뭐? TIL은 ML 팀블로그 쓸 때만 쓰는 거 아니냐고?
네... 맞는 거 같습니다... 매일 프로그래머스 5~10문제 풀다보니까 오답노트 쓰기가 귀찮아짐 <- 공부 안하는 사람들 특징
앞으로는 매일은 아니더라도 일주일만에 돌아오는 일은 없도록...
그리고 생각한 것은 TIL은 뭔가 나한테 설명하는 느낌(?)으로 진행하기로 했다. 왜냐면 이유는 없음.
오늘 할 내용은 바로 비지도 학습의 군집!
군집은 데이터셋을 cluster라는 그룹으로 나누는 작업. -> 한 cluster 안의 데이터 포인트끼리는 매우 비슷! 다른 cluster의 데이터 포인트와는 구분!
이 설명을 들으니 군집표본추출이 생각남... 근데 의미상 층화표본추출과 비슷하다. (군집표본추출은 군집끼리는 비슷하고 내부는 이질적이니까. 층화표본추출은 반대임.)
1. k-평균 군집 (3.5.1)
1. 특징
-
가장 간단하고 널리 사용하는 군집 알고리즘
-
데이터의 어떤 영역을 대표하는 cluster center를 찾음
-
두 단계 반복
-
데이터 포인트를 가장 가까운 cluster center에 할당
-
cluster에 할당된 데이터 포인트의 평균으로 cluster center을 다시 지정
-
cluster에 할당되는 데이터 포인트에 변화가 없을 때 알고리즘 종료
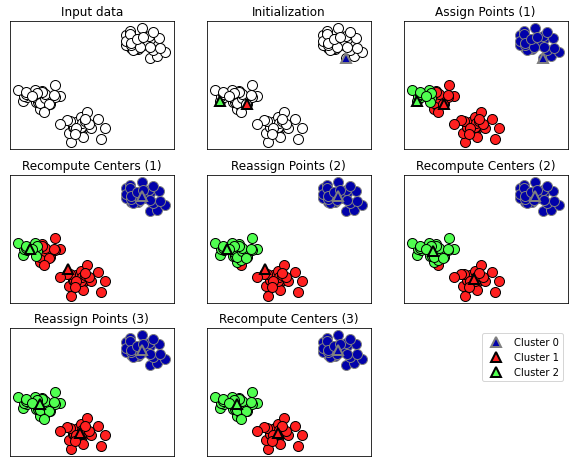 Input data: 데이터 포인트 입력
Input data: 데이터 포인트 입력
Initialization: 3개의 cluster를 찾도록 지정 -> cluster center로 삼을 데이터 포인트 3개를 무작위로 지정
Assign Points(1): 알고리즘 반복. 각 데이터 포인트를 가장 가까운 cluster center에 할당
Recompute Centers(1): 할당된 포인트의 평균값으로 cluster center 갱신
Reassgn Points ~ Recompute Center 반복
Recompute Center (3): cluter center에 할당되는 포인트에 변화가 없으므로 알고리즘 STOP!
-
from sklearn.cluster import KMeans
Kmeans = KMeans(n_cluster = 3)- 3개의 cluster를 지정했기 때문에 레이블은 0~2
- predict 메소드를 사용하면 새로운 데이터의 cluster lable을 예측 (훈련 세트에 대한 predict 메소드는 labels_와 같은 결과)
- 분류와 비슷해보이지만 lable 자체에 의미가 없음
2. 실패하는 경우
- cluter 개수를 정확히 알고 있더라도 k-평균 알고리즘이 항상 리를 구분해낼 수 있는 것은 아님
- cluster를 정의하는 것 = 중심 하나 -> cluster는 둥근 형태로 나타날 수 밖에 없음
- cluster의 반경이 모두 똑같다고 가정 = 이상치(극단치)까지 포함하는 사태 발생
- cluster에서 모든 방향이 똑같이 중요하다고 가정 -> 원형이 아닌 cluster는 구분하지 못함
(아래처럼 + two moons와 같은 형태면 .... 말잇못)
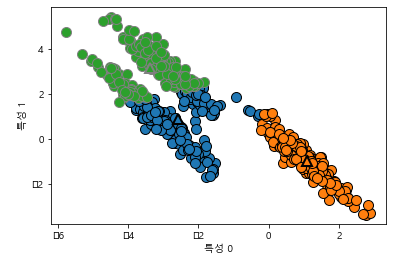
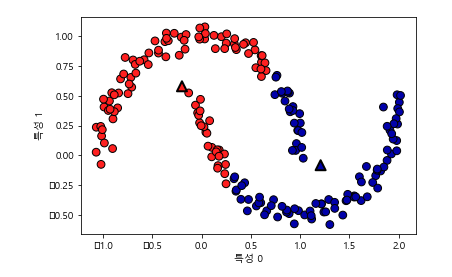
- PCA, NMF (데이터 포인트를 어떤 성분의 합으로 표현) 와는 다르게 하나의 값(중심)으로 각 데이터 포인트들을 표현 -> 벡터 양자화
그래서 two_moons와 같은 데이터를 흥미롭게 표현할 수 있음
X, y = make_moons(n_samples = 200, noise = 0.05, random_state = 0)
Kmeans = KMeans(n_cluster=10, random_State = 0)
Kmeans.fit(X)
y_pred = kmeans.predict(X)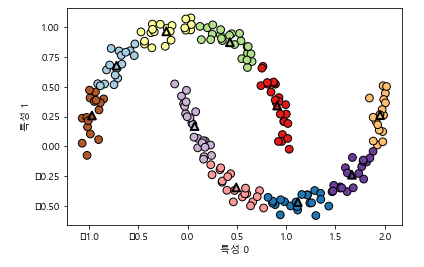
- 원래 특성 2개로는 불가능 했지만 10차원 데이터로 만들어 선형 분석이 가능해짐
3. 단점
- 무작위 초기화를 사용해서 알고리즘의 출력이 난수 초깃값에 따라 달라짐
- cluster 모양을 가정하고 있어 활용 범위가 비교적 제한적
- 찾으려는 cluter의 개수를 지정 (실제로는 알 수가 없지....)
2. 병합 군집 (3.5.2)
1. 특징
- 각 포인트를 하나의 cluster로 지정
- 어떤 종료 조건을 만족할 때까지 가장 비슷한 cluster를 합쳐 나감
1. ward: 기본값, 모든 cluster 내의 분산을 가장 작게 증가시키는 두 cluster를 합침
2. average: cluster 포인트들 사이의 평균 거리가 가장 짧은 두 cluster를 합침
3. complete: cluster 포인트 사이의 최대 거리가 가장 짧은 두 cluster를 합침
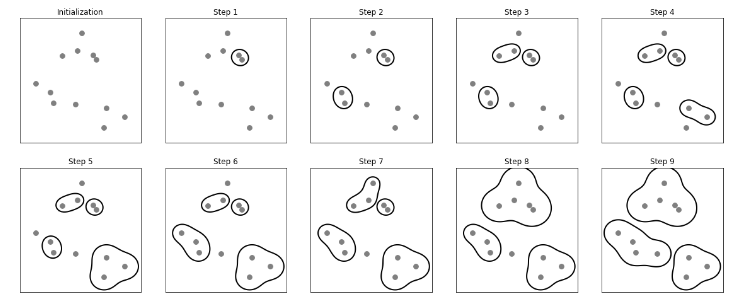
from sklearn.cluster import AgglomerativeClustering- scikit-learn의 병합 군집 모델을 사용하려면 찾을 cluster의 개수 지정
- 병합 군집이 적절한 개수를 선택하는 데 도움을 주기도 함!
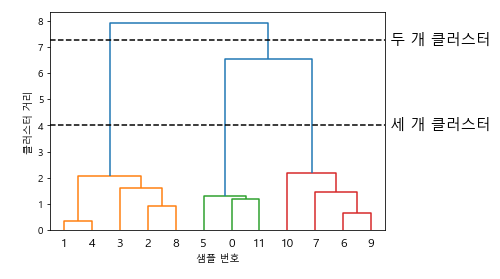
2. 계층적 군집과 덴드로그램
- 계층적 군집
: 병합 군집이 만드는 것 (군집이 반복하여 진행되면 모든 포인트는 하나의 포인트를 가진 clsuter에서 시작하여 마지막 cluster까지 이동)
- 2차원 데이터일 때만 계층 군집의 모습을 자세히 나타낼 수 있음
- 특성이 셋 이상인 데이터셋에는 사용할 수 없음
- 덴드로그램
: 다차원 데이터를 처리할 수 있음
- scikit-learn은 덴드로그램을 그리는 기능을 제공하지 않음 -> SciPy 군집 알고리즘을 통해 그릴 수 있음
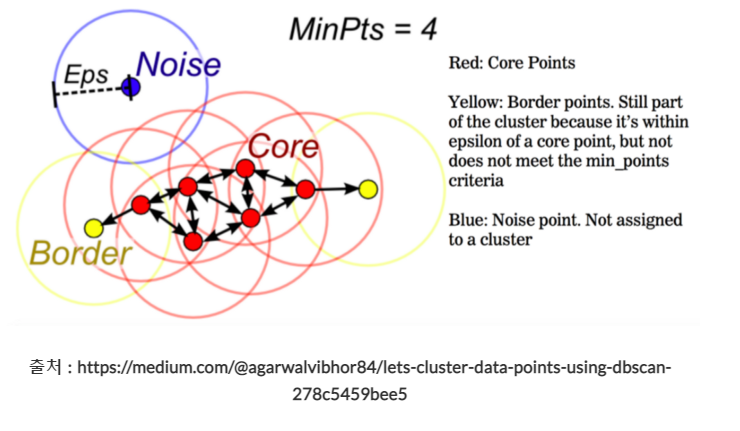
3. DBSCAN (3.5.3)
: 아~~주 유용한 군집 알고리즘
cluster의 개수를 미리 지정할 필요가 없음!!!!!!
- 다만.... 병합군집이나 k-평균보다 느림.....
- 큰 데이터셋에도 적용 가능
from sklearn.cluster import DBSCAN
4. 군집 알고리즘의 비교와 평가 (3.5.4)
- 어려운 점: 알고리즘이 잘 작동하는지 평가하거나 여러 알고리즘의 출력을 비교하기...
1. 타깃 값으로 군집 평가하기
: 군집 알고리즘의 결과를 실제 정답 cluster와 비교하여 평가할 수 있는 지표들이 있음
바로바로 1(최적)과 0(무작위 분류) 사이의 값을 제공하는 ARI와 NMI
2. 타깃 값 없이 군집 평가 하기
: 군집 알고리즘을 적용할 때 보통 그 결과와 비교할 타깃 값이 없음...
