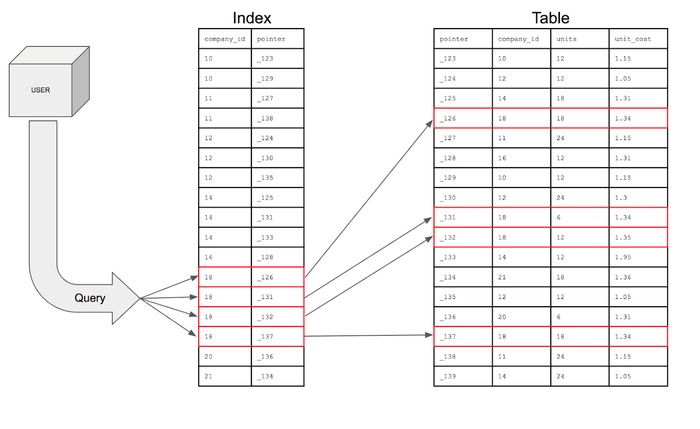
인덱스
✔️ 인덱스가 없다면?
SELECT *
FROM customer
WHERE first_name = 'minsoo';customer 테이블에 튜플이 100만개 있고, first_name = 'minsoo'에 index가 걸려있지 않다면
- full Scan(= table scan)으로 찾아야 한다
- O(N)
✔️ Index 사용 이유
- 조건을 만족하는 튜플을 빠르게 조회하기 위해
- 빠르게 정렬(
order by)하거나 그루핑(group by) 하기 위해
✔️ 인덱스 장점
- Full Scan보다 더 빨리 찾을 수 있다.
- B-tree 계열 인덱스라면 log(N)에 찾을 수 있다.
✔️ 인덱스 단점
- table에 write 할 때마다 index도 함께 변경해야 한다
- B-tree 조정 시간 발생
- index가 많아질수록 오버헤드가 커짐
- 추가적인 저장 공간 차지
불필요한 인덱스를 만들지 말자
✔️ 그 외
- foreign key에는 index가 자동으로 생성되지 않을 수 있다.
인덱스 문법
player 테이블
id(primary key) | name | team_id | backnumber
✔️ 이미 만들어진 테이블에서 인덱스 생성
중복가능한 컬럼에 대해서
CREATE INDEX player_name_idx ON player(name);Unique한 컬럼에 대해서
CREATE UNIQUE INDEX team_id_backnumber_idx ON player(team_id,backnumber);✔️ 테이블 생성할 때 index 생성
CREATE TABLE(
id INT primary key,
name varchar(20) NOT NULL,
team_id INT,
backnumber INT,
INDEX player_name_idx(name),
UNIQUE INDEX team_id_backnumber_idx(team_id,backnumber);
)- 기본키와 유니크키는 생성시 index가 자동 생성됨
✔️ 인덱스 확인
SHOW INDEX
FROM player;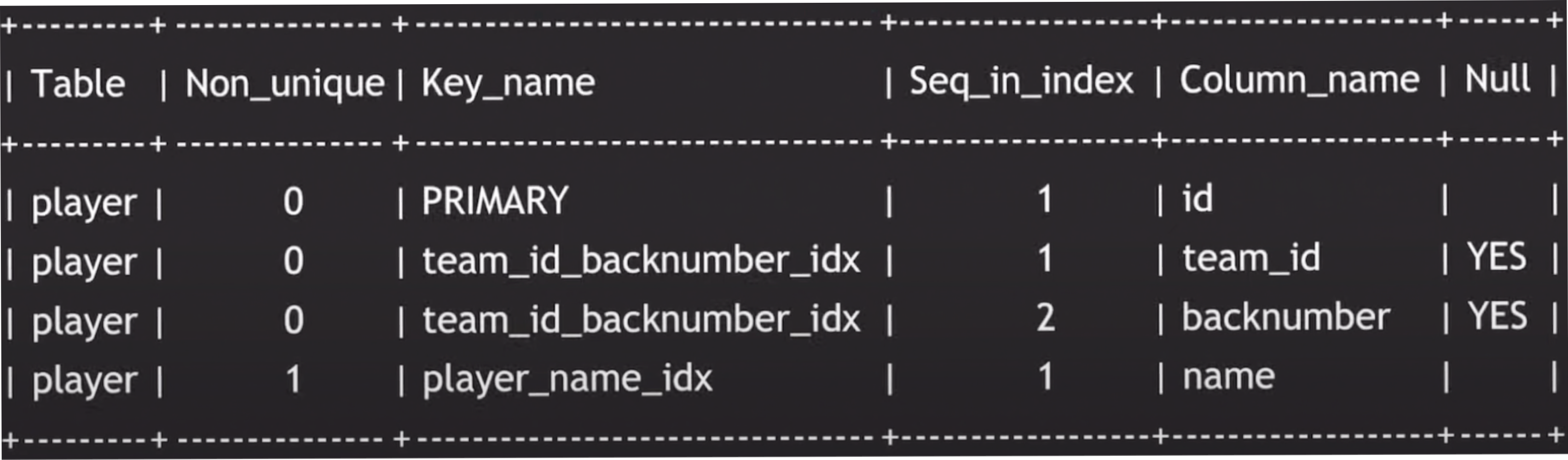
✔️ 인덱스 사용 확인
EXPLAIN
SELECT *
FROM player
WHERE backnumber = 7;
possible_keys: 사용할 수 있는 인덱스key: 사용한 인덱스
Optimizer가 알아서 적절하게 index를 선택한다
✔️ 인덱스 명시
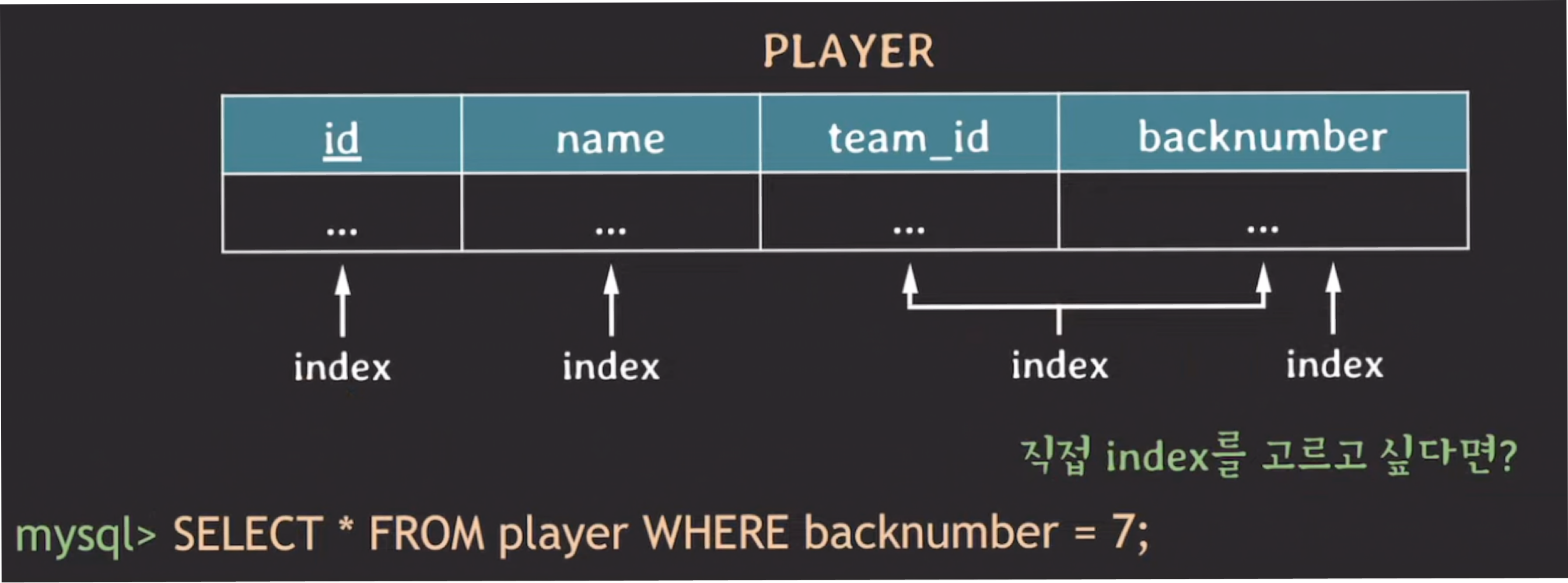
USE INDEX
SELECT *
FROM player
USE INDEX(backnumber_idx)
WHERE backnumber = 7;Optimizer가 명시한 인덱스를 사용하지 않으면 full_scan으로 동작한다.
FORCE INDEX
SELECT *
FROM player
FORCE INDEX(backnumber_idx)
WHERE backnumber = 7;인덱스 예제
1. team_id_backnumber_idx 사용
SELECT *
FROM player
WHERE team_id = 110;2. team_id_backnumber_idx 사용
SELECT *
FROM player
WHERE team_id = 110 AND backnumber = 7;3. full scan
SELECT *
FROM player
WHERE backnumber= 7 ;4. full scan
SELECT *
FROM player
WHERE team_id = 110 or backnumber = 7;사용하는 쿼리에 맞춰서 적절하게 index를 걸어줘야 query가 빠르게 처리될 수 있다.
인덱스 주의점
✔️ Multi column 인덱스 주의점
B-tree 기준으로 인덱스를 생성할 때 왼쪽을 기준으로 우선순위가 형성되고, 우선순위에 따라 정렬된다.
아래 예시에서 team_id 순으로 정렬되고, team_id가 동일할 경우 backnumber 순으로 정렬된다
CREATE UNIQUE INDEX team_id_backnumber_idx ON player(team_id,backnumber);✔️ 튜플이 많은 테이블에 인덱스 생성
이미 데이터가 몇백만건 이상 있는 테이블에 인덱스를 생성하는 경우 시간이 몇 분이상 소요될 수 있고 DB 성능에 안좋은 영향을 줄 수 있다.
B-tree 계열 인덱스 사용 이유
✔️ DB 성능 이슈
- DB는 Second Storage에 저장되어 있기 때문에 데이터를 조회할 때 Second Storage에 최대한 적게 접근하는 것이 좋다
- Block 단위로 데이터를 읽고 쓰기 때문에 연관된 데이터를 모아서 저장하면 더 효율적으로 관리할 수 있다.
✔️ B-tree 사용 이유
- B tree index는 self-balancing BST에 비해 second storage 접근을 적게한다
- B tree 는 block 단위의 저장 공간을 알차게 사용할 수 있다.
Covering Index
SELECT team_id, backnumber
FROM player
WHERE team_id = 5;조회하는 attribute들을 모두 index가 cover할 때 조회성능이 더 빠름
Full scan
조회하려는 데이터가 테이블의 상당 부분을 차지하거나, 테이블에 데이터가 조금 있는 경우 인덱스를 사용하는 것과 성능 차이가 작다.
Full scan 사용 여부는 Optimizer가 결정
Hash Index
✔️ 장점
- Hash Table 사용 -> 조회 O(1)
✔️ 단점
- rehashing
- equality 비교만 가능
- range 비교 불가능
- 정렬 불가능
- multi column index일 경우, 전체 attribute에 대한 조회만 가능
