
이 기세를 몰아 ... 더 풀어보기
1. 내 풀이
import sys
input = sys.stdin.readline
n, m = list(map(int, input().split()))
s = []
def dfs():
if len(s) == m:
print(' '.join(map(str, s)))
return
for i in range(1, n+1):
if (i not in s):
if len(s) == 0:
s.append(i)
dfs()
s.pop()
else:
for k in range(len(s)-1, len(s)):
if s[k] < i:
s.append(i)
dfs()
s.pop()
dfs()이전에 풀었던 거에서 쪼오끔 더 바뀐 거라서 쉽게 풀 수 있을 거라고 생각했지만 ... 아니었다 !!!
좀 걸렸음 ㅋㅋ... 개념은 비슷하다.
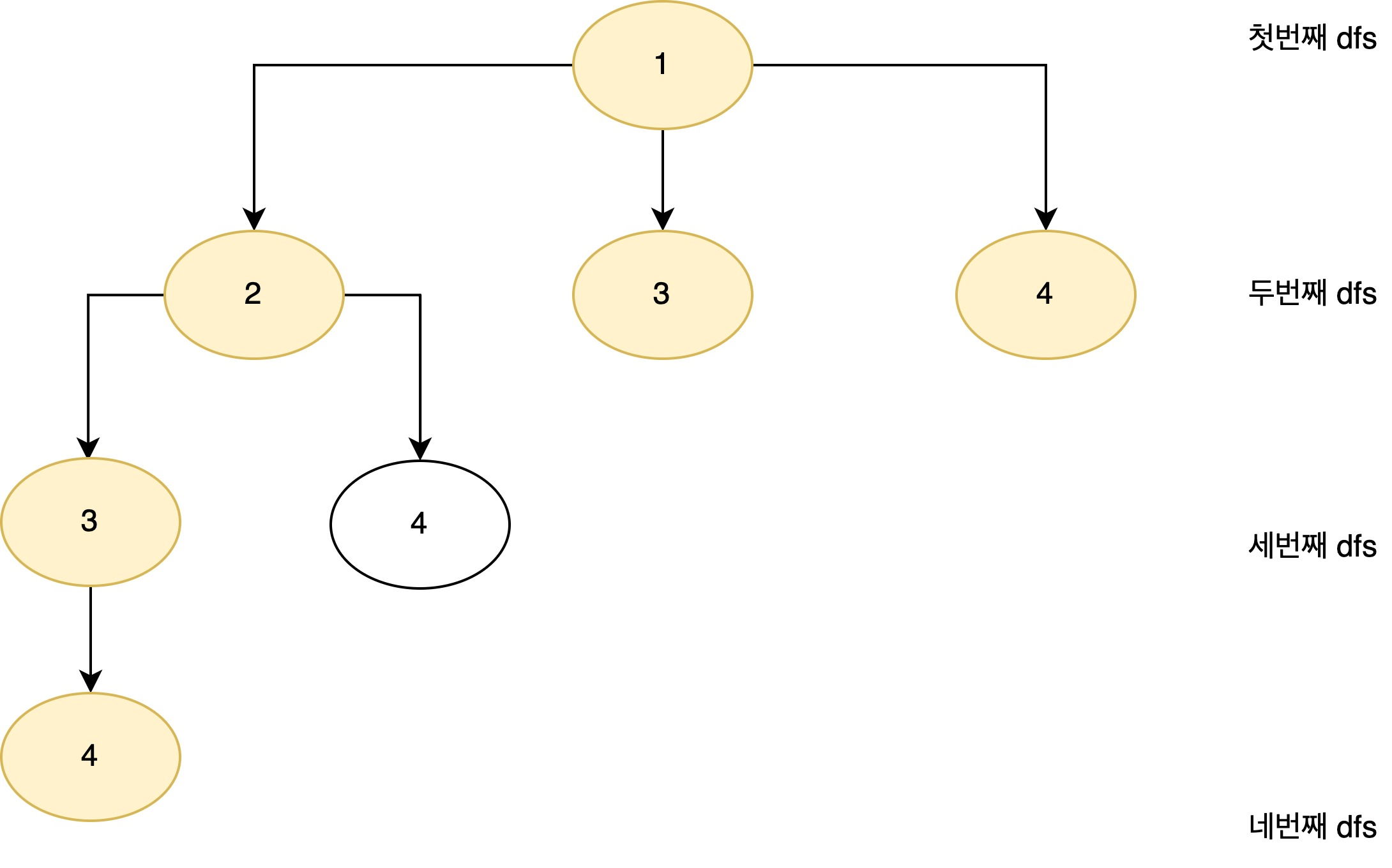
이전에는 모든 노드를 돌면서 중복되지 않은 수열을 추출하는 것이었다면, 이번에는 오름차순으로 된 모든 노드의 수열을 뽑는 것이다.
이전 노드값을 어떻게 가지고 올지 계속 고민 했던 게 문제였다.
2. 다른 풀이
n,m = list(map(int,input().split()))
s = []
def dfs(start):
if len(s)==m:
print(' '.join(map(str,s)))
return
for i in range(start,n+1):
if i not in s:
s.append(i)
dfs(i+1)
s.pop()
dfs(1)풀이 출처: https://jiwon-coding.tistory.com/22
이렇게 간단하게 풀 수 있는 것이었다니 !!! 단순히 start 변수만을 이용해서 오름차순이 가능하도록 하였다 ...
와우 지니어스 ...
3. 마치며
너무 꼬아서 생각하지말고 dfs의 본질을 생각할 수 있도록 해야겠다.

정말 알아?