[Paper Review] Towards Light-weight and Real-time Line Segment Detection (2022, AAAI)
오늘 소개할 논문은 AAAI 2022에 발표된 논문으로, Naver Vision팀에서 빠른 속도로 Line Segment를 감지하는 네트워크를 제안하였다.
Naver Vision 팀의 미션은 우리 주변의 시각적 세계를 이해하는 기계학습 알고리즘을 개발하고, vision 기반의 새로운 사용자 경험을 네이버 제품에 적용하는 것이다.
이 비전 팀에서 개발한 다양한 기술은 현재 우리 일상에서 흔히 살펴볼 수 있다.
대표적으로 네이버 앱에서 사용할 수 있는 스마트렌즈, 이미지/동영상 검색, 비주얼 커머스 서비스, 이미지를 통한 플레이스 찾기 기능 등이 이에 해당한다.
오늘은 위 기술 중 스마트렌즈에서 이미지를 검색 시 line segment를 정확하게 detection해주는 기술인 M-LSD 논문을 소개해보고자 한다.
- Introduction
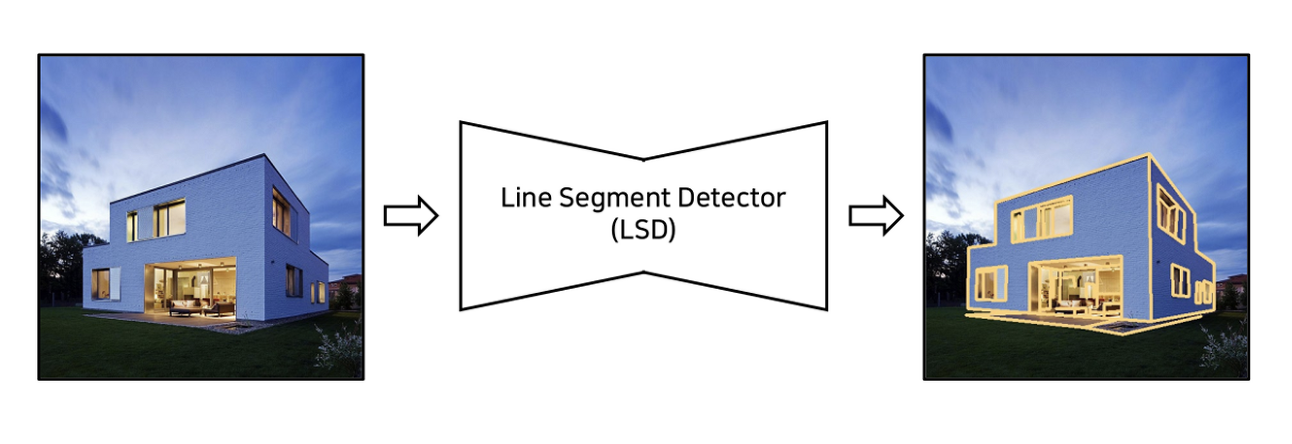
M-LSD를 이해하기 앞서 LSD에 대해 간단히 짚고 넘어가도록 하자.
LSD란 한 디지털 영상/이미지에서 선분을 검출 및 처리할 수 있도록 고안된 모델이다.
M-LSD를 이해하기 앞서 LSD에 대해 간단히 짚고 넘어가도록 하자.
LSD란 한 디지털 영상/이미지에서 선분을 검출 및 처리할 수 있도록 고안된 모델이다.
이 기술이 상당히 중요한 이유는 line segment들과 각 라인 간의 junction(교차점)들은 중요한 visual feature 가 되서 포즈 추정, 모션의 구조, 3D 재구성, 영상 매칭 등의 High-level vision 작업을 할 시에 기본 정보로 사용되기 때문이다.
그래서 이 LSD 모델은 여러 분야에서 다양한 방법들로 사용되고 있다.
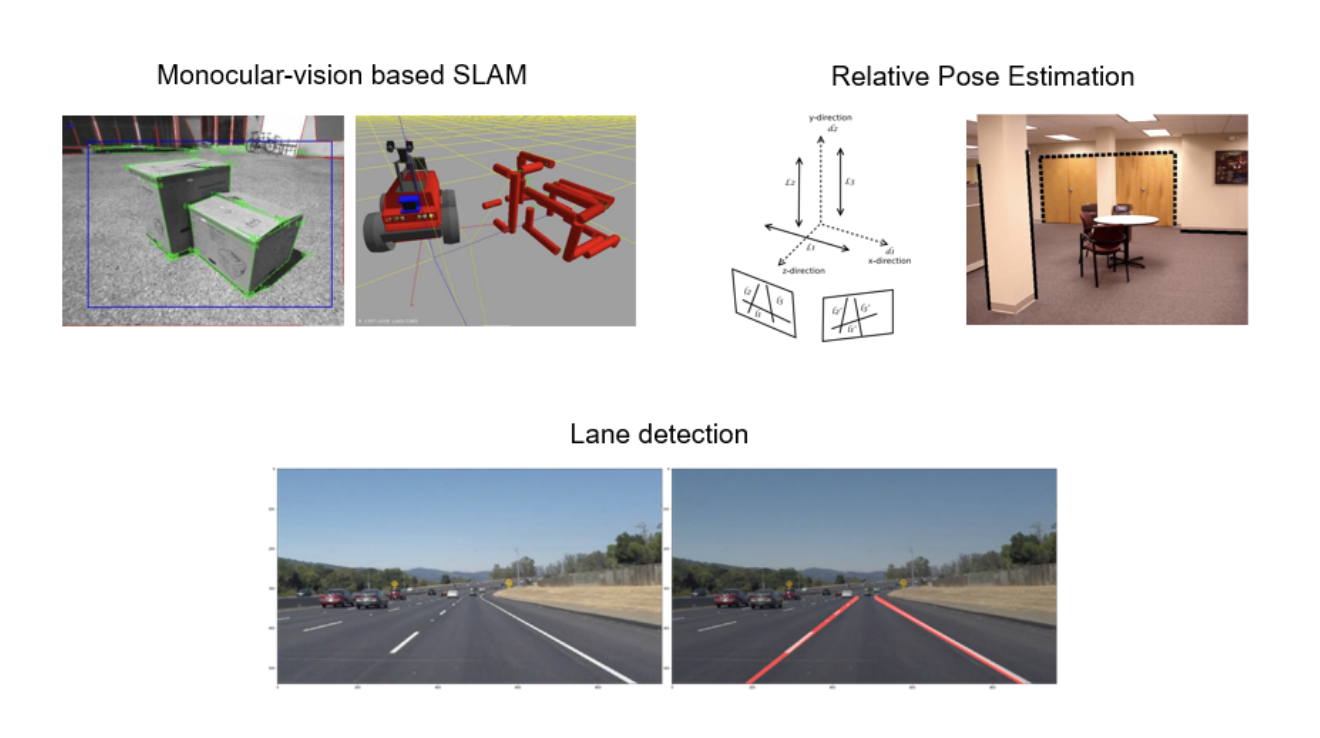
대표적인 예로 SLAM중에서 Monocular 카메라를 통해 Line segment를 이용한 Monocular-vision based SLAM이 이에 해당하며, 2개의 카메라를 이용해 pose간 연관성을 추정하는 Relative Pose Estimation, 그리고 자율주행 자동차에서 직선의 차선을 검출 및 인식하는데 있어 LSD모델이 사용된다고 한다.
또한 최근 들어 모바일이나 임베디드 장치와 같은 리소스 제약 플랫폼에서 이러한 비전 작업을 수행해야 하는 수요가 증가함에 따라 실시간 라인 세그먼트 감지(LSD)가 필수적으로 다가오게 되었다.
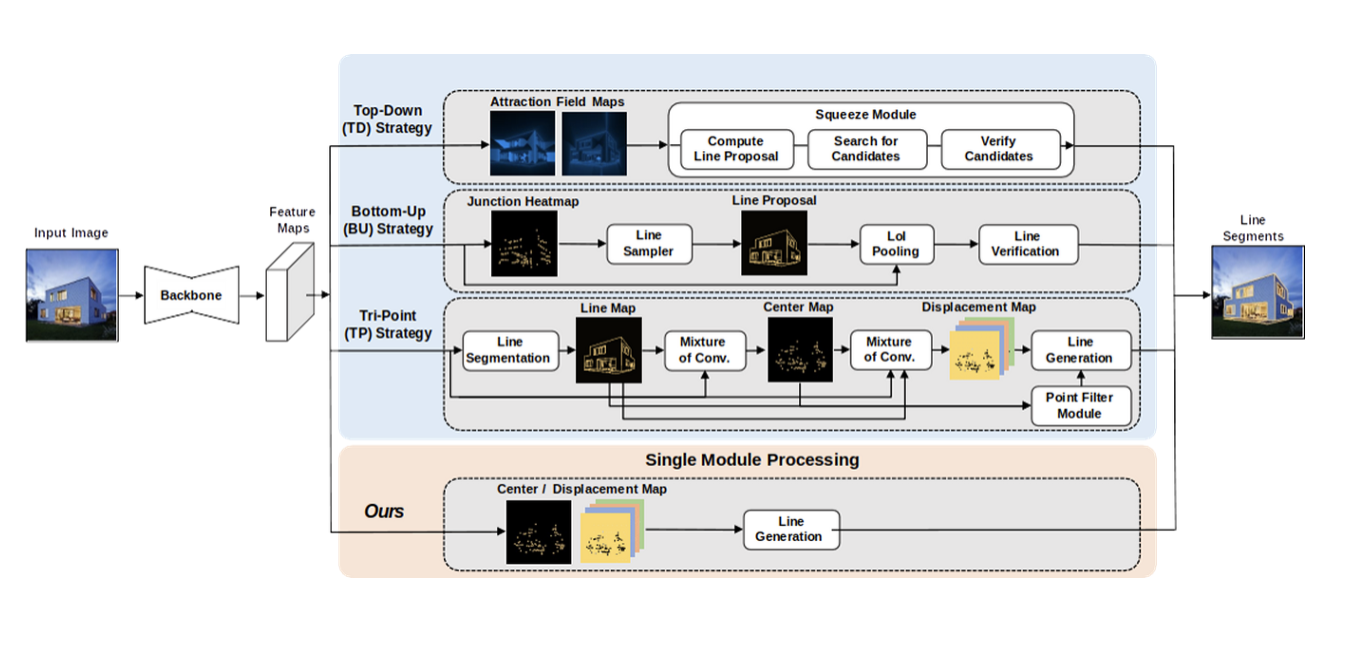
이 모델이 나오기 이전에도 실시간 LSD를 제시하려는 시도가 많이 있었다.
이전까지의 방법은 확장된 ResNet50 기반 FPN, hourglass 네트워크 및 Atrous residual U-net과 같은 대용량 백본 네트워크를 활용하기 때문에 큰 메모리와 높은 계산 성능이 필요할 수 밖에 없었다.
그렇기 때문에 서버급 GPU에 의존해야 한다는 한계가 있었으며, resource가 한정적인 플랫폼에 배치하기가 어렵다는 한계가 존재하였다.

그래서 이 논문에서는 수정된 모바일넷v2(modified Mobilnetv2) 을 백본으로 사용하는 M-LSD를 통해 좀 더 경량화되고 실시간으로 line segment를 detect해줄 수 있는 모델을 제안하였다.
- Proposed Method
1) Network Architecture

위 사진은 M-LSD의 네트워크 아키텍쳐를 보여주고 있다.
M-LSD의 백본, 즉 엔코더 네트워크로는 모바일 환경에서 실시간으로 실행될 수 있도록 잘 알려진 MobileNetV2의 일부(파라미터의 개수 = 16.5%만 사용)를 기반으로 한다.
그리고 디코더 네트워크는 top-down architecture에서 사용된 블록의 조합들로 설계되었다.
요약하자면
A형 : up-scale, skip connection 과 upscale을 통해 피쳐 맵을 연결.
B형 : residual block, 두 번의 3X3 컨볼루션을 수행하여 잔여학습 진행.
C형 : 두 번의 3X3 컨볼루션 후 1X1 컨볼루션 수행하여 Final feature map 추출
또한 파이널 피쳐 맵들은 다양하게 구성이 되어 있다.
1) TP map 은 length map 1개, degree map 1개, center map 1개, displacement map 4개를 포함하여 7개의 피쳐맵을 가지고 있다.
2) SoL 맵 또한 쎼 맵과 동일한 구성의 7개의 feature map이 있다.
3) Segmentation maps에는 junction(분기점)및 라인 map을 포함한 두 개의 feature map이 있다.
그래서 예측된 line segment는 여러 map중 TPmap에서 center point와 변위 벡터를 합하여 생성이 되며, 나머지 map들은 정확한 LSD를 하기 위한 보조 정보 map으로 사용된다.
추가적으로 트레이닝 단계에서 이 마지막 피쳐맵들은 TP, SoL, Segment map을 모두 포함하여 학습하지만,
인퍼런스 단계에서는 더 나은 효율성을 위해 오직 TP map만 사용하여 추론한다.
그럼 이 구조에 대해 자세히 알아보도록 하자.
2) Line Segment Representation : Tri-Point representation
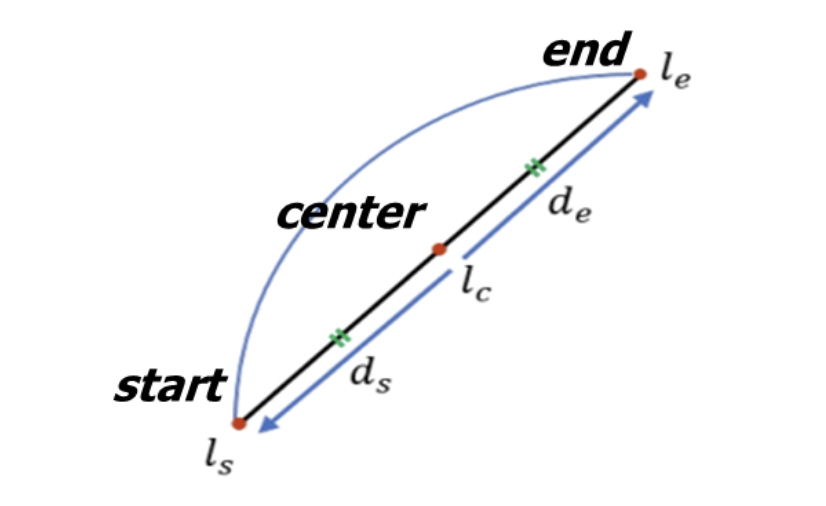
기존의 Line segment representation은 line segment predictions(선분 예측)이 생성되는 방식을 결정하고 궁극적으로 LSD의 효율성에 영향을 미친다.
이 논문에서는 이전의 real-time LSD를 수행하는 모델인 TP representation을 그대로 사용하고 있다.
TP representation은 세 개의 키포인트로 Start, Center 및 End point를 선택하여 line segment를 묘사한다.
ls, lc,le는 각각 시작점, 중심점 및 끝점을 나타내며, ds와 de는 중심 lc point에 대하여 시작점과 끝점에 대한 2d 변위 벡터이다.
중심점과 변위 벡터를 벡터화된 선분으로 변환하는 라인 생성 프로세스는 다음 수식과 같이 수행된다.

- Center point에 대한 좌표 (x,y)에 변위 벡터 ds,de를 더해줌으로써 시작점과 끝점에 대한 좌표를 나타낼 수 있다.
center point와 displacement vectors는 하나의 center map(중심 맵)과 4개의 displacement maps(변위 벡터 각 요소당 하나씩)으로 훈련된다.
그 후 line generation pross(라인 생성 프로세스)에서는 center map에 non-maximum suppression 알고리즘을 적용하여 정확한 중심점 위치를 추출한다.
하지만 기존의 방법이었던 center point와 변위 벡터가 있는 line segment의 학습은 다음과 같은 특정 상황에서 불충분할 수 있다.
1. 수용할 수 있는 필드 크기 내에서 line segment가 관리하기 너무 긴 경우
2. 각 두 개의 line segment 사이의 중심점이 서로 너무 가까울 때
LSD의 성능이 현저히 떨어지는 모습을 확인할 수 있었다고 한다.
3) Segments of Line segment(SoL) Augmentation
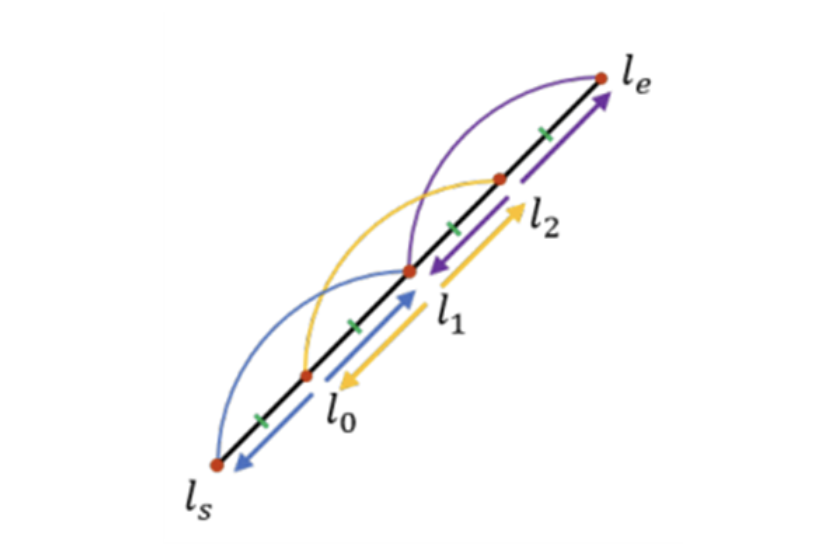
그래서 이 논문에서는 이러한 문제를 해결하고 기존의 TP representation에 더 많은 보조 정보를 제공할 수 있는 SoL Augmentation을 제안하였다.
SoL Augmentation은 하나의 선분을 (서로 겹치는 부분이 있는) 여러 하위 부분으로 분할하여, 많은 line segment가 나올 수 있도록 갯수를 늘리는 방식이다. 이 때 각 subpart 사이에 중첩이 되도록 분할을 했는데 연관성이 있는 하위 부분들 간의 연결을 유지하기 위함이라고 한다.

여기서 r(l)은 선분 l의 길이를 나타내고, µ는 subparts의 base length(기준 길이)를 나타낸다.
이 때 µ는 input size(입력 크기) × 0.125(보정값)를 실험에 의거해 설정하였다. 참고로 k ≤ 1일 때는 선분을 분할하지 않는다.
각 분할 점은 기존과 동일하게 TP representation으로 표현되며, 각 하위 부분 line segment는 전형적인 선분처럼 training 된다.
이 방법을 도입함으로써 line segment 에 대한 정보는 이전 방법인 TP보다 훨씬 많아졌고, 그 정보 중에서 가장 Ground Truth와 정확도가 높은 line segment만 nms 알고리즘으로 추출하니 훨씬 효율적이고 빠르다고 볼 수 있다!
4) Matching Loss
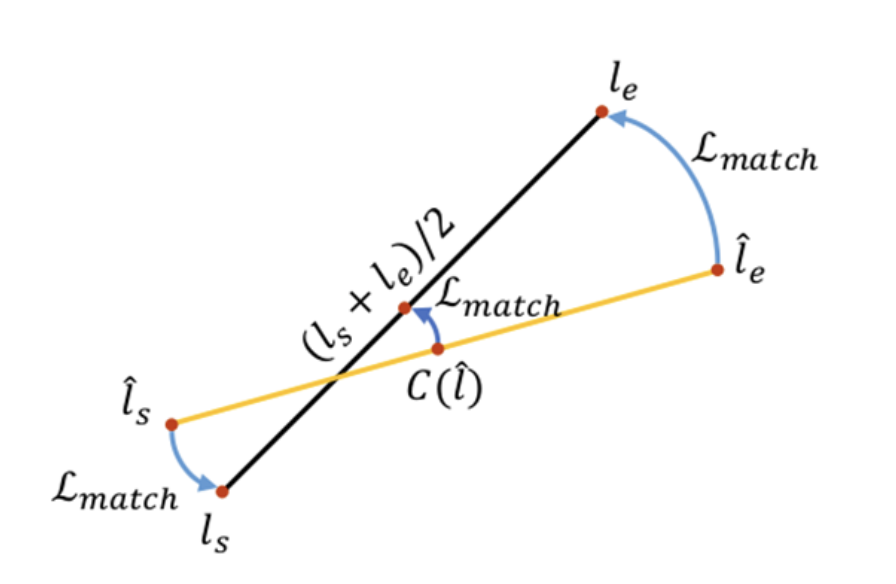
Sol Aug와 더불어 이 논문에서는 Ground Truth와 결합된 정보를 활용하는 Matching loss를 제시하였다.
Matching loss를 구하려면
1. 먼저 라인 생성 프로세스를 통해 계산할 수 있는 각 예측라인의 끝점을 취하고 GT의 끝점까지의 유클리드 거리 d(·)를 측정한다.
2. 다음으로, 1번에서 계산한 거리는 threshold 값인 γ(감마) 아래의 Ground Truth 선분 l과 예측된 선분 l^ 을 일치시키는 데 사용된다.
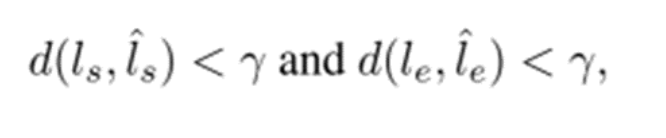
- 이 때 γ(임계값)은 5픽셀로 설정하였다.
3. 그런 다음, 이 조건을 만족하는 일치된 선분(l, l^)의 세트 M을 얻는다.
이는 다음과 같이 start, end 및 center point에서 일치된 선분의 기하학적 거리를 최소화하는 것을 목표로 한다.
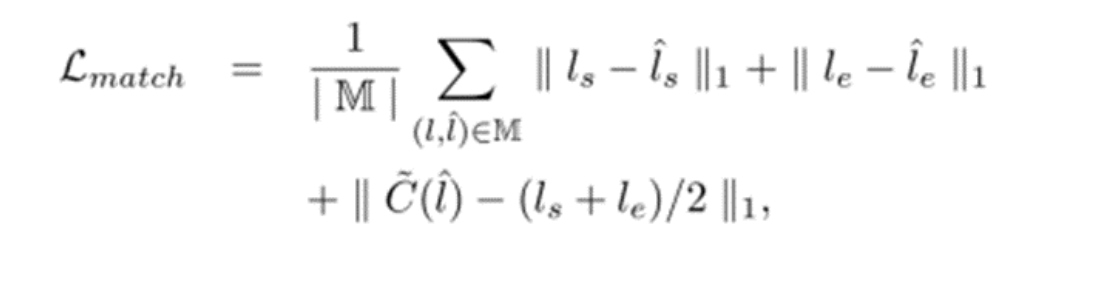
- 여기서 C(l^)는 center map에서 라인 l^의 중심점이다.
5) Junction with Geometric Information
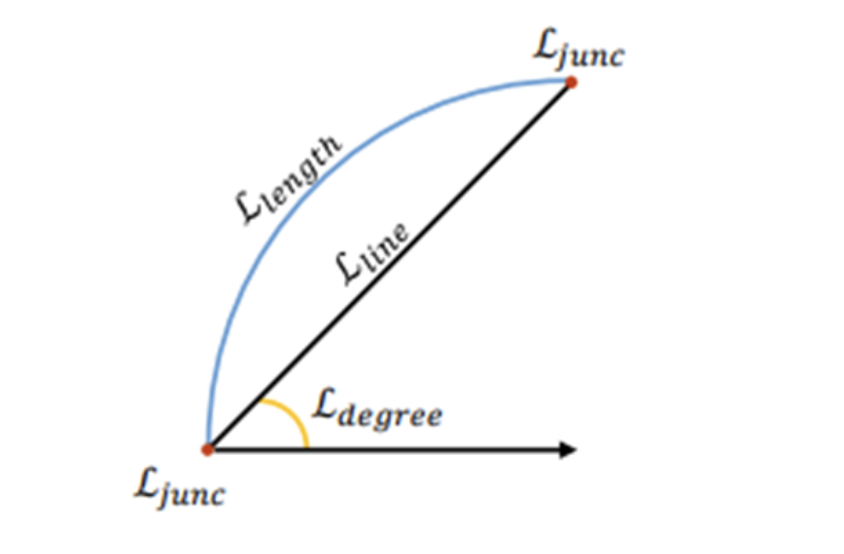
더불어 예측의 품질을 높이기 위해 line segment에 대한 다양한 geometric(기하학적) 정보를 통합하는 과정을 수행한다. 이 때 사용되는 geometric 정보로는 junction, line segment, length, degree가 해당된다.
먼저 중심점과 변위 벡터는 이 segmentation map에서 (픽셀 단위의) junction 및 line 과 매우 관련이 있는데, 중심점과 변위 벡터로부터 파생된 끝점은 junction point(교차점)가 되기 때문이며, 또한 중심점은 각 픽셀별로 line segment가 localize되어야 하기 때문이다.
따라서, junction 및 line의 segmentation map을 학습하는 것은 LSD에게 공간적 시그널로 작용한다.
이 부분에 대한 loss로는 weighted binary cross entropy loss를 사용하였다.
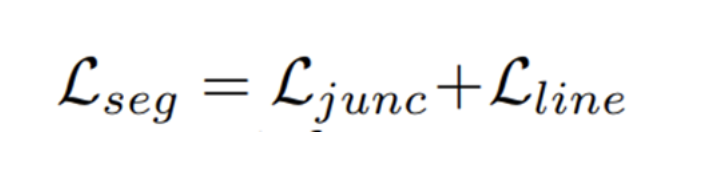
더불어 변위 벡터는 선분의 길이와 각도에 따라 다르게 도출될 수 있기 때문에 정확한 displacement 맵을 보조하기 위한 추가적인 기하학적 단서가 될 수 있다.
이 같은 경우 길이와 각도 범위가 넓기 때문에 정규화를 위해 각 길이를 입력 이미지의 대각선 길이로 나눈다.
각도의 경우 각 각도를 2pi로 나누고 0.5를 더해서 loss로 사용된다.
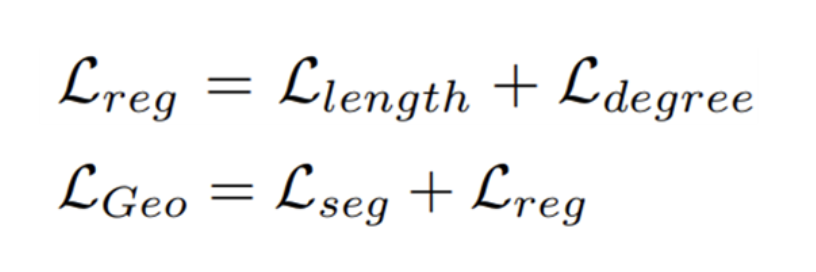
- Experiments
먼저 실험 환경 세팅을 위해 wireframe 과 yorkurban, 2개의 데이터 셋을 준비하였다. 그리고 성능측정 metric 으로는 Heatmap-based metric, Structural average precision(sAP), Line matching average precision(LAP)를 사용하였다.
최적화로는 테슬라 v100 gpu를 사용했고, input size로는 320 또는 520 사이즈를 넣어줬다. 또한 imagenet으로 pretrain한 MobileNetV2를 백본으로 사용하였다.
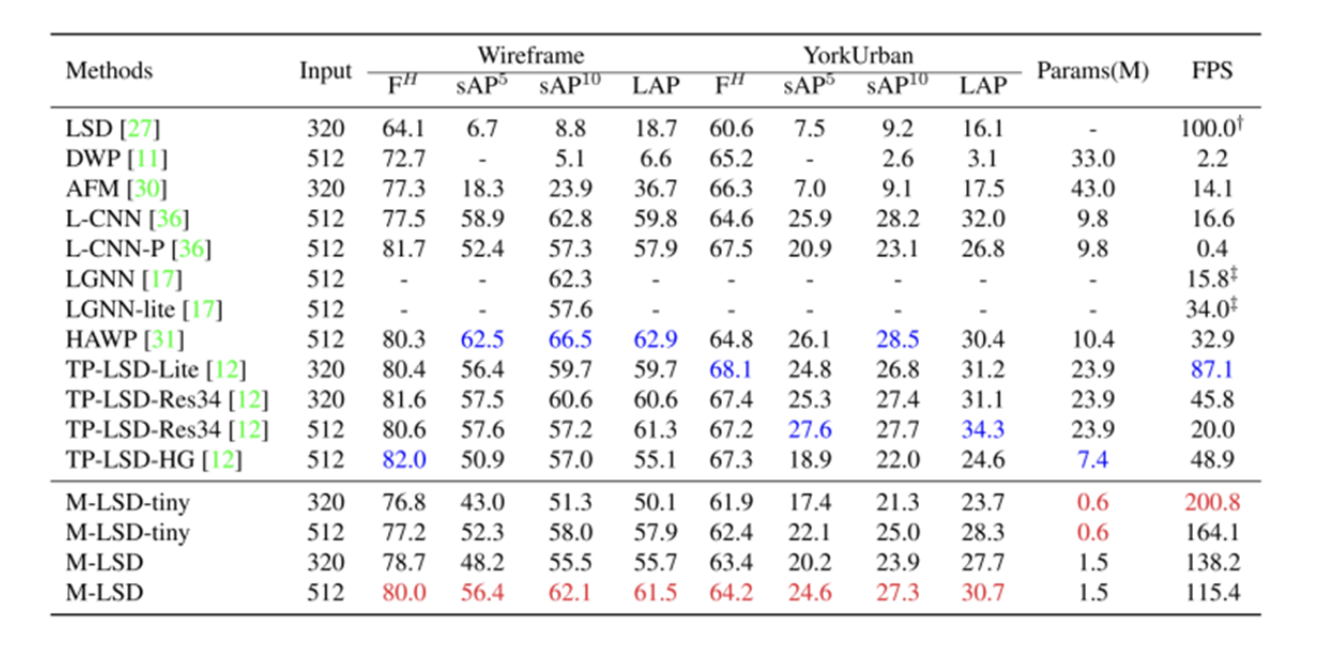
그래서 다른 LSD 모델들과 성능을 각 input 사이즈별로 정리하여 비교한 사진이다.
M-LSD와 M-LSD tiny 버전 metric을 보면 다른 LSD모델들에 비해 향상된 수치를 보여주는 것을 확인 할 수 있다.

또한 이를 실제로 visualization하여 Ground Truth와 비교를 해보아도 Ground Truth가 나타내는 line segment를 모두 검출해내고, 보다 훨씬 정교한 detection을 보여준다.
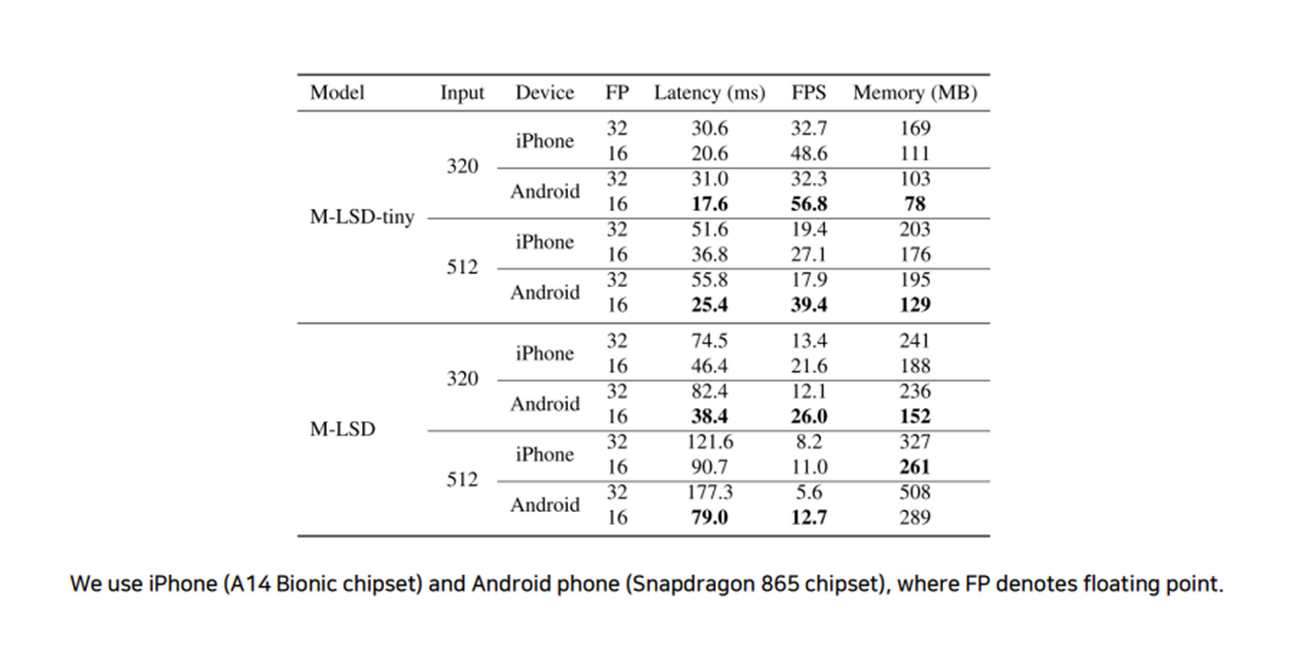
그리고 이 M-LSD의 가장 큰 장점은 mobile에서도 real-time으로 우수한 성능을 보여준다는 것이다.
세팅 환경으로는 아이폰 a14 bionic 칩셋과 안드로이드 폰(스냅드래곤 865칩셋)을 기준으로 하였으며, 최신 안드로이드와 아이폰 모바일 기기에서 각각 56.8 FPS와 48.6 FPS로 실시간 구동된다.
논문에 따르면 이는 모바일 장치에서 사용할 수 있는 최초의 실시간 LSD 방법이라고 한다.

그래서 Real-time LSD는 사진과 같이 모바일 디바이스 안에서 북 스캐너, 와이어프레임에서의 이미지 변환을 할 수 있으며, SLAM 및 포즈 추정, 차선 검출 등에 적용하여 사용할 수 있다.
- Demo Version
이 논문에서는 모바일에서 실시간으로 테스트 해볼 수 있는 데모 버전과, 컴퓨터에서 사진을 넣고 테스트 할 수 있는 데모버전으로 나뉘어 제공하고 있다. 궁금하다면 한번 해보시길 :)

