
📌 정렬
데이터를 특정한 기준에 따라서 순서대로 나열하는 것
-
정렬 알고리즘으로 데이터를 정렬하면 이진 탐색이 가능하다.
-
정렬 알고리즘은 굉장히 다양한데 선택 정렬, 삽입 정렬, 퀵 정렬, 계수 정렬이 대표적이다.
1️⃣ 선택정렬
무작위로 데이터가 있는데, 오름차순으로 정렬한다고 생각해 보자.
컴퓨터가 데이터를 정렬할 때, 가장 작은 데이터를 선택해 맨 앞의 데이터와 바꾸고, 그 다음 작은 데이터를 선택해 앞에서 두 번째 데이터와 바꾸는 과정을 반복하는 것이 '선택 정렬' 알고리즘이다.
💭 선택정렬 알고리즘 code
array = [5, 7, 3, 2, 1, 4, 6, 8, 10, 9]
for i in range(len(array)):
min_index = i
for j in range(i+1, len(array)):
if array[min_index] > array[j]:
min_index = j
array[i], array[min_index] = array[min_index], array[i] #swap
print(array)💭 선택정렬의 시간 복잡도
전체 수 n개에 대해서 비교 연산 n번을 수행하므로, O(N**2)이라고 할 수 있다.
따라서 데이터 개수가 100배 늘어나면 시간은 10000배 늘어난다. 즉 많아지면 많아질수록 정렬 속도가 급격히 느려진다. 따라서 알고리즘 문제 풀이 등에 이용되기에는 느린편이다.
2️⃣ 삽입정렬
삽입정렬은 특정한 데이터를 적절한 위치에 '삽입'하는 정렬이다.
삽입정렬은 첫 번째 데이터는 그 자체로 정렬 되어있다고 판단하고, 두 번째 데이터부터 정렬을 시작한다.
오름차순으로 정렬한다면, 첫 번째 데이터와 비교하여 자기보다 작으면 그 왼쪽에 삽입한다.
즉 전체 데이터에 대하여, 그 데이터 이전의 데이터들과 비교를 시작하고 자기보다 작은 값을 발견하면 멈추고 그 오른쪽에 삽입한다.
💭 삽입정렬 알고리즘 code
array = [5, 7, 3, 2, 1, 4, 6, 8, 10, 9]
for i in range(1, len(array)): # 0은 정렬된 상태. 1부터 n-1까지
for j in range(i, 0, -1): # i부터 1까지
if array[j-1] > array[j] :
array[j-1], array[j] = array[j], array[j-1]
else:
break # 자기보다 작은 데이터 만나면 멈춤
print(array)
💭 삽입정렬의 시간복잡도
삽입 정렬의 시간 복잡도는 O(N**2) 이다.
그러나 선택정렬은 현재 데이터 상태와 관계없이 무조건 모든 원소를 비교하는 반면, 삽입 정렬은 그렇지 않기 때문에 데이터가 거의 정렬되어 있는 상태라면 매우 빠르게 동작한다. 최선의 경우 O(N)의 시간 복잡도를 가진다.
보통은 비효율적이지만, 정렬이 거의 된 상태에선 퀵 정렬보다 강력하다.
3️⃣ 퀵 정렬
가장 많이 사용되며, 빠른 알고리즘
퀵 정렬에는 '피벗'이라는 개념이 있는데, "큰 숫자와 작은 숫자를 교환할 때 교환의 기준"을 의미한다.
피벗을 설정하는 방식에는 여러가지가 있는데, 대표적으로 '리스트의 첫 데이터를 피벗으로 설정'하는 방법이 있다.
사이즈가 N인 하나의 리스트 내의 특정 원소인 '피벗'을 기준으로, (1) 피버보다 작은 원소들과 큰 원소들을 좌우로 분리(파티션) 하여 두개의 서브 리스트를 구성한다. (2) 각 서브리스트를 재귀적 방식으로 퀵 정렬을 수행하여 정렬한 다음, (3) 두개의 정렬된 서브 리스트를 합하여 전체가 정렬된 리스트가 되게 하는 분할 정복 정렬 알고리즘이다.
리스트의 사이즈가 1인 경우 해당 리스트는 정렬된 것으로 간주한다. (= 종료조건)
💭 퀵 정렬 알고리즘 code
정석
array = [5, 7, 9, 0, 3, 1, 6, 2, 4, 8]
def quick_sort(array, start, end):
if start >= end: # 원소가 1개인 경우 종료
return
pivot = start # 피벗은 첫 번째 원소
left = start + 1
right = end
while (left <= right):
# 피벗보다 큰 데이터를 찾을 때까지 반복
while (left <= end and array[left] <= array[pivot]):
left += 1
# 피벗보다 작은 데이터를 찾을 때까지 반복
while (right > start and array[right] >= array[pivot]):
right -= 1
if (left > right): # 엇갈렸다면 작은 데이터와 피벗을 교체
array[right], array[pivot] = array[pivot], array[right]
else: # 엇갈리지 않았다면 작은 데이터와 큰 데이터를 교체
array[left], array[right] = array[right], array[left]
# 분할 이후 왼쪽 부분과 오른쪽 부분에서 각각 정렬 수행
quick_sort(array, start, right - 1)
quick_sort(array, right + 1, end)
quick_sort(array, 0, len(array) - 1)
print(array)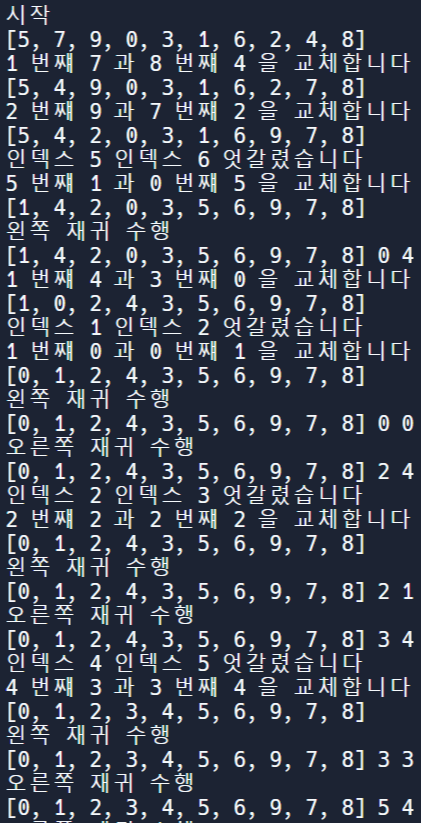
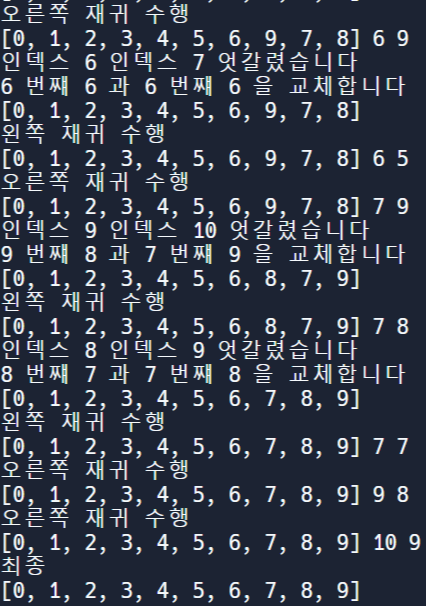
💭 퀵 정렬의 시간복잡도
퀵 정렬의 시간 복잡도는 O(NlogN)이다.
