
안드로이드 앱 프로젝트를 시작할 때, 프로젝트 구조 설계를 하게된다.
가장 잘 알려진 설계 구조는 크게 두가지로, 클린 아키텍쳐와 앱 아키텍쳐가 있다.
클린 아키텍쳐는 앱 개발 뿐만 아니라 다양한 도메인에서 사용되는 보편적인 설계 구조이고, 앱 아키텍쳐는 안드로이드 팀에서 권장하는 앱 설계 방식이다.
언뜻 보기에는 비슷해보이는 두 설계 방식은 어떻게 다른걸까?
두 설계 방식에 대한 정보는 널리 나와 있으므로, 직접 안드로이드 앱 개발을 했을 때 두 설계 방법이 어떻게 달랐는지, 그리고 사용하면서 느꼈던 점같은 개인적인 경험을 공유하고자 한다.
Clean Architecture
클린 아키텍쳐는 프로젝트 구조를 크게 세 레이어로 나눈다. UI를 담당하는 Presentation, 비즈니스 로직을 담당하는 Domain, 마지막으로 데이터를 다루는 Data.
패키지를 통해 각 레이어를 나눌 수도 있지만, 안드로이드 개발에서는 Gradle을 사용하기 때문에 모듈 단위로 나누는 것이 의존성 분리와 빌드 최적화에 도움이 된다.
my-project/
├── settings.gradle.kts
├── build.gradle.kts
├── data/
│ └── build.gradle.kts
├── domain/
│ └── build.gradle.kts
└── presentation/
└── build.gradle.kts모듈 단위로 나눈다면 이렇게 세 모듈로 구성된 프로젝트가 된다.
그리고 각 모듈에는 그 역할에 맞는 소스파일들이 자리한다.

각 모듈은 개략적으로 이렇게 구성된다.
Presentation에는 앱의 기초가 되는 Activity와 UI가 되는 View, 그리고 View의 상태관리를 담당하는 ViewModel이 존재한다.
Domain에는 UI에 데이터를 보여주고 사용자 입력에 따른 비즈니스 로직 처리를 위한 다양한 UseCase와 UseCase에서 사용될 데이터가 추상화된 Repository 인터페이스가 존재한다.
마지막으로 Data에는 Repository 인터페이스를 구체화하여 데이터를 처리하는 구현클래스들과 로컬과 네트워크에서 데이터를 주고 받는 DataSource가 존재한다.
장점
1. 유지보수성
비즈니스 로직을 위한 Domain 레이어가 존재함으로써, Presentation 레이어에서 반복 사용되는 비즈니스 로직을 UseCase로 묶어 하나로 관리할 수 있다. ViewModel에서 반복사용되는 로직을 분리관리할 수 있다는 것은 큰 장점이었다.
2. 관심사 분리 (Separation of Concerns)
추상화된 Repository를 사용하여 Data 레이어와의 의존성을 분리시킨다. 그렇기에 데이터를 주는 것이 로컬DB인지, 네트워크인지 신경 쓸 필요가 없이 온전히 하나의 역할(Single Responsibility)을 할 수 있다. 이러한 관심사의 분리는 네트워크가 없더라도 어떻게 데이터를 줬는지는 상관없이 데이터를 주기만 하면 되기 때문에 여러모로 테스트 용이성을 높여준다.
특징
1. 의존성
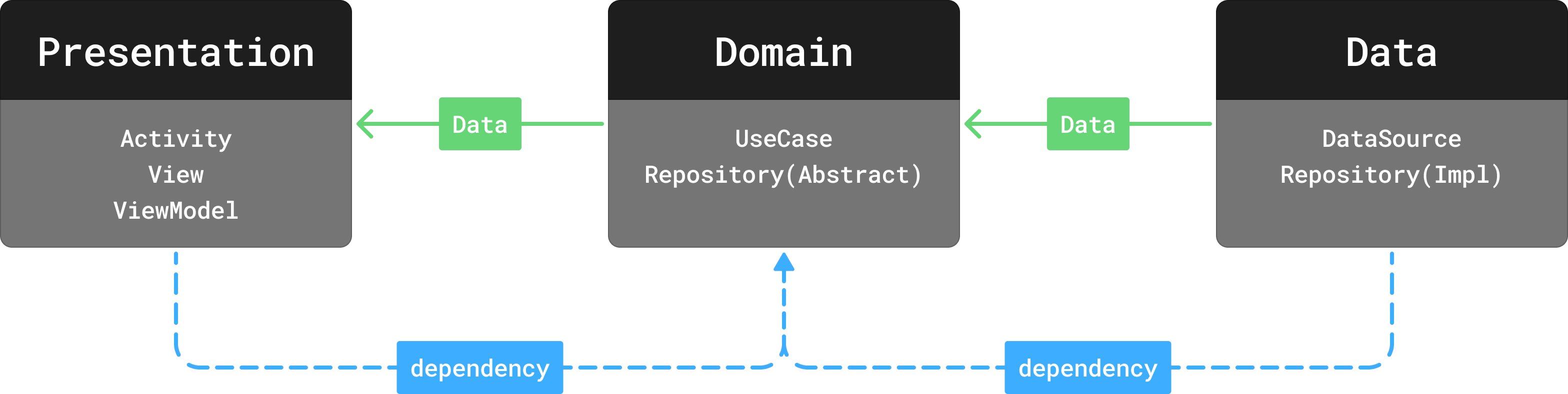
안드로이드 개발에서 클린 아키텍쳐의 특징은, 데이터의 흐름이 일방향으로 이어지지만, 의존성의 방향은 그렇지 않다는 것이다.
Data와 Domain같은 경우는 Domain에 있는 Repository 추상화를 Data에서 구체화하기 때문인데 오히려 데이터를 주는 Data가 데이터를 받는 Domain에 의존적이다.
따라서 의존성 역전의 법칙이 잘 이루어지는 경우라고 볼 수 있다.
하지만 Domain에서 관리되는 UseCase는 많은 경우 추상화를 하지 않고 구현체 자체를 Presentation 레이어에서 주입받아 사용하는 경우가 많아 Presentation은 데이터를 주는 Domain에 의존적이다.
2. Domain의 존재 의의
안드로이드에는 ViewModel이라는 클래스가 존재한다. 이것은 MVVM 디자인 패턴에서의 VM과 동일하지는 않지만, View와 관련된 비즈니스 로직을 처리하기도 한다. 이는 Domain 레이어가 안드로이드에 대한 의존성이 없고, 있어도 안되기 때문에 어쩔 수 없이 안드로이드와 깊은 연관이 있는 기능이거나, 생명주기 관리와 연관되어 어느정도의 비즈니스로직을 수행하기 때문이다.
3. 역할이 없는 UseCase
Domain은 비즈니스 로직을 위한 레이어이지만, ViewModel에서 단순한 비즈니스 로직은 처리되기 때문에 UseCase가 단순히 Repository의 함수 호출만을 하는 경우도 있었다. 이런 경우, UseCase로 인해 관리할 파일이 하나 더 늘어나기만 하는 것이다.
App Architecture

안드로이드 앱 아키텍쳐는 이러한 애매한 포지션의 Domain 레이어를 '옵션'으로 두었다. 안드로이드에서 지원하는 다양한 기능을 통해 복잡할 로직이 필요하지 않은 경우, ViewModel에서 충분히 비즈니스 로직을 처리할 수 있기 때문이다.
따라서 복잡한 비즈니스 로직이 필요하거나, 여러 화면에서 반복 사용되는 로직을 관리하기 위한 경우가 아니라면 UI와 Data 레이어만으로 프로젝트를 구성해도 무방하다는 뜻이다.
Domain?
하지만, 만약에 UseCase를 위해 Domain 레이어를 만들었다면 클린 아키텍쳐와 동일한가?
결론부터 말하자면, 앱 아키텍쳐에서의 Domain은 클린 아키텍쳐의 그것과 다르다.
The term "domain layer" is used in other software architectures, such as "clean" architecture, and has a different meaning there. - Android Developers
Domain 레이어에 대한 공식 문서를 읽어보면, 클린 아키텍쳐와 비슷하면서도 다른 점이 존재한다.
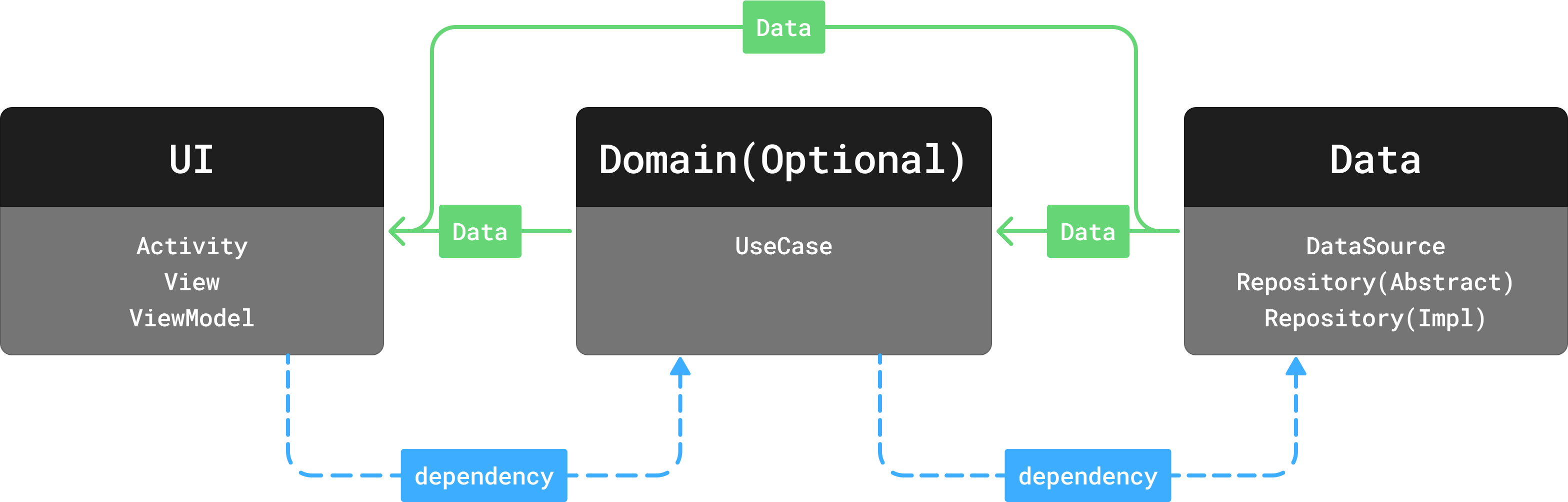
먼저 Domain은 옵션이기 때문에 Repository가 Data 레이어의 관할이 되면서 의존성의 방향이 달라졌다. 그리고 데이터의 흐름이 보다 자유분방해진 것을 볼 수 있다. Domain이 클린 아키텍쳐에서처럼 필수적인 것이 아닌만큼, 안드로이드 팀에서 Domain 레이어를 어떻게 사용하는가를 설계하는 팀과 개발자에 맡겼기 때문이다.
advantage of making this restriction is that it stops your UI from bypassing domain layer logic, for example, if you are performing analytics logging on each access request to the data layer.
However, the potentially significant disadvantage is that it forces you to add use cases even when they are just simple function calls to the data layer, which can add complexity for little benefit.
A good approach is to add use cases only when required. If you find that your UI layer is accessing data through use cases almost exclusively, it may make sense to only access data this way.
Ultimately, the decision to restrict access to the data layer comes down to your individual codebase, and whether you prefer strict rules or a more flexible approach.
Clean Architecture VS App Architecture
그렇다면 어느 설계 방식을 택해야하는가?
그것은 앱을 개발하는 팀이나, 개발자 개인에 따라 달라진다. 하지만 개인적으로는 팀단위에서는 조금 번거롭고 자유도가 떨어지지만 데이터 흐름을 보다 강제하는 클린 아키텍쳐를, 혼자하는 사이드 프로젝트에서는 앱 아키텍쳐를 활용하고 있다.
