
1. Directory Implementation
1) 디렉토리 구조를 Linear List로 구현
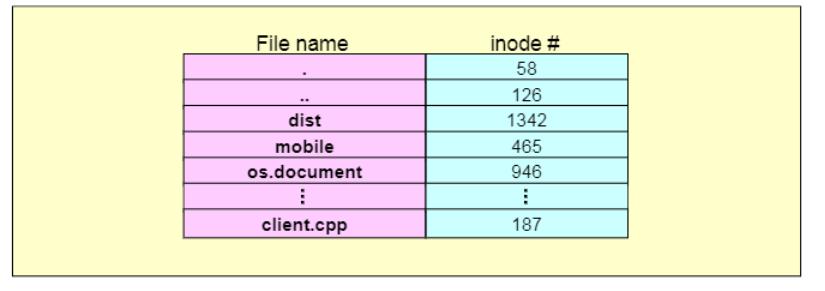
유닉스 운영체제는 위와 같은 디렉토리 구조를 갖고 있다.
각각의 엔트리는 파일이름과 메타 데이터를 가진다. 즉 파일 이름과 inode로 이뤄진다.
예를 들어 루트 디렉토리 밑에 d 디렉토리가 있을 때, d 디렉토리에 아래와 같은 파일들이 있다면 해당 파일들의 이름과 inode들이 저장된다.
. 는 그 자신의 디렉토리의 inode이며, ..는 부모 디렉토리로서, 이 경우 루트 디렉토리의 inode 번호이다.
2) 디렉토리 구조를 hash table로 구현
한 디렉토리에 속하는 엔트리의 개수가 너무 많으면, 특정 파일을 찾으려고 할때 일일이 탐색해서 inode 번호를 찾아야 한다.
이 때 시간이 매우 오래 걸리게 되므로, hash 기법을 사용할 수 있다.
디렉토리 테이블을 hash table로 사용해서 파일 이름을 hash function으로 주소로 변경해 주어서 바로 directory entry로 찾아갈 수 있게 해준다.
-> 그러나 해싱까지 사용하지는않는다..!
해싱은 collision handling이 필요한 기법이기 때문이다.
2. Allocation Methods
파일 시스템 안에 각 파일들에 대한 공간 할당을 어떻게 할 것인가!
디스크 공간이 효율적으로 사용되어야 하며, 파일 데이터에 빠르게 접근할 수 있어야 한다.
1) Contiguous Allocation
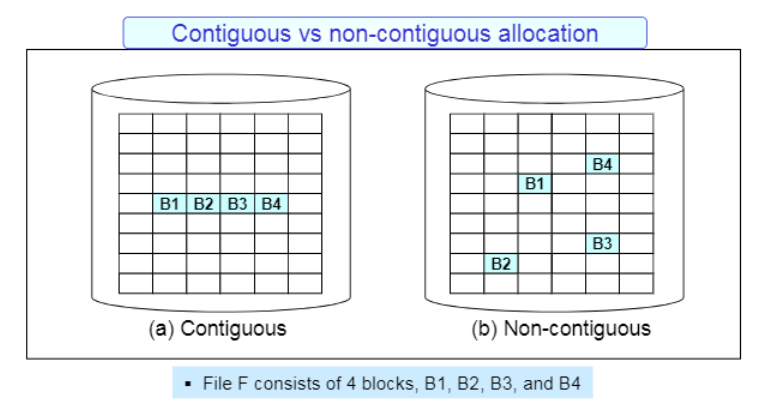
연속 할당 기법으로서, 한 파일의 데이터 블록은 storage상의 연속된 공간에 배치시킨다.
파일에 접근 할 때 매우 빠르게 접근할 수 있다.
❌ 문제
✔ 공간 효율성이 매우 낮다.
연속적으로 파일들이 할당되어 있는데, 만약 한 파일의 크기가 더 늘어나게 되면 그 뒤에 이어서 저장되어 있는 파일을 옮겨야 하는 등의 문제가 있다.
새로운 파일이 생성되었을 때 그 파일의 블록이 모두 연속적으로 위치할 수 있는 공간을 찾아야 한다.
✔ External Fragmentation 문제가 발생한다.
빈 공간이 3, 2, 1개씩밖에 없는데 배치해야 하는 파일의 블록은 5개인 경우 배치되지 못한다.
✔ 파일이 최종적으로 얼마나 필요하게 될지 예측하기 어렵다.
💨 Variation
전체를 다 연속할당하기는 어려우니,
한 파일의 몇 개 블록을 모아서, 각각을 extent 단위로 묶고 각 extent끼리만 contigouous allocation하되 서로 다른 extent는 discontiguous하게 한다.
-> 따라서 일반적으로는 non-contiguous 방법을 사용한다. 그리고 그 블록의 위치정보를 inode에 저장한다.
2) Linked Allocation
MS 운영체제에서 많이 사용
Discontiguous Allocation이다.
각 파일을 디스크 블록단위로 분산시켜서 저장한다.
흩어진 블록들을 linked list로 연결시켜서, storage 상에서 linked 되도록 만든다.
디렉토리는 첫 번째, 혹은 마지막 블록에 대한 포인터만을 갖는다.
👍 장점
블록단위 할당이므로, external fragmentation은 없다.
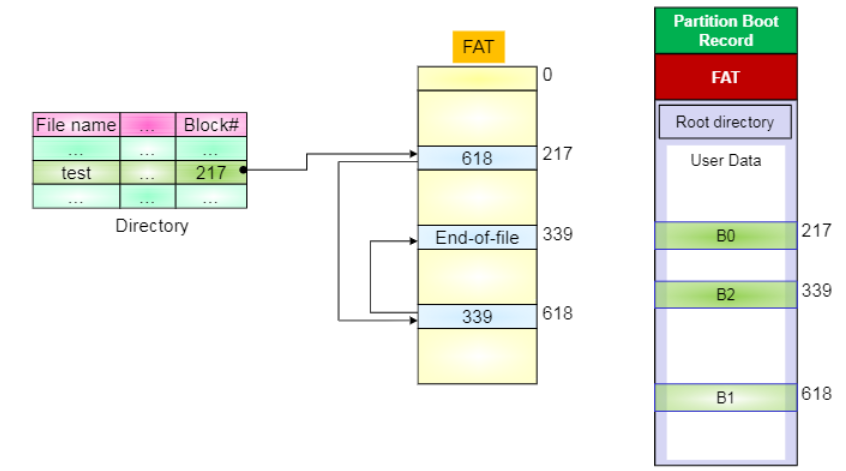
🌳 MSWindows의 FAT파일 시스템
윈도우 시스템에서는 디렉토리에 위와 같이 파일 이름과 파일의 메타 데이터들, 그리고 해당 파일의 첫 번쨰 블록 넘버가 온다.
217번 블록을 찾아가 보면, test 파일의 첫번째 블록이 있다.
FAT 영역의 217번에는 다음 블록의 위치가 저장되어 있다.
따라서 두번째 블록은 618번으로 간다.
FAT 영역의 618번에는 세번째 블록의 위치가 있다.이와 같이 파일 블록들을 순서대로 link되는 것을 FAT 영역에서 수행하고, 실제 Storage에서는 파일 데이터들만 존재하는 방식이다.
이러한 FAT 정보를 저장하는 곳은 디스크 상의 FAT 영역을 따로 만들어서 저장한다. (Boot records 뒤에)
👍 장점
external fragmentation이 존재하지 않는다.
❌ 단점
direct access를 지원하지 않으므로 link되어 탐색해야 한다.
pointer를 저장하기 위한 영역(FAT 등)이 따로 필요하다.
Reliability 문제가 있다. link가 끊어지면 그 이후 부분은 접근할수 없다.
3) Indexed Allocation
유닉스, 리눅스 운영체제에서 많이 사용한다.
Discontiguous Allocation이다.
파일의 각 block들의 위치 정보를 한 곳, index block에 넣어서 저장해 둔다. (유닉스의 경우 inode에 저장)
각 파일은 그 파일만의 index block이 있다.
디렉토리가 index block 정보를 포함하거나, 디렉토리는 inode 주소만 알고 inode에 그 index block을 저장하는 방식으로 할 수 있다.
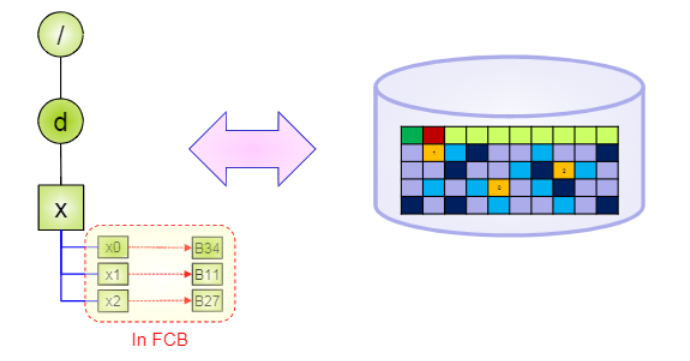
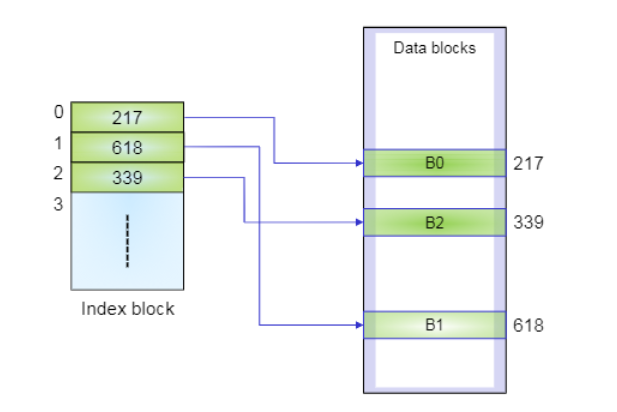
파일 F의 Index block에 위와 같이 블록0, 블록1의 위치 정보들이 한 군데 저장되어 있다.
그리고 이 index block을 inode에 저장해 둔다.
👍 장점
external fragmentation이 존재하지 않는다.
❌ 단점
index block을 추가적으로 만들기 때문에, 해당 공간에 대한 낭비가 있다.
inode에 대한 공간이 한정적이다.
inode 공간이 128Byte인데, 이 안에 각종 정보들을 다 저장해야 하는데 index block까지 저장하려면 file block number을 과연 몇 개까지 저장할 수있을까..?
한 block number가 4byte를 차지한다고 하면, inode에 index block 만 저장한다고 하더라도, inode에 block number을 32개밖에 저장할 수 없다.
-> 한 파일의 크기가 32block을 추가하게 되면 문제가 발생한다.
🌳 해결방안
index block이 하나로 부족하면, linked index block방법을 사용한다.
multi-level index로서, index에 level concept를 도입한 방법을 사용할 수도 있다.
linked와 multi-level을 mix한 방법을 사용하기도 한다.
