오늘의 목표
- JDBC
- DDD
내용
JDBC
JDBC 흐름
JDBC는 자바의 초창기 부터 제공되는 데이터베이스 엑세스를 위해 제공되는 API이며, 여러 데이터베이스와 연결될 수 있습니다.
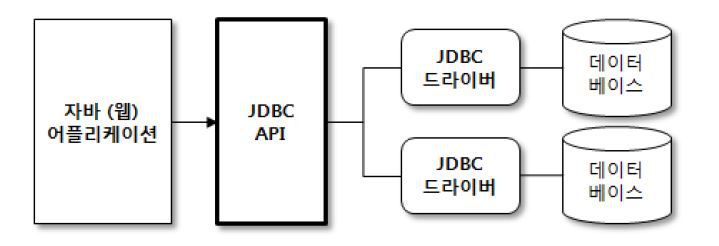
JDBC API를 이용하기 위해선 JDBC 드라이버로 데이터베이스를 먼저 로딩해야만 사용할 수 있습니다.
드라이버는 각종 데이터베이스(MySQL, Oracle, MsSQL, MariaDB등)를 연결하는 인터페이스로 특정 벤더의 데이터베이스를 구현한 구현체로 데이터베이스에 접근할 수 있습니다.
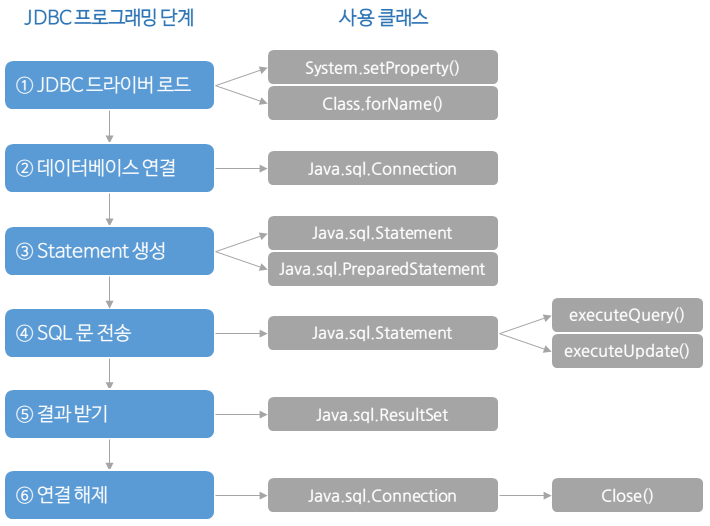
JDBC 사용순서
-
사용하고자하는 벤더의 데이터베이스를 구현하는 JDBC드라이버를 로딩합니다.
DriverManager클래스를 통해 로딩합니다. -
DriverManager.getConnection()메서드를 통하여 데이터베이스와 연결되는 세션 객체Connection객체를 생성합니다. -
Statement(정적),PreparedStatement(동적)클래스의 객체를 이용하여 SQL문으로 데이터베이스의 데이터를 조작하거나 읽어옵니다. -
SQL쿼리문의 결과는
ResultSet클래스의 객체로 전달받을 수 있습니다. -
데이터베이스 이용이 끝나면 반드시
.close()메서드로 사용하였던 객체들을 모두 연결을 해제하여 리소스를 반환해야 합니다. 데이터베이스는 무한한 접근 요청을 받을 수 없으므로 접근이 제한 됩니다. 따라서 사용직후 반환을 해야 자원이 낭비되고, 다른 클라이언트가 부득이하게 접근을 하지 못하는 경우를 방지할 수 있습니다.
Connection Pool
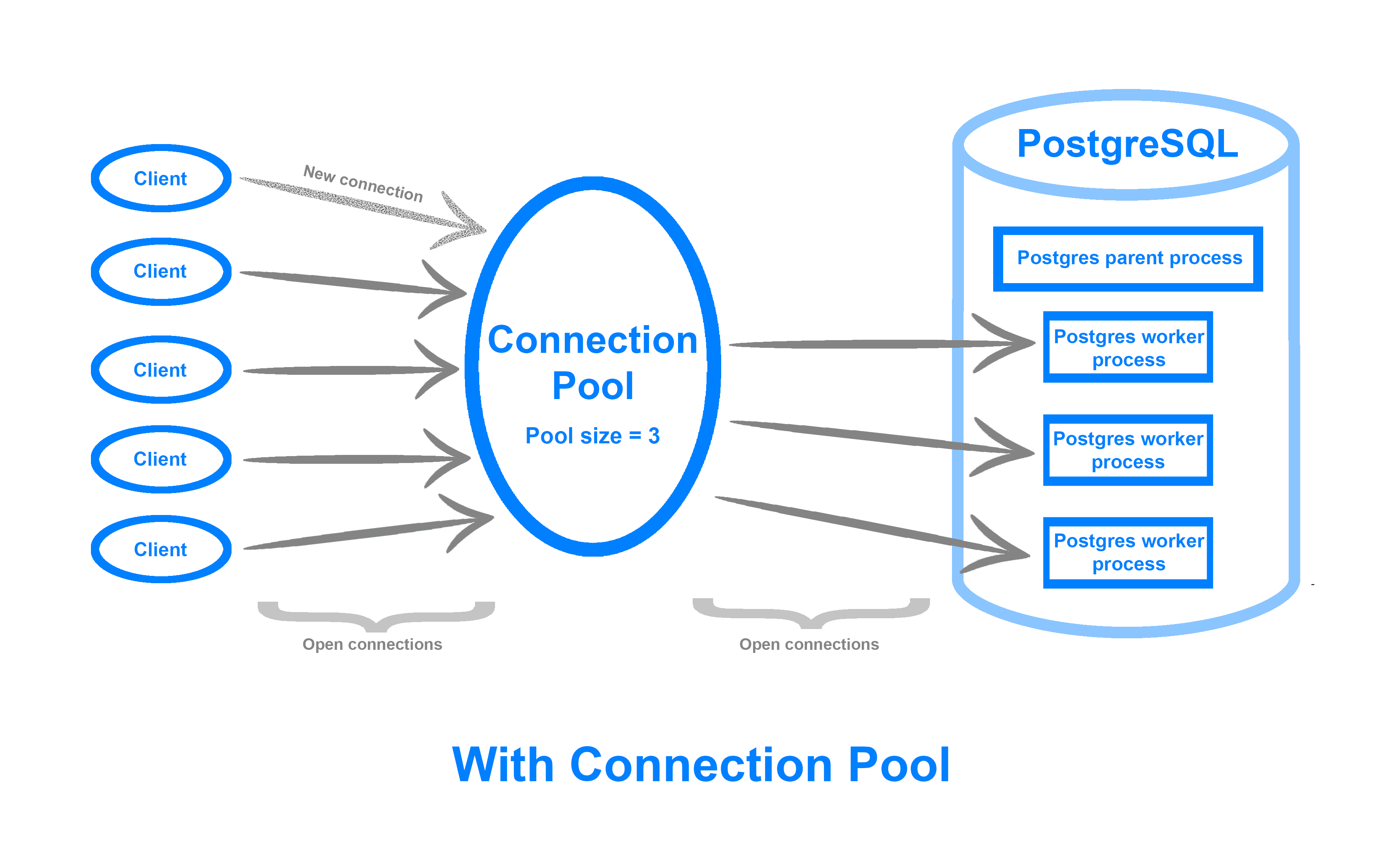
데이터베이스 접근을 위한 Connection객체를 생성하는 것은 비용이 많이 드는 작업입니다. 따라서 JDBC는 사전에 ConnectionPool이란 곳에 Connection객체를 미리 만들어 두었다가 요청시 대여를 하고 요청이 끝나면 반납을 받는 방식으로 Connection객체를 관리함으로써 성능을 향상 시킬 수 있습니다.
데이터 엑세스 기술
Spring에서 데이터 접근 계층에서 데이터베이스로의 데이터 엑세스 기술은 여러 가지가 존재하고 또 새로운 기술이 선보이고 있습니다. 가령 JDBC, Spring JDBC, Spring Data JDBC는 모두 다른 엑세스 기술이고, JPA, Spring Data JPA도 다른 기술입니다.
또 과거에 SQL중심 기술로 SQL문을 어떻게 활용하여 직접적으로 포함이 되는 방식인 SQL 중심 기술에서 객체 중심 기술로 지속적으로 이전되는 추세입니다.
JDBC -> JdbcTempalte로 드라이버 로딩, 연결해제를 자동으로 -> Spring JDBC -> ORM으로 SQL문을 직접사용하기보단 객체의 메서드로 DB조작 -> Spring Data JDBC
Spring Data JDBC는 Spring Data JPA처럼 ORM기술을 사용하지만 기술적 복잡도가 한층 더 낮은 기술입니다.
앞서 말했듯 JDBC, Spring JDBC, Spring Data JDBC, JPA, Spring JPA, Spring Data JPA는 모두 다른 엑세스 기술입니다. 물론 선행되어야 할 엑세스 기술이 있고, 사용하기 좀더 쉬운 엑세스 기술이 존재할테지만, 결과적으론 모두 익혀야 합니다.
Spring Data JDBC
의존 라이브러리 추가를 위해 build.gradle의 dependencies에 라이브러리를 추가합니다.
dependencies{
implementation 'org.springframework.boot:spring-boot-starter-data-jdbc'
runtimeOnly 'com.h2database:h2'
}Spring Data JDBC를 이용하기 위해 spring-boot-start-data-jdbc를 추가하였고, 인메모리(서버 종료시 데이터베이스 데이터가 초기화되는 메모리상의) DB인 H2를 추가하기위해 com.h2database:h2를 추가하였습니다.
application.properties 파일을 application.yml로 확장자를 변경하여 다양한 설정 정보들을 depth별로 입력할 수 있습니다.
spring:
h2:
console:
enabled: true
path: /h2
datasource:
url: jdbc:h2:mem:test
sql:
init:
scema-location: classpath*:db/h2/schema.sql| 속성 | 설명 |
|---|---|
| path: /h2 | 웹 브라우저에서 DB에 접속하기위한 주소창의 경로를 설정합니다. http:localhost:8080/h2입력시 DB접속 전 화면으로 이동합니다. |
| url: jdbc:h2:mem:test | DB로 접속하기 위한 URL을 동적이아닌 고정된 위치로 지정합니다.(해당 속성이 존재하지 않을 시 서버 실행마다 바뀜) |
| scema-location | 읽어들일 스크립트파일의 위치를 지정합니다. |
| classpath*: | src/main/resource/ 위치와 동일합니다. |
기존과 같이 컨트롤러 클래스를 만들고, DTO, 엔티티, Mapper, Service를 만들어 서비스 계층까지 만들면 이용 가능합니다.
Repository는 데이터 접근 계층으로 써 DB로 접근하기 위한 클래스이거나 인터페이스 입니다. @Repository 에너테이션을 사용하여 구현을 하여도 되지만, CrudReopsitory<엔티티, @Id타입>을 상속받은 인터페이스 만으로도 해당 계층을 구현할 수 있습니다.
public interface 레포지터리 extends CrudRepository<엔티티,@Id타입> {
}CrudRepository를 상속 받았기 때문에 CrudRepository에서 정의된 메서드들은 모두 사용할 수 있습니다. CrudRepository는 단순한 CRUD작업들을 구현해 두어서 별다른 메서드 없이 작업을 수행할 수 있습니다.
@Service
public class 서비스{
private final 레포지토리 레포지토리;
//DI주입
public 서비스(레포지토리 레포지토리){
this.레포지토리 = 레포지토리;
}
public 엔티티클래스 create엔티티(엔티티클래스 엔티티객체){
return 레포지토리.save(엔티티객체);
}
}서비스에서 레포지토리 객체를 DI를 통해 주입받고, 해당 레포지토리의 메서드를 엔티티객체를 매개변수로 실행함으로써 DB에 값을 저장할 수 있습니다.
save()메서드는 CrudRepository.save()로 이미 정의되어 있습니다.
CrudRespository의 두번째 제네릭타입의 @Id타입은 데이터베이스에서 Primary Key가 될 속성의 엔티티 클래스의 멤버 변수 타입을 지정합니다.
@Getter
@Setter
public class 엔티티클래스{
@Id
private long messageId;
private String message;
}Spring Data JDBC는 ORM기술을 이용하여 SQL보단, 객체를 이용하여 데이터베이스를 조작합니다. 그러기 위해선 클래스와 테이블을 몇가지 규칙으로 일치시켜야 에러가 발생하지 않을 것입니다.
'엔티티클래스'클래스는 '엔티티클래스'테이블과 매핑되고, 엔티티클래스의 messageId는 데이터베이스의 message_id와 매핑되고, 엔티티클래스의 message는 데이터베이스의 message와 매핑됩니다.
@Id에너테이션이 있는 멤버변수는 테이블의 Primary Key입니다.- 클래스의 이름과 테이블의 이름은 동일해야 합니다.
- 클래스의 멤버변수와 테이블의 속성명이 동일합니다.
- 멤버변수의
대문자는 테이블의_소문자로 일치하고 인식합니다.
이외에도 많은 규칙들이 존재합니다.
Spring Data JDBC 순서
- build.gradle에 사용할 데이터베이스를 위한 의존 라이브러리를 추가합니다.
- application.yml 파일에 사용할 데이터베이스에 대한 설정을 합니다.
- ‘schema.sql’ 파일에 필요한 테이블 스크립트를 작성합니다.
- application.yml 파일에서 ‘schema.sql’ 파일을 읽어서 테이블을 생성할 수 있도록 초기화 설정을 추가합니다.
- 데이터베이스의 테이블과 매핑할 엔티티(Entity) 클래스를 작성합니다.
- 작성한 엔티티 클래스를 기반으로 데이터베이스의 작업을 처리할 Repository 인터페이스를 작성합니다.
- 작성된 Repository 인터페이스를 서비스 클래스에서 사용할 수 있도록 DI 합니다.
- DI 된 Repository의 메서드를 사용해서 서비스 클래스에서 데이터베이스에 CRUD 작업을 수행합니다.
DDD(Domain Driven Design)
도메인 주도 설계정도로 해석이 가능하며 도메인을 위주로 설계하는 기법을 의미합니다. 매우 어려운 기법이므로 한번에 모든것을 익힌다가 아니라 경험을 쌓아간다고 생각해야합니다.
도메인(Domain)
도메인이란 하나의 비즈니스 로직, 업무 영역으로 정의할 수 있겠습니다. 예를들어 배달음식을 주문한다고 할때 과정별로 도메인 지식들을 비즈니스 로직으로 구현해야 합니다.
“도메인이란 용어 자체는 한 마디로 우리가 실제로 현실 세계에서 접하는 업무의 한 영역이다”
애그리거트
애그리거트는 비슷한 도메인끼리 묶은 그룹입니다.
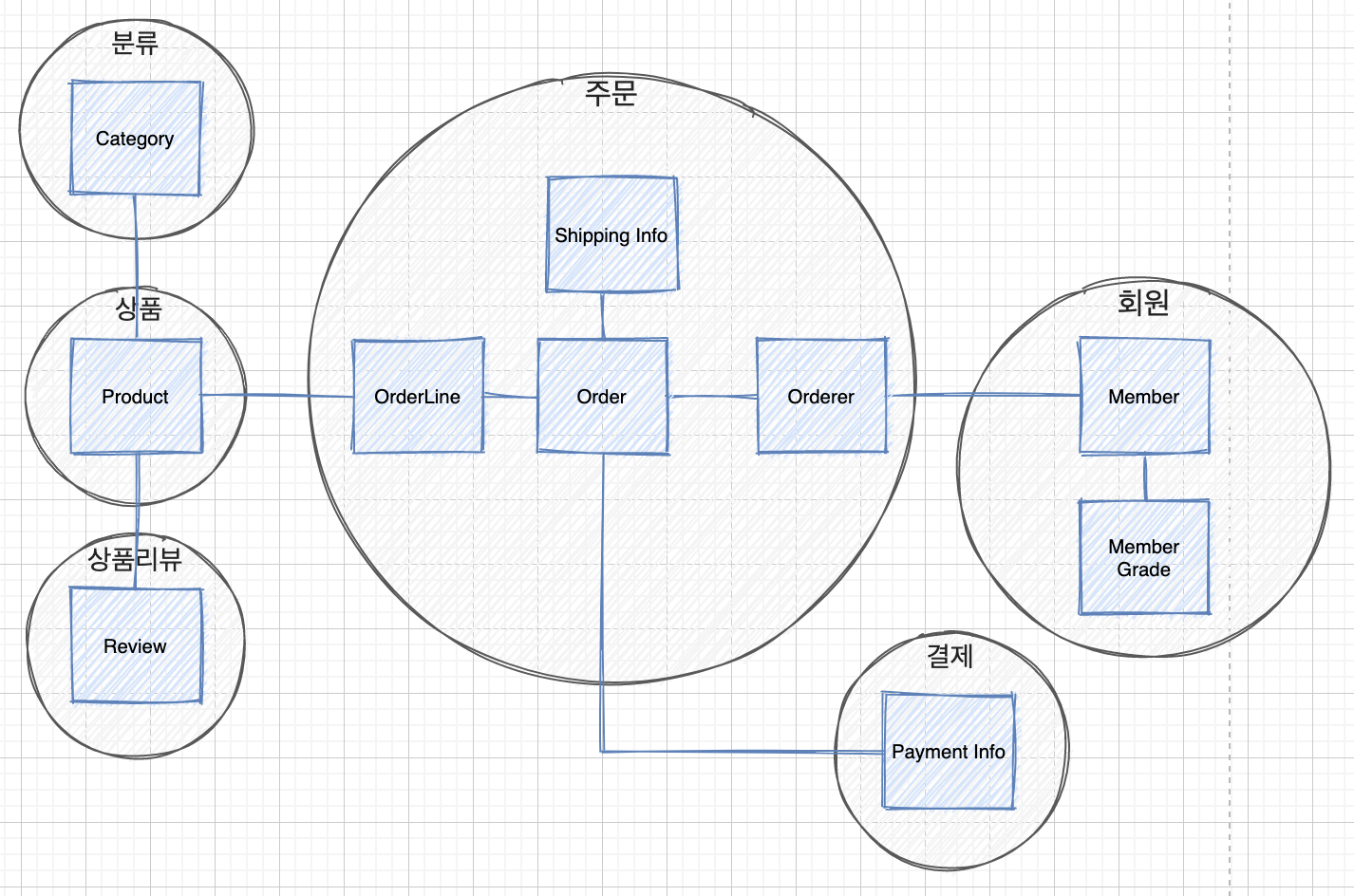
주문을 한다고 하면 주문 번호, 주문 회원 정보, 배달 정보, 주소 정보 등 도메인들이 주문이라는 애그리거트에 묶일 수 있습니다.
같은 애그리거트내에 존재하는 도메인들은 비슷한 업무를 수행합니다.
애그리거트 루트(Aggregate Root)
도메인은 업무의 한 영역, 애그리 거트는 비슷한 일을 하는 도메인의 그룹이라하면 애그리거트 루트는 애그리거트를 대표하는 도메인을 의미합니다.
아파트의 1동,2동,3동을 애그리거트, 각 동의 주민들을 도메인이라 하면 동대표를 애그리거트 루트라고 보면 되겠습니다.
관계형 데이터베이스에선 에그리거트 루트는 부모 테이블이 되고, 같은 애그리거트에 존재하는 다른 도메인들은 자식 테이블이 됩니다.
즉, 다른 도메인들은 외래키로 애그리거트 도메인의 키를 사용합니다.
엔티티 클래스 간의 관계
엔티티 클래스에선 다른 도메인과의 관계를 표현할때 List를 이용하여 1:N 관계를 표현합니다. N:N은 새로운 클래스를 하나 만들어 1:N, N:1로 나뉘어야 합니다. 1:1은 변수를 사용하거나 클래스를 합칩니다.
데이터베이스 테이블 간의 관계
데이터 베이스에선 다른 도메인과의 관계를 표현할때 외래키를 이요하여 1:N관계를 표현합니다. N:N은 새로운 테이블을 하나 만들어 1:N, N:1로 나뉘어야 합니다. 1:1은 외래키를 사용하거나 테이블을 합칩니다.
후기
마지막 계층인 데이터 접근 계층을 오늘 처음으로 학습하였습니다. 아직 Spring Data JDBC를 제한적으로만 학습하였지만 앞으로 더 많은 엑세스 기술들을 학습하여 지식의 폭을 넓혀나가겠습니다.
GitHub
없음!
