
1. UNIX 운영체제
1) Time Sharing System, Interactive System
여러명의 사용자가 단일 컴퓨터 시스템을 동시에 사용하는 환경을 가정하기 때문에, time quantum이 기반 된 스케줄링
2) 우선순위 기반의 스케줄링
프로세스의 우선순위를 120단계로 나누어서, 0부터 119까지의 우선순위를 부여한다.
우선순위가 낮은 쪽 60개는 User Priority (0에 가까울수록 우선순위 높음)
우선순위가 높은 쪽 60개는 Kernal Priority (119에 가까울수록 우선순위 낮음)
커널 우선순위란, 프로세스가 커널 모드에서 실행할 때 할당 받는 우선순위
유저 우선순위란, 프로세스가 유저 모드에서 실행할 때 할당 받는 우선순위
3) Clock Handler
유닉스의 cpu에는 clock handler가 있는데, 주기적으로 인터럽트를 발생시켜서 cpu 내 모든 프로세스의 우선순위를 재정비한다. 이 때마다 우선순위가 바뀌므로, dynamic 하다.
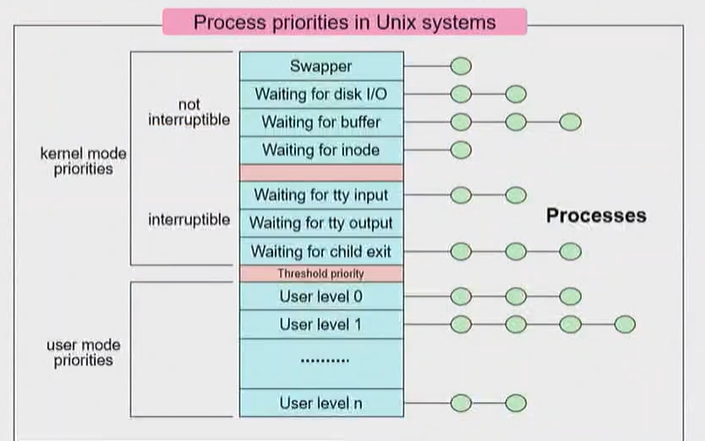
- 위 60단계의 커널 모드 우선순위, 아래 60 단계의 유저 모드 우선순위로 나뉘어진 모습
즉, ready Queue가 120개 있는 것이다. (Multi-level Feedback Queue처럼) - 커널 우선순위에는 Interruptible과 not Interruptible로 나뉘는데, not Interruptible RQ가 더욱 더 우선순위가 높다.
4) 스케줄링 원칙
항상 우선순위가 높은 프로세스부터 스케줄링한다.
프로세스의 우선순위는 계속 변화한다. (Dynamic 우선순위)

clock handler가 인터럽트를 걸 때마다 우선순위가 조정되는데, 이 때 우선순위를 조정하는 식은 다음과 같다.
첫 번째 Decay Computation이 이뤄진다. 프로세스가 cpu를 현재까지 사용한 양 (= CPU COUNT)을 2로 나누어, 커널의 CPU COUNT 변수에 저장한다.
두 번째 Priority Adjustment 이다. 앞서 한번 나누었던 cpu count를 "한번 더" 2로 나누고, 기존의 우선순위 값과 nice value를 더하여 "새로운 우선순위"를 만든다.
ex) 유저 모드에서의 프로세스를 기준으로, Base Priority(=사용자 우선순위 중 가장 우선순위가 높은 값)는 60이다. nice value는 사용자가 생각하는 우선순위로, nice 라는 command를 이용해서 내가 실행하고자 하는 프로세스의 우선순위를 nice value만큼 낮추는 것이다.
만약 nice value가 +5라면, 사용자 프로세스 우선순위에 5를 더하여 그 우선순위를 낮추는 것이다.
5) 예시

가정: 각 프로세스들은 I/O 등 다른 것을 하지 않고 모두 CPU만 이용한다. Time quantum = 1이다. Nice value는 모두 0이다.
(0) Time = 0
각 프로세스의 초기 우선순위가 60으로 모두 동일하기 때문에, 랜덤으로 p1이 먼저 시작되었다.
time quantum=1이므로, 1/60초마다 cpu count가 하나씩 증가한다. 따라서, time quantum 1초동안 cpu count는 60번 증가한다.
이 때 time quantum이 끝나면 clock handler가 cpu에 인터럽트를 걸고, 우선순위가 조정된다.
(1) Time = 1
decay computation으로 p1의 cpu count는 60/2 = 30이다. Priority = 30/2 + 60 + 0 = 75이다.
p2, p3는 그대로 cpu count = 0, priority = 60이다.
스케줄링을 할 때 p2, p3의 우선순위가 같으므로 랜덤으로 p2가 선정된다.
1초 동안 p2의 cpu count는 60번 증가하고, 다시 clock handler가 인터럽트를 걸어서 우선순위가 조정된다.
(2) Time = 2
decay computation으로 p2의 cpu count = 60/2 = 30이다. Priority = 30/2 + 60 + 0 = 75이다.
p1의 decay computation은 cpu count = 30/2 = 15이다. Priority = 15/2 + 60 + 0 = 67이다. (소수점 이하는 무조건 버린다)
p3은 그대로 값을 유지한다.
스케줄링을 할 때 p3의 우선순위가 가장 높으므로 선정된다. 1초 동안 p3가 cpu를 사용한다.
(3) Time = 3
p3의 cpu count = 30, priority = 75가 된다.
p2의 cpu count = 15, priority = 67이 된다.
p1의 cpu count = 15/2 = 7, priority = 60 + 7/2 + 0 = 63이다.
p1이 스케줄링되어 cpu를 사용한다.
(4) Time = 4
p1의 cpu count = 7 + 60 = 67이고, decay computation으로 cpu count = 33이 된다.
priority = 60 + 33/2 = 60 + 16 = 76이 된다.
p2의 decay computation = 15/2 = 7, priority = 60 + 7/2 = 63이 된다.
p3의 decay compuation = 30/2 = 15, priority = 60 + 15/2 + 67이 된다.
이러한 방식으로 UNIX 운영체제의 스케줄링은 진행된다.
=> 계속 번갈아서 P1, P2, P3가 CPU를 사용하게 된다. 공평하게 CPU TIME을 1/3씩 나누어 갖게 된다. UNIX 시스템이 탄생할 때부터 CPU TIME을 공평하게 분배하도록 하였기 때문에, UNIX는 아주 공평한 스케줄링 기법을 갖고 있다.
=> CPU를 사용하는 프로세스의 우선순위는 떨어지지만, 사용하지 않으면 우선순위가 유지되거나, 우선순위가 올라간다.
6) FSS 스케줄링 (Fair Share Scheduling)
UNIX 시스템의 스케줄링 기법은 'FFS 스케줄링' 기법이다.
사용자 커뮤니티, 즉 프로세스들을 '여러개의 공평한 Share 그룹'으로 나누고, 그룹 단위로 CPU Time을 공평하게 할당하겠다는 방식이다.
사용자 A 는 프로세스 1개를 생성했고, 사용자 B는 프로세스 2개를 생성했다고 생각해 보자. CPU Time을 각 프로세스 단위로 배분하면, 프로세스가 각각 1/3씩 cpu time을 나누어 가졌지만 사용자 단위로는 A는 1/3, B는 2/3이기 때문에 불공평하다. 따라서 이를 사용자 단위로 Grouping하여, 사용자 A가 1/2, 사용자 B가 1/2씩 CPU Time을 가져가고 프로세스1은 1/2, 프로세스 2와 3은 각각 1/4을 가져간다.
7) FSS 예시
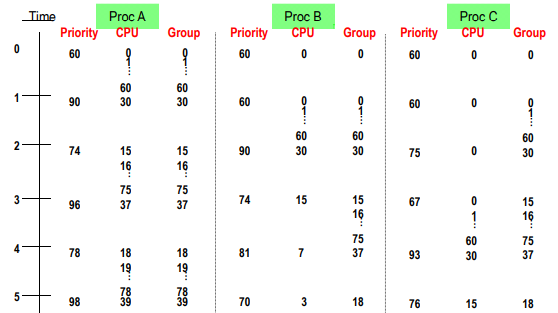
Group 1 = {Pa}, Group 2 = {Pb, Pc} 라고 하자.
(1) Time = 0
모든 프로세스의 우선순위는 동일하게 60이라고 가정해 보자. 랜덤으로 Pa가 선정되어 실행되면 Time Quantum = 1만큼 실행된다.
(2) Time = 1
Pa의 CPU Count는 60이 되고, Group COunt도 60이 된다. 각각 2로 나누어서 cpu count = 60/2 = 30, Group count = 60/2 = 30이 된다. Priority = 60 + (30/2) + (30/2) = 90이 된다.
Priority는 현재 B, C가 제일 높으므로 B가 선정되었다고 생각해 보자.
(3) Time = 2
B의 CPU COUNT = 60, GROUP COUNT = 60이 된다. B의 CPU COUNT, GROUP COUNT는 모두 2로 나누어 30이 되고 Priority = 90이다.
C의 CPU COUNT = 0, GROUP COUNT = 60/2 = 30이 된다. Priority = 60 + 0 + 15 = 75가 된다.
A의 CPU COUNT, GROUP COUNT 는 각각 2로 나누어 15가 되고, Priority = 60 + 7 + 7+ = 74가 된다.
현재 우선순위는 A가 가장 높으므로 A 가 선택된다.
(4) Time = 3
A의 CPU COUNT = 75, GROUP COUNT = 75가 된다. 이 때 Decay 하여 각각 37이 되고, Priority = 60 + 18 + 18 = 96이 된다.
B의 CPU COUNT = 15, GROUP COUNT= 15, Priority = 74가 된다.
C의 CPU COUNT = 0 ,GROUP COUNT = 15가 되고 Priority = 67이다.
C가 스케줄링을 받는다.
(5) Time = 4
c의 CPU COUNT = 60, GROUP COUNT = 75, DECAY 하여 CPU = 30, GROUP = 37이다. Priority = 93이 된다.
b의 CPU COUNT = 7, GROUP = 75/2 = 37가 되고, Priority = 60 + 3 + 18 = 81이 된다.
결과적으로
A => B => A => C 반복 ..
A가 CPU Time의 1/2, B, C 는 1/4을 가져가서 Group 1, Group 2가 각각 절반씩 가져간다.
UNIX는 이러한 형태로 프로세스들에게 그룹 단위로 CPU TIME을 공평하게 배분하는 스케줄링을 사용했다.
- UNIX 시스템은 각 프로세스의 CPU COUNT 등의 정보들을 U-area에 저장한다.
(프로세스의 정보를 저장하는 PCB를 리눅스에서는 PCB를 'Process Descriptor'라고 하고, UNIX는 'U-area와 Process Table Slot'에 저장된다. 따라서 U-area는 PCB의 일부인 것이다!)
2. Windows OS
1) 우선순위 기반의 선점 스케줄링 기법
윈도우에서는 프로세스가 아니라 '스레드'라는 용어를 더 많이 사용한다.
우선순위 기반의 선점 스케줄링 기법이며, 32 단계의 우선순위 레벨을 가지고 있다.
- 1~15까지는 Variable Class이다.
- 16~32까지는 Real-time Class이다.
UNIX와는 달리 값이 클수록 우선순위가 높다.(32의 우선순위가 제일 높고 1이 제일 낮다)
2) MFQ 스케줄링
각 우선순위 레벨마다 Queue를 사용하기 때문에 MFQ 스케줄링 기법에 근간을 두었다. 우선순위가 높은 큐에서 낮은 큐로 이동하며 스레드를 선정한다.
3) 32가지 우선순위 클래스의 구분
1은 Real Time, 2-6은 모두 Variable Class
(1) RealTime Priority Class (RT CLASS)
(2) High Priority Class
(3) Above Normal
(4) Normal
(5) Below Normal
(6) Idle
4) 6개의 클래스마다 상대적인 우선순위 레벨을 7단계를 두고 있다.
(1) Time critical
(2) Highest
(3) Above normal
(4) Normal
(5) Below Normal
(6) Lowest
(7) Idle
5) 윈도우즈의 스케줄링 기법
(1) 어떤 스레드가 CPU을 실행하다가 Time quantum을 다 사용하면, 그 스레드의 우선순위는 떨어진다. 단, 그 스레드가 variable 클래스였다면 떨어진다. (만약 스레드가 real time 클래스라면 우선순위는 떨어지지 않는다)
(2) variable 우선순위의 스레드가 wait operation으로부터 풀리면 (= 입출력을 하고 sleep에서 wake up을 하여, ready 상태로 돌아올 때) Dispatcher(=스케줄러)가 스레드의 우선순위를 높여준다.
=> MFQ의 기본적인 구조와 동일함.
(3) 다만, 입출력 하고 돌아올 때 우선순위를 얼마나 올려주는지는 각각 다르다.
키보드/마우스 입출력을 하고 오면 상당히 증가한다. 키보드, 마우스는 사람이 사용하는 것이기 때문에, 사용자와 상호작용하고 있는 경우엔 그 스레드의 우선순위를 높여서 사용자 반응을 빨리 줄 수 있도록 한다.
디스크/보조장치를 하고 오면 적당하게 증가한다. 디스크와 보조장치는 사용자와의 상호작용이 아니라 내부적인 것이므로 우선순위 증가가 적당히만 이뤄진다.
(4) 여러 프로세스를 사용하더라도 내가 현재 사용중인, 가장 top에 있는 프로세스를 'foreground'라고 하며 나머지를 'background'라고 한다. 어떤 프로세스가 background에서 foreground로 오면, thread의 time quantum은 3배 증가한다. 즉, 백그라운드에 비해 사용자와 직접 상호작용 중인 foreground 스레드의 time quantum은 3배가 더 높다. => 사용자와의 인터랙션 시
- UNIX의 경우에는 커맨드를 입력하고, Enter키를 치면 'foreground', 커맨드를 입력하고 & (and key)를 치면 'background'가 된다.
(5) 윈도우스 7에서는 'UMS 스케줄링'이 사용됐다. UMS란 User Mode Scheduling이다.
항상 스케줄러가 스케줄링을 할 때에는, 스케줄러는 커널 안에 있으므로 커널이 CPU를 잡아야 한다. 즉 커널의 개입이 필요하다. 그 때 CPU에서 사용자 프로세스는 Context saving을 하며, 나가있어야 한다. 이러한 커널의 개입으로 인한 오버헤드가 발생하는 것을 방지하기 위해서, 커널 모드로 들어가지않고 유저 모드에서도 스케줄링을 할 수 있도록 만든 것을 'UMS'라고 한다.
3. LINUX
1) 리눅스 커널 버전 2.4를 기준으로, 많은 변화가 있었다.
2.4 이전은 unix의 전통적 스케줄링 기법의 변화된 기법으로 사용했다. 즉, '우선순위 기반으로 한 Round-robin 스케줄링'이고, 'MFQ 스케줄링' 기법이었다.
그러나 이 기법에는 두 가지 문제점이 있었다.
(1) smp 시스템을 잘 지원하지 못했다. smp란 symmetrical Multi-processor 시스템으로, Multiple CPU를 갖는 시스템에서 각 CPU들이 CPU가 전부 똑같은 기능(Capability)과 스펙을 갖고 있을 때 smp라고 한다.
(2) 테스크의 개수에 따라서, 테스크의 개수가 너무 많아지면 스케줄링을 선정하는데 시간이ㅏ 너무 오래 걸린다.
- Unix는 프로세스, MS Windows는 스레드, Linux는 테스크(task)라고 한다.
2) 2.4 이후~ 2.6.22 변화된 기법
(1) O(n), O(1) 스케줄링
Order of n and Order of 1 스케줄링 기법은, task의 개수가 몇개든 스케줄링을 하는 데 스케줄링을 하는 데 걸리는 시간이 비슷하다는 것이다.
(2) smp를 지원한다.
- Load Balancing : smp 같은 multiple cpu 시스템에서, 모든 cpu가 거의 비슷한 부하를 가질 수 있도록 테스크를 적절히 분배하여 load balancing(부하 균형)을 잘 맞추었다.
- Processor Affinity : 한 cpu에서 실행을 했던 task를 다른 cpu로 옮겨서 실행하는 'task migration'을 못하게 한 것이다. cpu1에서 실행했던 task는 그 cpu1의 캐시에 자신의 여러 정보들을 저장했는데, cpu2로 넘어가면 그 캐시를 가져오고 cpu1의 캐시를 삭제해야 한다. 이것들이 모두 오버헤드가 되므로, task를 한 cpu에서만 실행되도록 만들었다.
(3) 공평한 스케줄링 방법
(4) 서버 workload에 초점을 맞추어 만들어진 스케줄링 기법
(5) interactive한 데스크탑 시스템에서는 리눅스를 사용하면 성능이 below par(기본도 못하는 수준)이었고 클라우드/서버/데이터 센터 등에서 사용되는 것에는 리눅스가 최적화되어 있었다.
(interactive한 시스템에서 잘 작동 못함)
3) 2.6.23 이후 변화된 기법
서버 워크로드에도 적절하게, Interactvie 한 데스크탑 application에도 적절하게 변화 되었다.
(1) Modular Schedular
스케줄러 클래스를 두고, 여러개의 스케줄링 기법을 사용할 수 있게 하였다.
내가 원하는 스케줄링 기법을 선택할 수 있게 한 것이다.
(2) CFS (Completey Fair Schedular)
리눅스의 대표적 스케줄링 기법.
공평한 스케줄링을 하자는 것을 기본으로 하여, ready queue를 red-black tree로 만들어서, 스케줄링한 것이다. 스케줄링의 시간 복잡도가 O(logN)이 되도록 하였다.
4) 리눅스 스케줄러
(1) I/O-Bound Process와 CPU-Bound Process에 중에서, 당연히 I/O Bound Process를 선호한다. 그렇다고 CPU Bound Process를 무시하지는 않고 케어하면서, I/O Bound Process를 선호한다.
(2) 우선순위 기반의 선점 스케줄링이며, unix 운영체제처럼 숫자 값이 적을수록 높은 우선순위를 가진다.
(3) 우선순위의 범위는 0-99는 우선순위가 높은 Real-time Range (커널 모드)고, 100-139는 우선순위가 낮은 Nice value Range (유저 모드)이다.
(4) 스케줄러 클래스
각 스케줄러 클래스마다 다른 스케줄링 알고리즘을 사용한다.
- Default Scheduling Class (Nice value range에서) : CFS 스케줄링
- Real Time Scheduling Class : 다른 알고리즘(fcfs나 round robin 등)
(5) 우선순위 배정 - Real Time task에 대해서는 고정 우선순위를 배정한다. 우선순위가 변하지 않고 끝까지 실행된다.
- 나머지 Task는 우선순위가 다이나믹하게 변한다. sleep을 오래 할수록 더 I/O Bound라고 보기 때문에 우선순위가 많이 올라간다.
- computation을 많이 하면 우선순위가 떨어진다.
- Nice value를 사용해서, 양수로 nice value가 주어지면 우선순위가 떨어지고, 음수면 우선순위가 올라간다. (그런데 커널만이 nice value를 음수로 할 수 있고, 일반 사용자는 nice value를 양수로만 줄 수 있기 때문에 자신의 task 우선순위를 떨어뜨릴 수만 있다)
=> 정리 (핵심)
Real Time Task(0~99) 까지는 MFQ 구조로 Ready Queue를 두고, FIFO나 RR 스케줄링
Nice value Task(100~139) 는 Red Black Tree로 CFS 스케줄링
