[PL] Syntax Analysis : Parse Tree, Abstract Syntax Tree, Ambiguous Grammer
Compiler / Programming Language

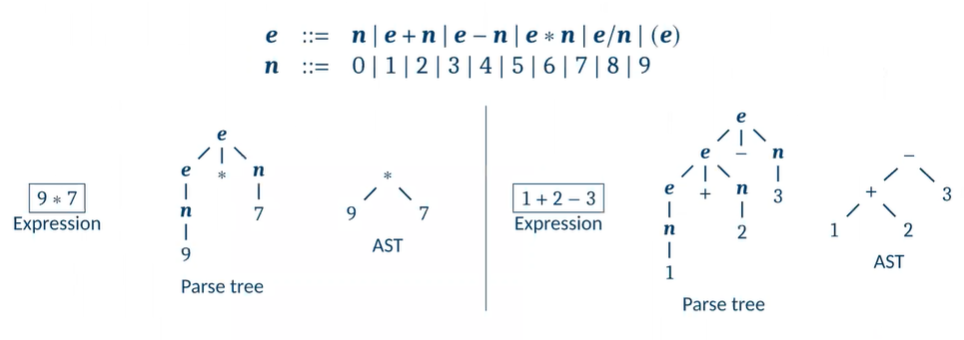
1. Parse Tree (=Derivation Tree)
📌Example
Production Rules을 적용하여 Left-most Non-terminal Derivation을 진행한 예시
- e를 Final String "3+(1-5)"으로 만들었다.
- 즉, "3+(1-5)"는 올바른 string이다.

➡️ 이 Derivation은 tree로 만들 수 있으며 이를 "Parse Tree"라고 명명한다.
(1) 각 노드 e, +, e, n, 등등 모든 노드는 'Terminal'이거나 'Non-terminal'이다.
(e는 non-terminal, 3은 terminal)
(2) 부모노드 e로 인해 생긴 e + e 는 자식 노드이다.
(3) 맨 위에 있는 노드 e는 '루트 노드'이며, 루트 노드는 항상 하나이다.
(4) 맨 마지막에 있는 노드는 'leaf 노드'이며, 모두 terminal이다. 3, +, (, 1, -, 5, )는 모두 terminal이다.
- leaf 노드를 모두 모아서 final string을 만들어낼 수 있다.
(5) 루트 노드와 leaf 노드 사이에 있는 노드는 'internal nodes'이다.
2. Parsing의 첫 번째 문제 "Ambiguous Grammer"
Parsing은 sequence of tokens에서 derivation / parse tree를 만드는 과정이다.
Derivation과 parse tree는 문법에 의해 정의된 언어의 문자열을 어떻게 생성할 수 있는지 보여준다.
Parsing에는 두 가지 문제가 존재하는데, 그 Parsing의 첫 번째 문제 "Ambiguous Grammer" 를 알아보자 !
1) 정의
Ambiguous Grammers는 어떠한 문법에서 하나의 string을 가지고 두개의 다른 leftmost derivation이나 rightmost derivation이나 두개의 다른 parse tree가 생성되는 것을 의미한다. 즉, 하나의 문자열에 대해 두 개의 의미가 생기는 것이다.
그러나 이러한 Ambiguity는 컴파일러에 따라 다른 실행결과가 발생될 수 있게 만드는데, 프로그램의 올바른 동작을 보장하지 못하기 때문에 그 프로그래밍 언어의 reliability를 매우 떨어뜨리므로 사용할 수 없다.
📌Example
Exp -> Exp + Exp
Exp -> Exp * Exp
Exp -> NUM➡️ 어떻게 '1+2*3'을 Parsing할 수 있을까?!
Exp -> Exp Exp -> Exp + ExpExp -> 1 + ExpExp -> 1 + 2Exp -> 1 + 2*3
Exp -> Exp + Exp -> 1 + Exp -> 1 + ExpExp -> 1 + 2Exp -> 1 + 2*3
=> Exp Exp으로 Derivation을 시작하던, Exp + Exp으로 Derivation을 시작하던 "1+23"으로 끝나므로 "1+2*3"은 유효한 문자열이며 두 Derivation은 모두 옳다.
=> 비록 둘 다 똑같은 문자열을 반환하지만, 하나의 문법에서 두 개의 parse tree가 생겼기 때문에 이 문법은 모호하다.
=> 전자 : 1+2를 만들고 그 결과에 3을 곱함 : (1+2)3의 의미
=> 후자 : 23을 만들고 그 결과에 1을 더함 : 1+(2*3)의 의미
=> 두 parse tree가 똑같은 문자열을 생성하더라도, 전자는 9, 후자는 7의 값이므로 결과값이 다르다. 즉, 문자열이 같은 모양이더라도 Exp*Exp로 parsing 하는 컴파일러와 Exp+Exp로 parsing 시작하는 컴파일러는 다른 결과값을 만들어낼 수 있다.

2) 어떻게 Ambiguous Grammer을 찾아낼 수 있을까?
Ambiguous Grammer을 찾아내고, 제거하는 공식적인 알고리즘은 존재하지 않는다. 따라서 내가 만든 프로그래밍언어가 Ambiguous Grammer인지 증명할 수 있는 공식적 방법은 없다.
➡️ 그러나, 체크할 수 있는 한 가지 방법은 Left-hand Non-terminal이 Right-hand에 두 번 존재하는지 확인하는 것이다.
➡️ Non-terminal A는 Right-hand에 두 번 존재한다 => Ambiguous Grammer이다!
📌Example
A -> A a A
Production form : A -> A a A
Sequential form : A a A a A
두 개의 parse tree가 존재한다.
결과 string은 A a A a A로 똑같지만 다른 Parse Tree이다.
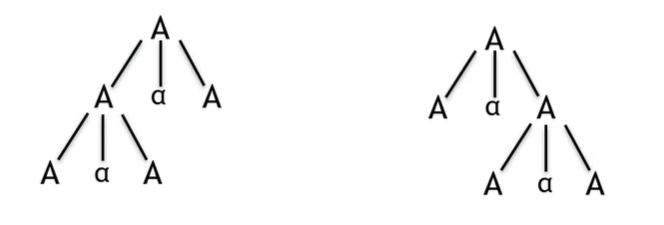
3) 그렇다면 어떻게 Ambiguous Grammer을 제거할 수 있을까?
➡️ Operatian Priority 를 주는 것이다.
* 에 + 보다 더 높은 priority를 제공하면 된다.
📌Example
Exp -> Exp + Exp
Exp -> Exp * Exp
Exp -> NUMPriority를 준 후
Exp -> Exp + T | T
T -> T * F | F
F -> NUM처음 적용할 production rule을 Exp -> Exp + Exp 으로 하거나 Exp -> Exp * Exp 할 수 있었는데,
Priority를 준 이후에는 Exp -> Exp + Exp 을 적용할 수 밖에 없다.Exp -> Exp + T -> T + T -> F + T -> NUM + T -> 1 + T
-> 1 + T F -> 1 + F F -> 1 + NUM F -> 1 + 2 F
-> 1 + 2 NUM -> 1 + 2 3이렇게 하면 처음에 Exp -> Exp + T를 선택할 수밖에 없다. 즉 2*3을 생성한 이후 1을 더하므로 Multiplication이 우선함으로써, 1 + (2*\3)의 결과가 생성된다.
✔️ 트리에서 Operator가 root node에서 멀어지면 멀어질수록 우선순위가 높아지는 것이다.(먼저 수행되는 것이다)
따라서 곱셈이 먼저 수행할 수밖에 없도록 production rule을 만들면, Ambiguous Grammer가 없도록 만들 수 있다.
3. Abstract Syntax Tree