현재 학교에서 공부중인 전공 과목 'System Programming'의 강의 내용을 필기하여 정리한 시리즈이다. 우리 학교의 시스템 프로그래밍은 컴퓨터에 대한 동작 원리를 이론적으로 학습한 후, 이것을 이론에서 그치지 않고 코드로 직접 구현하여 하나의 작은 컴퓨터를 만드는 것을 목표로 하고 있다.
Overall HW Structure
우선 컴퓨터 시스템의 전체적인 하드웨어 구조를 살펴보면 아래와 같다.
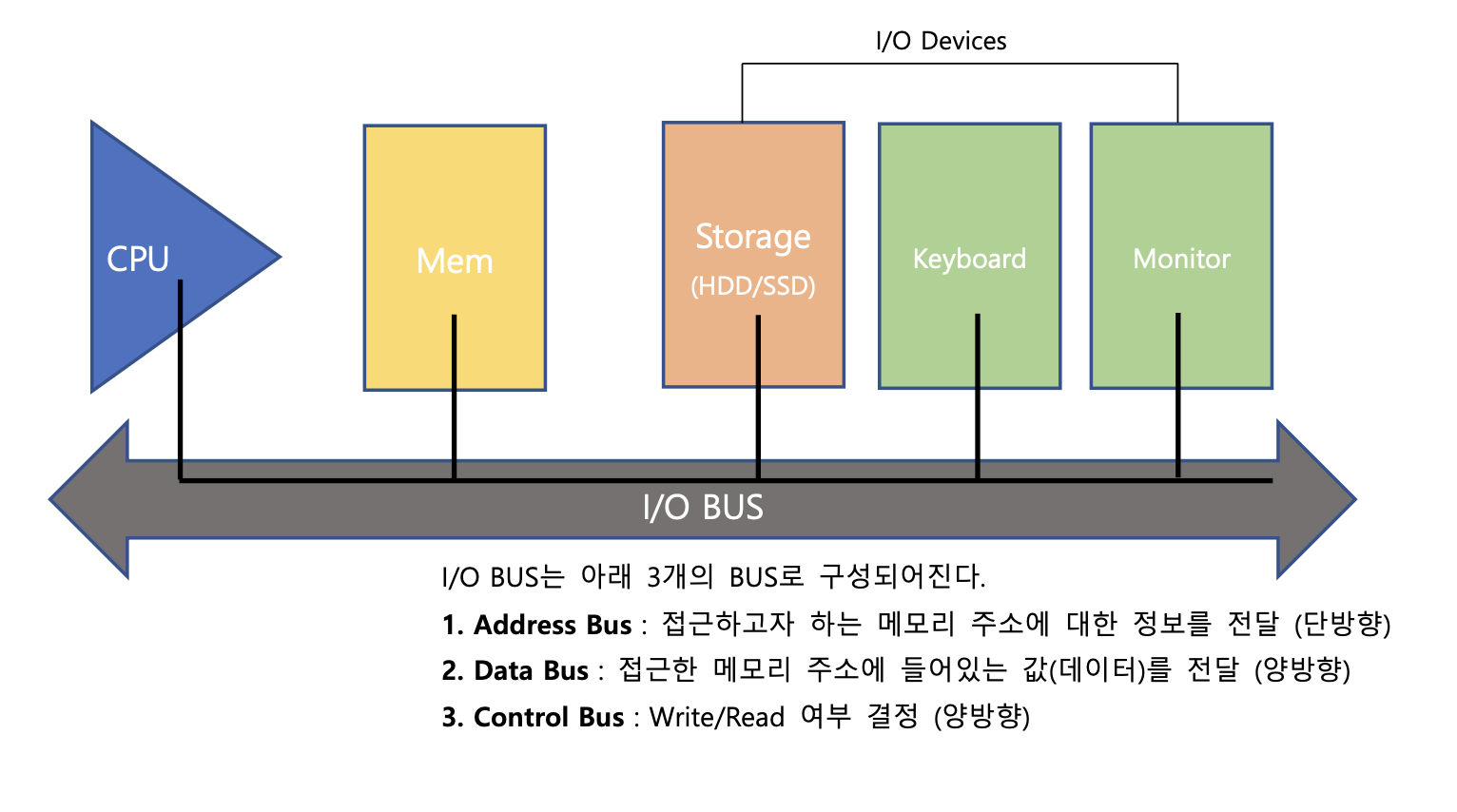
위의 그림에서처럼 확인할 수 있듯이 컴퓨터의 구조는 크게 CPU, Memory, 저장장치(Storage) & 입출력 장치(Keyboard, Mouse, Monitor..)로 나뉜다. 저장장치와 입출력장치는 I/O Device로 크게 묶을 수 있다.
그렇다면 이 장치들은 서로 어떤식으로 상호작용하며 동작할까?
우리가 MS Word 프로그램을 실행시키는 상황을 가정해보자. 해당 상황에서 프로그램이 실행되고 종료되는 과정을 말로 쉽게 풀어 설명하면 아래와 같다.
- Keyboard나 Mouse 등의 입출력 장치를 통해 해당 프로그램을 클릭하여 실행시키면,
- 해당 입력이 I/O Bus를 통해 CPU에게 전달되고,
- CPU는 Storage에 저장되어 있는 Word 프로그램을 메모리에 올리게 되며 프로그램이 실행된다. (모니터에 출력)
- 이후 프로그램을 종료시키려고 닫기 버튼을 클릭하게 되면
- 클릭 이벤트의 발생으로 Keyboard/Mouse -> CPU로 해당 요청이 전달되게 되고,
- CPU가 메모리에서 Word 프로세스를 내리면서 프로그램이 종료되는 것이다.
여기서 각 영역들(메모리,저장장치,CPU,입출력 장치)이 서로 간의 요청과 데이터를 주고받으면서 통신하기 위해 필요한 것이 I/O Bus이다. IO 버스의 종류는 아래와 같이 크게 세가지로 나뉜다.
Data Bus
기억장치와 I/O 장치의 명령어와 데이터를 CPU의 MBR로 보내고, CPU가 연산한 결과를 기억장치와 I/O로 보낸다. 데이터 버스의 크기는 CPU가 한 번에 전송 가능한 데이터의 크기와 같다. 이처럼 CPU - I/O Device 양쪽에서 데이터를 주고 받아야 하기 때문에
양방향 통신을 한다.
Address Bus
CPU쪽에서 데이터를 저장할 위치를 정해주어야 하는데, 이때 이용되는 것이 바로 주소 버스이다. 단순히 CPU쪽에서 기억장치 or I/O Device의 어디로 데이터를 보낼것인지에 대한 주소를 전달하기 때문에 단방향 통신이 이루어진다.
e.g.,) 5라는 값을 1번주소에 넣어라 => MBR : 5 MAR : 1
Control Bus
CPU가 기억 장치나 I/O Device와 데이터 전송을 주고받을 때나, 서로의 상태를 다른 장치들에 알리기 위해 신호를 전달하는 버스이다. 대표적으로 I/O Device에서 요청하는 Inturrupt가 이 버스를 타고 CPU 에게 전달된다. CPU는 기존의 처리해야할 작업을 하고 있다가, 사용자가 I/O Device를 통해 클릭을 하는 등으로 다른 프로그램이 실행된다고 가정하면, 이때 I/O Device가 제어 버스를 통해 CPU에 '나부터 좀 처리해줘' 라는 신호를 보내게 되고, CPU가 이를 인지하고 해당 프로그램을 우선적으로 처리하는 Context Switching이 일어나게 되는 것이다. 통신 방향은 CPU 에서 저장장치나 I/O Device로 신호를 줄 수도 있고, 방금 설명한 것처럼 역으로 신호를 보내는 것도 가능하기에 양방향 통신을 한다고 보면 되겠다.
잠깐! 여기서 Context Switching이 뭘까? 간단히 알아보자.
Context Switching
Context는 간단히 말해서 CPU가 해당 프로세스를 실행하기 위한 해당 프로세스의 정보이다. 이러한 컨텍스트들은 프로세스 제어 블록(Process Control Block , PCB)에 적재가 된다. (PCB는 운영체제가 프로세스에 대한 중요한 정보를 저장해 놓는 곳으로 Task Control Block 또는 Job Control Block이라고도 한다. 각 프로세스가 생성될 때마다 고유의 PCB가 생성되며 프로세스가 종료되면 PCB는 제거된다. 이처럼 PCB는 프로세스의 중요한 정보를 포함하고 있기 때문에, 일반 사용자가 접근하지 못하도록 보호된 메모리 영역에 위치해있다.)
Context Switching은 CPU가 Inturrupt 등에 의해서 처리해야 할 프로세스를 바꿀때, 기존에 처리하고 있었던 프로세스의 정보(Context)를 PCB(0번)에 저장해놓고, 새로 실행하려는 프로세스의 정보(Context)를 PCB(1번)에서 가져와서 실행을 하는 방식으로 이루어진다. (여기서 PCB 뒤 괄호에 적은 번호는, 각 프로세스마다 Context가 각기 다른 영역에 저장됨을 의미한다. )
전체적인 하드웨어의 구조를 살펴보았으니 이제 CPU와 메모리에 대해 살펴보겠다.
CPU
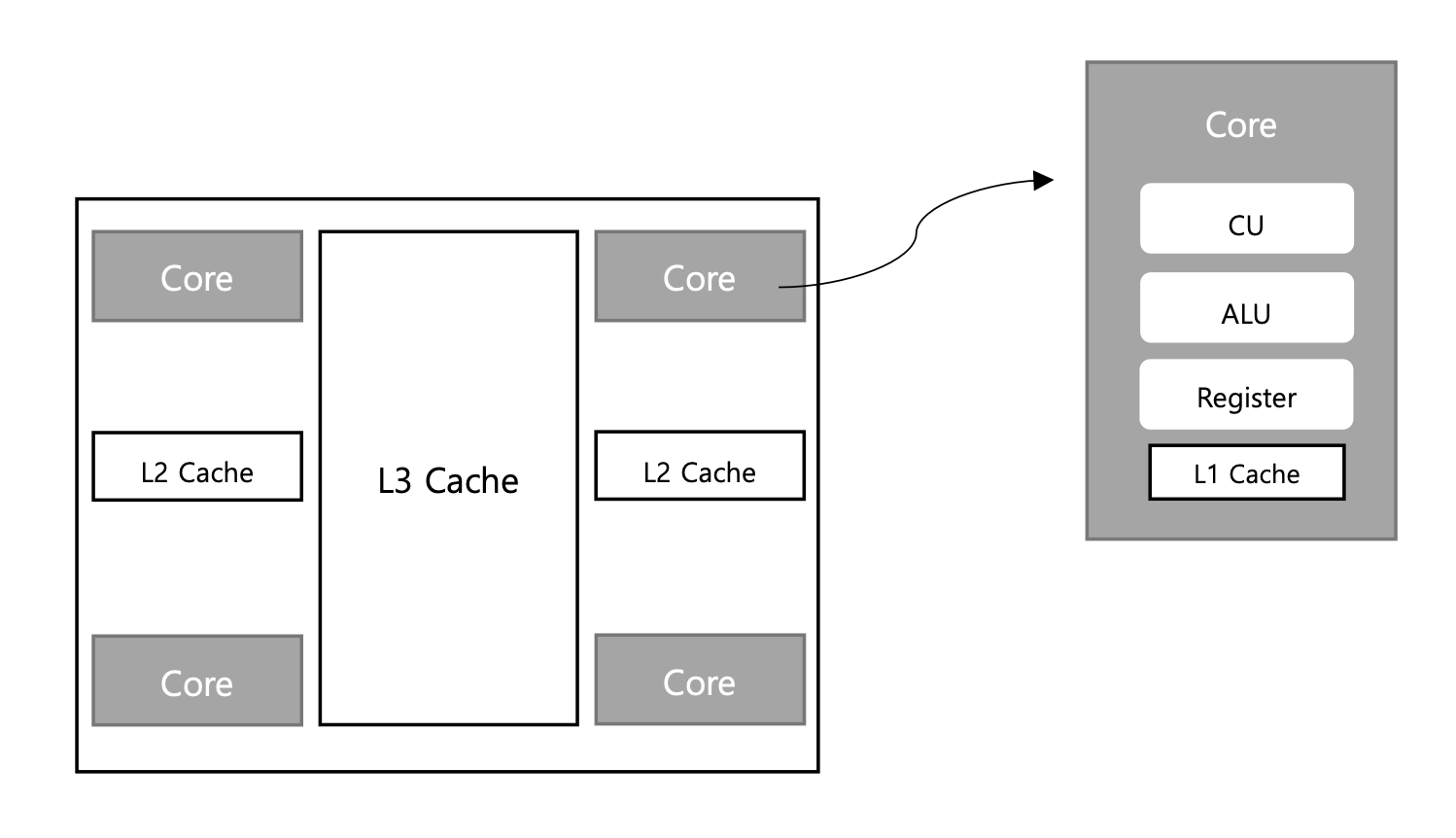
코어와 캐시 메모리로 나뉘는 것을 확인할 수 있다.
CPU에서 실질적인 역할 수행은 Core가 담당한다. 코어는 아래와 같이 구성된다.
Core
1. 제어 장치 (CU, Control Unit)
메모리에서 명령을 불러와 명령어를 해독하고 해독된 명령어에 따라 특정 작업 등의 실행을 지시하는 실질적인 핵심 장치
2. 연산 장치 (ALU, Arithmethic Login Unit)
제어 장치의 지시를 받아서 산술, 논리, 비트 등의 연산을 수행하는 장치다.
3. 기억장치 (Register)
제어, 연산 장치 등에서 사용하는 임시 기억 장치의 역할을 한다. 그 종류는 아래와 같다.
- PC (Program Counter) : 다음 인출(Fetch) 될 명령어의 주소를 가지고 있는 레지스터
- AC (Accumulator) : 연산 결과 데이터를 일시적으로 저장하는 레지스터
- IR (Instruction Register) : 가장 최근에 인출된 명령어(현재 실행 중인 명령어)가 저장되어 있는 레지스터
- SR (Status Register) : 현재 CPU 의 상태를 가지고 있는 레지스터
- MAR (Memory Address Register) : PC 에 저장된 명령어 주소가 사용되기 전에 일시적으로 저장되는 주소 레지스터
- MBR (Memory Buffer Register) : 기억장치에 저장될 데이터 혹은 읽힌 데이터가 일시적으로 저장되는 버퍼 레지스터
Cache
그럼 이제 Cache에 대해 살펴보자. 캐시의 정의는 다음과 같다.
"컴퓨터 과학에서 데이터나 값을 미리 복사해 놓는 임시 장소를 가리킨다. 캐시는 캐시의 접근 시간에 비해 원래 데이터를 접근하는 시간이 오래 걸리는 경우나 값을 다시 계산하는 시간을 절약하고 싶은 경우에 사용한다. 캐시에 데이터를 미리 복사해 놓으면 계산이나 접근 시간없이 더 빠른 속도로 데이터에 접근할 수 있다." - Wikipedia
즉, 메모리의 속도와 CPU의 속도차이가 상당하기 때문에, 메모리에서 곧바로 데이터에 접근하면 시간이 오래걸리고 병목현상이 발생한다. 이를 방지하기 위해 CPU에 작고 빠른 캐시를 두어 이곳에 자주 사용하는 데이터나 값을 임시적으로 저장해놓고, CPU에서 메인 메모리에 접근하는 대신에 이 캐시에서 빠르게 꺼내어올수 있도록 하는 것이다.
캐시 메모리는 아래와 같이 종류가 나뉜다.
- L1 Cache : 코어마다 각각 독립적으로 보유하고 있는 캐시로, 코어와 가장 가깝고 코어 내부에 있는 레지스터가 L1 Cache를 읽고 쓰는데 사용한다.
- L2 Cache : L1 Cache와 L3 Cache를 잇는 역할을 하는 중간 규모의 캐시이다.
- L3 Cache : 모든 코어가 공유하는 가장 큰 규모의 캐시이다.
즉, 데이터가 오가는 경로(순서)를 살펴보면 아래와 같다. 속도는 왼쪽부터 가장 빠르다.
Register ↔ L1 cache ↔ L2 cache ↔ L3 Cache ↔ Memory ↔ Storage(HDD,SSD)
가장 빠른 저장장치인 레지스터와 가까워질수록 그 속도 차이를 매꾸기 위해 임시장치를 연속적으로 거치도록 해두는 느낌이라고 생각하면 이해가 쉬울것이다.
(notice : 캐시가 효율적으로 동작하려면, 캐시에 저장할 데이터가 지역성을 가져야 한다. 여기에 해당 내용을 숙지하기 좋은 포스팅이 있으니, 참고하도록 하자.)
Memory
메모리는 크게 휘발성 메모리인 RAM(Random Access Memory)과 비휘발성 메모리 ROM(Read-Only Memory)이 있다.
이름에서 유추할 수 있듯이, RAM은 컴퓨터 시스템이 종료되면 메모리에 저장되어 있던 정보들이 모두 사라지게 되고, ROM은 시스템이 종료되어도 저장되어 있던 정보들이 유지가 된다. RAM의 경우 읽기/쓰기가 모두 가능하고 ROM보다 속도가 빠르며, ROM의 경우 주로 읽기만 가능하고 쓰기가 불가능하며 속도가 RAM보다 느리기 때문에 주로 기본 입출력 시스템, BIOS 등 변경 가능성이 없는 시스템 소프트웨어를 기억시키는데 이용되곤 한다. 아래는 CPU와 메모리, 저장장치(DISK)의 상호작용을 간단하게 정리한 그림이다.
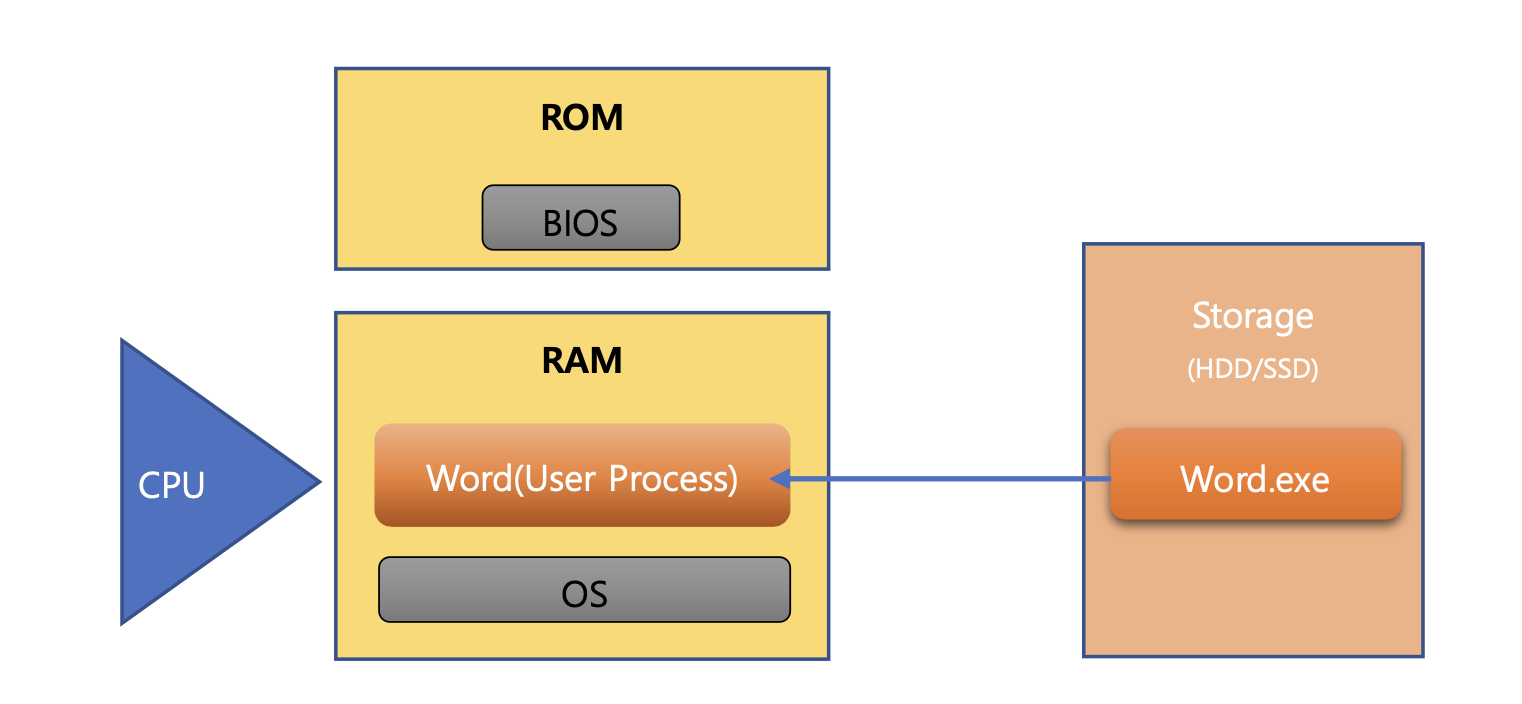
위 그림을 설명하자면 아래와 같다.
- 컴퓨터를 키면 ROM에 있던 BIOS가 부팅 전 하드웨어를 한번 초기화 시켜 컴퓨터가 사용될 준비를 마치며,
- 컴퓨터를 부팅시키고 OS를 호출하게 된다.
- OS는 컴퓨터가 부팅된 후 RAM에 가장 처음으로 깔리게 되며, 이후 자원과 입출력을 관리하며 동작한다.
- 만약 우리가 Word 프로그램을 실행시키게 되면,
- Storage에 파일 형태로 저장되어 있던 Word가 CPU에 의해 RAM에 올라오게 되며,
- 이때 RAM에 올라온 프로그램을 Process라고 칭한다. (이때 해당 프로세스는 유저가 사용하고자 실행된 프로세스이기 때문에 User Process라고 한다.)
Process
그렇다면 프로세스는 메모리(RAM) 위에서 어떤식의 구조를 가질까?
아래는 프로세스를 5개의 논리적 기준으로 나눈 것으로, 각 영역을 Segment라고 칭한다. (앞서 말했듯 프로세스는 컴퓨터의 메모리에 올라가 있는 '실행중인' 프로그램을 말한다. 즉, 아래의 그림은 프로그램이 실행 상태로 들어갔을때 메모리에 어떤식으로 올라가는지에 대한 그림이다.)
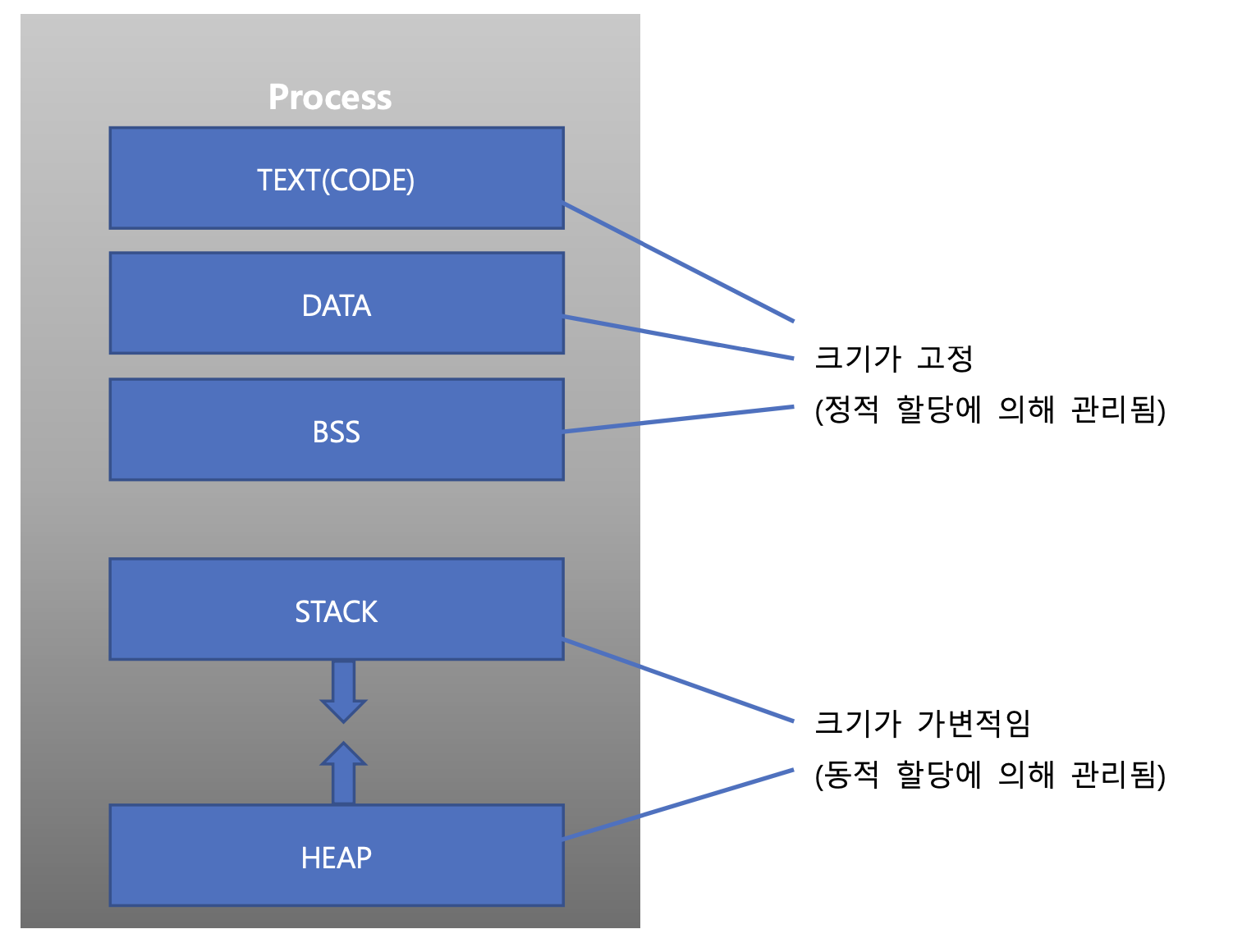
- TEXT(CODE) Segment
컴파일된 소스코드 자체가 저장되는 영역으로, 코드를 실행해야 하기에 읽기권한과 실행권한이 부여된다. 악성코드를 삽입할 위험이 있기 때문에 현대의 운영체제들은 이 영역에 쓰기 권한을 부여하지 않는다.
- DATA Segment
컴파일이 완료된 시점의 전역 변수/상수가 위치하는 영역이다. CPU 에서는 해당 영역의 변수/상수를 읽어야 하기에 읽기 권한이 부여된다. 데이터 세그먼트는 쓰기 권한의 유무에 따라 세부적으로 data / rodata 라는 두 세그먼트로 다시 분류된다.
- data 세그먼트 : 쓰기권한을 보유한 세그먼트로, 프로그램 실행 중 값이 바뀔 수 있는 전역 변수가 위치하는 영역이다. (읽기/쓰기 권한 보유)
- rodata 세그먼트 : 쓰기권한이 없는 영역이기에 프로그램 실행 중 변하면 안되는 전역 상수가 위치한다. (읽기 권한만 보유)
- BSS Segment
전역 변수가 저장되는 영역이라는 점에서 DATA Segment와 비슷하지만, BSS Segment에는 선언은 되었지만 값 초기화가 되지 않은 전역변수가 담긴다. DATA Segment와 마찬가지로 CPU가 해당 영역의 변수를 읽어야 하기에 읽기 권한이 부여되며, 전역 '변수'를 담고있기에 프로그램 실행 도중 값이 바뀔수 있어야 하니까 쓰기 권한 또한 부여된다.
- STACK Segment
앞서 설명했듯 DATA Segment와 BSS Segment에는 전역 변수가 저장되었다면, 이곳에는 함수 내부에 있는 변수 등 임시적으로 사용되는 '지역 변수'와 '매개 변수'가 담기게 된다. 이름에서 알수 있듯이 스택 구조의 특징인 LIFO(Last In, First Out) 방식으로 동작하기 때문에 프로그램이 실행되며 호출된 함수들은 차곡차곡 메모리에 쌓이며 실행되고, 함수가 종료되면 해당 함수에 할당되었던 이 지역 변수들이 메모리에서 해제된다. 프로그램은 사용자의 입력 등 여러 외부 요인에 의해 변화무쌍하기 때문에, 이러한 함수들이 얼마나 호출되고 또 스택 공간을 얼마나 차지할지 알수가 없기에 운영체제에서는 프로세스가 실행될 때 Stack Segement에 우선 조금의 스택을 할당하고, 부족하게 되면 이를 확장시켜주는 방식으로 동작한다. 참고할 것은, 운영체제에서 모든 프로그램에게 동일하게 스택 공간을 내어주거나 확장시켜주는 것이 아니기에 해당 프로그램의 통상적인 스택 공간을 넘어서면 그때는 우리가 종종 프로그래밍을 하다 겪는 Stack Overflow가 발생한다. (권한은 읽기 쓰기 권한이 부여된다)
- HEAP Segment
이곳은 동적 할당(Dynamic Allocation)을 통해 생성된 동적 변수가 저장되기 위한 곳이기에, 기본적으로 비어있는 상태로 존재한다. JAVA에서 'new'를 통해 동적으로 생성되는 변수가 이곳에 할당된다고 보면 된다. 운영체제는 주로 위의 나머지 4개 세그먼트를 할당하고 남은 공간에서 힙 세그먼트의 공간을 할당하며, 동적 변수가 얼마나 생기고 어느정도의 공간이 필요할지는 예측이 힘들기에 프로그램이 실행되는 중에 크기가 가변적으로 할당된다. (권한은 스택 세그먼트와 마찬가지로 읽기 / 쓰기 권한이 부여된다.)
