SQL
1.[탐구] 다중정렬이란?
SQL에서 ORDER BY 구문을 사용한 다중 정렬이란, 결과를 정렬할 때 여러 개의 기준(컬럼)을 순서대로 적용할 수 있다는 의미입니다.즉, 하나의 ORDER BY 구문에서 여러 정렬 조건을 나열하면, SQL은 왼쪽부터 오른쪽으로 순차적으로 정렬을 수행합니다.먼저 U
2.[SQL 오류] [컬럼A] is not a valid group by expression
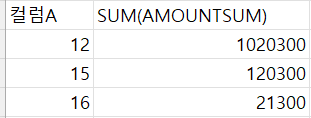
이 오류는 SELECT 절에서 집계 함수(SUM)를 사용한 컬럼과 그렇지 않은 컬럼(컬럼A)이 동시에 존재할 때, GROUP BY 절이 필요함을 의미합니다.=> SELECT절은 집계 함수가 필요한 컬럼들과 그렇지 않은 컬럼들 함께 쓸 수 없음! SUM(AMOUNTSUM
3.[탐구] GROUP BY할 때 왜 SELECT에는 집계함수가 필요할까?
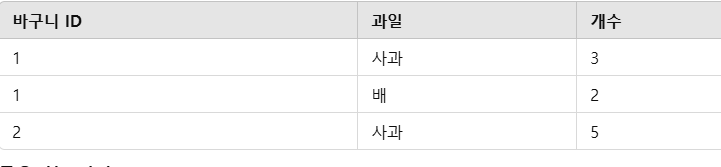
묶은 데이터를 처리하려면 반드시 SUM, COUNT 같은 집계 방식으로 계산해야 한다.묶은 데이터(그룹화한 데이터)만 결과로 보여줄 수 있으며, 묶이지 않은 데이터는 사용할 수 없다.예를 들어 보자,할머니, 마트에서 과일을 산다고 생각해보세요. 지금 손에 이렇게 적혀
4.[SQL 기초] TIMESTAMP/DATE_ADD()/DATEADD()
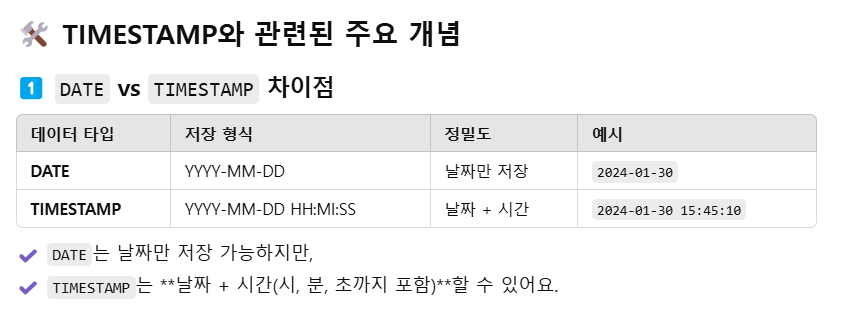
✅ TIMESTAMP는 SQL에서 날짜와 시간을 저장하는 데이터 타입입니다.✅ 년-월-일 시:분:초 형식으로 데이터를 저장하며, DATE보다 더 정밀하게 시간 정보를 저장할 수 있습니다.✅ 대부분의 데이터베이스(MySQL, PostgreSQL, Oracle, SQL S
5.[CASE] 종류/ END AS

→ 여기서는 G.GRADE가 'S', 'A', 'B' 중 어떤 값이냐에 따라 보너스를 계산END AS 컬럼명 → 별칭(alias)안 써도 작동은 하지만, 쓰는 게 실무에서 기본왜냐하면:1.SELECT절에 표현식으로 나오는 값에 이름을 붙이지 않으면, 결과 테이블에 컬럼
6.[서브쿼리, 윈도우함수,CTE 함수 연습] 보호 기간이 가장 긴 동물 찾기

ANIMAL_INS와 ANIMAL_OUTS 테이블을 사용하여, 동물 보호소에 가장 오래 있었던 동물의 ID, 이름, 보호 기간을 구하는 SQL문을 작성하세요. 단, 보호 기간은 ANIMAL_OUTS.DATETIME - ANIMAL_INS.DATETIME 으로 계산합니다
7.Windows 함수 연습
💡 문제: 가장 최근 주문 가져오기테이블명: ordersorder_id (int) – 주문 고유 IDuser_id (int) – 사용자 IDorder_date (date) – 주문일amount (int) – 주문 금액✏️ 예시 출력user_id order_id ord
8.snowflake 오류 - 'HH:MM:SS'
SQL 문법 오류가 발생한 이유는 DATEADD와 CAST(GETDATE() AS DATE)를 잘못 사용했기 때문입니다. Snowflake에서는 CAST(GETDATE() AS DATE)를 사용할 필요 없이 CURRENT_DATE를 사용하면 됩니다. 또한, + 'HH:
9.서브쿼리 VS WITH
네! 완벽한 이해입니다! 😊👏📌 서브쿼리 vs. WITH(CTE) 개념 정리💡 서브쿼리:쿼리의 마지막에 AS 별칭을 붙여야 바깥에서 사용할 수 있음.보통 ()로 감싸서 사용함.한 번만 실행되고, 여러 번 사용하려면 중복 작성해야 함.💡 WITH (CTE):이름
10.UNION(ALL) 합칠 때 컬럼명이 달라도 가능할까?
가능하다.2️⃣ USER_ID 값이 달라도 UNION ALL이 되나?👉 UNION ALL은 "컬럼 개수 & 데이터 타입"만 맞으면 된다!UNION은 중복 제거, UNION ALL은 중복 제거 XUSER_ID가 온라인에선 숫자(INT), 오프라인에선 NULL인데 둘 다
11.[SELECT 별칭] 서브쿼리 쓰기 vs 안쓰기
이유 ✅UNION ALL을 하면 컬럼명이 첫 번째 SELECT 절을 기준으로 결정됨즉, DATE_FORMAT(SALES_DATE, '%Y-%m-%d') AS SALES_DATE를 한쪽에서만 적용하면 다른 테이블과 UNION ALL할 때 데이터 타입이 맞지 않을 수 있음
12.UNION ALL - 결과 집합(Result Set)이 하나로 되고, 개별 테이블 별칭 사라짐
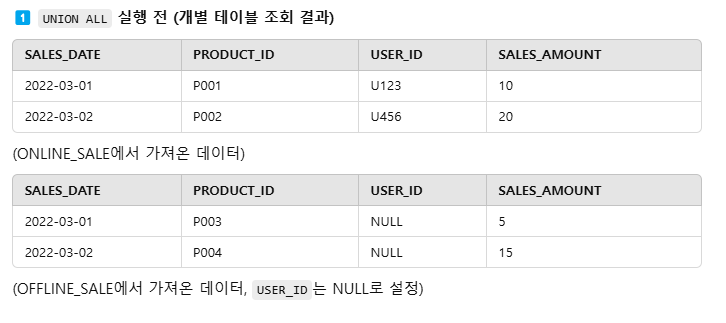
두 테이블이 합쳐져서 하나의 결과 집합이 됨각 컬럼에는 ONS. 또는 OFS. 같은 별칭이 없어짐✅ UNION ALL을 사용하면 두 테이블에서 가져온 데이터를 하나의 테이블처럼 다룰 수 있음.✅ ORDER BY에서 ONS. 또는 OFS. 같은 테이블 별칭을 사용할 수
13.SELECT문, UNION 실행 순서의 관계
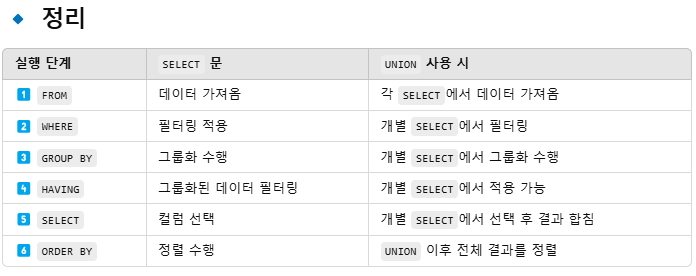
일반적인 SELECT 쿼리는 다음 순서로 실행(실행되는 순서지, 작성하는 순서는 아님!)🔹 실행 순서1️⃣ FROM → 데이터를 가져올 테이블 지정2️⃣ WHERE → 조건에 맞는 데이터 필터링3️⃣ GROUP BY → 같은 값끼리 그룹화4️⃣ HAVING → 그룹화
14.NULL AS (cf. 'NULL' AS)

📌 핵심 개념:NULL AS 컬럼명에서는 컬럼명에 테이블 별칭(OFS, ONS)을 붙일 수 없음.UNION이 실행되기 전이라서가 아니라, 기본적으로 AS 뒤에는 테이블 별칭이 올 수 없기 때문.👉 올바른 이유:✅ NULL AS USER_ID → USER_ID라는 이
15.CASE 안에 CASE 트릭
CASE 안에 CASE를 써야 하는 이유는"어떤 조건을 '하나하나에 대해 검사'한 다음, 그것들을 모아서 최종 판단하려고 할 때""일단 각 줄에 대해 조건 판단하고""그 판단 결과들로 '모아서' (집계해서) 결론 내고 싶을 때"각 row에 대해 어떤 조건을 검사해서 1
16.CASE문에서 ELSE 생략 - CASE 가 COUNT, SUM 같은 집계 함수 안에 있을 때

이때 ELSE 생략해도 → 자동으로 ELSE NULL처럼 동작함COUNT는 NULL을 세지 않기 때문에 조건에 맞는 row만 카운트됨SUM도 NULL은 0처럼 무시됨
17.SELECT 1 패턴 / (NOT) EXISTS 패턴

d
18.EXISTS / NOT EXISTS (2)
즉, "해당 테이블에 그런 기록이 있냐 없냐만 본다."서브쿼리 안에 SELECT 1을 쓰는 이유도, 실제로 뭘 가져오는 게 아니라 "있냐/없냐"만 따지기 때문"A가 한 적이 있는지 확인해라"→ "이 사람이 뭘 했는지 기록이 있으면 포함시켜!"해석"수강신청 기록이 하나라
19.WHERE 는 질문을 던지는 것 (bool표현, o/x)

\~~조건에 대해서 true/false 이니?위의 물음을 더 풍부하게 물어보기 위해 조건을 더하는 것