
1. U-Net이란?
U-Net은 그 형태가 U자 형태로 이루어진 모델로, 인코더-디코더 형태를 가지고 있다.
- 인코더: 입력받은 이미지를 CNN을 이용해 특징 추출
- 이미지의 크기는 축소 + 정보 압축
- 디코더: 압축된 정보가 복원되어 입력과 같은 크기의 출력을 가짐
- 업샘플링 과정(Transeposed CNN): 커널을 이용해 특징으로 이미지를 복원하는 연산 ➡️ 이미지의 크기를 키움
- 업샘플링은 (하나의 픽셀 * 커널의 가중치)의 합으로 이루어짐
- 업샘플링 할 때 겹치는 영역은 더해주면서 최종 출력을 계산함
- 복원된 특징은 합성곱을 통해 추출된 특징과 합쳐짐
- 이미지의 특징을 뽑아내자! = Convolution
- 이미지를 복원하자! = Upsampling
U-Net의 활용
- 이미지 깊이 추정
- Segmentation
- Denosing
2. 데이터를 살펴보자
이번에 사용할 데이터는 Oxford-IIIT Pet 데이터셋으로, 고양이와 강아지 이미지가 약 7,000장 들어있다. 원본 RGB 이미지와 배경, 경계, 동물 픽셀을 구분하는 타겟 이미지가 한 쌍으로 제공된다.
아래의 코드를 이용해 실제 데이터를 보면 이와 같다.

import matplotlib.pyplot as plt
from PIL import Image
path_to_annotation = "annotatioin의 경로" # ground truth
path_to_image = "images의 경로" # 실제 이미지
# 이미지 불러오기
annotation = Image.open(path_to_annotation + "Abyssinian_1.png") # open: 경로를 읽어 PIL 객체로 저장
plt.subplot(1,2,1)
plt.title("annotation")
plt.imshow(annotation)
image = Image.open(path_to_image + "Abyssinian_1.jpg")
plt.subplot(1,2,1)
plt.title("image")
plt.imshow(image)
plt.show()여기서 Image.open은 경로의 이미지를 읽어 PIL 객체로 저장하는 역할을 한다. PIL(Python Imaging Library)이란, 파이썬에서 이미지 분석을 쉽게 하기 위해 사용하는 라이브러리이다. 여기서 사용할 수 있도록 이미지를 변환하는 것이라 보면 된다. (이름 참 단순하게도 지어놨다 ...)
3. 학습용 데이터 만들기
위 데이터를 이용해서 학습할 수 있도록 Dataset을 만들어보자. 먼저 Dataset의 init 함수부터 살펴보면,
import glob
import torch
import numpy as np
from torch.utils.data.dataset import Dataset
from PIL import Image
class Pets(Dataset)
def __init__(self, path_to_img,
path_to_anno,
train=True,
transforms=None,
input_size=(128,128)):
# 정렬
self.images = sorted(glob.glob(path_to_img+"/*.jpg"))
self.annotations = sorted(glob.glob(path_to_anno+"/*.png"))
# 데이터셋 나누기 (80% 학습, 20% test)
self.X_train = self.images[:int(0.8*len(self.images))]
self.X_test = self.images[:int(0.8*len(self.images))]
self.Y_train = self.annotations[int(0.8*len(self.annotations)):]
self.X_train = self.annotations[int(0.8*len(self.annotations)):]
self.train = train
self.transforms = transforms
self.input_size = input_size
def __len__(self):
if self.train:
return len(self.X_train)
else:
return len(self.X_test)
def preprocess_mask(self, mask):
mask = mask.resize(self.input_size)
mask = np.array(mask).astype(np.float32)
mask[mask!=2.0] = 1.0
mask[mask==1.0] = 0.0
mask = torch.tensor(mask)
return mask
def __getitem__(self, i):
if self.train:
X_train = Image.open(self.X_train[i])
X_train = self.transforms(X_train)
Y_train = Image.open(self.Y_train[i])
Y_train = self.preprocess_mask(Y_train)
return X_train, Y_train
else:
X_test = Image.open(self.X_test[i])
X_test = self.transforms(X_test)
Y_test= Image.open(self.Y_test[i])
Y_test = self.preprocess_mask(Y_test)
return X_test, Y_test첫 번째 정렬을 신경 써야 한다. 내가 사용하는 데이터 폴더에는 서로 다른 폴더에 데이터쌍이 들어있는데, 이름은 동일하여 sorted로 정렬을 해주도록 하였다.
두 번째는 학습 난이도를 낮추기 위해 타켓을 살짝 수정하는 것이다. 2번에서 ground truth를 보면, 경계와 동물이 따로 나뉘어져있는 것을 확인할 수 있다. 이렇게 되면 모델은 배경, 경계, 동물의 형태를 모두 맞춰야 한다. 이게 난이도가 있으니, 조금 수정하는 것이다. 경계를 동물의 영역으로 보아 총 배경, 동물의 두 라벨을 갖도록 만든다.
4. 모델 정의하기
U-Net 모델에서는
- 인코더: Conv2D() 사용
- 디코더: ConvTranspose2D() 사용
이를 통해 특징을 추출하거나 업샘플링을 진행한다.
추가로 주의해야 할 부분은 바로 최종 출력 부분인데, 지금 내가 하려고 하는 태스크의 출력은 0과 1 사이의 값을 갖는 1채널의 이미지이다. 여기서 squeeze를 이용해 이를 없애주어야 하는데 없애주는 이유는 조금 더 찾아보아야 할 것 같다 ...!
U-Net은 아래와 같은 기본 블럭 5개를 거치게 된다.
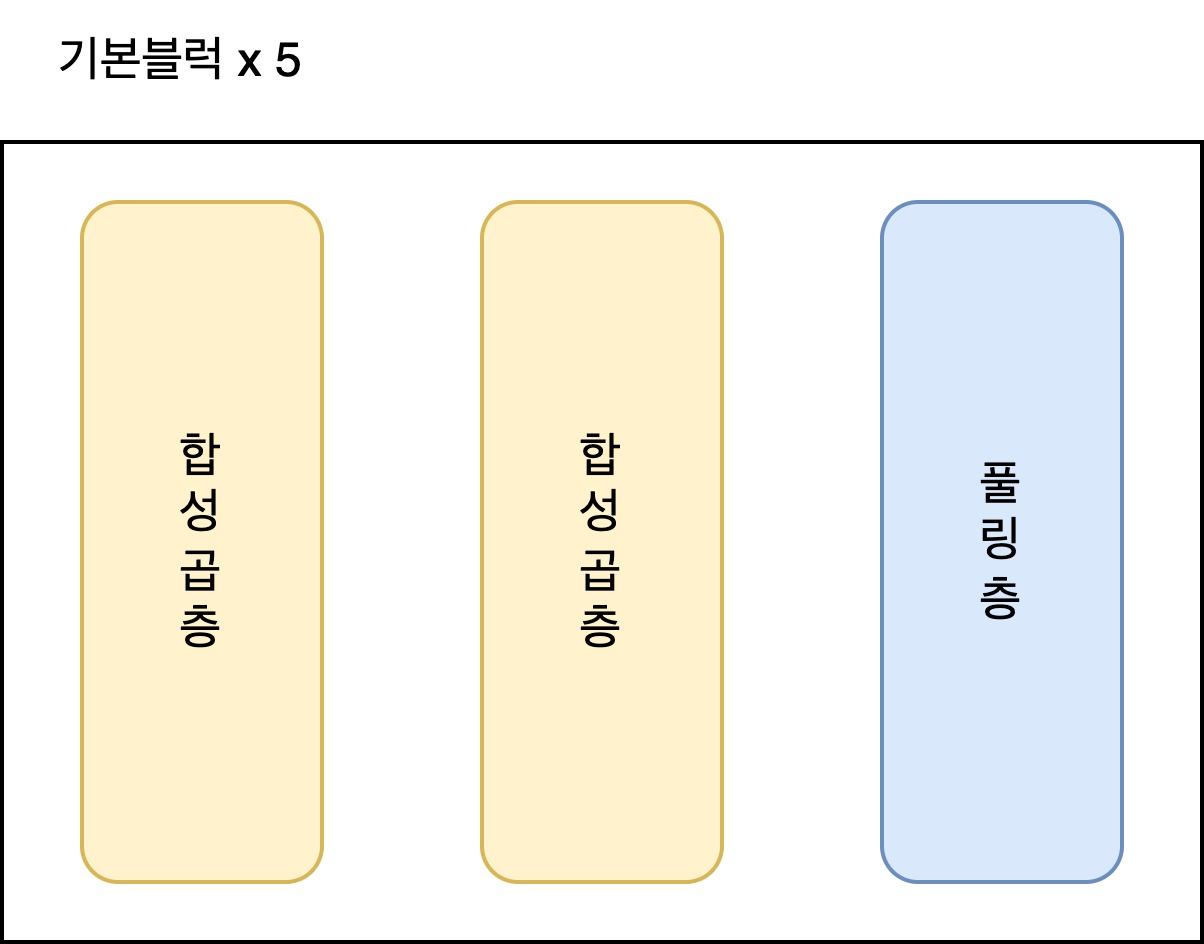
이때 마지막 5번째 블럭의 풀링은 진행하지 않는다. 그 이유는 디코더에서 복원할 때 정보의 손실이 일어나기 때문이다!
인코더 코드는 다음과 같다.
import torch.nn as nn
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
self.enc1_1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.enc1_2 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.enc2_1 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.enc2_2 = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.enc3_1 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
self.enc3_2 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2)
self.enc4_1 = nn.Conv2d(256, 512, kernel_size=3, padding=1)
self.enc4_2 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.enc5_1 = nn.Conv2d(512, 1024, kernel_size=3, padding=1)
self.enc5_2 = nn.Conv2d(1024, 512, kernel_size=3, padding=1)자 이제! 디코더를 정의해보자. 디코더는 인코더와 대칭 되는 아키텍처를 가지고 있다.
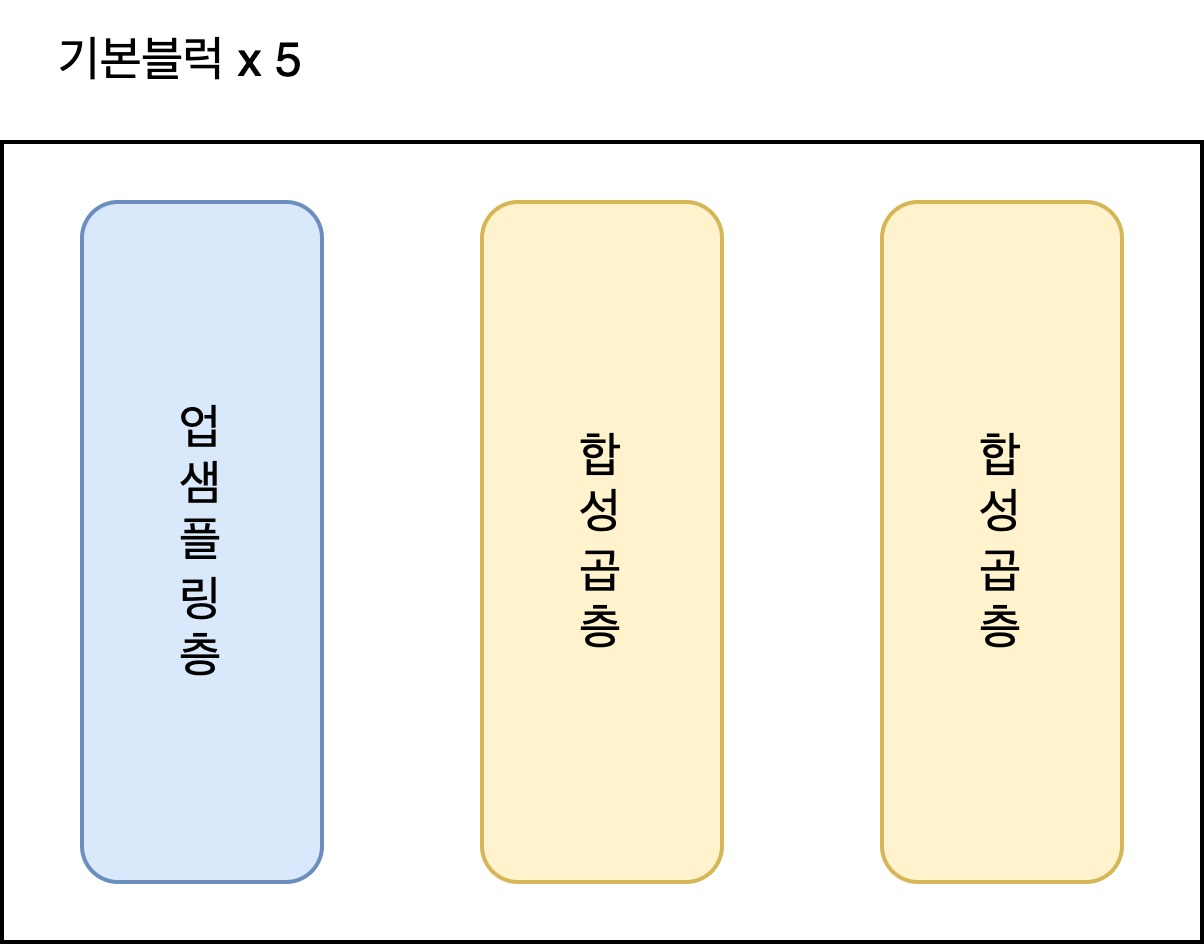
인코더의 풀링층의 자리가 첫번째 레이어로 바뀌고, 업샘플링층이 자리하게 된다. 코드는 다음과 같다.
self.upsample4 = nn.ConvTranspose2d(512, 512, 2, stride=2)
self.dec4_1 = nn.Conv2d(1024, 512, kernel_size=3, padding=1)
self.dec4_2 = nn.Conv2d(512, 256, kernel_size=3, padding=1)
self.upsample3 = nn.ConvTranspose2d(256, 256, 2, stride=2)
self.dec3_1 = nn.Conv2d(512, 256, kernel_size=3, padding=1)
self.dec3_2 = nn.Conv2d(256, 128, kernel_size=3, padding=1)
self.upsample2 = nn.ConvTranspose2d(128, 128, 2, stride=2)
self.dec2_1 = nn.Conv2d(256, 128, kernel_size=3, padding=1)
self.dec2_2 = nn.Conv2d(128, 64, kernel_size=3, padding=1)
self.upsample1 = nn.ConvTranspose2d(64, 64, 2, stride=2)
self.dec1_1 = nn.Conv2d(128, 64, kernel_size=3, padding=1)
self.dec1_2 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.dec1_3 = nn.Conv2d(64, 1, kernel_size=1)
self.relu = nn.ReLU()이제 forward propagation을 정의해보자.
def forward(self, x):
# encoder의 forward 정의
x = self.enc1_1(x)
x = self.relu(x)
e1 = self.enc1_2(x)
e1 = self.relu(e1)
x = self.pool1(e1)
x = self.enc2_1(x)
x = self.relu(x)
e2 = self.enc2_2(x)
e2 = self.relu(e2)
x = self.pool2(e2)
x = self.enc3_1(x)
x = self.relu(x)
e3 = self.enc3_2(x)
e3 = self.relu(e3)
x = self.pool3(e3)
x = self.enc4_1(x)
x = self.relu(x)
e4 = self.enc4_2(x)
e4 = self.relu(e4)
x = self.pool4(e4)
x = self.enc5_1(x)
x = self.relu(x)
x = self.enc5_2(x)
x = self.relu(x)
# decoder의 forward 정의
x = self.upsample4(x)
x = torch.cat([x, e4], dim=1)
x = self.dec4_1(x)
x = self.relu(x)
x = self.dec4_2(x)
x = self.relu(x)
x = self.upsample3(x)
x = torch.cat([x, e3], dim=1)
x = self.dec3_1(x)
x = self.relu(x)
x = self.dec3_2(x)
x = self.relu(x)
x = self.upsample2(x)
x = torch.cat([x, e2], dim=1)
x = self.dec2_1(x)
x = self.relu(x)
x = self.dec2_2(x)
x = self.relu(x)
x = self.upsample1(x)
x = torch.cat([x, e1], dim=1)
x = self.dec1_1(x)
x = self.relu(x)
x = self.dec1_2(x)
x = self.relu(x)
x = self.dec1_3(x)
x = self.relu(x)
x = torch.squeeze(x)
return x5. 모델 학습하기
학습 루프는 언제나 그렇듯 유사하다. 이번에 쓸 loss function은 BCEWithLogitsLoss()이다. 처음 보는 loss function임 ...
BCE (Binary Cross Entropy) 는 이름에서 알 수 있듯이 이진분류 사용하는 Cross Entropy이다.
코드는 아래와 같다.
import tqdm
from torchvision.transforms import Compose
from torchvision.transforms import ToTensor, Resize
from torch.optim.adam import Adam
from torch.utils.data.dataloader import DataLoader
device = "cuda" if torch.cuda.is_available() else "cpu"
transform = Compose([
Resize((128,128)),
ToTensor()
])
train_set = Pets(path_to_img = path_to_image,
path_to_anno= path_to_annotation,
transforms = transform)
test_set = Pets(path_to_img = path_to_image,
path_to_anno= path_to_annotation,
transforms = transform,
train=False)
train_loader = DataLoader(train_set, batch_size=32, shuffle=True)
test_loader = DataLoader(test_set)
model = UNet().to(device)
learning_rate = 0.0001
optim = Adam(params=model.parameters(), lr = learning_rate)
for epoch in range(200):
iterator = tqdm.tqdm(train_loader)
for data, label in iterator:
optim.zero_grad()
preds = model(data.to(device))
loss = nn.BCEWithLogitsLoss()(
preds, label.type(torch.FloatTensor).to(device)
)
loss.backward()
optim.step()
iterator.set_description(f"epoch{epoch+1} loss: {loss.item()}")
torch.save(model.state_dict(), "./UNet.pth")깊게 살펴보아야 할 부분은 ... 크게 없다!
한가지 팁은 Pytorch의 BCEWithLogitsLoss()함수는 시그모이드 함수를 자동으로 계산해준다고 한다. 그래서 시그모이드를 넣지 않았던 것이구만 ...!
6. 성능 평가하기
import matplotlib.pyplot as pyplot
model.load_state_dic(torch.load("./UNet.pth", map_location="cpu"))
data, label = test_set[1]
pred = model(torch.unsqueeze(data.to(device), dim=0))>0.5
with torch.no_grad():
plt.subplot(1,2,1)
plt.title("Predicted")
plt.imshow(pred)
plt.subplot(1,2,2)
plt.title("Real")
plt.imshow(label)
plt.show()pred 부분은 모델의 이미지 픽셀 중 0.5 이상은 1, 그 아래는 0으로 만드는 코드다. 이를 통해 제대로 Segmentation을 한 것인지 판단할 수 있다.
7. 마치며
Segmentation은 처음 해봤는데 꽤나 신기했다. 그런데 U-Net이 완벽하게 이해된 것은 아니라서 조만간 U-Net을 자세하게 한 번 읽어봐야 할 것 같다!
