
픽셀
이미지는 픽셀로 구성되어 있다. jpeg의 한 픽셀은 RGB 색상으로 표현된다. R, G, B 각각은 0~255 까지의 값으로 색이 표현되기 때문에, 1바이트로 표현할 수 있다. 따라서 한 픽셀은 3바이트로 표현된다.
jpeg로 이미지를 저장할 때, 파일 크기를 줄이기 위해 압축하여 저장한다. 파일 크기를 줄이는 이득을 얻음으로써 손해를 보는 것도 있을텐데, 압축 과정을 살펴보면서 어떤 트레이드 오프가 발생하는지 살펴보자.
손실 압축 알고리즘
jpeg에서 사용하는 압축 기법은 손실 압축 알고리즘의 한 종류로, 다음과 같은 과정을 거친다.
- 색 공간 변환(RGB → YCbCr)
- 다운샘플링
- DCT(Discrete Cosine Transform, 이산 코사인 변환)
- 양자화
- 지그재그 스캔
- 허프만 코딩
1. 색 공간 변환(RGB → YCbCr)
인간의 눈은 명도에 예민하지만, 색상 구분 능력은 상대적으로 떨어진다. 이는 아주 비슷한 서로 다른 두 색상을 동일한 색상으로 인지한다는 말이며, 색상에서 손실을 일으켜 압축한다면, 명도에서 손실이 나는 것과 비교했을 때, 색의 변화를 인지하기 어렵다는 의미이다.
RGB는 명도와 색상이 섞여있어서 색상에 대해서만 손실을 일으킬 수 없다. 그래서 명도와 색상을 분리할 수 있는 색 공간 중 YCbCr 색 공간으로 변환한다. Y, Cb, Cr의 의미는 다음과 같다.
- Y : 명도
- Cb : 초록색에 파란색이 섞인 정도
- Cr : 초록색에 빨간색이 섞인 정도
YCbCr로 분리하는 과정을 마치면, Y색 1장, Cb색 1장, Cr색 1장으로 분리된다. 각 장의 픽셀은 1가지 색만 나타내기 때문에 1바이트로 표현된다.
 | 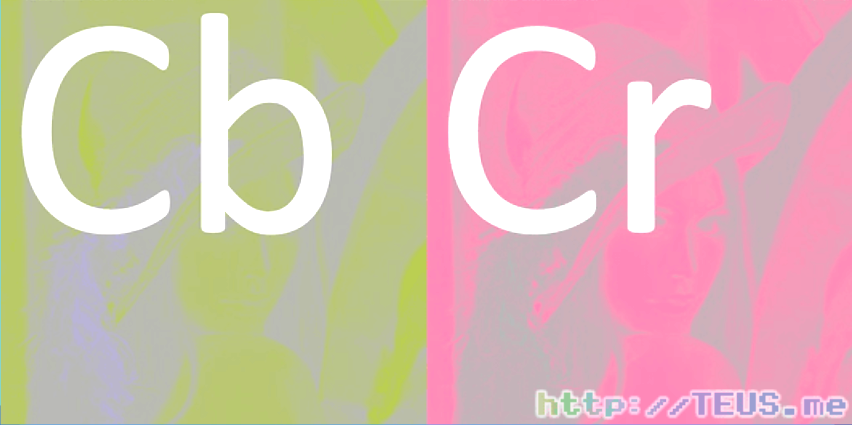 |
|---|
2. 다운샘플링
색상 정보인 Cb, Cr색에 손실을 일으켜 용량을 압축하는 것을 ‘다운샘플링’이라고 한다. 이 과정에서 Y색은 보존한다. 다운샘플링은 특정 크기의 픽셀 블럭을 잡아서 이루어지고, 행의 길이는 2로 고정이며, J:a:b의 비율로 이루어진다. J,a,b의 의미는 다음과 같다.
- J : 픽셀 블럭의 너비
- a : 첫번째 행에서 추출되는 샘플 개수
- b : 두번째 행에서 추출되는 샘플 개수
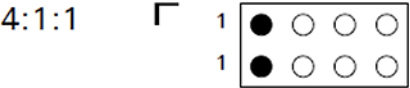
J:a:b 의 비율로는 4:4:4 / 4:4:0 / 4:2:2 / 4:2:0 / 4:1:1 / 4:1:0 등이 있다. 이 중, 이해를 위해 4:1:1 / 4:2:0 / 4:4:0을 예를 들어 설명하겠다.
 |  |
|---|
4:1:1 의 예시를 보면 행의 길이는 2(고정), J=4(열의 길이), a=1, b=1 이다. 따라서 2x4의 픽셀 블럭이 만들어진다. 1행의 1x4 픽셀 블럭을 전부 하나의 색상으로 통일하고 2행도 똑같이 적용한다. 이때 각 픽셀 블럭에 정해지는 색상은 픽셀 블럭 내의 평균, 중간값 등의 방법으로 대표값을 산출하여 지정한다.
 |  |
|---|
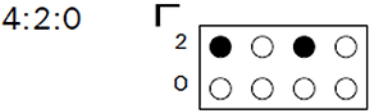
J=4, a=2, b=0 이다. 2x2 픽셀 블럭 + 2x2 픽셀 블럭으로 나뉘어 각각의 대표값으로 색상이 지정된다.
 |  |
|---|
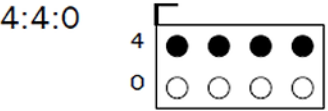
J=4, a=4, b=0 이다. 2x1 픽셀 블럭 4개로 나뉘어 각각의 대표값으로 색상이 지정된다.
jpeg는 4:2:0 으로 주로 다운샘플링이 진행되는데, 그 이유는 픽셀 블럭이 4:1:1 / 4:4:0 처럼 가로 세로의 비율이 맞지 않는 구조는 시각적 손실을 일으키기 때문에 피해야하고, 색상이 많이 손실될수록 압축에 유리하기 때문이다.
다운샘플링을 통해 색상에 손실이 발생하면, 다운샘플링 과정에서 잡힌 픽셀 블럭들이 각각 하나의 색으로 표현된다. 가령, 다운샘플링 이전에는 2x2의 픽셀 블럭의 4개 픽셀이 서로 다른 4개의 색상을 표현하므로 12바이트 용량이 필요했다. 그러나 다운샘플링 이후에는 2x2픽셀 블럭을 하나의 색상으로 표현하여 3바이트만 필요하게 되므로 용량이 줄어들게 된다.
3. DCT(이진 코사인 변환)
이미지에는 인간의 눈에 민감한 저주파 성분과 인감의 눈에 덜 민감한 고주파 성분이 있다.
- 저주파 성분 : 이미지에서 하늘이나 벽면처럼 단순한 형태
- 고주파 성분 : 이미지에서 머리카락, 잎맥, 텍스트의 경계처럼 복잡한 형태
마치 인간의 눈이 밝기엔 민감하고, 색상엔 덜 민감하여, 색상에 손실을 일으켰던 것처럼, 사람은 저주파 성분에 민감하고, 고주파 성분엔 덜 민감하기 때문에 주로 고주파 성분에 손실을 일으켜 용량을 압축할 수 있다. DCT는 고주파 성분을 손실시킬 수 있도록 [0,255]로 표현되는 색상을 주파수 값으로 표현하는 작업이다.
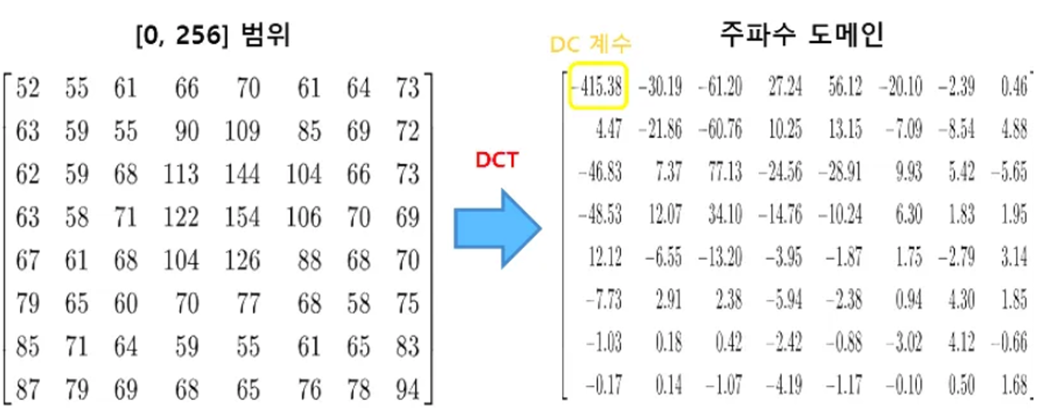
DCT 수행 결과인 주파수 도메인은 색상 정보를 구성하는 64가지 기저 패턴이 각각 얼마나 포함되어 있는지를 나타낸다. 64가지 패턴 중 좌측 상단에 있을수록 저주파에 속하고, 우측 하단에 있을 수록 고주파에 속하는데, 하단 좌측 사진의 64가지 기저 패턴을 주파수 도메인의 각 값에 대응시켜, 하단 우측 사진같은 8×8 픽셀 블록들을 표현할 수 있다.
 |
 |
|
DCT를 수행하고 나면, 좌측 사진과 주파수 도메인처럼 절대값이 큰 저주파 성분은 좌측 상단으로, 절대값이 작은 고주파 성분은 우측 하단으로 몰리게 된다. |
DCT를 수행하여 좌측 상단은 저주파 성분으로, 우측 하단은 고주파 성분으로 분리할 수 있었다.
4. 양자화
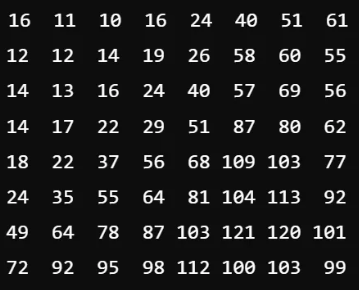
값을 근사화하는데 쓰이는 방법 중 하나는 나눗셈이다. 나눗셈을 통해 저주파와 고주파 값에 손실을 일으킬 수 있고, 이를 양자화라고 한다. 이때, 각 주파수 값을 나눌 수를 정해야하는데, 이는 양자화 테이블(8x8)에 정해져 있으며, 테이블 내의 값은 압축률에 따라 달라진다.
양자화에서는 사람의 눈에 덜 민감한 고주파 성분을 위주로 제거한다. 이를 위해 양자화 테이블은 고주파 성분을 제거하기 위한 값이 상대적으로 더 크게 구성되어 있다. DCT를 수행하면 중주파 성분들이 ↗ ↙ 방향으로 분포하게 되기 때문에 비슷한 값들이 나타난다. 이는 양자화 후에도 유지되며, 고주파 값들은 0에 가까운 값을, 저주파 값들은 상대적으로 높은 값을 갖게 된다.
아래 두 사진은 양자화 테이블, 양자화를 진행한 주파수 도메인 예시이다.
 |
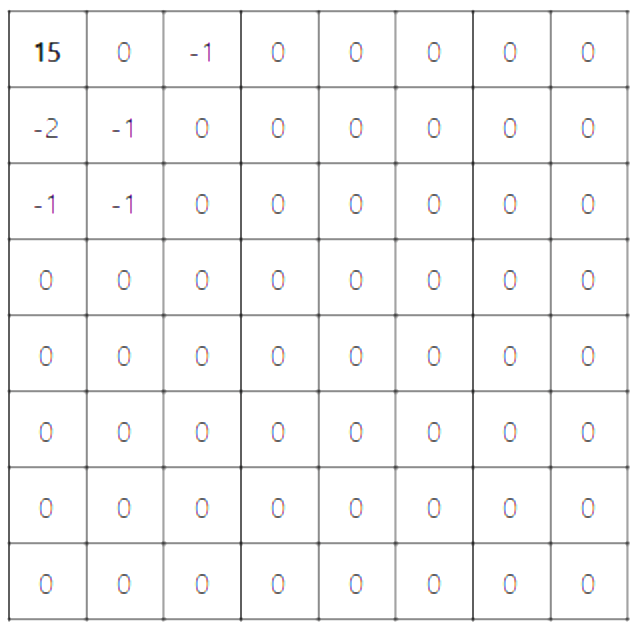 |
양자화를 거치면서, 주파수 값들이 작아졌기 때문에, 각 주파수의 값을 저장하는데 사용하는 비트의 수가 감소하여 용량이 줄어들었다.
5. 지그재그 스캔
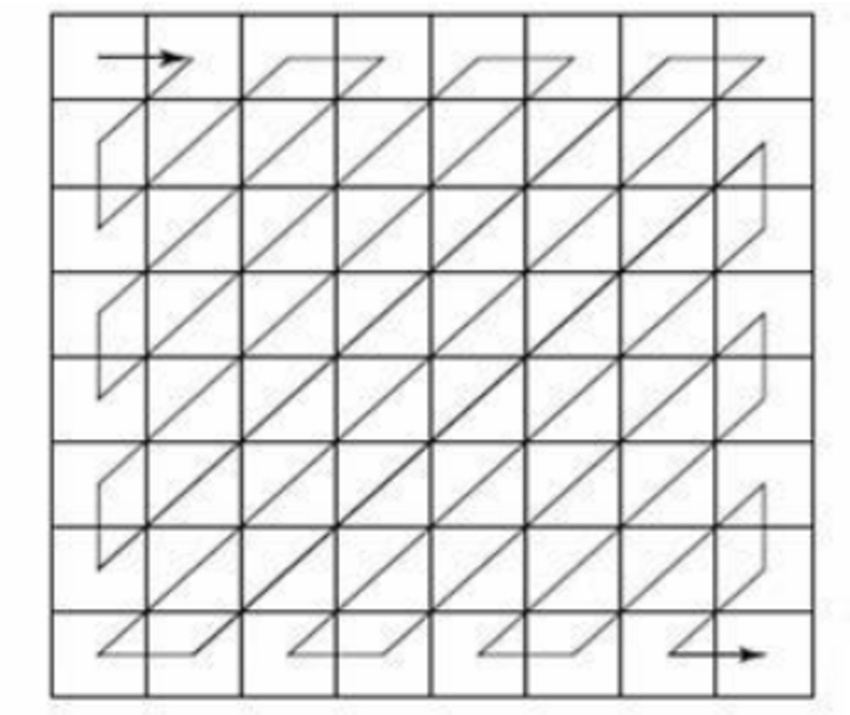
|
좌측의 사진처럼 값을 탐색하는 방법을 지그재그 스캔이라고 한다. 지그재그 스캔을 사용하는 경우 중 하나는 탐색 경로에 동일한 숫자가 연속적으로 놓여있을 때이다. DCT & 양자화를 수행한 경우가 그러하다. 고주파, 중주파, 저주파가 서로 분리되어 ↗ ↙ 방향으로 비슷한 값들끼리 인접하게 배치되므로, 지그재그 스캔을 사용하면, 동일한 값을 읽을 확률이 높아진다. |
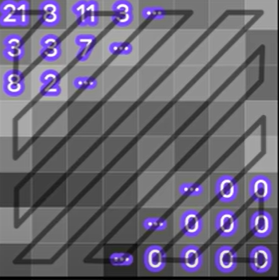
|
DCT & 양자화한 결과를 지그재그 스캔을 사용하여 탐색한 숫자들을 나열하면 21 3 3 3 8 3 11 3 7 2 … 0 0 0 0 0 0 0 과 같은 식으로 마지막에 0이 나열될 수 있다. 여기서 0 처럼 동일한 숫자가 연속될 경우, 이를 압축 시킬 수 있다. 가령, 마지막에 0이 연속적으로 15개 나왔다면 “0이 15개 있어요~” 라는 의미로 0#15처럼 표시하여 15개의 0을 한번에 표현하여 압축할 수 있다. 이로 인해 길이가 29인 “0 0 … 0”(15개의 0)문자열은 길이가 4인 “0#15” 로 압축된다. |
지그재그 스캔을 통해, 연속적으로 동일한 수를 압축하여 고주파 성분을 압축할 수 있었다.
6. 허프만 코딩
허프만 코딩이란 빈도가 높은 데이터에는 적은 비트를, 빈도가 낮은 데이터에는 많은 비트를 부여하여 기존 데이터를 압축하는 방식이다. 지그재그 스캔 후, 연속된 동일한 숫자를 x#y 처럼 압축하여 개별적으로 연속하는 수들은 압축시킬 수 있었다. 그러나, 문자열 전체 내에 존재하는 동일한 x#y 혹은 숫자들은 압축하지 못하였다. 따라서 압축 허프만 코딩을 통해 지그재그 스캔 후 미처 압축하지 못한 동일한 데이터를 압축할 수 있을 것이다.
가령, 지그재그 스캔으로 “3#2 8 3#2 11 3#2 7 0#3 1 0#3”과 같은 결과가 나왔다면, 허프만 코딩을 통해 여러 번 등장하는 데이터인 “3#2” 와 “0#3”을 추가적으로 압축할 수 있을 것이다.
| 3#2 | 8 | 11 | 7 | 0#3 | 1 |
|---|---|---|---|---|---|
| 3회 | 1회 | 1회 | 1회 | 2회 | 1회 |
위 문자열을 허프만 코딩을 통해 각각에 비트를 부여하면 아래 표와 같다.
| 3#2 | 8 | 11 | 7 | 0#3 | 1 |
|---|---|---|---|---|---|
| 11 | 011 | 010 | 001 | 10 | 000 |
이 표로 “3#2 8 3#2 11 3#2 7 0#3 1 0#3” (문자열) → 1101111010110011000010 (비트) 로 변환된다.
x#y 는
- x, y : ‘0’~’9’로 구성된 n자리 숫자 문자열 → n바이트
- # : 문자 → 1바이트
이므로 용량이 29바이트 → 22비트로 압축되었다.
이와 같이 지그재그 스캔하여 압축한 결과에 대해 전체 데이터의 빈도를 따진 후 허프만 코딩을 통해 비트로 변환하여 압축할 수 있었다.
결론
지금까지 JPEG가 압축되는 과정을 살펴보았으며, 85%의 압축률로 손실 압축 과정을 거쳤을 때, 압축 결과는 아래와 같은 정도로 압축 되는 것을 알 수 있었다.
| 원본 | 이전 용량 | 압축본 | 압축 후 용량 | 용량 압축률 | |
|---|---|---|---|---|---|
| tiger.png | 6.19MB | ⇒ | tiger 85%.jpeg | 320KB | 약 94.8% |
| leaf.png | 3.80MB | ⇒ | leaf 85%.jpeg | 331KB | 약 91.3% |
| cat.png | 607KB | ⇒ | cat 85%.jpeg | 78.9KB | 약 87% |
압축은 다운샘플링, 양자화, 지그재그 스캔, 허프만 코딩 단계에서 일어난다. 이 중 지그재그 스캔과 허프만 코딩은 주어진 데이터에서 중복된 데이터를 짧게 표현하는 과정이므로 소멸되는 정보 없이 압축된다.
하지만 다운샘플링과 양자화는 다르다. 다운샘플링은 픽셀 블럭 내에 있는 픽셀들의 색상이 하나의 색상으로 통일되면서 기존의 픽셀들이 가지던 색상이 변질되면서 압축된다. 양자화는 값을 근사화시키면서 생기는 나머지들을 버리면서 기존에 이미지가 가지고 있던 데이터의 일부가 소멸되면서 압축된다.
DCT를 통해 색상 값을 주파수로 변환하고 후에 압축하는데 사용하는 것처럼, 압축된 것을 다시 이미지로 보려면 복원하는 과정이 필요한데, 이때 필요한 복원 과정 중 하나가 주파수 값을 색상 값으로 변환하는 작업이다. 그러므로, 주파수에 손실이 발생하면 복원하는 색상에도 손실이 발생하게 된다.
이로 인해, 단색 이미지는 다운샘플링에서는 색상이 변질되지 않지만, 양자화에서 색 손실이 발생한다. 반면, 호랑이 수염처럼 복잡한 패턴을 지닌 이미지는 다운샘플링과 양자화 과정에서 손실이 발생한다. 그러므로 이미지 압축 시, 복잡한 이미지는 손실된 변화가 빠르게 드러날 것이고, 단색 이미지는 손실된 변화가 천천히 드러날 것이다.
변화가 눈에 드러나는 압축률은 이미지마다 다르지만, 경우에 따라 작은 변화에도 민감할 수 있으므로, .jpeg로 압축 시, 여러 경우를 정보 손실에 유의하며 압축률을 정해야 할 것이다.
