Java ParallelStream


Java ParallelStream
Stream API의 기능중 하나로 병렬 처리를 쉽게 구현할 수 있게 해준다.
ParallelStream을 사용하면 멀티코어 CPU 환경에서 여러 스레드를 활용하여 데이터를 병렬로 처리
내부 적으로 ForkJoinPool을 사용하여 작업을 분할하고 실행 결과를 합치는 방식
Single Core, Multi Core

출처 : https://www.donga.com/news/It/article/all/20161018/80845621/1
-
Single Core : 멀티태스킹을 할 수 없기 때문에, 여러 작업을 처리할 때는 작업 간의 전환(context switching)을 통해 순차적으로 작업을 처리
-
Multi Core : 각 코어가 독립적인 작업을 수행할 수 있기 때문에 여러 작업을 동시에 처리가 가능하고 이를 통해 병렬 처리 수행
ForkJoinPool
멀티코어 프로레서에서 여러 작업을 병렬로 처리하는게 유리하게 설계된 스레드풀
분할-정복(Divide and Conquer): 작업을 작은 단위로 분할하여 각 작업을 병렬로 처리하고, 처리된 결과를 다시 결합하는 방식입니다.

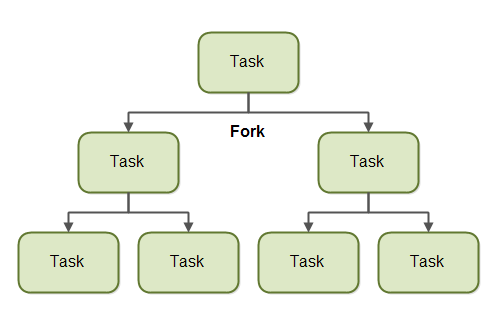
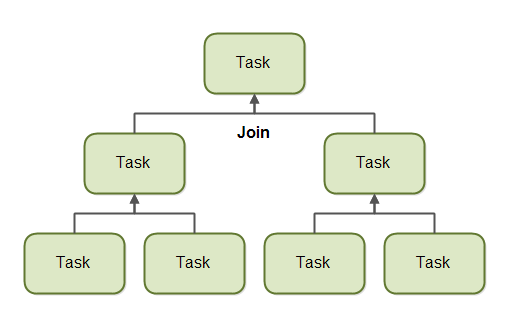
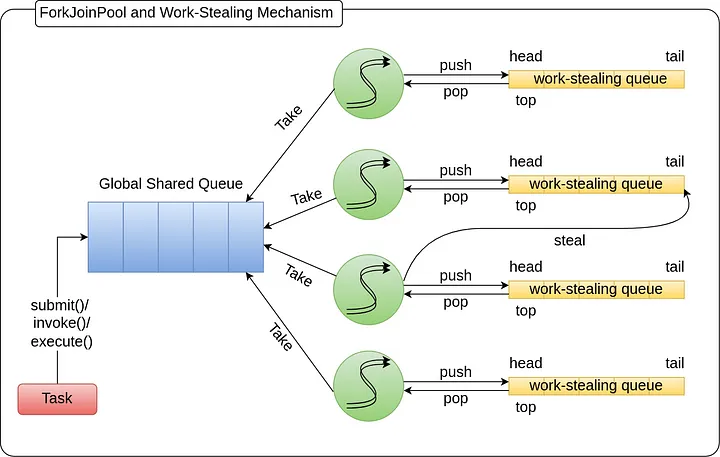
워크 스틸링 (Work Stealing)
- 자신의 작업 큐에 작업이 없을 때, 다른 스레드의 큐에서 작업을 가져오는 방식
- Idle 상태인 스레드는 다른 스레드의 작업을 가져와서 작업을 처리
- 스레드 자신의 task queue로 deque를 사용한다. deque는 양 쪽 끝으로 넣고 뺄 수 있는 구조이며,각 스레드는 deque의 한쪽 끝에서만 작업하고 나머지 반대쪽에서는 task를 가지러온 다른 스레드가 접근

한 쪽은 가니쉬를 만들고 나머지 다른 쪽은 청소하는 모습
ParallelStream 코드
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
System.out.println("Stream 처리");
list.stream()
.map(num -> num * 2)
.forEach(num -> System.out.print(num + " "));
System.out.println();
System.out.println("ParallelStream 처리");
list.parallelStream()
.map(num -> num * 2)
.forEach(num -> System.out.print(num + " "));
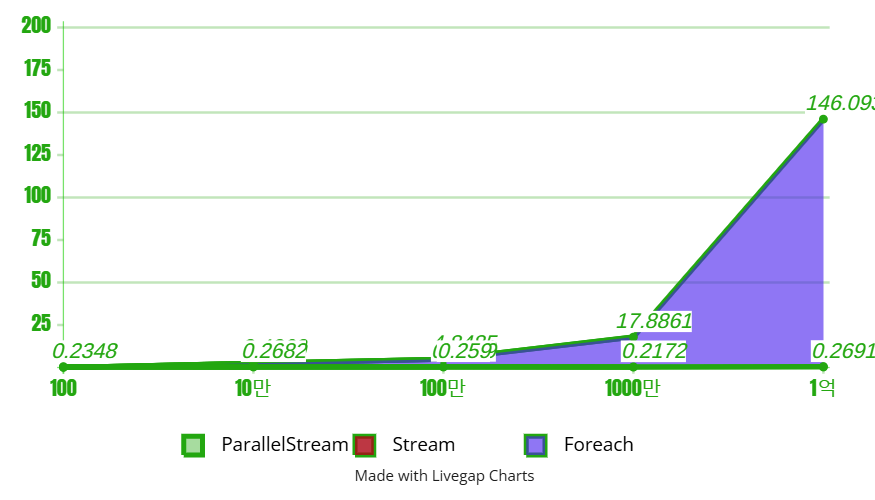
Foreach, Stream, ParallelStream 비교
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 100_000_000; i++) {
list.add(i);
}
// for-each
int sum = 1;
long startTime = System.nanoTime();
for (Integer num : list) {
sum = num * 2;
}
long endTime = System.nanoTime();
double elapsedTimeForEach = (endTime - startTime) / 1_000_000.0;
System.out.println("for-each 처리 시간: " + elapsedTimeForEach + " ms");
// Stream (순차 스트림)
startTime = System.nanoTime();
list.stream()
.map(num -> num * 2)
.count();
endTime = System.nanoTime();
double elapsedTimeStream = (endTime - startTime) / 1_000_000.0;
System.out.println("Stream 처리 시간: " + elapsedTimeStream + " ms");
// ParallelStream
startTime = System.nanoTime();
list.parallelStream()
.map(num -> num * 2) // 값을 2배로 변환
.count();
endTime = System.nanoTime();
double elapsedTimeParallelStream = (endTime - startTime) / 1_000_000.0; // 나노초를 초로 변환
System.out.println("ParallelStream 처리 시간: " + elapsedTimeParallelStream + " ms");
}100건

10만건

100만건

1000만건

1억건

비교 차트
ParallelStream 장단점
멀티코어 시스템에서 작업을 여러 스레드로 분할하여 병렬로 처리함으로써 성능을 크게 향상시킬 수 있고 특히, 큰 데이터셋이나 복잡한 연산을 처리할 때 유용
스트림이 데이터를 자동으로 분할하고 병렬로 처리하는 방식이므로, 개발자는 병렬 처리에 대한 복잡한 코드 작성 없이 병렬화를 활용
작은 데이터셋에서는 병렬화하는 데 필요한 오버헤드(데이터 병합, 컨텍스트 스위칭)가 순차적으로 처리하는 것보다 더 많은 비용 발생
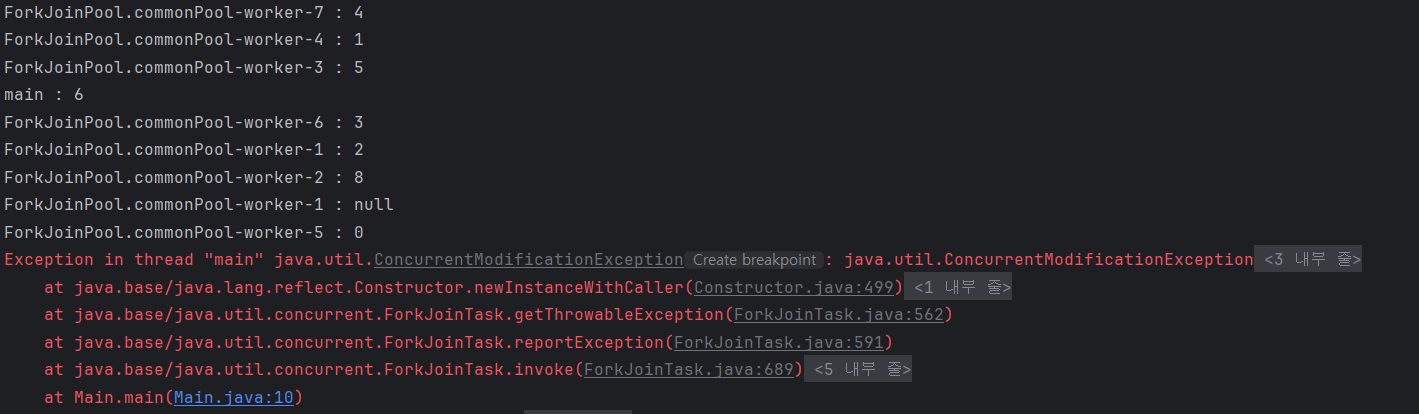
여러 스레드에서 동시에 데이터를 처리하므로, 스레드 안전한 연산을 사용해야함
병렬 스트림은 기본적으로 처리 순서를 보장하지 않으며 순서가 중요한 경우, forEachOrdered() 메서드를 사용하여 순서를 보장
리스트를 변경하는 작업이나, 외부 상태를 수정하는 작업에서는 문제가 발생
결론
ParallelStream을 써야할때는 CPU 집약적인 작업 또는 데이터가 많을수록 유리하지만
I/O 중심 작업에는 병렬 처리의 효과가 크지 않으며, 오히려 I/O가 대기 시간을 발생시키고 데이터를 여러 스레드에서 처리하기 때문에, 공유 데이터의 상태를 변경하는 작업이 포함된 경우 주의해서 사용해야 한다.

참고자료 : https://jenkov.com/tutorials/java-util-concurrent/java-fork-and-join-forkjoinpool.html
https://dev-coco.tistory.com/183
이미지 : 넷플릭스 흑백요리사
