
Mutation Based Fuzzing
좋은 입력을 만들어낼 수 있는 방법은, 프로그램의 주요 기능을 실행할 수 있게 하는 valid input을 변경해 가면서 하는 것이다.
🔔 핵심 구성요소
Seed Selection = seed를 고르는 기술. valid한 seed input 집합을 받는데, 이 중 변이를 가할 좋은 seed를 고르는 기술이다.
Seed Mutation = seed를 바꾸는 기술.
seed 입력을 변이하는 operator들 중 operator을 선택하여 변이하는 기술이다.

🌳 AFL의 동작방식
AFL 위에 매우 많은 Mutation based fuzzing 기술들이 구현되어 있다.
대표적 mutation fuzzing 기술 AFL의 동작 방식을 알아보자.
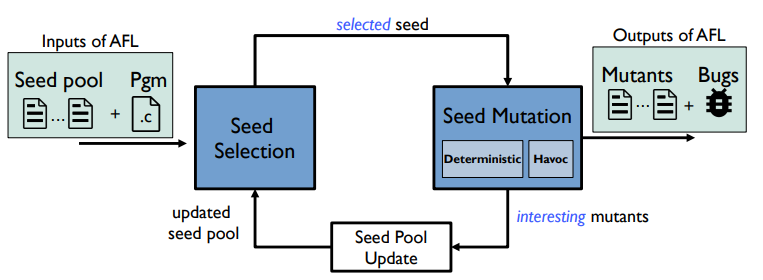
Seed pool가 program이 input으로 주어지면, seed selection이 seed를 고르고, seed mutation에서 두 스테이지를 거쳐서 interesting한 mutants를 만들어 낸다.
이를 통해 seed pool을 업데이트하고, seed selection을 다시 한다.
이 과정을 반복하는 것이 AFL의 동작 방식이다.
1. Seed Selection
1) 큐에 시드 풀의 시드들을 넣어둔다.
큐 맨 앞에 있는 것부터 꺼낸다.

2) Mutation에서 mutant가 만들어지면, checker가 interesting한 mutant인지 아닌지(새로운 코드를 실행하거나 오류를 발견할 수 있는지) 체크한다.
🔔 interesting한 mutant의 종류
(1) 그 input이 target program에 crash를 일으킨다.
(2) 그 input이 아직 커버되지 않은 새로운 path를 커버한다.
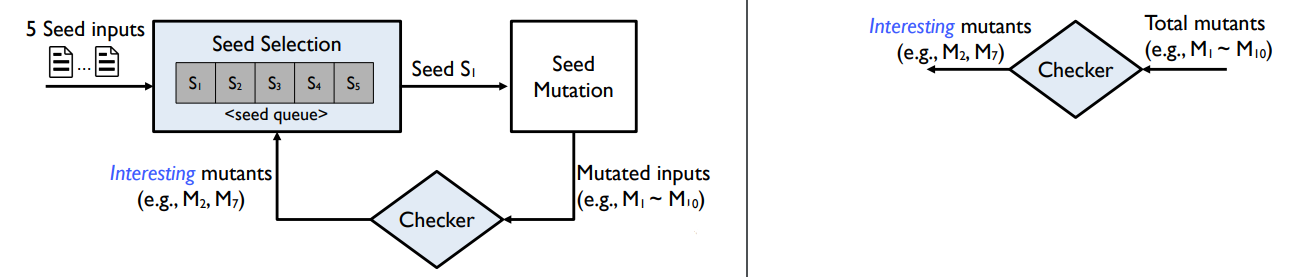
3) mutant 10개중 2번, 8번이 interesting할 경우 해당 seed queue 뒤에 넣는다.
그리고 seed selection이 queue의 시드를 sequential하게 고르고, mutation을 가하고, checker가 체크하면서 반복된다.
checker가 interesting mutant를 update하는 속도보다 seed selection 속도가 빠르면, 어느 순간에는 queue의 맨 끝 지점에 도달할 것이다. 즉 더 이상의 seed 입력이 없는 상황에서는 다시 처음 queue의 첫 지점부터 sequential하게 고른다.

2. Seed Mutation
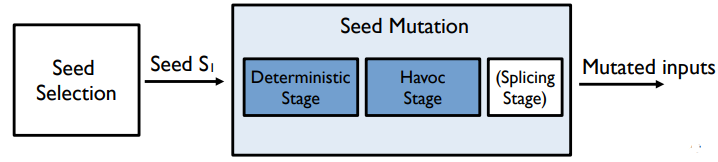
seed selection 단계에서 선택된 시드가 있을 때, 그 시드를 어떻게 바꾸어야지 더 많은 오류를 찾을 수 있을지 고민하는 것이다.
✔ Deterministic Stage
input에 변이를 가할 때, randomness가 없다.
하나의 mutation operator을 사용해서 시드 입력에 small change를 가한다.✔ Havoc Stage
Randomness를 강하게 변이를 가한다. 동일한 시드 입력이어도 만들어지는 시드 입력의 종류는 굉장히 다르다.
여러개의 mutation operator을 sequential하게 사용해서 시드 입력이 big change를 가한다.(+ Splicing Stage) :
앞서 interesting mutant를 만들어내지 못한다면 splicing stage가 켜져서 변이를 가하게 된다.
1) Deterministic Stage
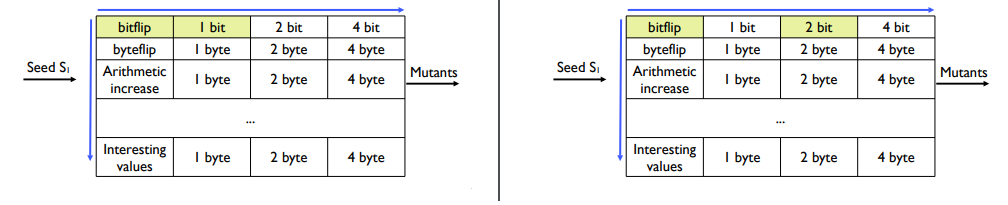
입력의 처음부터 끝까지 각 mutation operator을 하나하나 전부 적용해 본다.
operator =bit flip(1, 2, 4bit),byteflip(1,2,4byte),arithmeticinc/dec...
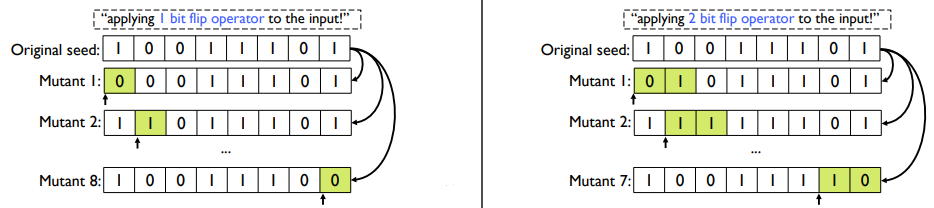
다음과 같이 1bit flip은 1bit 단위로 혹은 2bit 단위로 인덱스 하나하나 전부 적용하는 것이다.
이러한 방식으로 각각의 mutation operator들을 프로그램 입력의 첫 지점부터 끝 지점까지 적용하게 된다. 1bit flip 끝나면 2bit flip을 적용하고, 2bit flip 끝나면 4bit flip을 하게 되고 쭈욱 모든 operator들을 적용하여, mutant들을 만들게 된다.

2) Havoc Stage
operator의 n개를 '누적해서' 적용한다.
(1) 먼저 몇 개의 mutant를 만들어낼지 결정한다. -> m개
(2) 적용할 operator의 개수를 결정한다. -> n개
(3) operator을 고르고(어떻게 mutate할지), 그 개수에 seed 입력의 어느 위치에 적용할지 결정한다. 랜덤하게 고르는 과정이다.

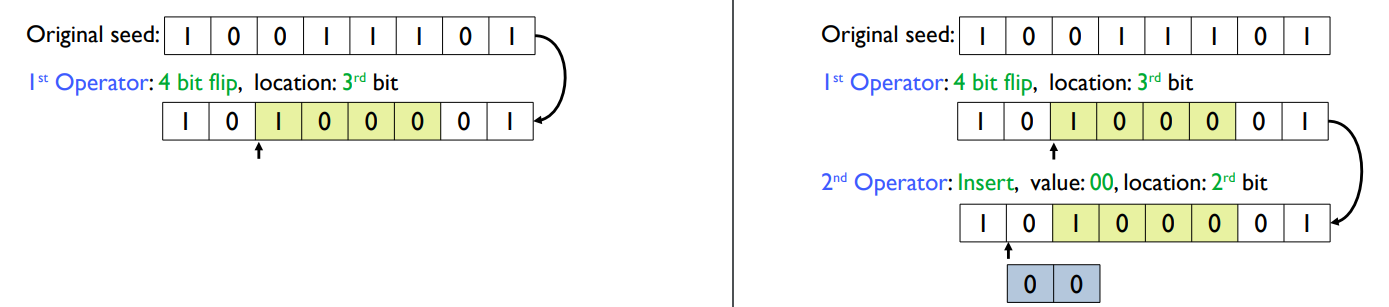
operator을 3개로 결정했다고 가정해 보자..
첫 번째 operator은 4bit lfip이고, 3rd bit부터를 location으로 결정하였다.
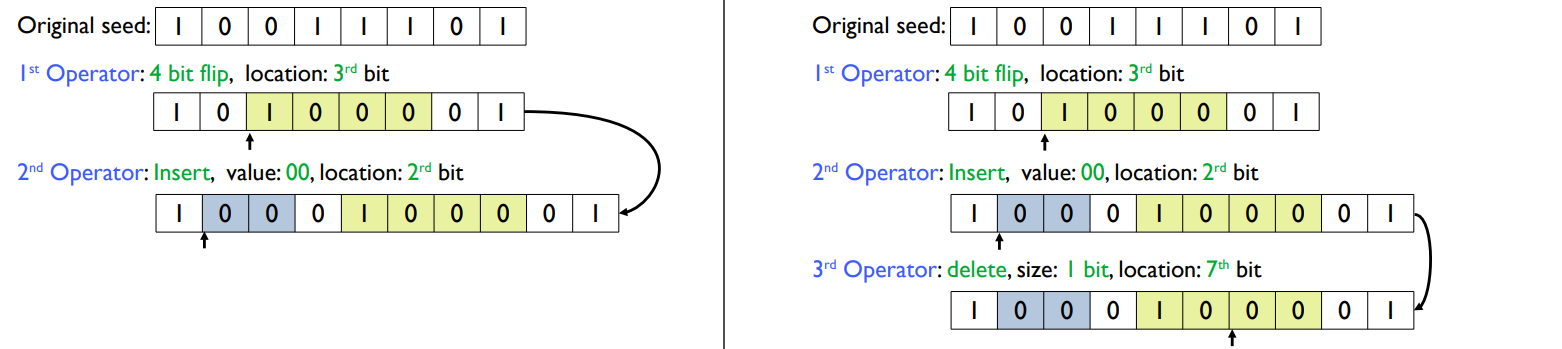
두 번쨰 operator는 누적하여 첫번째 operator의 결과값에, value 00을 insert하는데 그 위치는 2rd bit로 결정한다.
세 번째 operator는 delete operator로서, 7번째 위치에서 1 bit를 delete한다.
따라서 다음과 같이 변이를 많이 가한 입력을 만들어내게 된다.
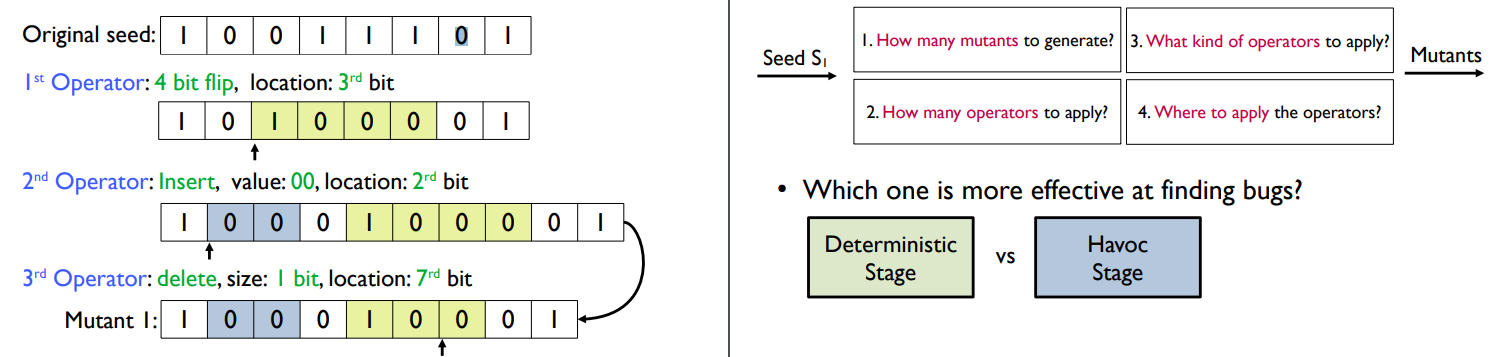
Havoc stage는 매우 많은 랜덤 스테이지를 가지고 있다.
얼마나 많은 mutant를 만들지,
mutant를 만들기 위해 얼마나 많은 operator를 적용할지,
어떤 종류의 operator을 적용할지,
어디에 operator을 적용할지
를 결정해야 한다!
두 스테이지 중 어떤 것이 오류를 찾는데 특화되어 있을까?!
-> Havoc stage가 훨씬 유용하다.
🔔 Mutation based Fuzzing 관련 연구들
Seed Pool Generation
시드 풀의 퀄리티를 높이기 위한 연구
Seed Selection
시드 풀로부터, 어떠한 시드부터 mutation을 가해야 하는지에 대한 연구
Seed Mutation
시드에 어떻게 변이를 가할지 결정하는 연구
