
FCFS와 RR은 'Arriving Time'을 기준으로 하는 스케줄링 기법이다.
1. FCFS (First-Come-First-Service) = FIFO
1) 비선점형 스케줄링
Time quantum 없는 스케줄링 기법이다. 더 높은 우선순위의 프로세스가 들어와도 CPU를 선점하지 못한다.
2) 스케줄링 기준= Ready Que에 도착하는 '도착시간'
Ready Queue에 먼저 도착한 프로세스가 먼저 스케줄을 받게 된다.
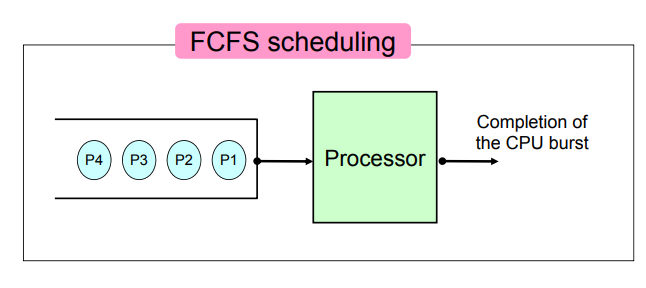
제일 먼저 들어온 p1이 제일 먼저 들어오고, ready queue에 들어온 순서대로 p1, p2, p3, p4가 cpu에 들어간다. time quantum이 끝나면 나가는 것이 아니라, 각 프로세스가 cpu를 사용하고 싶은 만큼 다 사용하고 나서 나간다.
완전히 종료해서 terminated 상태로 나가거나, I/O 를 이용하고 싶은 경우 asleep 상태로 나가게 된다.
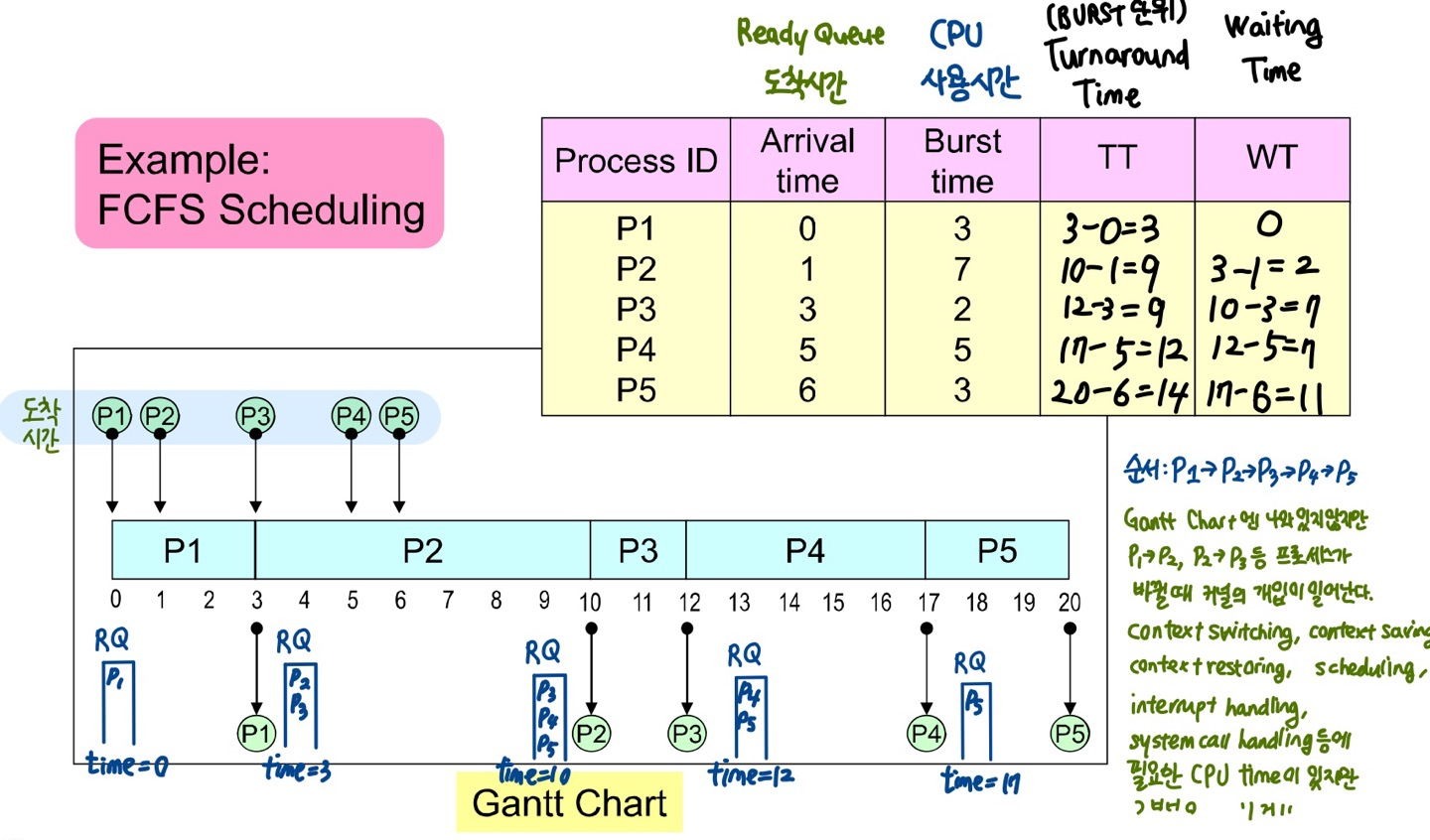
3) 자원 활용도
- 비선점 스케줄링이기 때문에 context switching이 많지 않기 때문에 자원의 활용도가 높다.
4) 적절한 시스템
- Batch System에는 적절하지만 Interactive System에는 적절하지 않다.
- Interactive System은 선점 스케줄링을 사용해야 한다. 왜냐하면 비선점 스케줄링을 사용할 경우 한 프로세스가 cpu를 독점할 수 있기 때문에 다른 프로세스의 응답시간이 매우 안 좋아질 수 있기 때문이다.
5) 단점
- Convoy Effect = CPU 사용 시간이 긴 큰 프로세스가 하나라도 있다면, 다른 많은 프로세스들이 전부 기다려야 할 수 있다.
- 이로 인해 평균 응답시간이 매우 길어질 수 있다.
2. RR (Round-Robin)
1) 스케줄링 기준 : ready que에 도착한 '도착시간'
- 먼저 도착한 프로세스가 먼저 스케줄링을 받는다.
2) 선점 스케줄링
- Time Quantum을 두어서 한 프로세스가 cpu를 독점하지 못하게 한다. Time Quantum이 지나면, 그 프로세스는 cpu를 release하고 ready 상태로 돌아간다.
✅ FCFS와의 차이점 = 스케줄링 기준은 FCFS와 동일하지만 '선점' 스케줄링이다.
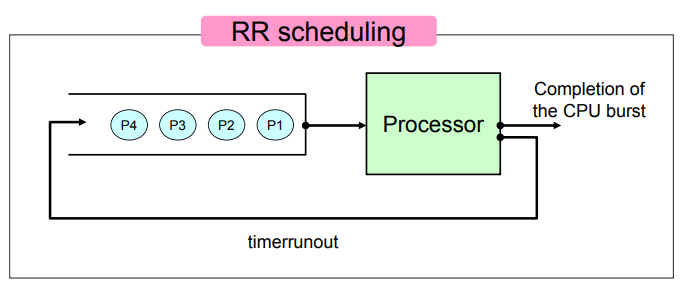
P1 -> P2 -> P3 -> P4 순서로 CPU를 사용하지만, 주어진 Time Quantum동안만 사용할 수 있다. Time Quantum이 지나면, Timer Interrupt가 발생해서 프로세스를 ready queue의 뒤쪽에 넣어준다. 혹은 P1이 실행하다가 Time Quantum이 지나기 전에 시스템 콜을 해서 I/O 를 시작하면, 그 때에는 asleep 상태로 나가게 된다.
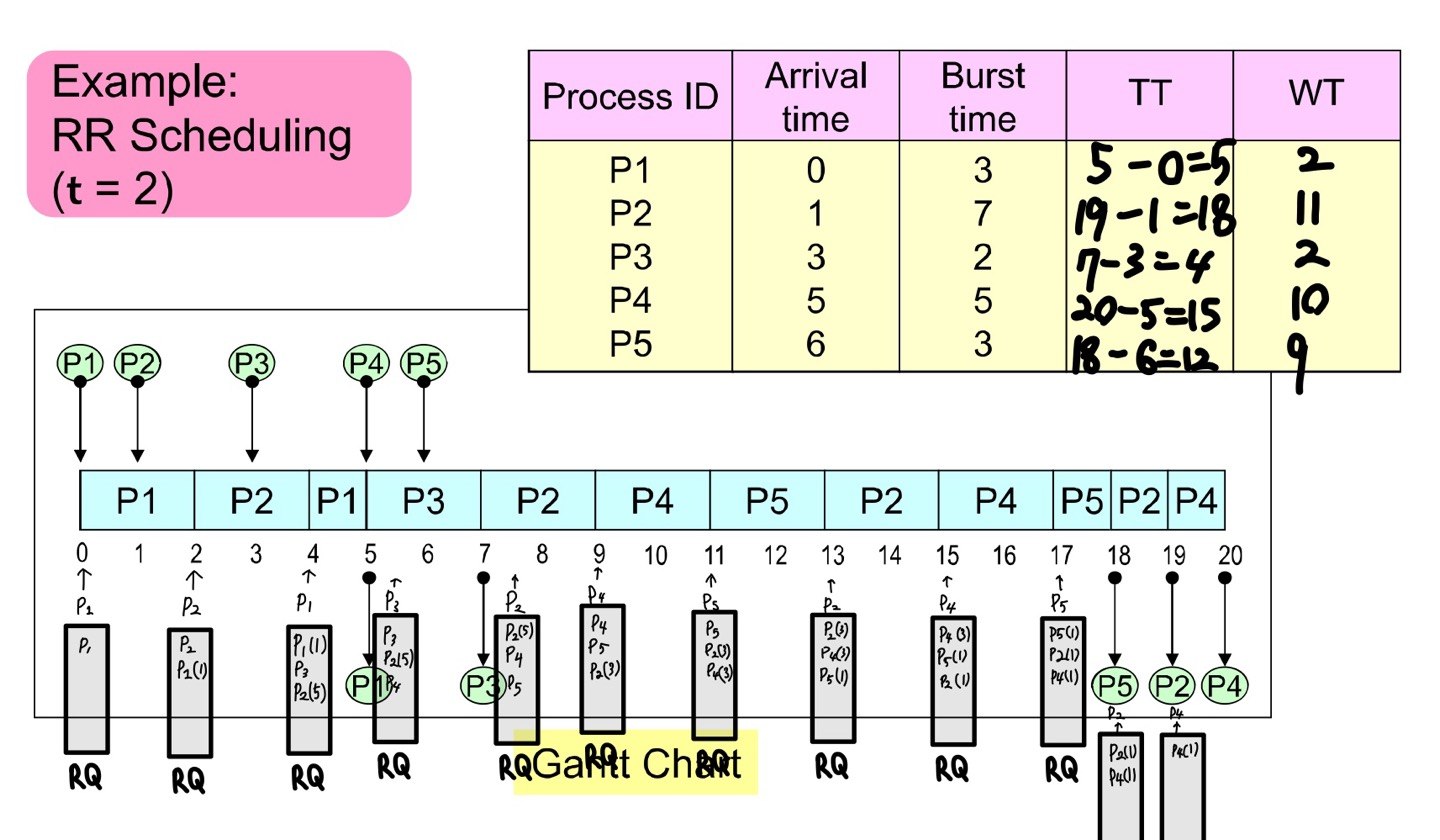
3) 단점
Preemption으로 인해서 Context Switching 오버헤드가 커진다. 그렇지만 한 프로세스가 CPU를 독점하는 일은 사라진다.
따라서 Interactive 시스템이나 Time-sharing 시스템에서 사용하기에 적합하다.
4) Time quantum의 크기
- Time-quantum을 만약 크게 하게될 경우에는 결국 FCFS 기법이나 다를 바 없기 때문에 좋지 않다.
- Time quantum을 작게 하면 context switching이 매우 많아지고, 그 때마다 커널이 계속 개입하기 때문에 커널의 오버헤드가 매우 커질 우려가 있다.
- Processor Sharing: Time Quantum을 아주 작게하면, 시스템에 들어와 있는 모든 N개의 프로세스가 cpu의 타임을 1/n만큼 나누어 갖는 효과를 갖게 되는데, 이것을 'processor sharing'이라고 한다. 즉 모든 프로세스가 아주 공평하게 1/n만큼 cpu time을 나눠 갖게 된다.
