자바 튜닝
J2EE 패턴
- 엔터프라이즈 애플리케이션을 설계하고 개발하는 데 사용되는 자바 기반 기술
- 애플리케이션의 복잡성을 관리하고, 확장성, 유지보수성, 성능을 개선하는 데 도움
MVC 모델
- J2EE 패턴을 공부하려면 MVC 모델에 대해 먼저 이해를 해야한다.
- J2EE에는 MVC 구조가 기본적으로 깔려있고 Spring 프레임워크의 Spring MVC에도 적용된다.
- MVC는 Model, View, Controller의 각각의 역할을 분리해서 개발하는 모델
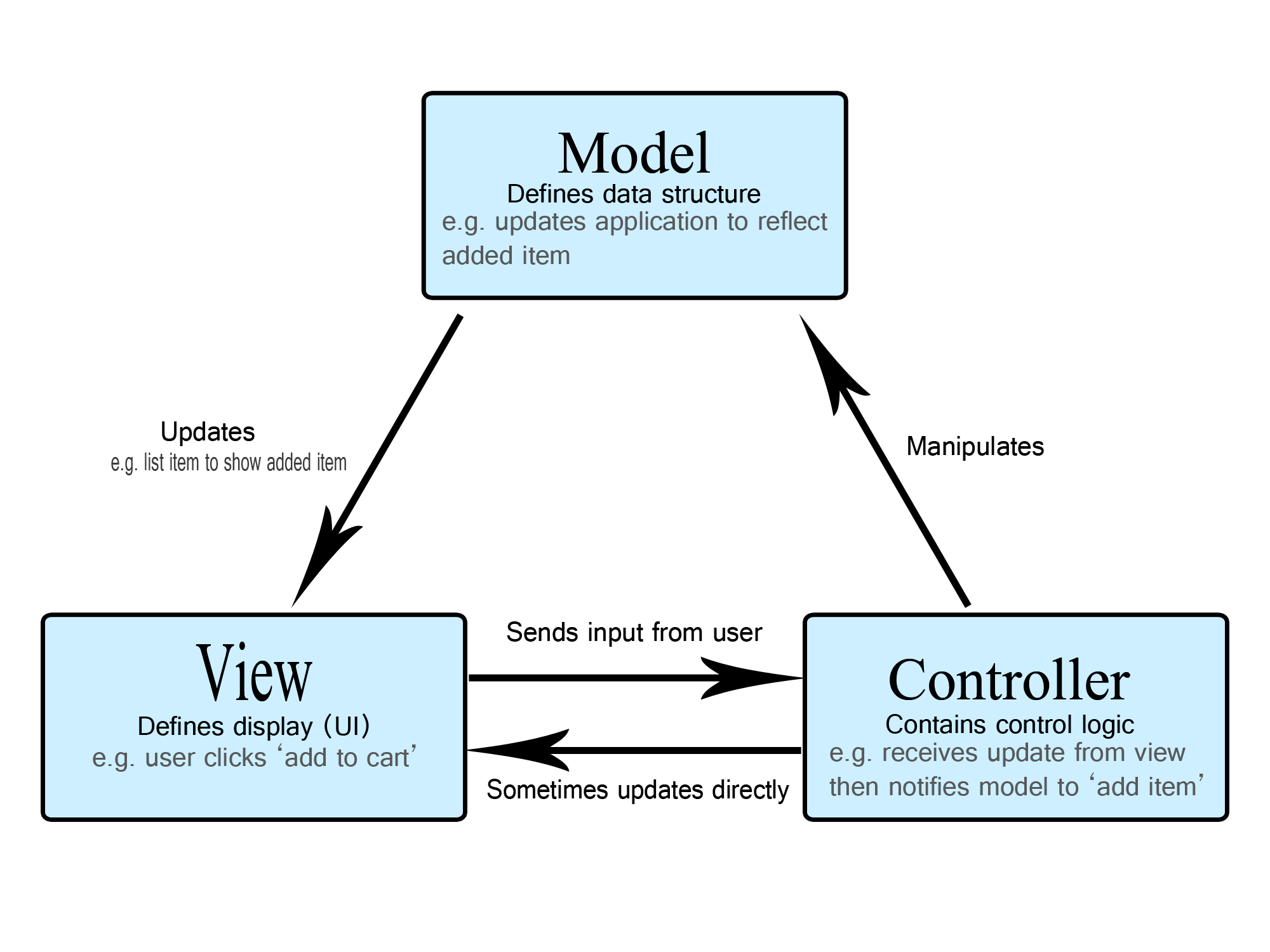
출처 : https://developer.mozilla.org/ko/docs/Glossary/MVC
J2EE 디자인 패턴
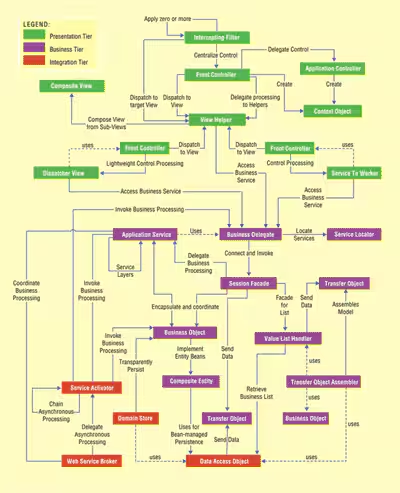
출처 : https://www.oracle.com/technical-resources/articles/javaee/j2ee-evolution.html
- 사용자의 요청이 처리되는 순서로 위에서 아래로 보면된다.
- 위에서 부터 프레젠테이션 티어, 비즈니스 티어, 인테그레이션 티어이다.
- 이중 가장 성능과 밀접한 패턴은 Service Locator 패턴
- 애플리케이션 개발 시 반드시 사용해야 하는 Transfer Object 패턴
Transfer Object 패턴
- Value Object라고도 불리며 데이터를 전송하기 위한 객체에 대한 패턴
- 주로 클라이언트와 서버 간의 데이터 전송에서 성능을 향상시키기 위해 사용
- 데이터 전송 시 네트워크 호출 횟수를 줄이고, 불필요한 오버헤드를 최소화하는 데 도움
- toString() 메서드는 Class@A1B2C3 처럼 알 수 없는 값을 리턴하기에 반드시 구현하자
import java.io.Serializable;
public class CustomerTO implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private String address;
private int age;
// 생성자
public CustomerTO(String name, String address, int age) {
this.name = name;
this.address = address;
this.age = age;
}
// 게터 및 세터
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
// toString 메서드
@Override
public String toString() {
return "CustomerTO{" +
"name='" + name + '\'' +
", address='" + address + '\'' +
", age=" + age +
'}';
}
}Servicec Locator 패턴
- 예전에 많이 사용되었던 EJB의 EJB Home 객체나 DB의 DataSource를 찾을 때 소요되는 응답 속도를 감소시키기 위해서 사용
- 엔터프라이즈 애플리케이션에서 서비스 객체를 효율적으로 검색하고 제공
- 클라이언트와 서비스 간의 결합도를 줄여 서비스 구현을 변경해도 클라이언트 코드를 수정할 필요가 없다
public class ServiceLocator {
private static Cache cache;
static {
cache = new Cache();
}
public static Service getService() {
Service service = cache.getService();
if (service != null) {
return service;
}
InitialContext context = new InitialContext();
Service newService = (Service) context.lookup();
if (newService != null) {
cache.addService(newService);
}
return newService;
}
}프로그램 속도 비교
프로파일링 툴 vs APM 툴
| 비교 항목 | 프로파일링 툴 | APM 툴 |
|---|---|---|
| 목적 | 코드 수준에서 성능 문제 식별 | 애플리케이션 전체의 성능 모니터링 및 관리 |
| 데이터 수집 범위 | 특정 코드 영역에 집중 | 전체 애플리케이션 및 인프라스트럭처 |
| 수집 데이터 유형 | 메소드 호출, CPU 사용량, 메모리 사용량 등 | 응답 시간, 트랜잭션 속도, 에러율, 시스템 리소스 사용량 등 |
| 실시간 모니터링 | 제한적 | 실시간 모니터링 가능 |
| 오버헤드 | 상대적으로 높음 | 상대적으로 낮음 |
| 확장성 | 보통 소규모 애플리케이션에 적합 | 대규모 분산 시스템에도 적합 |
| 대표 툴 | VisualVM, YourKit, JProfiler | New Relic, AppDynamics, Dynatrace |
응답 시간 프로파일링
- 응답 시간을 측정하기 위함
- 하나의 클래스 내에서 사용되는 메서드 단위의 응답 시간을 측정
- 보통 CPU 시간과 대기 시간 제공
메모리 프로파일링
- 잠깐 사용하고 GC의 대상이 되는 부분을 찾거나, 메모리 릭이 발생하는 부분을 찾기 위함
- 클래스 및 메서드 단위의 메모리 사용량이 분석
System 클래스
- static으로 선언되어 있으며 생성자가 없다.
- 다음 메서드는 절대로 사용해서는 안된다.
- static void gc() : 메모리를 명시적으로 해제하도록 GC를 수행
- static void exit(int status) : 현재 수행중인 VM을 멈춤
- static void runFinalization() : GC가 알아서 해당 객체를 더 이상 참조할 필요가 없을때 호출하는데 해당 메소드를 호출하면 참조 해체 작업을 기다리는 모든 객체의 finalize() 메서드를 수동으로 수행해야 한다.
String 클래스
String vs StringBuffer vs StringBuilder
String
- 한 번 생성되면 변경할 수 없는 문자열 객체
- 불변이기 때문에 본질적으로 스레드 안전
- 문자열이 자주 변경되지 않을 때 사용
- 문자열을 변경할 때마다 새로운 객체를 생성하므로 상대적으로 느림
StringBuffer
- 문자열을 변경할 수 있는 객체
- 모든 메서드가 synchronized로 동기화되어 있어 멀티스레드 환경에서 안전
- 멀티스레드 환경에서 문자열을 자주 변경할 때 사용
- 동기화로 인해 단일 스레드 환경에서는 StringBuilder보다 느릴 수 있음
StringBuilder
- 문자열을 변경할 수 있는 객체
- 동기화되지 않아 단일 스레드 환경에서만 안전
- 단일 스레드 환경에서 문자열을 자주 변경할 때 사용
- 동기화가 없기 때문에 StringBuffer보다 빠름
| 비교 항목 | String | StringBuffer | StringBuilder |
|---|---|---|---|
| 불변성 | 불변 (immutable) | 가변 (mutable) | 가변 (mutable) |
| 스레드 안전성 | 스레드 안전 | 스레드 안전 (synchronized) | 스레드 안전하지 않음 |
| 성능 | 문자열 조작 시 상대적으로 느림 | 문자열 조작 시 상대적으로 느림 | 문자열 조작 시 상대적으로 빠름 |
| 사용 시기 | 문자열이 자주 변경되지 않을 때 | 멀티스레드 환경에서 문자열을 자주 변경할 때 | 단일 스레드 환경에서 문자열을 자주 변경할 때 |
| 동기화 여부 | 동기화되지 않음 | 동기화됨 | 동기화되지 않음 |
| 기본 크기 | 고정된 크기 | 가변 크기 | 가변 크기 |
| 메모리 할당 | 새로운 문자열을 만들 때마다 새로운 객체 생성 | 동적 배열로 관리, 필요 시 확장 | 동적 배열로 관리, 필요 시 확장 |
| 대표 메서드 | length(), charAt(), substring() | append(), insert(), reverse() | append(), insert(), reverse() |
| 사용 예 | 텍스트 상수, 변경되지 않는 문자열 | 멀티스레드 환경에서 문자열 조작 | 단일 스레드 환경에서 문자열 조작 |
Collection
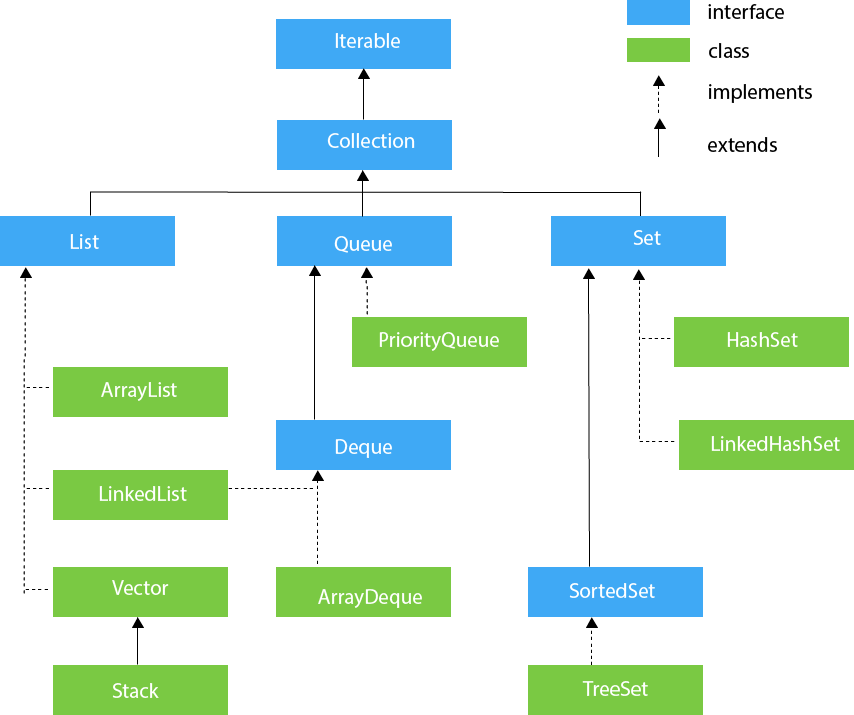
참고자료 : https://www.javatpoint.com/collections-in-java
List
- 배열처럼 사용되지만 담을 수 있는 크기가 자동으로 증가된다.
- 데이터를 추가하는 속도에는 큰 차이가 없지만 데이터를 조회하는 경우 ArrayList가 가장 빠르고 다음으로 Vector(내부에서 get() 메서드를 호출할때 synchronized가 선언) 다음으로 LinkedList 순이고 삭제시 LinkedList는 별 차이가 없지만 ArrayList와 Vector는 실제 안에 배열을 사용하기에 위치 값을 변경하기에 느리다.
- Vector : 객체 생성시에 크기를 지정할 필요가 없는 배열 클래스
- ArrayList : Vector와 비슷하지만, 동기화 처리가 되어 있지 않다.
- LinkedList : ArrayList와 동일하지만, Queue 인터페이스를 구현했기에 FIFO 큐 작업을 수행
Set
- 중복이 없는 집합 객체를 만들때 사용
- 데이터를 순서에 따라 탐색하는 작업이 필요할 때는 TreeSet 그럴 필요가 없으면 HashSet 또는 LinkedHashSet을 사용
- HsshSet : 데이터를 해쉬 테이블에 담는 클래스로 순서 없이 저장
- TreeSet : red-black 트리에 데이터를 담고 값에 따라서 순서가 정해진다. 데이터를 담으면서 동시에 정렬을 하기 떄문에 HashSet보다 성능상 느리다.
- LinkedHashSet : 해쉬 테이블에 데이터를 담는데, 저장된 순서에 따라서 순서가 결정
Map
- Key와 Value의 쌍으로 저장
- 대부분의 클래스들이 동일하지만 TreeMap 클래스가 가장 느리다.
- Hashtable : 데이터를 해쉬 테이블에 담는 클래스, 내부에서 관리하는 해쉬 테이블 객체가 동기화 되어있어 동기화가 필요한 부분에서 해당 클래스 사용
- HashMap : 데이터를 해쉬 테이블에 담는 클래스, Hashtable 클래스와 다른 점은 null 값을 허용 및 공기화되어 있지 않음
- TreeMap : red-black 트리에 데이터를 담으며 키에 의해 순서가 정해진다.
- LinkedHashMap : HashMap과 거의 동일하며 이중 연결 리스트를 사용하여 데이터를 담는다.
Queue
- 선입선출(FIFO) 방식을 사용 및 데이터가 많은 상황에서 적용
- PriorityQueue : 큐에 추가된 순서와 상관없이 먼저 생성된 객체가 먼저 나오는 큐
- LinkedBlockingQueue : 저장할 데이터의 크기를 선택적으로 정할 수 있는 블로킹 큐
- ArrayBlockingQueue : 저장되는 데이터의 크기가 정해져 있는 FIFO 기반의 블로킹 큐
- PriorityBlockingQeueu : 저장되는 데이터의 크기가 정해져 있지 않고, 객체의 생성 순서에 따라 순서가 저장되는 블로킹 큐
- DelayQueue : 큐가 대기하는 시간을 지정하여 처리
- SynchronousQueue : put() 메서드를 호출하면 다른 스레드에서 take() 메서드가 호출될 때까지 대기하도록 되어 있는 큐
Static
- 자주 사용하고 절대 변하지 않는 변수는 final static으로 선언
- 설정 파일 정보도 static으로 관리
- 코드성 데이터는 DB에서 한 번만 읽기
- static을 사용하는 것이 걱정된다면 아예 쓰지 말라
static과 메모리 릭
- static으로 선언한 부분은 GC가 되지 않는다.
- 지속적으로 데이터가 쌓이면 더 이상 GC가 되지 않으면서 시스템은 OutOfMemoryError를 발생
- 메모리 릭이 발생하고 시스템을 재시작해야한다.
reflection
- 클래스의 정보 및 여러 가지 세부 정보를 알 수 있다.
- instanceof를 사용하는 것이 클래스의 이름으로 해당 객체의 타입을 비교하는 방법보다 낫다.
- 클래스의 메타 데이터 정보는 JVM의 Perm 영역에 저장된다.
synchronized
Thread vs Runnable
| 비교 항목 | Thread 클래스 | Runnable 인터페이스 |
|---|---|---|
| 구현 방식 | Thread 클래스를 확장 | Runnable 인터페이스를 구현 |
| 코드 재사용성 | 다중 상속을 지원하지 않으므로 재사용성 떨어짐 | 다른 클래스를 확장할 수 있어 재사용성 높음 |
| 유연성 | 다른 클래스를 상속할 수 없음 | 다른 클래스를 상속 가능 |
동기화
- 하나의 객체를 여러 스레드에서 동시에 사용할 경우
- static으로 선안한 객체를 여러 스레드에서 동시에 사용할 경우
I/O 병목 현상
- Java에서 입출력은 스트림을 통해서 이루어진다.
- I/O는 성능에 영향을 가장 많이 미친다.
- 파일의 크기가 크거나 반복 회수가 많을 경우 BufferedReader를 사용한다.
- 대시보드, 차트, 그래프 등을 통해 데이터를 직관적
- 실시간으로 데이터 변화를 모니터링하고, 검색 및 필터
NIO
- 기존의 Java IO보다 비동기적이고 블록킹이 아닌 I/O 작업을 지원
- 데이터 스트림 대신 버퍼를 사용하여 데이터를 읽고 쓰는 방식
로그
System.out.println() 문제점
- 콘솔에 로그를 남길 경우 프린트될때까지 프린트 하려는 부분은 대기한다.
- 그러면 애플리케이션에 대기 시간이 발생한다.
- 운영 환경에서는 사용하지 말아야 한다.
Slf4j, LogBack
- slf4j는 format 문자열에 중괄호를 넣고, 순서대로 데이터를 콤마로 구분하여 전달한다.
- 문자열 더하기 연산이 발생하지 않아 속도면에서 빠르다.
- LogBack은 예외의 스택 정보를 출력할 때 해당 클래스가 어떤 라이브러리를 참고하고 있는지 포함하여 제공한다.
JSP, 서블릿, Spring
JSP 호출 순서
- JSP URL 호출
- 페이지 번역
- JSP 페이지 컴파일
- 클래스 로드
- 인스턴스 생성
- jspInit 메서드 호출
- _jspService 메서드 호출
- jspDestory 메서드 호출
서블릿 라이프 사이클
- 서블릿 객체가 자동으로 생성 및 초기화 또는 사용자가 해당 서블릿을 처음으로 호출했을 때 생성되고 초기화
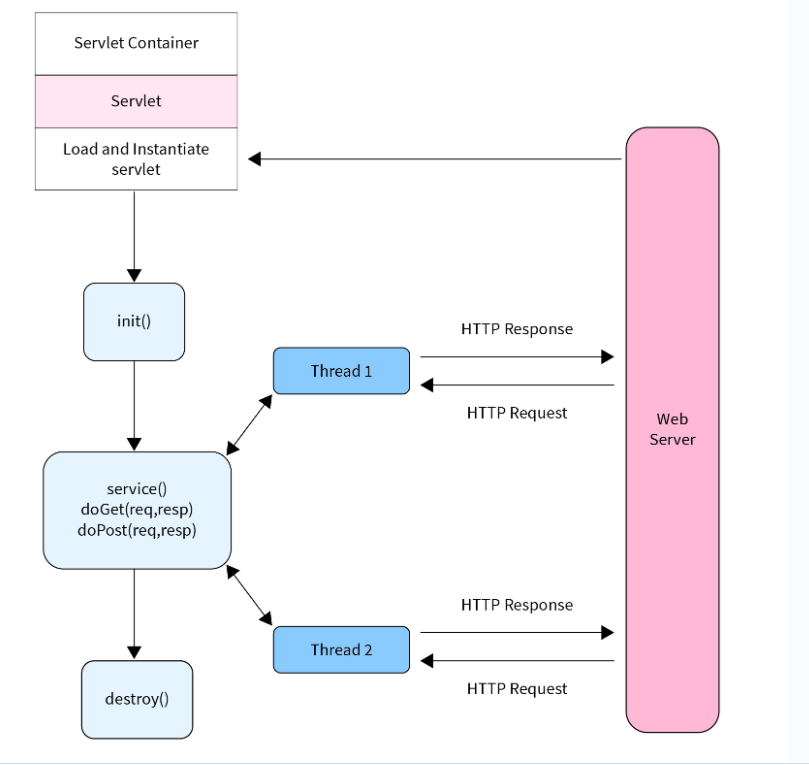
참고 자료 : https://www.scaler.com/topics/servlet-life-cycle/
Spring 사용시 문제점
- 성능 문제가 가장 많이 발생하는 부분은 프록시(proxy)
- 프록시는 기본적으로 실행시에 생성
- 트랜잭션에 주요 사용되며 @Transactional 어노테이션을 사용하면 해당 어노테이션을 사용한 클래스의 인스턴스를 처음 만들 때 프록시 객체를 만든다.
- 뷰 객체를 새로 찾기 보다는 이미 찾아본 뷰 객체를 캐싱하면 훨씬 빠르게 뷰 객체를 찾을 수 있고 스프링에서 제공하는 ViewResolver 중 자주 사용되는 InternalResourceViewResolver에는 캐싱 기능이 내장되어 있다.
DB 사용시 문제점
DB Connection, Connectino Pool, DataSource
- Connection 객체를 얻는 부분은 매우 느리다.
- 객체를 생성 및 네트워크 부담을 줄이기 위해 사용하는것이 Pool이다
- 검증된 DataSource를 사용하자
DB를 사용할 때 닫아야하는 것
Connection 닫히는 경우
- close() 메서드를 호출하는 경우
- GC의 대상이 되어 GC되는 경우
- 치명적인 에러가 발생하는 경우
서버 세팅 설정해야할 대상
- WAS를 웹 서버로 사용해서는 안된다.
- 스레드의 개수를 늘린다.
- KeepAlive를 설정 시간을 늘려 연결을 계속 사용하여 대시시간이 짧아진다.
- KeepAliveTimeout을 설정하여 다음 연결이 될 때 까지 얼마나 기다리는지 설정한다.
- 스레드의 갯수는 DB 연결 개수 보다 많아야한다.
VJM 구성
현재 운영 되고 있는 대부분의 시스템들은 모두 HotSpot 기반 VM
- VM(Vritual Machine) 런타임
- JIT(Just In Time) 컴파일러
- 메모리 관리자
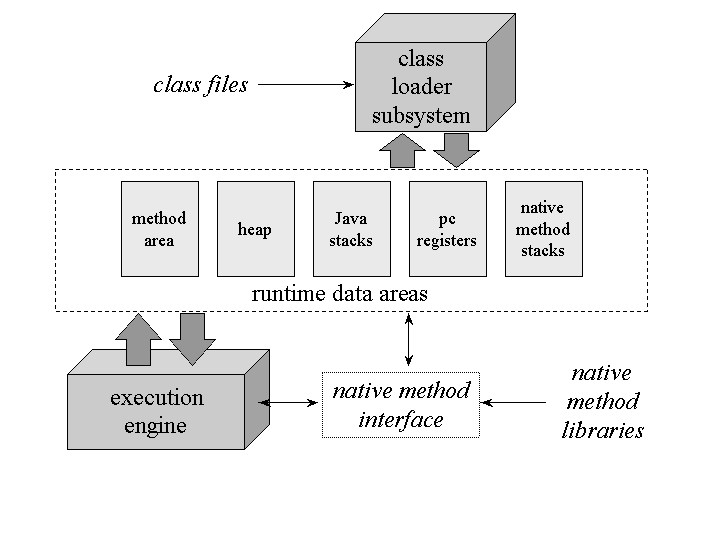
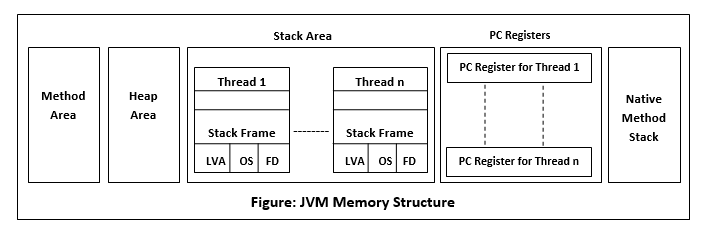
참고자료 : https://medium.com/@fullstacktips/java-memory-management-understanding-the-jvm-heap-method-area-stack-27c895fcce44
GC 원리
GC는 다음의 역할을 수행
- 메모리 할당
- 사용 중인 메모리 인식
- 사용하지 않은 메모리 인식
자바의 메모리 영역
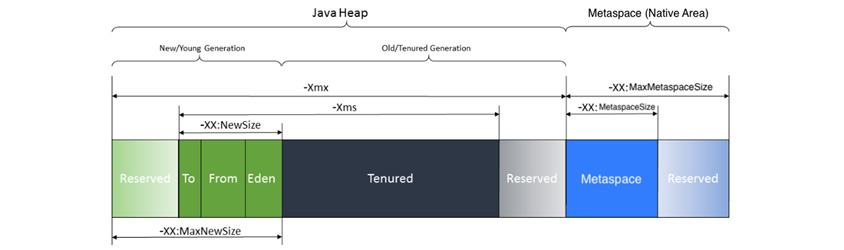
- Eden 영역에 데이터가 차면, Surviovor 영역으로 옮긴다.
- 두 개의 Survivor 영역 사이에 우선 순위가 있는것은 아니고 두 개의 영역 중 한 영역은 반드시 비어있어야 한다.
- 비어있는 영역에 Eden 영역에 있던 객체 중 GC 후에 살아 남아 있는 객체들이 이동한다.
- Survivor 영역이 차면 GC가 되어 꽉차 있던 Survior 영역이 비어 있는 영역으로 옮긴다.
- Young 영역에서 Old 영역으로 넘어가는 객체 중 Survivor 영역을 거치지 않고 바로 Old로 가는 영역은 객체의 크기가 우주 큰 경우 이다.
