알파고 최근에 본사람없음 -> 한 순간에 없어짐
돈이 안되서 2017년에 알파고 프로젝트가 종료되서 기계 다분해함
AGI (Artificial General Intelligent) : 자비스
프젝에 자비스 넣지말자 (너무흔하다)
GAN(Generative Adversarial Network) : 2014년에 나옴
How can generative adversarial networks (GANs) learn real life distributions easily?
이미지 생성 : random gaussian부터 작업을 시작한다. 이미지 여러장이 있으면 통째로 넣어서 바꿔준다 (change color, add grass, rotate change type) 이 쪽이 좀 빡셈, 국내에서는 네이버가 좀 한다고 덤비는데 언발에 오줌누기 수준이고 통신사 skt, 카카오, kt가 연합해서 돈을 끌어 모아야 될 까 말까다.
방법 1 : 잘되있는걸 따라 쓰는 것 >> OpenAI, MS, Meta, Google
방법 2 : 잘되있는걸 튜닝해서 쓰는 것
방법 3 :
https://abiaryan.com/posts/intro-llms/
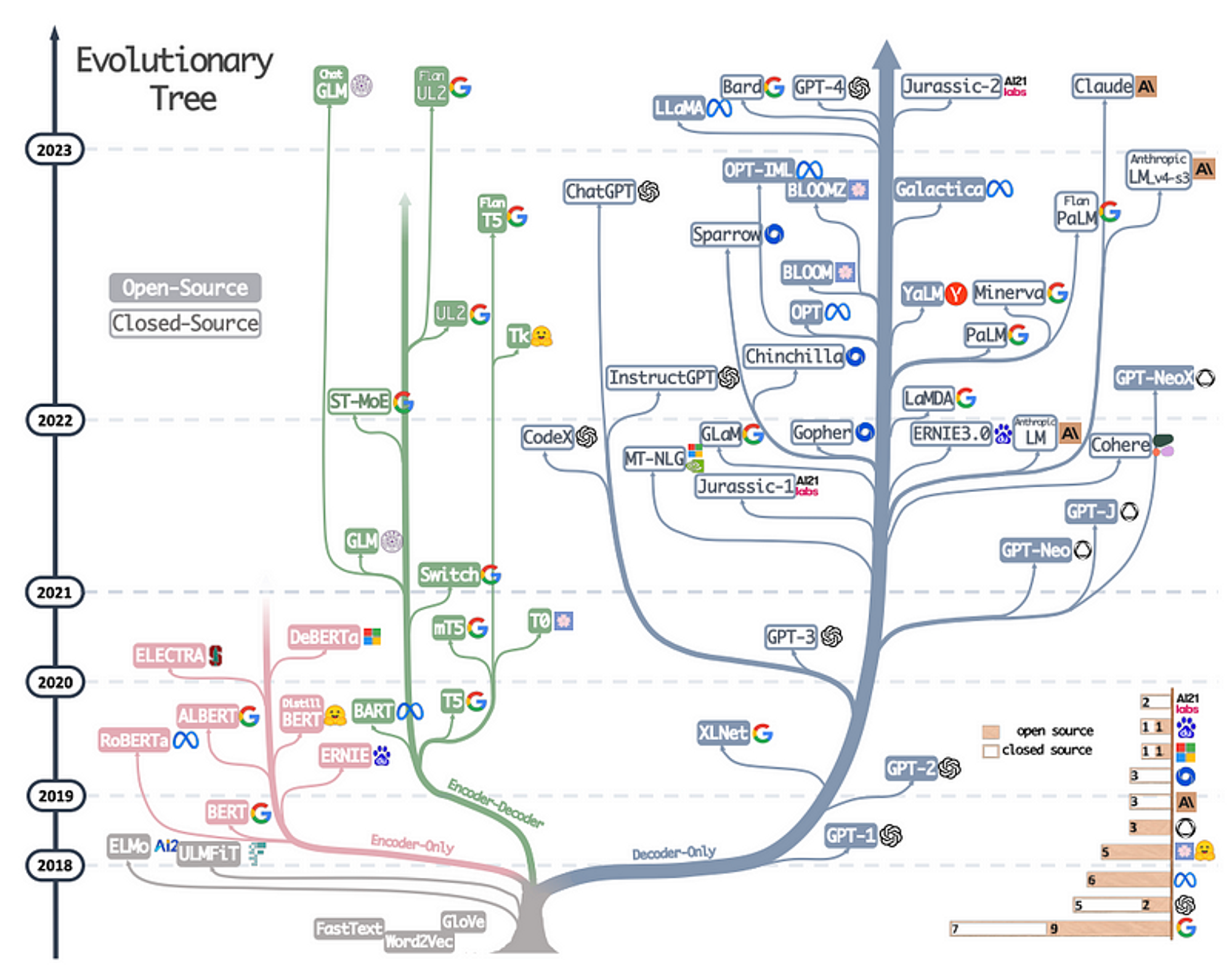
LLaMA : Meta 모델 > 1300억듬 하나만드는데, GPT3 : EPOCH 한 번 돌리는데 20억듬 => 돈도 실력이다.라고 누가 말함
DALL-E : 이미지 생성형 AI
Whisper : 사람들의 음성을 들어서 text로 변환됨(쉽지않음) 동영상을 넣으면 자막파일 자동으로 만들어지는 프로그램 있음
캘리포니아 미술 대회 : 80시간 동안 대화하면서 만든 모델 창의적인 작품이라는대 이견없다고 인정해줌 midjourney로 만듬
https://www.midjourney.com/home?callbackUrl=%2Fexplore
이미지 생성에 특화된 업체, 처음부터 유료(퀄리티만 보면 여기가 좋음) -> midjourney 기업체에서 많이씀, 디자이너 10명 중 8명을 짜름(고급 일자리들을 뺏어감)
국내 업체들 : 허접함
카카오톡 : 카카오 대화 내용을 긁어서 학습 시키면 좋은 모델이 나옴 -> 대신 이걸 사용하면 불법(개인정보침해)
SSG : STT로 텍스트를 뽑아서 학습시킨 다음에 모델을 만듬(챗봇운영중)
말뭉치(학습데이터) GPT의 겨우 크롤링을함(일반 크롤링 4200억 개의 토큰, 190억개의 토큰, 책1,2 : 670억개의 토큰(인터넷 이전의 자료들), 위키백과 30억개 3%) -> GPT3의 데이터, GPT4 부터는 오픈을 안함
토큰? 가운데 구멍뚫린 동전, NLP에서는 토큰(기본 단위) = 단어
tokenizer
https://platform.openai.com/tokenizer

150개의 토큰, 734개의 문자 : 과금 단위가 token이다. color가 바뀌는 지점이 token이 바뀌는 지점이다. 단어는 하나인데 의미는 바뀌는 부분이 있어서 token이 단어 중간에 바뀐다. ( 괄호 칸도 토큰 하나먹음, 마침표도 토큰 하나먹음 << 되도록 prompt에서 안쓰게 주의하는게 나을듯. 대충 단어수 * 1.3 한게 토큰 수가 된다(평균). 분당 사용할 수 있는 토큰수가 있음 tpm(token per minute)이걸 넘으면 시스템이 멈춘다. 언어 모델들을 잘 뭉쳐두면 학습이 잘됨? 아님, 가중치 무한 ( ) : 도전이 올 가중치가 제일 높다. 1박 뒤엔 2일이 올 확률이 제일높음, 전국 다음엔 노래자랑이 제일 높게 나옴(이건 근데 시켜보면 다 다름, 상황에 맞는게 나옴) 문장 가운데가 있으면 mask tape으로 가려둔다.
아름다운 ( ) 강산, 동해물과 ( ) 마르고 닳도록, 사랑하는 ( ) 가족 << masking 기법을 이용함. BERT모델이 대표적으로 이런 예임. 최근 MS에서 직원 만명을 짜른다고 통보함(사람 짜르면 주가올라감). BERT 구글사의 모델은 학습 량이 많을 수록 발전속도가 느려짐 학습량이 많아지면 제곱으로 발전속도가 느려짐, GPT는 학습량이 많을수록 그런게 별로 없음. 말뭉치를 모아둔게 LM, 많이 모아둔게 LLM, 너무 키워두니까 학습시키기 어려워서 최근에는 반대로 가고있음, sLLM : 성능은 떨어져도 light하게 만들어서 작게 만든 다음에 핸드폰에 넣어둠. 초 거대모델 < 공부 안한애, 초 언어 모델 이런건 없음 공부안한 애들이 쓰는 표현들 절대 초 넣으면 안됨. 언어 모델의 크기 : parameter의 개수가 나옴. MS가 openai에 1조 3천억 투자하고, Azure까지 내놔서 물 올라감. 작년에 14조 또 투자함 ㅁㅊ 지금도 미친듯이 발전하고있음. 발전속도가 빠르면 불안함, 독점 하는거 보고 이사회에서 샘알트만 CEO해고 하는 사태가 있었음. open ai 직원중 700명중 500명이 MS로 간다는 기사까지 나왔음. open ai로 다시 복귀함 5일만에-> 이사회가 짤림. 윈도우 폰 14조 해서 망했지만, cloud 독점권 가짐. 개이득받음, Knowledge Transfer, 언어 모델을 잘만들어두면, trasfer을 통해 감정분석, 문서요약, 번역, 질의 응답, 작문, 문장 재구성 등 여러 기능을 할 수 있음.
GPT 3버전과 4버전의 가장 큰 차이 : 3은 언어 모델만 있지만, 4는 멀티 모달 결과를 낸다. vision 성능이 있음. 3.5와 4 사이에는 엄청 큰 괴리감이 있다. 문서나 보도자료, proposal을 넣어보면 굉장히 잘해준다.
prompt를 어떻게 잘 쓸수 있는지를 고민하는게 prompt Engeeniring이라고 한다. gpt한테 배달의 민족 리뷰를 보여주고 사람의 기분이 많이 상한 정도를 숫자로 표현하게 해줌 -> 지금 배달의 민족이 실제로 이 기능을 쓰고있음.
prompt : "음식이 맛있어요. 포장 상태도 좋았어요. 그런데 양이 좀 부족했어요." 이 글에서 느껴지는 감정을 문장별로 좋으면 1 안좋으면 0으로 표현해줘
질문을 이렇게하면 일반적인 대답을 함.
prompt컨트롤이 중요하다.


번역기능은 굉장히 뛰어남.
문장을 친근하게 바꿀 수도 있음.// 메일 보낼때도 유용하다.

Chatgpt의 한계 : 3버전은 2021년 9월에 학습이 멈췄다.
// 거짓말 시킬 수 도 있음
// Hallucination이라고함, 이를 피해가야됨
피해갈수 있는 방법


AI로 직접 일을 시키는거보다 AI로 사람을 감시하는게 더 효율이 높게 나옴.
- Search Engine을 같이 붙여쓰는것
- MS가 openai의 독점권을 가지고 있어서 같이 쓸 수 있음, gpt덕분에 MS의 gpt활용 검색엔진인 bing의 점유율이 3프로에서 10프로까지 올라왔음. Google의 점유율 현재 90%. 구글이 최근에 Gemini를 내놓음
-
Open-ai : 비영리 단체라고 지네가 홍보해둠, DALL-E 2 같은거 살려면 GPU가 매우 중요하다. GPU요새 귀함, 데이터센터용 으로 받을려면 6개월이 걸린다. Meta랑 MS가 250만장 사갔음, 구글은 Tensorflow Process Unit(TPU)가 있어서 50만장만 사감. DALL-E
-
Bing에서 Image Creator를 사용 -> prompt를 입력 받으면 그림을 그려준다.
-
Open-ai Codex : 한 달에 4만원내면 쓸 수 있음. 비슷한게 GitHub Copilot이 있음. copilot 그냥 저냥 쓸만함. 다음 버전 copilot-x가 좀 쓸만함. 윈 11에 코파일럿이 그냥 들어와있음 곧 copilot을 윈도우 앱들에 다 심으려고 함
-
GPT model : Meta에서 만든 Lama 모델은 오픈소스가 다 공개 되어있음, Lama를 fine tuning해서 사용해도됨, gpt4가 되면 gpt3.5부터 성능이 배가된다. API 호출해서 DALL-E를 사용하는 경우도 있음. Deprecated : 예전에 사용하는 모델들 잘안쓰이는건 없어지고 있고 모델들은 지속적으로 업데이트 되고있음. gpt - turbo : turbo옵션이 붙는이유 : 성능을 개량한 버전임, turbo를 사용해서 1만개처리하다 1.5만개로 늘면 시간이 줄어들어서 어찌보면 비용이 절약되는 효과가 나타난다.
gpt-4-32k-0314 : 32k(token수들) -
GPT-4
gpt4의 세상으로 넘어가고있으며, 결국 GPU 싸움이다(학습 시간 싸움). GPU를 어떻게하면 더 적게 쓰고 학습 시킬수 있을지? -> 언어 모델을 작게해서 성능을 최대한 비슷하게 하기(줄이기), 학습할때는 nvidia쓰는데 운영할때는 운영전용 칩을 만들어서 박기, edge device용 칩을 박는다. NPU사용
-
GPT-3.5
turbo모델은 대화가 가능함. 반면 일반 모델은 안됨.
InstrcutGPT의 RLHF(Reinforcement Learning from Human Feedback) : 반사회적, 패드립, 욕같은 것들 필터를 달아줘서 걸러내줌(사람을 직접 갈아넣음) Reinforcement Learning Human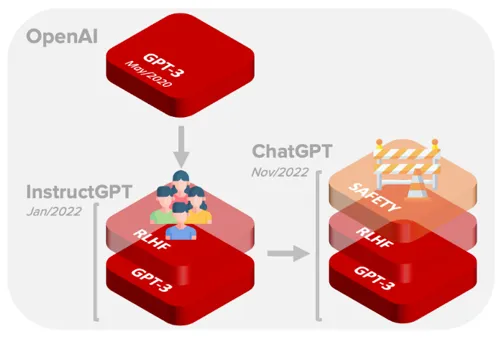
Azure는 SAFETY 필터도 하나 더 걸어놨음. -
Whisper
위스퍼도 꽤 좋은 성능을 냄, skt에서 사용하는 에이닷이 위스퍼랑 비슷함. skt에서는 적당한 선에서 끊은거 같음. 글자를 받아쓰는데 이상한쪽으로감
LLM의 한계
-
N-Shot Learning
언어 모델한테 대충 내가 물어보는 내용을 몇 번 알려주는 기법임, 한번이면 원샷, 한 번도 안물어보면 제로샷, 여러번 물어보면 퓨샷이라고한다.
zero-shot, one-shot, two-shot, few-shot -
Fine-tuning
기존의 언어 모델들을 이용해서 적절하게 바꿔주는것, 대부분의 경우에는 fine tuning을 안해도 됨 돈이 많이 들기 때문이다. Fine tuning은 json파일을 만들어서 대화 하듯이 밀어 넣고 데이터를 알려주면 파인튜닝이 되는 것이다.
*문제 : 비용(GPU), 운영, 모델의 업데이트, 내부 인력 -
RAG(Retrieval Augmented Generation)
ex) pdf 챗봇 구축 : 문서를 기반으로 챗봇을 구축할 경우, 아래와 같은 과정을 통해 대화가 가능하도록 한다.
순서 : 문서업로드 -> 문서 분할 -> 문서 임베딩 -> 임베딩 검색 -> 답변 생성 -
LangChain, Semantic Kernel
-
Azure를 통해 openai모델 사용하는게 더 안정적이고, 최근 데이터 센터 지은게 스웨덴이라 리소스그룹 영역을 이쪽 쓰는게 나음
-
개별적으로 만들려면 스토어 가서 Azure OpenAI 만들면 나옴
-
생성이 안되면 폼을 작성하면됨. GPT를 많이 써야됨. 지금부터 계정을 만들어서 생성을 해봐야된다.
-
embbeding-ada-002 모델은 매우쌈 오픈소스 모델을 이용해서 무료로 해볼 것.답을 생성할때는 gpt-35-turbo모델을 사용할 것이다. 모델 버전 - 나온 날짜, TPM : Token Per Minute
-
피사체 심도
피사체 심도가 얕다는 뜻은 피사체에 포커스를 집중해 뒤의 배경이 흐릿해진다는 뜻이다. 인물 사진 찍을 때 주로 사용한다.
-
모션블로
펭귄이 빨리날아가는 효과를 주기위해 모션블로를 준것이다.
-
카메라 렌즈
관광렌즈 ,어안렌즈, 물고기렌즈 등 카테고리만 지정해줘도 효과가 나타난다. 사진 찍을때 렌즈 정보가 들어가므로 이를 학습해서 렌즈 느낌을 알고 있는것이다. 해질녘 펭귄 :
It's golden hour 프롬프트 추가하면 이를 나타낸다.
cloudy weather : 흐린날의 펭귄이 나옴.
이처럼 prompt에 문장을 추가하면 이를 반영해서 DALL-E와 같은 생성형 AI모델이 이미지를 생성해준다.
