CNN 구조
- 일반 신경망처럼 여러 층을 차례대로 거치며 복잡한 특징을 학습한다.
- (모서리, 직선) -> (원, 정사각형) -> (이미지의 일부)등을 학습한다.
- 가중치는 무작위 값으로 초기화 되며 활성화 함수를 사용한다.
- 오차를 역전파하며 가중치를 수정해 나아간다.
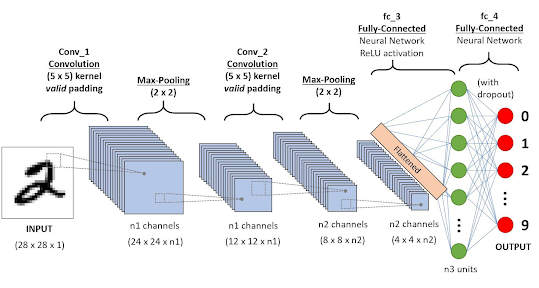
전체 학습 과정
- 데이터 입력 - 이미지를 합성곱층에 입력한다.
- 전처리 - 합성곱층을 지나며 특징 맵을 추출한다. 이미지의 크기가 각 층을 지날 때마다 줄어들고 특징 맵 수는 늘어난다.
- 특징 추출 - 전결합층에 입력되어 이미지를 분류한다.
- 머신러닝 모델 - 결과를 출력한다.
합성곱층
합성곱
- 두 함수를 인수로 새로운 함수를 만들어내느 연산이다.
- 합성곱 필터를 입력 이미지 위로 이동시키며 합성곱 필터가 위치한 부분에 해당하는 작은 이미지 조각을 처리한 결과를 모아서 새로운 이미지 특징 맵을 만든다.
- 특징을 유지하면서 이미지의 해상도를 떨어뜨리느 것이다.
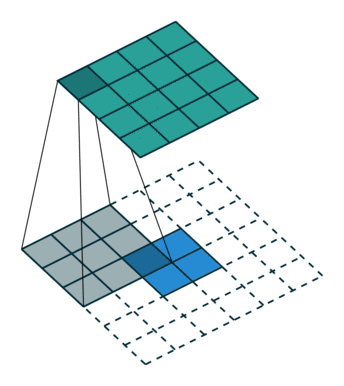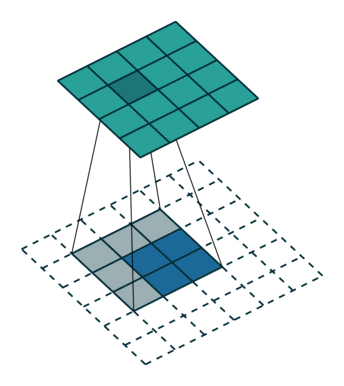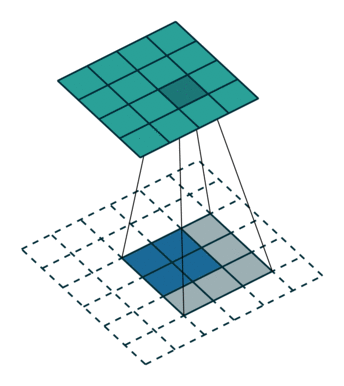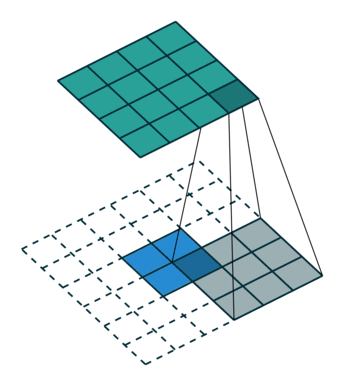
폴링층
- 합성곱층 수를 늘리면 출령층의 깊이가 깊어지는 만큼 학습해야 할 파라미터 수가 늘어난다.
- 이런 식으로 신경망의 규모가 커지면 학습에 필요한 계산 복잡도가 상승하고 학습 시간도 오래 걸린다.
- 폴링은 다음 층으로 전달되는 파라미터 수를 감소시키는 방법으로 신경망의 크기를 줄인다.
최대 폴링 최소 폴링
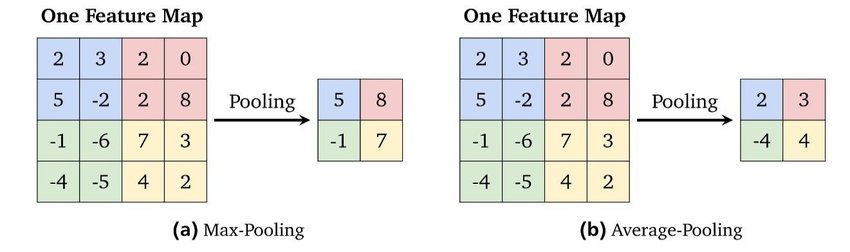
이미지 분류
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
# build the model object
model = Sequential()
# CONV_1: add CONV layer with RELU activation and depth = 32 kernels
model.add(Conv2D(32, kernel_size=(3, 3), padding='same',activation='relu',input_shape=(28,28,1)))
# POOL_1: downsample the image to choose the best features
model.add(MaxPooling2D(pool_size=(2, 2)))
# CONV_2: here we increase the depth to 64
model.add(Conv2D(64, (3, 3),padding='same', activation='relu'))
# POOL_2: more downsampling
model.add(MaxPooling2D(pool_size=(2, 2)))
# flatten since too many dimensions, we only want a classification output
model.add(Flatten())
# FC_1: fully connected to get all relevant data
model.add(Dense(64, activation='relu'))
# FC_2: output a softmax to squash the matrix into output probabilities for the 10 classes
model.add(Dense(10, activation='softmax'))
model.summary()
# model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 28, 28, 32) 320
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 14, 14, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 14, 14, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 7, 7, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 3136) 0
_________________________________________________________________
dense_1 (Dense) (None, 64) 200768
_________________________________________________________________
dense_2 (Dense) (None, 10) 650
=================================================================
Total params: 220,234
Trainable params: 220,234
Non-trainable params: 0
_________________________________________________________________https://github.com/moelgendy/deep_learning_for_vision_systems/blob/master/chapter_03/mnist_cnn.ipynb
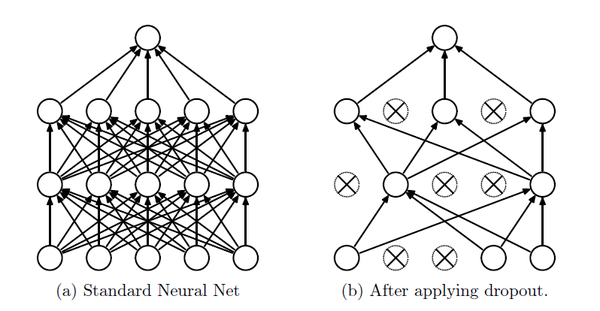
드롭 아웃
- 과적합을 방지하기 위한 수단 중 가장 널리 쓰인다.
- 노드의 일정 비율을 비활성화하여 순방향 또는 역전파 계산에 참여하지 않는다.
- 뉴런 간에 발생하는 상호 의존 관계도 완화시킬 수 있다.
- 경험적으로 전결합층에 적용하는 것이 좋다.
[참고자료]
https://www.hanbit.co.kr/store/books/look.php?p_code=B6566099029
https://sonsnotation.blogspot.com/2020/11/7-convolutional-neural-networkcnn.html
https://docs.nestjs.com/guards
https://datascience.stackexchange.com/questions/6107/what-are-deconvolutional-layers
