1.임베딩(Embedding)
-
임베딩이란 사람이 사용하는 언어(자연어)를 컴퓨터가 이해할 수 있는 언어(숫자) 형태인 벡터(vector)로 변환한 결과 혹은 일련의 과정을 의미
-
임베딩 역할은 1. 단어 및 문장 간 관련성 계산, 2. 의미적 혹은 문법적 정보의 함축(ex 왕-여왕, 교사-학생)이다.
-
임베딩 방법에 따라 희소 표현 기반 임베딩, 횟수 기반 임베딩, 예측 기반 임베딩, 횟수/예측 기반 임베딩이 있음
-
예측 기반 임베딩은 신경망 구조 혹은 모델을 이용하여 특정 문맥에서 어떤 단어가 나올지 예측하면서 단어를 벡터로 만드는 방식
-
대표적으로 워드투벡터(w2v)가 있음
-
w2v는 문맥에 있는 단어를 다른 단어들을 이용해서 예측하는 것임
-
This book is my ( ) <- w2v로 예측(문맥을 읽어서 예측한다)
-
nltk -> nlp쪽에서 token화를 도와주는 library
-
sent_tokenize, word_tokenize : 문장, 단어를 token으로 쪼개주는 library
-
w2v는 두가지 방식이 있음, 가운데 단어를 통해서 문맥단어를 예측하는 방법, 문맥단어들을 이용해 가운데 단어를 예측함
-
CBOW(Continuous Bag Of Words) : 문맥단어들을 이용해 가운데 단어를 예측함, 모든 단어 집합을 one-hot encoding을 해주고 입력층, 은닉층, 출력충, 세 개를 쌓아서 구조를 이룸.
-
Word Analogies : King[0.3 0.7] - Man[0.2 0.2] + Woman[0.6 0.3] = Queen[0.7 0.8] (대충 말장난 좌표로 계산)
-
sg(skip gram) : 중간단어로 문맥단어를 예측
-
예측 기반 임베딩
-
사전에 없는 단어에 벡터 값을 부여하는 방법
-
패스트 텍스트는 주어진 문서의 각 단어를 n-gram으로 표현하고, n의 설정에 따라 단어의 분리 수준이 결정한다. 예를 들어, n을 3으로 설정(트라이그램(trigram)하면 'This is Deep Learning Book'은 This is Deep, is Deep Learning, Deep Learning Book으로 분리한 후 임베딩한다.
-
peter.txt로 예제 학습
-
글로브(Glove, Global Vectors for Word Representation)는 횟수 기반의 LSA(Latent Sematic Analysis) 잠재 의미 분석과 예측 기반의 w2v 단점을 보완하기 위한 모델, 글로브는 그 이름에서 유추할 수 있듯이 단어에 대한 글로벌 동시 발생 확률 정보를 포함하는 단어 임베딩 방법이다.
-
즉, 단어에 대한 통계 정보와 skip-gram을 합친 방식이라고 할 수 있음
-
다시 풀어서 이야기하면 skip-gram 방법을 사용하되 통계적 기법이 추가된 것이라고 할 수 있ㅇ므
-
글로브를 사용하면 다음 그림과 같이 단어 간 관련성을 통계적 방법으로 표현해줌
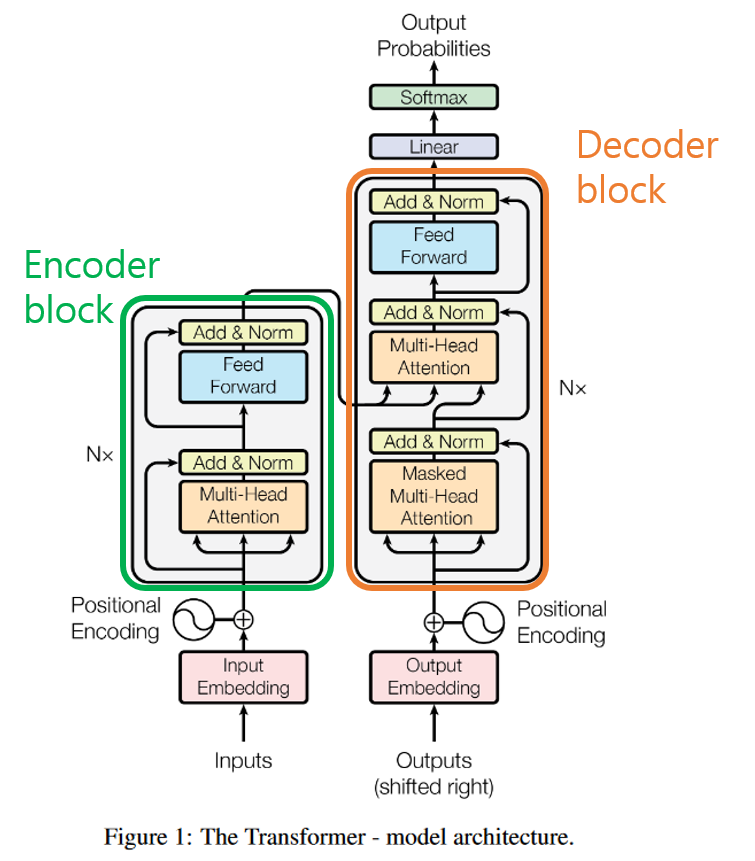
2. 트랜스포머(Transformer)
RNN
- Long-term dependency problem
- No Parallelization(병렬연산안됨)
- 박찬호한테약함(말많으면 분석을 못함)
Self-Attention
- 문장을 이해하기위해 문구에 집중한다.
- encoder : 액기스만 받아주는거 input
- decoder : 받은 액기스를 풀어주는것 output
BERT : encoder로만 이뤄져있음 & 문서분류, 감정분류 주
GPT : decoder로만 이뤄져있음 & 말을 계속 뱉어냄
Transformer : self-attention 도입, en + de로 이뤄져있음
인코더 입력
1. Input Embedding
- inputs에 입력된 데이터를 컴퓨터가 이해할 수 있도록 행렬 값으로 바꿔 줌
- Input Embedding 레이어는 인덱스 값들을 받아 이를 각각의 단어 임베딩 벡터값으로 바꿔준다.
트랜스포머와 RNN의 다른점은 단어가 순서대로 들어온다는 점이다.
- Positional Encoding
- 트랜스포머는 입력되는 문장을 순차적으로 처리하지 않고 병렬로 한번에 처리하기 때문에 단어의 위치 정보를 다른 방식으로 알려줘야 함
Scaled Dot-Product Attention
- cossim(Q, K)로 두 벡터를 곱해서 벡터의 크기로 나눠서 sim정도를 파악한다. Softmax를 곱하면 유사성을 확률로 변환해준다. Attention = 쿼리 키 값 = Q, K 내적으로 단어간 유사성을 구하고 V(중요도)를 곱해서 중요하고 관련있는 단어에 더 관심을 둔다.
ex) Q = 나는 너를 매우 사랑해. K, V = I love you so much.
Attention(Q, K, V) = softmax(QK^T / (dk)^(1/2)) * V
Multi-Head Attention
- 해석의 다양성을 존중하는 Attention, 여러 관점에서 attention을 달리줌
