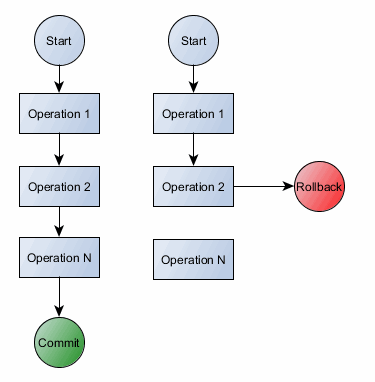
출처: https://vladmihalcea.com/a-beginners-guide-to-acid-and-database-transactions
Schedule
Schedule
- 여러 Transaction 들이 동시에 실행될 때 각 Transaction에 속한 Operation의 실행 순서
- 각 트랜잭션 내의 Operation의 순서는 변경되지 않는다.

위 그림처럼 T1,T2가 주어졌을 때, 위 그림 아래처럼 T1,T2의 Operation를 구성할 수 있다.

Operation의 실행 순서에 따라 다양한 Schedule이 만들어질 수 있고, 그에 따른 결과도 달라진다.
Serial Schedule
Schedule 1,2와 같이 Transaction들이 겹치지 않고 한 번에 하나씩 실행되는 Schedule
트랜잭션을 병행수행하는 것이 아니다.
- 장점: 정확한 결과를 기대할 수 있다.
- 단점: 한 번에 하나의 Transaction만 실행되기 때문에 좋은 성능을 낼 수 없고 현실적으로 사용할 수 없는 방식
Non-serial Schedule
Schedule 3,4와 같이 Transaction들이 겹쳐서 실행되는 Schedule
- 장점: 여러 Transaction들이 겹쳐서 실행되기 때문에 동시성이 높아져서 같은 시간 동안 더 많은 트랜잭션들을 처리할 수 있다.
- 단점: 어떤 형태로 겹쳐서 실행되는지에 따라서 이상한 결과가 나올 수 있다.
Serializable Schedule
Conflict of two operations
세가지 조건을 모두 만족하면 두 Operation은 Conflict 하다고 할 수 있다.
- 서로 다른 Transaction 소속
- 같은 데이터에 접근
- 최소 하나의 Operation은 Write
Conflict Operation의 순서가 중요하다.
- 왜냐하면 Conflict Operation들의 순서가 바뀌면 결과도 바뀌기 때문이다.
- ex: r1(H)->w2(H) , w2(H)->r1(H)
Conflict equivalent for two schedules
두 조건을 만족하면 Conflict Equivalent 하다고 한다.
- 두 Schedule은 같은 Operations를 가진다.
- 어떤 Conflicting Operations의 순서도 양쪽 Schedule 모두 동일하다.
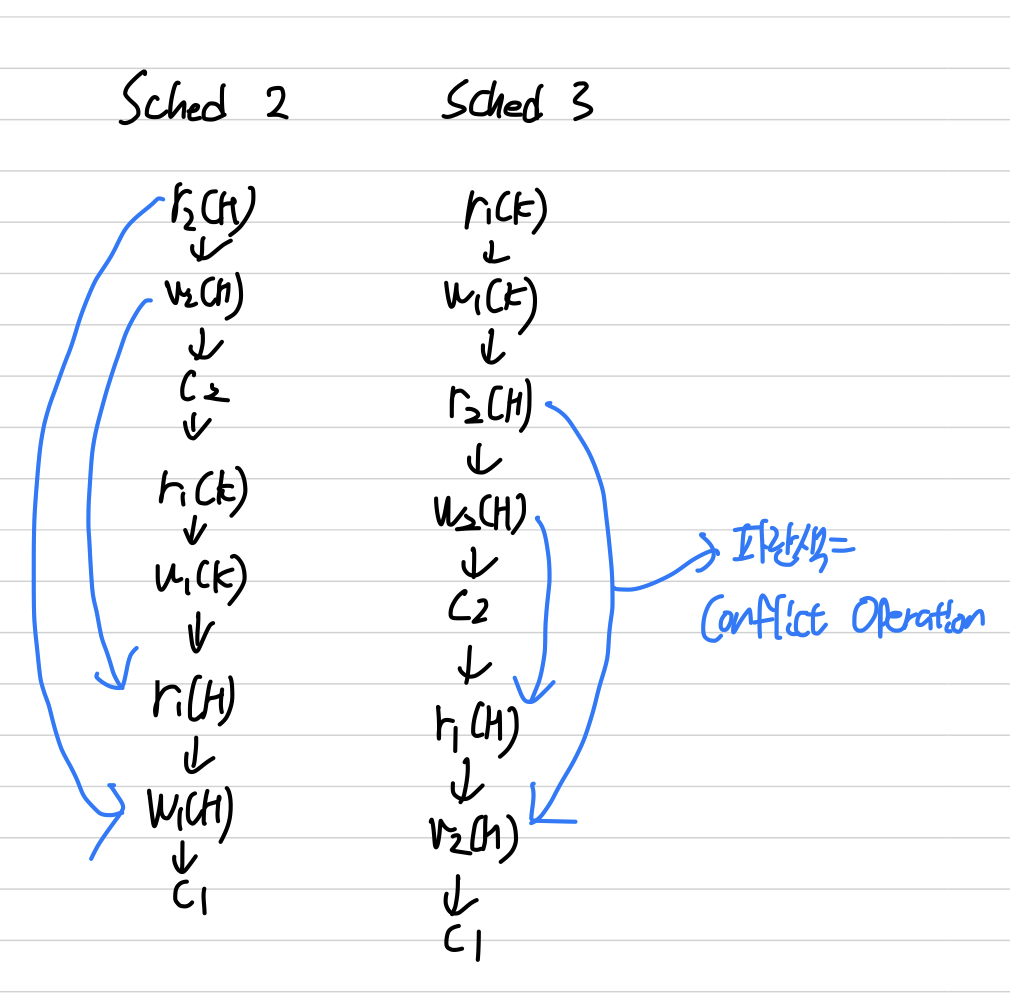
-
Sched.2 와 Sched.3 은 Conflict Equivalent 하다.
- Sched.2는 Serial Schedule이다.
-
Sched.3은 Non-serial Schedule이지만, Serial Schedule과 Conflict Equivalent 하다.
-
Sched.3은 Conflict Serializable 하다.
- Sched.3은 Non-serial Schedule이지만 정상적인 결과를 보장한다.
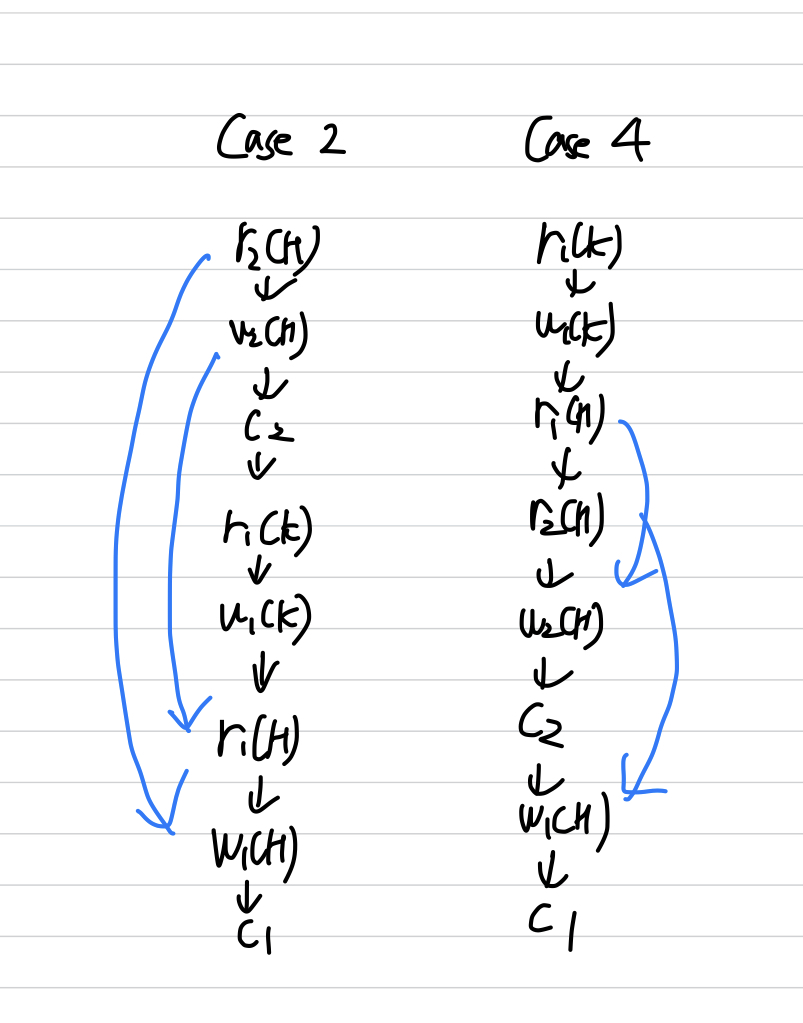
-
Operations는 같지만, Conflict Operations의 순서가 다르다.
-
같은 Operations일지라도, 결과가 달라진다.
- 성능 때문에 Serial Schedule 대신 Non-serial Schedule을 실행해야 한다.
- 하지만, 결과는 의도대로 동작해야 한다.
- Non-serial Schedule을 사용하는 대신, Conflict Serializable한 Non-serial Schedule을 사용하면 의도대로 결과를 얻을 수 있다.
- 모든 트랜잭션마다 Conflict Serializable을 확인하기에는 비용이 크다.
- 여러 트랜잭션을 동시에 실행해도 Schedule이 Conflict Serializable 하도록 프로토콜을 적용해야 한다.
Unrecoverable Schedule
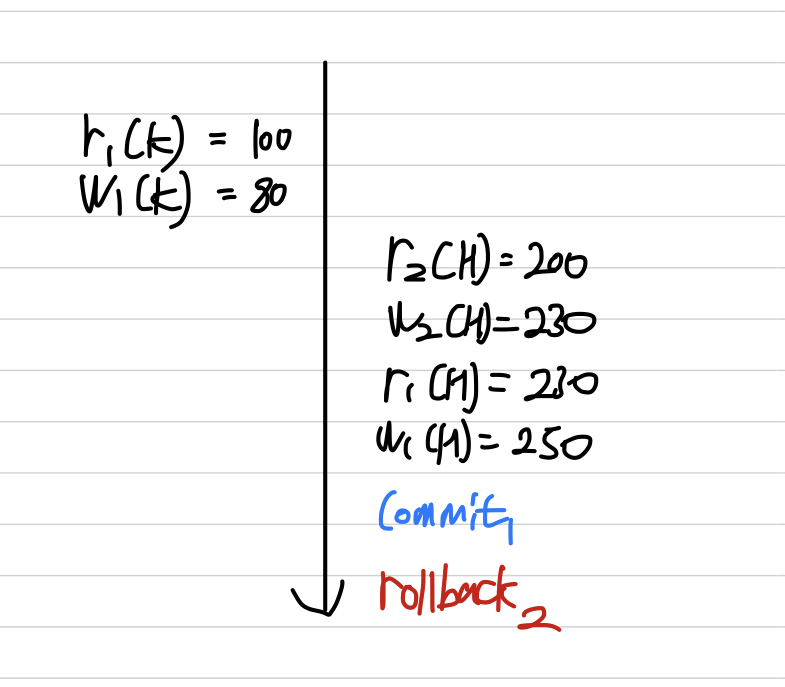
- Schedule 내에서 Commit 된 트랜잭션이 Rollback된 트랜잭션이 Write 했었던 데이터를 읽은 경우
- Durability 속성 때문에 커밋된 트랜잭션은 되돌릴 수 없다.
- Rollback을 해도 회복불가능할 수 있기 때문에 이런 Schedule은 DBMS가 허용하면 안된다.
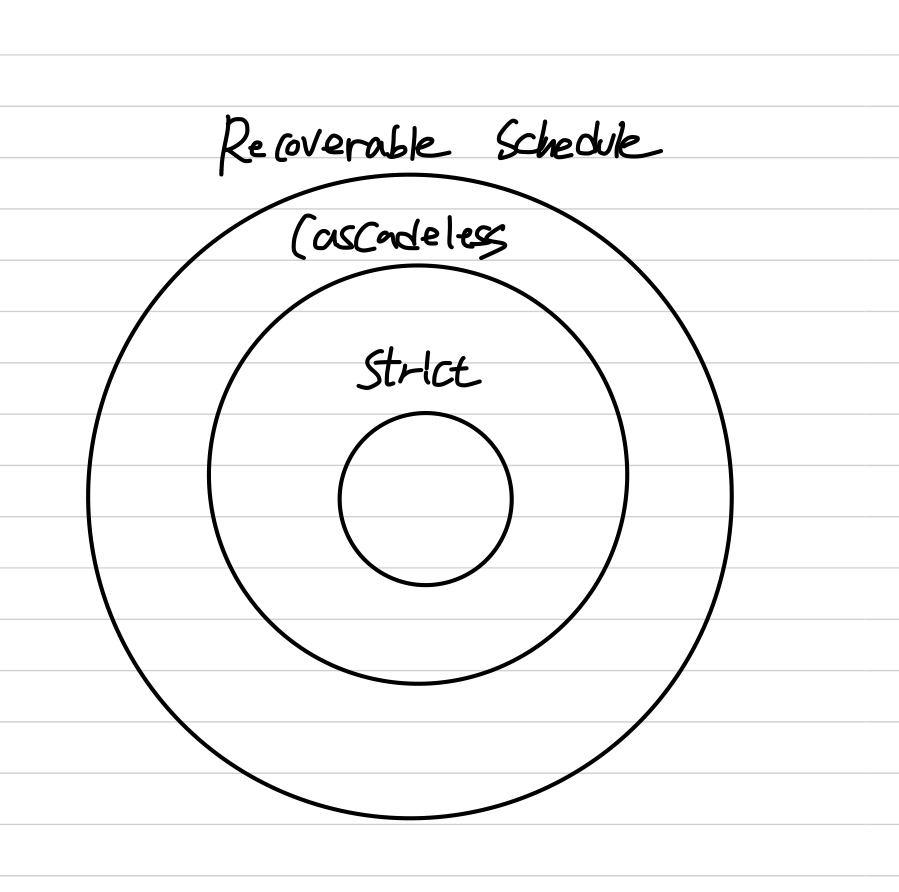
Recoverable Schedule
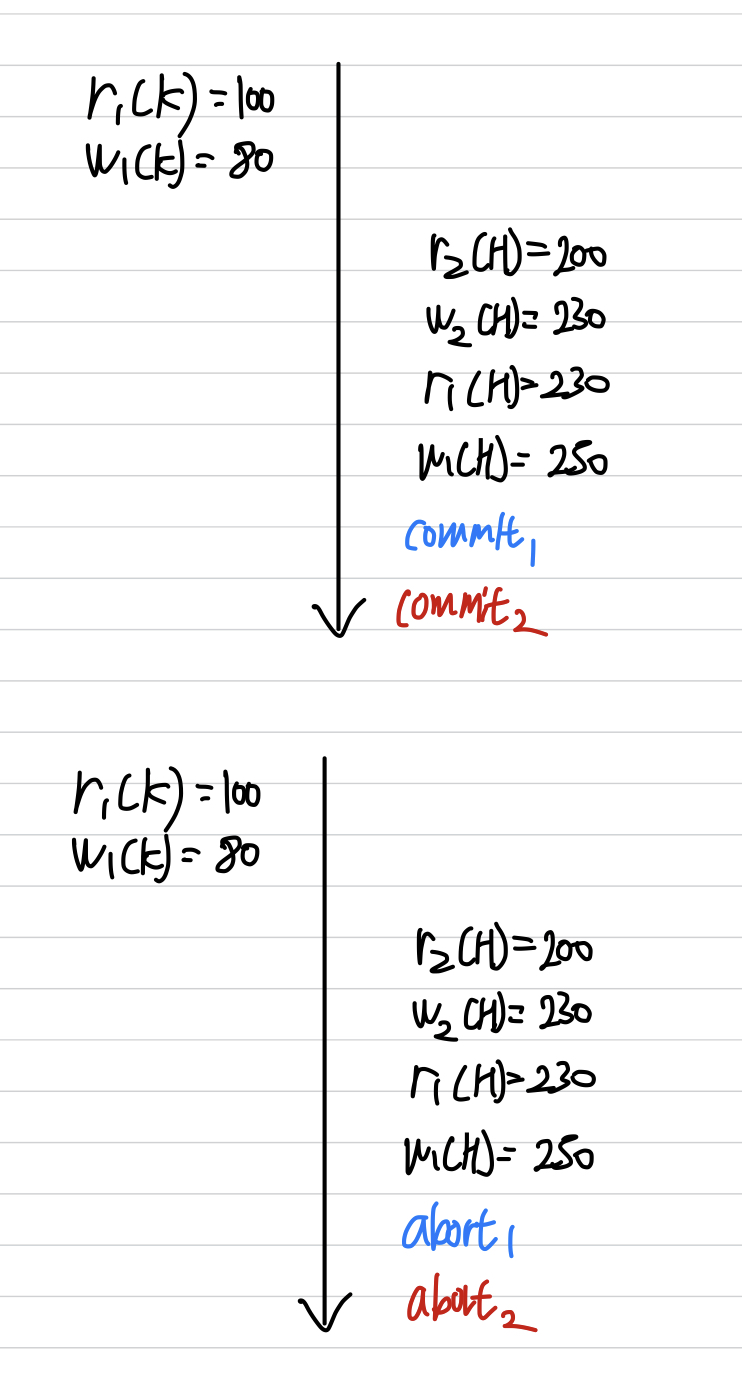
- Schedule 내에서 그 어떤 트랜잭션도 자신이 읽은 데이터를 Write한 트랜잭션이 먼저 Commit/Rollback 하기 전까지는 Commit 하지 않는 Schedule
- Rollback 할 때, 이전상태로 온전히 돌아갈 수 있기 때문에 DBMS는 이런 Schedule만 허용해야 한다.
Cascading Rollback
- 하나의 트랜잭션이 Rollback을 하면 의존성이 있는 다른 트랜잭션도 Rollback
- 여러 트랜잭션의 롤백이 연쇄적으로 발생하면 처리비용이 많이 든다.
Cascadeless Schedule
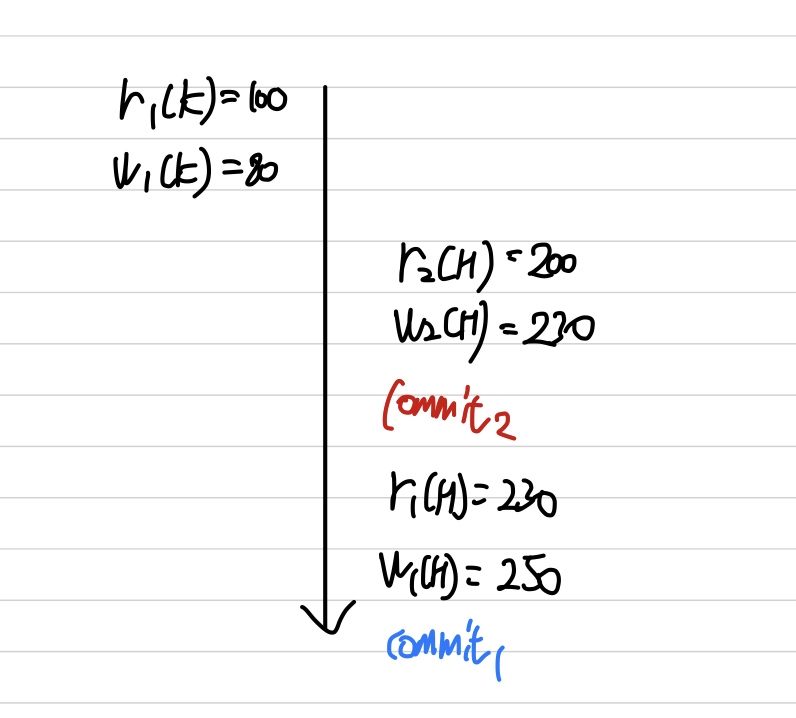
-
데이터를 Write한 트랜잭션이 Commit/Rollback 한 뒤에 데이터를 읽는 Schedule
-
Schedule 내에서 어떤 트랜잭션도 커밋되지 않는 트랜잭션이 Write한 데이터는 읽지 않는 Schedule
Strict Schedule

- 커밋되지 않은 트랜잭션이 Write한 데이터는 쓰지도 읽지도 않는 Schedule
- Schedule 내에서 어떤 트랜잭션도 커밋되지 않은 데이터는 읽지도 쓰지도 않는 Schedule
- Rollback 할 때 Recovery가 쉬움
- 트랜잭션 이전 상태로 돌려놓기만 하면 된다.
이상현상
Dirty Read

Commit 되지 않은 변화를 읽음
Non-repeatable Read(or Fuzzy read)

같은 데이터의 값이 달라지는 현상
Phantom Read

없던 데이터가 생기는 현상
Isolation Level
-
Dirty Read, Non-repeatable Read, Phantom Read 현상이 모두 발생하지 않게 만들수 있지만 그러면 제약사항이 많아져서 동시성이 떨어지게 되고, DB throughput이 떨어진다.
-
일부 이상현상은 허용하는 몇가지 Isolation Level을 만들어서 사용자가 필요에 따라서 적절하게 선택할 수 있도록 한다.
| 격리수준 | Dirty Read 허용 | Non-repeatable read 허용 | Phantom Read 허용 |
|---|---|---|---|
| Read Uncomitted | O | O | O |
| Read Committed | X | O | O |
| Repetable Read | X | X | O |
| Serializable | X | X | X |
MySQL8.0 기준 InnoDB의 default isolation level = Repeatable Read
이상현상 + α
Dirty Write

Commit 안된 데이터를 Write
Rollback 시 정상적인 Recovery는 매우 중요하기 때문에 모든 Isolation Level에서 Dirty Write를 허용하면 안된다.
Lost Update

업데이트를 덮어씀
Dirty Read 확장

트랜잭션이 Rollback되지 않아도 Dirty Read가 될 수 있는 예
Read Skew

Inconsistent 한 데이터 읽기
Write Skew

Inconsistent 한 데이터 쓰기
Phantom Read 확장

같은 데이터를 읽지 않아도 서로 연관된 데이터가 있는 경우에 없던 데이터가 생긴 경우
Snapshot Isolation
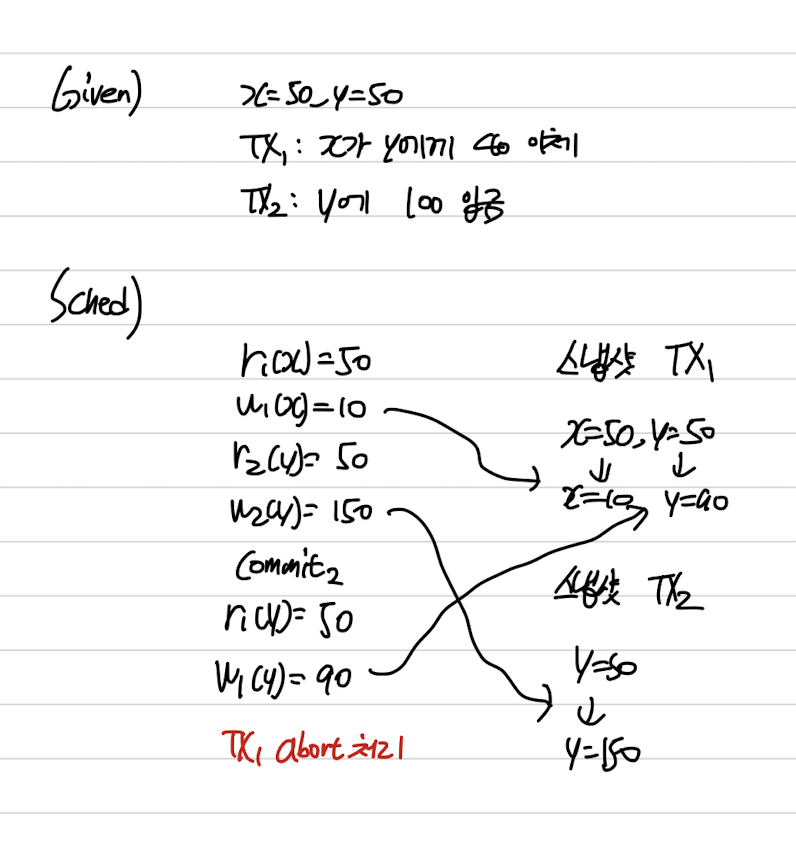
- Snapshot Isolation = Type of MVCC
- 트랜잭션 시작 전 Commit 된 데이터만 보임
- First-Commiter Win 방식
