학습률을 너무 작게 설정하면 학습이 오래걸리고, 너무 크게 설정하면 손실이 감소하지 않거나 발산하게 된다.
모멘텀
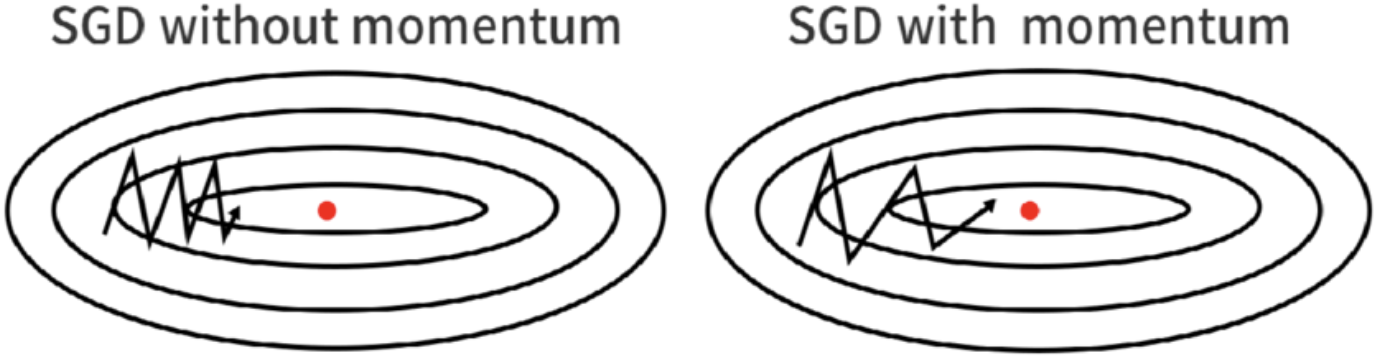
- 확률적 경사 하강법은 오차의 최소점으로 향하면서 이동 방향에 진동이 일어난다.
- 이러한 진동은 가중치의 수렴이 오래 걸리거나 최소점을 지나쳐 발산을 일으킨다.
- 모멘텀은 엉뚱한 방향으로 가중치의 이동 방향이 진동하는 것을 완화시키는 기법이다.
- 세로 방향으로는 학습을 느리게 하고, 가로 방향으로는 빠르게 진행한다.
https://paperswithcode.com/method/sgd-with-momentum
Adam(Adaptive moment estimation)
- 모멘텀과 비슷하게 이전에 계산했던 경사의 평균을 속도항으로 사용하지만 지수적으로 감쇠된다.
- 다른 최적화 알고리즘보다 학습 시간이 빠르다.
[참고자료]
https://www.hanbit.co.kr/store/books/look.php?p_code=B6566099029
