한다.
- 단방향 or 양방향 통신
- 양방향이라면 반이중 전송(한 순간에 한 방향 전송만 가능) or 전이중 전송(동시에 양방향 데이터 전송 가능)
- 두 프로세스 간에 부모-자식과 같은 특정 관계가 존재해야만 하는가?
- 네트워크를 통해 통신이 가능한가?
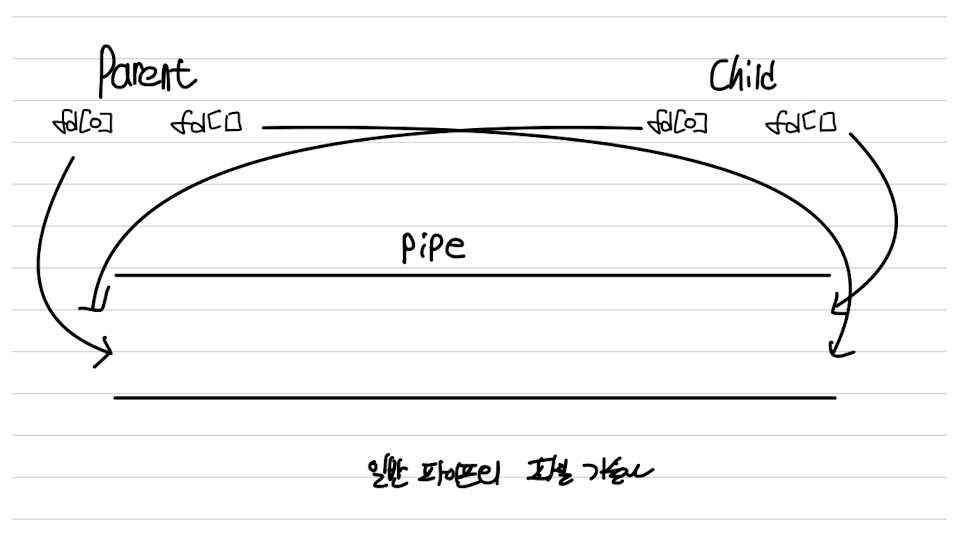
일반 파이프(Ordinary Pipes)
-
단방향 통신, 반이중 전송
- 양방향 통신이 필요하다면 두 개의 파이프를 사용해야 한다.
-
부모-자식 간의 통신
- 일반적으로 부모 프로세스가 파이프를 생성하여 자식 프로세스와 통신한다.
- 일반 파이프는 파이프를 생성한 프로세스 이외에는 접근할 수 없다.
- 자식 프로세스는 열린 파일을 부모로부터 상속받기 때문에 자식 프로세스는 부모로부터 파이프를 상속받는다.
-
일반 파이프는 오로지 프로세스들이 서로 통신하는 동안에만 존재한다.
- 프로세스들이 통신을 마치고 종료하면 일반 파이프는 없어지게 된다.
-
유닉스에서의 일반 파이프
- 유닉스는 파이프를 파일의 특수한 유형으로 취급
pipe(int fd[]);:fd[]파일 기술자를 통해 접근되는 파이프를 생성fd[0]: 파이프의 읽기 종단fd[1]: 파이프의 쓰기 종단
지명 파이프(Named Pipes)
일반 파이프보다 강력한 통신을 제공한다.
- 양방향 통신, 반이중 전송(Unix에서)
- 부모-자식 관계X
- 지명 파이프가 구축되면 여러 프로세스들이 이를 사용하여 통신할 수 있다.
- UNIX에서는 지명 파이프를 FIFO라고 부른다
- 생성되면 지명 파이프는 파일시스템의 보통 파일처럼 존재한다.
mkfifo(),open(),close()등 일반적인 시스템콜로 조작된다.
- 파일시스템에서 삭제될때까지 존재한다.
- 통신하는 두 프로세스는 동일한 기계 내에 존재해야 한다.(Unix에서)
- Windows 지명 파이프가 UNIX 파이프보다 훨씬 풍부한 통신 기법 제공
✔️ 클라이언트-서버 환경에서 IPC
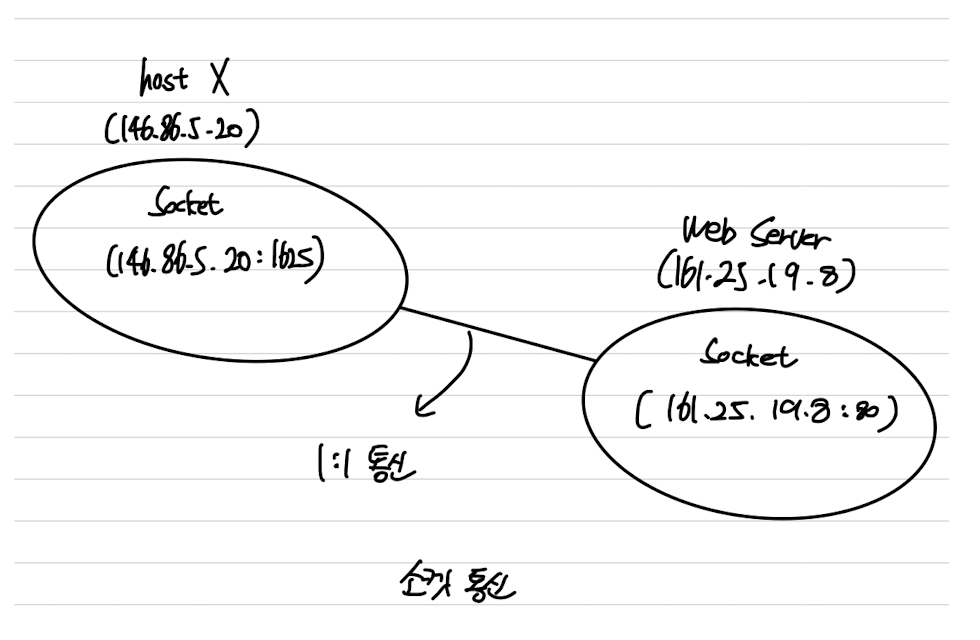
Sockets(소켓 통신)
-
소켓은 통신의
endpoint를 뜻한다.- 네트워크를 통하여 통신하는 한 쌍의 프로세스는 프로세스 당 하나씩 한 쌍의 소켓이 필요하다.
- 각 소켓은 (IP 주소 + 포트 번호)로 식별된다.
-
일반적으로 소켓은 클라이언트-서버 구조를 사용한다.
- 서버는 지정된 포트에 클라이언트 요청 메시지가 도착하기를 기다린다.
- 요청이 수신되면 서버는 클라이언트 소켓으로부터의 연결 요청을 수락함으로써 연결이 완성된다.
- 클라이언트 프로세스가 연결을 요청하면 호스트 컴퓨터가 포트 번호를 부여한다.
- 모든 연결은 유일해야 한다.
-
소켓 통신은 1:1 통신이다.
- 식별자 매핑을 통해 소켓을 식별한다.
- 서버는 클라이언트로부터 요청이 들어올때마다 클라이언트 정보에 매핑되는 식별자 매핑을 조회한다.
소켓
아래와 같은 통신에 필요한 다양한 정보와 상태를 저장한다.
- 소켓 주소: 네트워크 인터페이스 주소 + 포트 번호(IP 주소, 포트 번호)
- 통신 상태: 소켓 통신 상태 정보 저장(연결 중, 대기, 연결 종료 등)
- 수신 및 송신 버퍼
- 소켓 옵션
소켓 매핑 테이블
- 소켓 매핑 테이블은 서버가 클라이언트와 연결된 소켓을 관리하기 위한 자료구조이다.
- 이 자료구조는 연결된 소켓의 식별자와 함께 클라이언트의 정보를 매핑하여 저장한다.
- 소켓 아이디
- 클라이언트 IP 주소와 포트 번호
- 서버 IP 주소와 포트 번호
- 상태 정보(소켓 연결 상태)
- 기타 관련 정보(소켓 옵션,버퍼 크기 등과 같은 기타 소켓 관련 정보)
RPCs(원격 프로시저 호출)
-
클라이언트는 호스트에 프로시저를 호출하여 통신한다.
-
RPC 시스템은 클라이언트 쪽에 Stub을 제공하여 통신을 하는데 필요한 자세한 사항들을 숨겨준다. 보통 원격 프로시저 마다 다른 스텁이 존재한다.
-
클라이언트가 원격 프로시저를 호출하면 RPC는 그에 대응하는 스텁을 호출하고, 원격 프로시저가 필요로 하는 매개변수를 건네준다.
-
그러면 스텁이 원격 서버의 포트를 찾고 매개변수를 정돈한다.
-
그 후 스텁은 메시지 전달 기법을 사용하여 서버에게 메시지를 전송한다.
-
이 후 대응되는 스텁이 서버에도 존재하여 서버 측 스텁이 메시지를 수신한 후 적절한 서버의 프로시저를 호출한다.
요약
- 프로세스
- 프로세스는 실행 중인 프로그램이다.
- 프로세스는 실행되면서 상태가 변경된다.
- New, Ready, Waiting, Terminated
- 각 프로세스는 운영체제 내에서 PCB에 의해 표현된다.
- 프로세스가 실행중이지 않은 상태일 때는 적절한 대기 큐에 놓인다.
- 입출력 대기 큐, 준비 완료 큐
- 프로세스 스케줄링
- 장기(잡) 스케줄링: 메모리에 적재할 프로세스를 스케줄링
- 단기(CPU) 스케줄링: Ready Queue에서 프로세스를 스케줄링
- 프로세스 생성/종료
- 부모 프로세스는 새로운(자식) 프로세스를 생성한다.
- 부모는 작업을 진행하기 전에 자식 프로세스가 종료되는 것을 기다릴 수 있다.
- 부모와 자식 프로세스가 병행하게 실행될 수 있다.
- 프로세스 통신
- 공유 메모리: 통신을 위한 코드 조작 책임이 프로그래머에게 있다. 운영체제는 공유 메모리 공간만 제공한다.
- 메시지 전달: 운영체제가 메시지 전달 시설을 제공한다.
- 한 운영체제에서 두가지 방식 모두 사용될 수 있다.
- 클라이언트-서버 통신
- 소켓
- RPCs
