![]()
1. 목표
A. 과제 목표
- Kubernetes 이해하기
- Kubernetes에서 배포되는 서비스(Grafana, FTPS, MySQL & InfluxDB 등) 이해하기
- 각 서비스의 컨테이너 배포방법 파악하기
- yaml 파일 작성법 파악하기
B. 과제 설명 번역
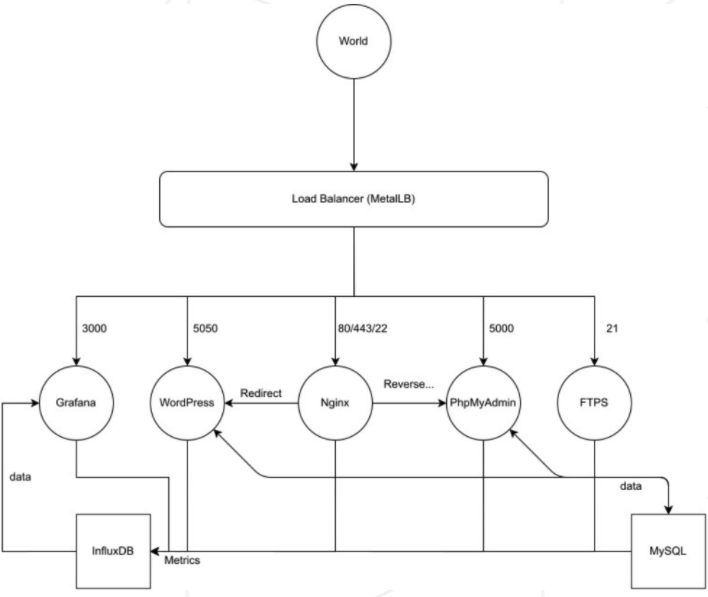
- 다음 조건을 고려하여 Kubernetes 클러스터를 구축해야 한다.
- 과제의 서비스들은 각 컨테이너로 동작해야 한다.
- 각 컨테이너는 Alpine 기반으로 동작해야 한다.
setup.sh파일은Dockerfile을 통해 각 서비스의 image를 만들어야 한다.- 클러스터를 관리하기 위해 Kubernetes dashboard를 활용할 줄 알아야 한다.
- 외부에서 서비스로 접근하기 위해 Load Balancer를 활용해야 한다.
- Load Balancer는 클러스터로의 유일한 진입점이고 하나의 외부 IP를 가져야 한다. 그리고 포트로 클러스터 내부의 서비스들을 구분해야 한다.
- Wordpress는 5050번 포트를 사용해야 하고, MySQL 데이터베이스를 사용해야 한다. Wordpress와 MySQL은 개별 컨테이너에서 동작해야 한다.
- Wordpress 웹사이트는 몇 개의 user들과 관리자가 있어야 한다.
- Wordpress는 개별 nginx 서버가 필요하다.
- Load Balancer가 Wordpress로 redirect 해야한다.
- phpMyAdmin은 5000번 포트를 사용해야 하고, MySQL 데이터베이스와 연결되어야 한다.
- phpMyAdmin은 개별 nginx 서버가 필요하다.
- Load Balancer가 phpMyAdmin로 redirect 해야한다.
- nginx 서버 컨테이너는 80번 포트와 443번 포트를 사용해야 한다.
- nginx 서버 컨테이너에서 http를 지원하는 80번 포트는 301 type으로 https를 지원하는 443번 포트로 redirect 되어야 한다.
- nginx 서버 컨테이너는
/wordpress경로로 접근할 경우IP:WPPORT로 307 redirect 되어야 한다. - nginx 서버 컨테이너는
/phpmyadmin경로로 접근할 경우IP:PMAPORT로 reverse proxy 해야 한다. - FTPS 서버는 21번 포트를 사용해야 한다.
- Grafana는 3000번 포트를 사용해야 하고, InfluxDB 데이터베이스를 사용해야 한다.
- Grafana는 클러스터 내의 컨테이너들을 모니터링할 수 있어야 한다.
- Grafana에서 각 서비스마다 한 개의 dashboard를 만들어야 한다.
- Grafana와 InfluxDB는 개별 컨테이너에서 동작해야 한다.
- MySQL, InfluxDB 두 개의 데이터베이스에 문제가 생겨도 데이터는 유지되어야 합니다.
- 모든 컨테이너들은 문제가 발생할 시에 재시작되어야 한다.
- FTPS, Grafana, Wordpress, PhpMyAdmin, nginx 오브젝트의 type은 Load Balancer이다.
- InfluxDB, MySQL 오브젝트의 type은 ClusterIP이다.
- NodePort가 존재해선 안된다.
kubectl port-forwardcommand는 금지된다.- 해당 과제에서 Load Balancer 사용을 위해 MetalLB를 활용하는 것이 좋다.
- 오역이 있을 경우, 댓글로 알려주세요!
2. 사전 학습
A. Kubernetes 개요
1) Container Orchestration
44BITS의 유튜브 : https://youtu.be/SNA1sSNlmy0
- 초기의 서버 관리 방법
- 문서화? 버전 업데이트가 어렵다.
- 서버 관리 도구의 등장(CHEF, puppet, ANSIBLE) : 어떤 프로그램을 설치할 지 판단해주는 도구(개발자 대신 명령어를 날려줌) > 도구의 사용법도 따로 공부해야하고 서버 관리의 난이도가 높을수록 도구 활용의 난이도가 높아짐.
- 가상머신(Virtual Machine)의 등장 : 가상 머신 1개에 1개의 프로그램만 있으므로 충돌우려가 없고 필요 시, 여러 가상머신을 파일 하나로 묶어서 쓸 수 있음 > 클라우드 환경에 안맞고 특정 vendor에 의존성이 생김. 그리고 컨테이너에 비해 느림.
- Docker의 등장 : 대부분의 서버 관리의 단점을 보완해줌.(프로그램의 컨테이너화)
- 컨테이너의 특징
- 가상머신과 비교하여 컨테이너 생성이 쉽고 자원사용이 효율적임
- 컨테이너 이미지를 이용한 배포와 롤백(버전 다운그레이드?)이 간단
- 언어나 프레임워크에 상관없이 애플리케이션을 동일한 방식으로 관리
- 개발, 테스팅, 운영 환경은 물론 로컬 pc와 클라우드까지 동일한 환경을 구축
- 특정 vendor에 의존성이 없음
- Docker 등장 이후 서버 관리 방법(정형화 됨)
- 개발자는 코드를 작성함
- 작성된 코드는 docker image로 build 됨
- docker hub에 image가 저장됨
- image를 run해서 컨테이너화 시킴
-
Container Orchestration의 등장
: 복잡한 컨테이너 환경을 효과적으로 관리하기 위한 도구, 관리할 docker container가 많을수록 관리가 까다로워져서 등장하게 됨. -
Container Orchestration의 특징
- Cluster
: 다양한 사양의 서버들을 cluster 단위로 추상화 시켜 관리함. master 서버를 하나 두고 관리자가 master 서버를 통해 cluster 내부의 node에 접근함. cluster 내부의 node간 네트워킹이 형성됨. - State
: 특정 프로그램에 대한 몇 개의 컨테이너를 사용할지 자동으로 판단해줌. 특정 컨테이너에 문제가 생겼을 때도 대신 처리해줌. - Scheduling
: 여러 서버에 어떤 프로그램이 있는지 자동으로 체크해주고 어느 공간이 적절한지 스스로 판단한 후 특정 프로그램을 적절한 공간에 자동으로 넣어줌. 적절한 공간이 없다고 판단할 시에 자동으로 컨테이너를 하나 더 생성해서 공간을 만들어줌 - Rollout Rollback
: 버전 관리, 프로그램에 관련된 컨테이너들을 한꺼번에 버전 다운시키고 업시킬 수 있음 - Service Discovery
: 특정 서버에 특정 웹이 등록 되고 이를 계속 관찰해주는 proxy 서버가 특정 웹이 변경될 때마다 자동으로 설정을 갱신해줌 - Volume
: 특정 서버에 특정 storage(ex. google cloud)를 자동으로 연결시켜 줌
- Kubernetes는 위와 같은 Container Orchestration의 특징을 모두 갖는다.
2) 왜 Kubernetes인가?
- 구글 + 여러 대형회사들이 개발에 참여 : 다양한 경험들과 기술들이 녹아있다. 서비스메시(Istio, linkerd), CI(Tekton, Spinnaker), 컨테이너 서버리스(Knative), 머신러닝(kubeflow)이 모두 쿠버네티스 환경에서 돌아간다.(클라우드 네이티브 애플리케이션 대부분이 Kubernetes와 찰떡이다.)
- 다양한 배포방식이 있다 :
Deployment,StatefulSets,DaemonSet,Job,CronJob등의 다양한 배포방식을 지원한다. 각 서비스별 필요한 기능에 따라 배포방식을 골라 쓰면 된다.
3) Kubernetes 파헤치기
조대협님의 블로그에 게재된 Kubernetes 관련 글을 참고할 것이다.
https://bcho.tistory.com/1256?category=731548
A) 클러스터의 구조
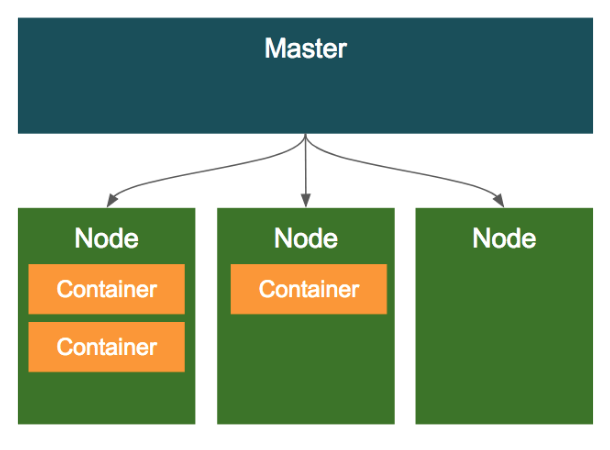
- 클러스터는 클러스터 전체를 관리하는 1개의
Master와 여러개의Node(컨테이너가 배포되는 머신 ex. 가상머신이나 물리적인 서버머신)로 구성된다.
B) 클러스터 관리 프로세스
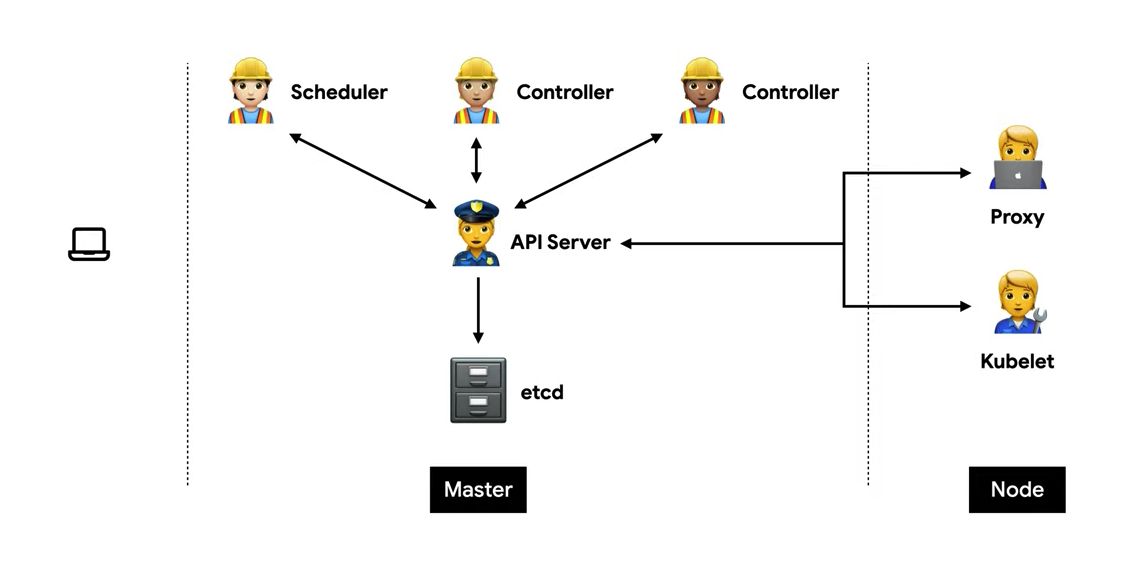
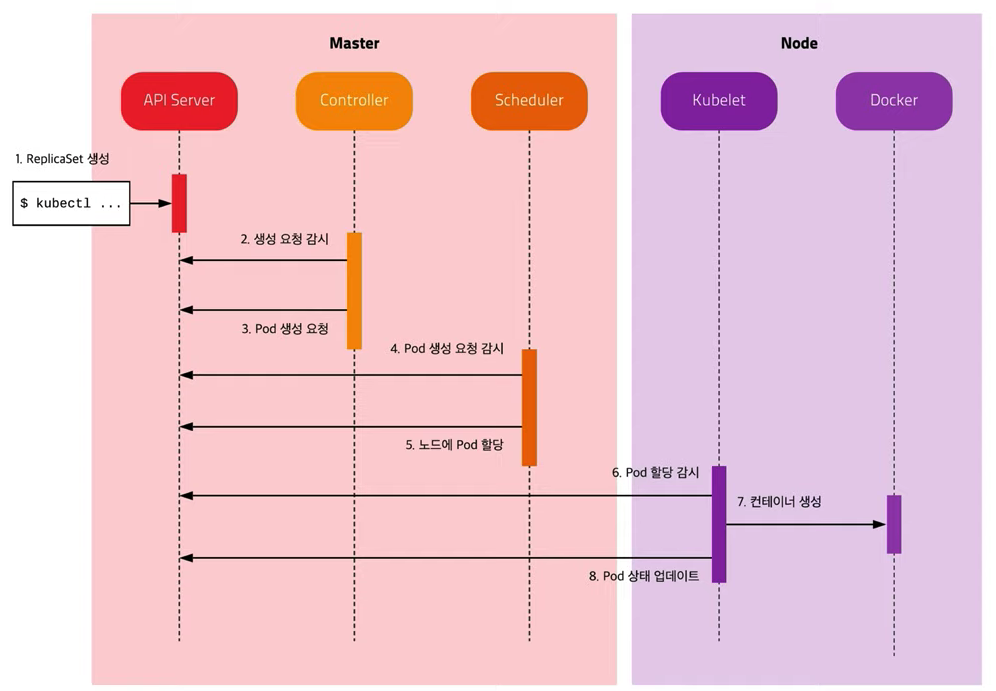
- 그림 출처 : https://youtu.be/SNA1sSNlmy0
- 관리자는 원하는 상태를 다양한 오브젝트로 정의하기 위해 yaml파일을 작성하고, 작성한 yaml파일을 Kubernetes에 적용시킨다.
- 마스터 내부의 API 서버는 yaml파일의 데이터를 받아서 etcd 저장소에 저장한다.
- 마스터 내부의 컨트롤러는 etcd 저장소를 주기적으로 확인하고, pod 생성 요청이 존재한다면 API 서버에 pod 생성을 요청한다.
- API 서버는 etcd 저장소에서 pod 생성 요청을 pod 할당 요청으로 갱신한다.
- 마스터 내부의 스케줄러는 etcd 저장소를 주기적으로 확인하고, pod 할당 요청이 존재한다면 어떤 노드에 pod를 할당할지 결정한 후에 API 서버에 특정 노드에 pod를 할당하겠다고 요청한다.
- 노드의 kubelet은 etcd 저장소를 주기적으로 확인하고, 자신에게 pod를 할당하겠다는 요청이 발견되면 상태에 맞게 pod를 생성하고 API 서버에 알린다.
- API 서버는 노드의 상태를 etcd 저장소에 갱신한다.
C) 오브젝트
Kubernetes의 오브젝트들은
기본 오브젝트와 기본 오브젝트를 생성하고 관리하는컨트롤러로 구성된다. 그리고 이러한 오브젝트들은 기본 스펙이외에 추가적인 메타정보들로 정의될 수 있다.
- 오브젝트의 기본 스펙 : yaml파일에 기본적으로 정의되어야 하는 오브젝트의 상태를 의미한다.
- 메타정보 : 개인 임의대로 정의할 수 있는 정보로 보면 될 것 같다.
- 쿠버네티스에 의해서 배포 및 관리되는 가장 기본적인 오브젝트는 컨테이너화되어 배포되는 애플리케이션의 워크로드를 기술하는 오브젝트로
PodServiceVolumeNamespace4가지가 있다.
(워크로드(work load) : 사전적 의미로 주어진 시간 안에 컴퓨터 시스템이 처리해야 하는 작업의 양과 작업의 성격) - 4가지의 기본 오브젝트들은 각기 다양한 work load로 기술된다고 이해하면 된다.(
Pod는 컨테이너화된 애플리케이션,Volume은 디스크,Service는 로드밸런서 그리고Namespace는 패키지명)
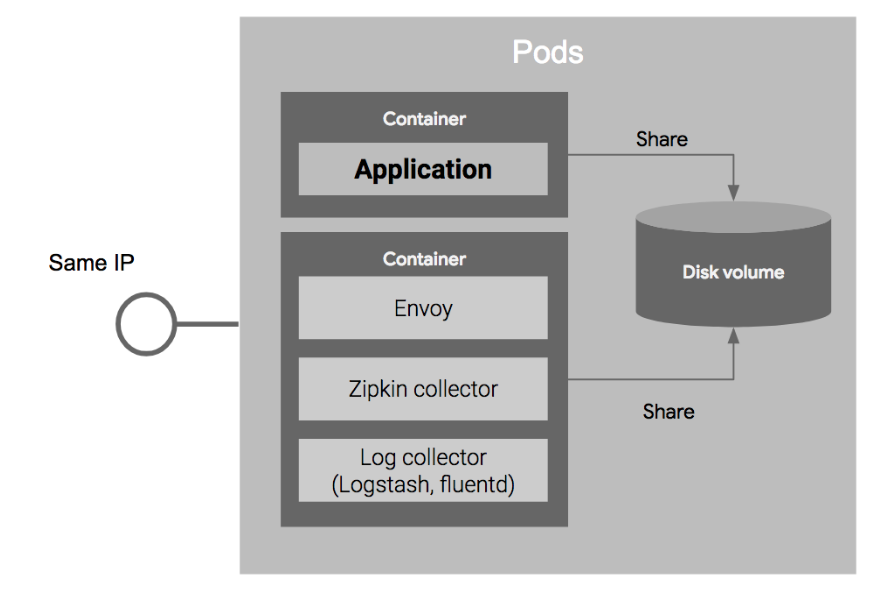
- pod
: Kubernetes의 가장 기본적인 배포 단위이다. 한개 이상의 컨테이너로 구성된다.
- 특징
1) pod내의 컨테이너들은 IP와 Port를 공유한다.
: 같은 pod내의 컨테이너들은 localhost를 통해 서로 통신이 가능하다.(A : 8080, B : 7001, B에서 A를 호출할 때 localhost:8080)
2) pod내의 컨테이너들은 같은 pod내의 디스크볼륨을 공유할 수 있다.
: 예를들어 일반적인 경우에 애플리케이션 로그파일을 읽고 수집하는 로그수집기를 애플리케이션과 다른 컨테이너로 배포할 경우, 파일 시스템이 분리되어 로그수집기가 로그파일 읽는 것이 불가능하지만 쿠버네티스의 경우, 같은 디스크볼륨을 공유하여 다른 컨테이너의 파일을 읽어올 수 있다.
-
volume
: pod내에서 각 컨테이너에 로컬디스크가 할당이 되는데, 할당된 로컬디스크는 영구적이지 않다.(컨테이너를 재시동하거나 새로 시작할 때, 기존 디스크의 데이터는 제거되고 새로운 로컬 디스크가 할당되기 때문에) 그래서 각 pod마다 영구적으로 데이터를 저장할 수 있는volume이라는 공간을 두어 영속적으로 저장해야하는 데이터를 여기에 저장한다.volume은 같은 pod내의 컨테이너들이 모두 공유할 수 있다.

-
service
: 여러개의 pod를 서비스할 때,Load balancer를 활용하여 하나의 IP와 Port로 묶어서 서비스를 제공한다. pod는 동적으로 생성되고 제거되기 때문에 각 pod마다 ip주소 이용이 힘들고, 동적으로 추가 및 삭제된 pod들의 목록을Load balancer가 유연하게 선택해줘야 한다. > label과 label selector의 등장
-
label selector : 어떤 pod들을 하나의 service로 묶을 것인지 service를 생성할 때 정의
-
label : pod를 생성할 때 해당 pod가 어떤 label로 묶일지 정의
-
서비스 type별 설명은 추후 추가 예정
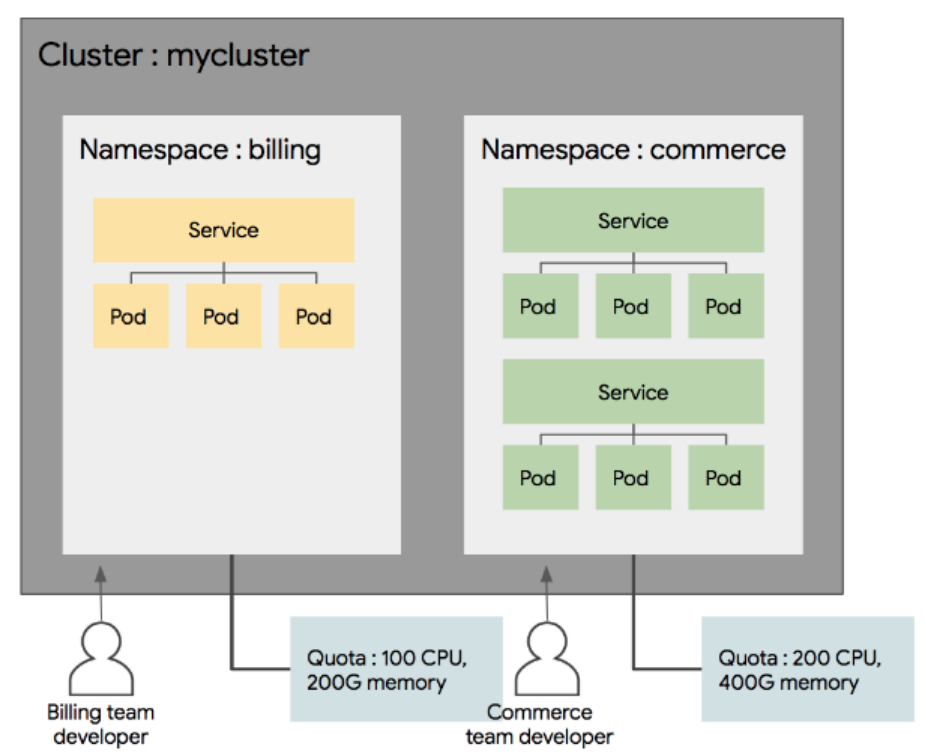
- namespace
: 클러스터 내의 논리적인 분리 단위이다. Pod,Service 등은 네임 스페이스 별로 생성이나 관리가 될 수 있고, 사용자의 권한 역시 이 네임 스페이스 별로 나눠서 부여할 수 있다.
-
특징
1) 네임스페이스별 접근 권한을 다르게 운영할 수 있다.
2) 리소스의 할당량을 지정할 수 있다. 개발계에는 CPU 100, 운영계에는 CPU 400과 GPU 100개 식으로, 사용 가능한 리소스의 수를 지정할 수 있다.
3) 네임 스페이스별로 리소스를 나눠서 관리할 수 있다. -
네임 스페이스는 논리적인 분리 단위이지 물리적이나 기타 장치를 통해서 환경을 분리(Isolation)한것이 아니다.
D) label
라벨은 쿠버네티스의 리소스를 선택하는데 사용이 된다. 각 리소스는 라벨을 가질 수 있고, 라벨 검색 조건에 따라서 특정 라벨을 가지고 있는 리소스만을 선택할 수 있다. metadata 섹션에 키/값 쌍으로 정의가 가능하며, 하나의 리소스에는 하나의 라벨이 아니라 여러 라벨을 동시에 적용할 수 있다. (키 값은 label, value 값은 임의의 값)
- label selector
1) Equality based selector : 등가 조건에 따라 리소스를 선택한다.
(ex. environment = dev, tier != frontend)
2) Set based selector : 집합의 개념 사용
(ex. environment in (production,qa) 는 environment가 production 또는 qa 인 경우, tier notin (frontend,backend)는 tier가 frontend도 아니고 backend도 아닌 리소스를 선택하는 방법)
E) Controller
기본 오브젝트로 애플리케이션의 설정 및 배포가 가능하지만, 좀 더 편리한 관리를 위해서 Controller를 사용함. 컨트롤러는
Replication Controller (aka RC),Replication Set,DaemonSet,Job,StatefulSet,Deployment가 있다.
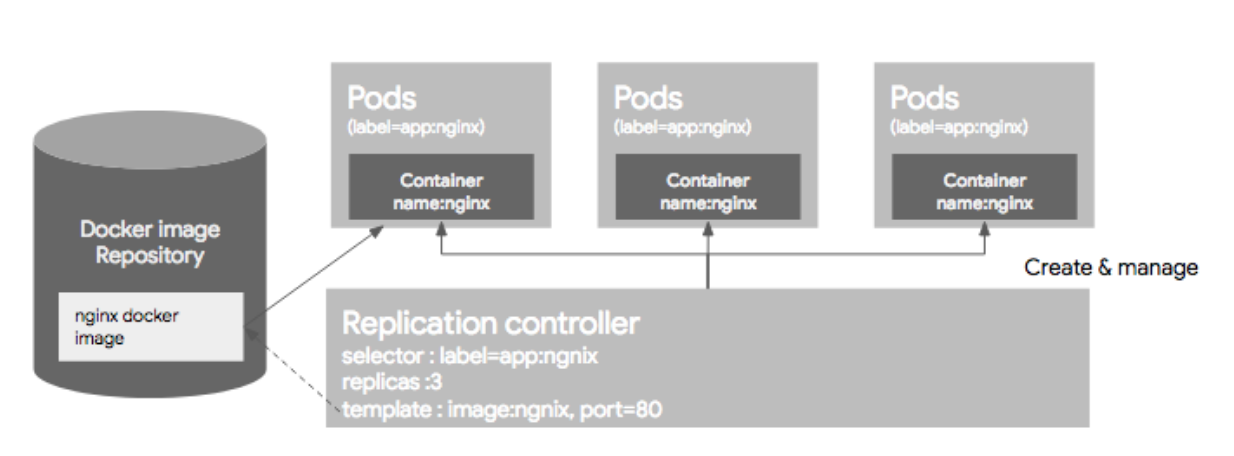
- Replication Controller(RC) : 지정된 숫자로 pod를 기동시키고 관리한다. 크게 3가지 파트로 구분된다.
-
pod selector : 먼저 Pod selector는 라벨을 기반으로 하여, RC가 관리한 Pod를 가지고 오는데 사용한다.
-
Replica 수 : RC에 의해서 관리되는 Pod의 수인데, 그 숫자만큼 Pod 의 수를 유지하도록 한다.
-
pod template : 생성할 pod에 대한 정보(docker image, port, label 등)를 정의한다.
-
주의할 점 : 이미 기동되고 있는 pod가 있는 상태에서 새로운 RC를 생성하고, 생성된 RC의 label selector가 기동되고 있는 pod의 label를 가리키는 경우 해당 pod들은 새로 생성된 RC의 컨트롤을 받게된다. 이렇게 되면 pod의 스펙과 RC에서 정의한 pod의 스펙과 다를지라도 pod를 삭제하지 않는다.
-
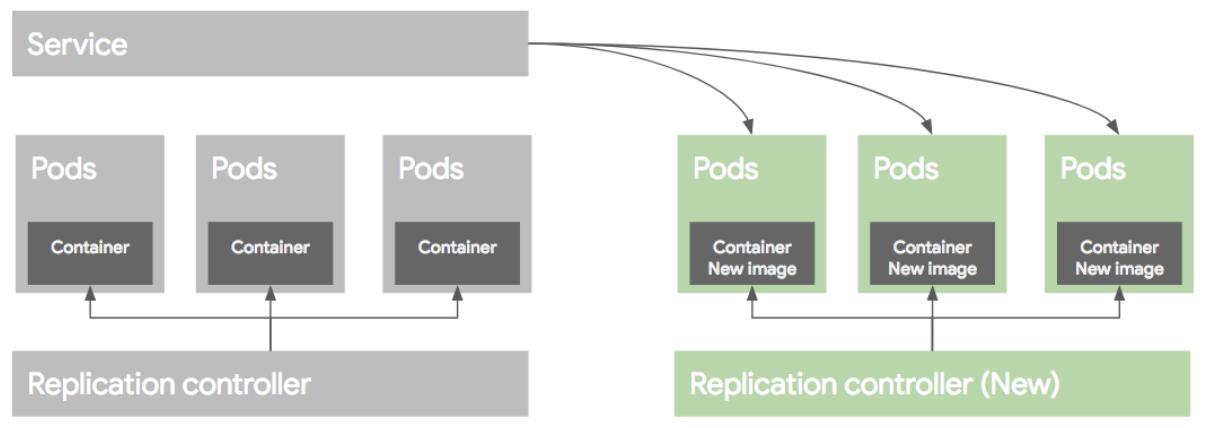
ReplicaSet : RC의 새버전이다. Replication Controller 는 Equality 기반 Selector를 이용하는데 반해, Replica Set은 Set 기반의 Selector를 이용한다.
-
Deployment : ReplicaSet의 상위 추상화 개념이며 ReplicaSet의 버전 upgrade를 도와준다.
2. 과제 진행 과정
A. 개발 환경 구축
쿠버네티스 클러스터를 실행하려면 최소한 scheduler, controller, api-server, etcd, kubelet, kube-proxy를 설치해야 하고 필요에 따라 dns, ingress controller, storage class등을 설치해야 한다.
minikube는 이러한 설치를 쉽고 빠르게 하기 위한 도구이다.
brew install minikube: minikube 설치- 42서울 클러스터에서 과제수행 시
~/.zshrc에 환경변수(export MINIKUBE_HOME=~/goinfre) 추가(42서울 클러스터 컴퓨터는 개인이 사용할 수 있는 메모리가 한정되어 있어서 추가적인 메모리 공간이 필요함) - virtual box 설치 : spotlight에서
managed software center를 검색한 후 virtual box를 설치해준다. minikube start --driver=virtualbox: virtualbox vm을 활용하여 minikube 실행(minikube의 default driver는 virtualbox라고 한다.)
- minikube에서 VM을 사용하는 이유 : local 환경과 Kubernetes 환경을 독립시켜 주기 위해 사용한다.
minikube status: 동작이 잘 되는지 확인한다.
B. MetalLB 설치
MetalLB는 BareMetalLoadBalancer의 약자이다. Kubernetes의 Service 객체들이 Loadbalancer type으로 선언되어 외부 IP를 할당받을 수 있도록 도와준다.
1) LoadBalancer가 필요한 이유
- Kubernetes의 pod는 소멸과 생성을 반복하고, 이 때마다 pod에 할당된 ip가 바뀌어 호출이 어렵다.
- Kubernetes 특성상 하나의 Application을 여러 pod로 운용할 수 있고, 트래픽을 어느 pod로 보내줄지 결정해주는 기능이 필요하다.
- 위 두 가지의 pod 특성때문에 LoadBalancer type의 서비스가 필요하다. LoadBalancer type의 서비스는 하나의 지정된 외부 ip를 할당받고, 해당 ip로 들어온 트래픽들을 각 pod로 뿌려주는 역할을 한다.
2) MetalLB가 필요한 이유
- Loadbalancer type의 서비스를 사용하기 위해 외부에서 접근 가능한 ip를 할당받아야 하고, 해당 ip는 클라우드 벤더들에게 제공받아야 한다.
- 클라우드 벤더들의 ip 제공 없이 Loadbalancer type의 서비스를 사용하기 위해 MetalLB를 사용한다.
- MetalLB를 사용하게 되면 외부 Loadbalancer를 사용하지 않고 Loadbalancer 기능을 구현할 수 있다.(Load Balancer 포스트 참고)
3) MetalLB 설치
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.9.3/manifests/namespace.yaml: metallb-system으로 지정된 namespace(클러스터 내의 논리적인 분리 단위) 오브젝트를 클러스터에 배포한다.kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.9.3/manifests/metallb.yaml: metallb의 controller와 speaker가 생성된다.kubectl create secret generic -n metallb-system memberlist --from-literal=secretkey="$(openssl rand -base64 128)": memberlist secret을 만들어 speaker간 통신을 암호화한다.- MetalLB는 configmap이 적용될 때까지 유휴상태라고 한다. MetalLB configmap이 적용되기 위해
metallb-systemnamespace로 configmap yaml파일을 만들어 적용시켜주면 된다. - MetalLB를 세팅할 때 사용되는 다양한 프로토콜 중 Layer 2 프로토콜을 활용할 것이고 이를 configmap을 통해 전달할 것이다.(Layer 2 프로토콜은 노드 하나가 트래픽을 다 받고 해당 서비스에 연결된 모든 pod로 트래픽을 분산시키는 방식이다. 구조가 비교적 간단하다고 함.)
- configmap yaml파일의 addresses 부분에 트래픽을 받을 ip의 범위를 지정해주는데, host ip가 해당 범위 내에 있어야함(host ip는 minikube를 실행한 후에
minikube ip명령어로 확인 가능하다.)
4) 주의할 점
- Load Balancer IP의 host 주소는 0이나 255가 되면 안된다.
5) 참고
- MetalLB
https://metallb.universe.tf/ - Loadbalancer란?
https://pakss328.medium.com/%EB%A1%9C%EB%93%9C%EB%B0%B8%EB%9F%B0%EC%84%9C%EB%9E%80-l4-l7-501fd904cf05 - [쿠버네티스] Minikube + MetalLB 셋팅 자동화하기
https://velog.io/@humblego42/%EC%BF%A0%EB%B2%84%EB%84%A4%ED%8B%B0%EC%8A%A4-Minikube-MetalLB-%EC%85%8B%ED%8C%85-%EC%9E%90%EB%8F%99%ED%99%94%ED%95%98%EA%B8%B0
C. 서비스 배포 전 공통
Kubernetes에 서비스를 배포 하기 전에 먼저 숙지해야할 공통적인 부분을 다룰 것이다.
1) Kubectl
앞으로 디버깅 할 일이 많이 생길 것이다. 간편한 디버깅을 위해
kubectl명령어를 숙지하자.
- 기본 form : kubectl [COMMAND][TYPE] {NAME] {FLAGS]
kubectl get all: 현재 실행되고 있는 모든 object들의 상태를 보여준다.kubectl get pod: 현지 실행되고 있는 모든 pod들의 상태를 보여준다.(pod대신 다른 object(Service)를 넣어도 된다.)kubectl describe pods: 특정 replicaset이 제어하는 pod들의 정보 및 상태 출력kubectl logs: 특정 이름을 가진 pod의 로그 조회kubectl delete: 현재 실행되고 있는 모든 object 실행 중지
2) foreground 및 background 실행
- foreground 실행이란? 사용자와의 직접적인 교류를 위해 다른 프로세스보다 우선적으로 실행되는 것을 의미한다. 예를들어 명령프롬프트 상에서 특정 프로세스가 foreground로 실행되고 있다면, 해당 프로세스를 제외한 다른 프로그램은 실행이 불가하다.
- background 실행이란? 특정 프로세스가 background로 실행이 되면 다른 프로세스도 같은 터미널 상에서 실행될 수 있다.
- 보통 쉘스크립트로 프로그램을 실행하게 되면 프로그램은 쉘스크립트 프로세스의 자식프로세스로 메모리를 할당 받지만, background로 실행이 되면 쉘스크립트의 자식프로세스로 실행이 되지 않는다.
- 즉, docker는 container에서 실행되는 프로세스의 자식프로세스를 지속적으로 추적하여 실행되고 있는 프로세스의 유무를 파악하는데, background실행은 자식프로세스로 할당되는 것이 아니기 때문에 docker가 이를 인식하지 못한다.
3) Virtualbox Docker에 접근하기
Kubernetes는 Virtualbox라는 remote 환경에서 실행이 되지만, image build를 로컬에서 하면 Virtualbox에 image가 생성되는 것이 아니라 로컬에서 생성된다.
eval $(minikube -p minikube docker-env)명령어를 사용하면 Virtualbox의 Docker CLI를 활용할 수 있고 로컬에서 Virtualbox에 image를 생성할 수 있다.
4) alpine version
alpine version마다 설치할 수 있는 패키지가 다르다. 없는 패키지를 설치할 경우
DNS Lookup에러가 발생한다.
- 필자는 과제 수행을 위해 alpine 3.12를 활용하였고 없는 패키지는
RUN echo "http://dl-2.alpinelinux.org/alpine/edge/community" >> /etc/apk/repositories명령어를 활용하여 alpine OS에 없는 패키지들을 추가하여 사용하였다.
5) 참고
- Docker CLI
https://nickjanetakis.com/blog/understanding-how-the-docker-daemon-and-docker-cli-work-together - apk 패키지
https://wiki.alpinelinux.org/wiki/Alpine_Linux_package_management - kubectl 명령어 설명
https://honggg0801.tistory.com/47 - foreground, background 실행
https://itholic.github.io/linux-jobs-bg-fg/
D. Nginx 설치 및 배포
1) Nginx란?
: nginx는 동시 접속 처리에 특화된 웹 서버 프로그램이다.
2) Nginx의 구동방식
- Nginx는 구동방식으로 비동기 Event-Driven 방식을 채택하고 있다.
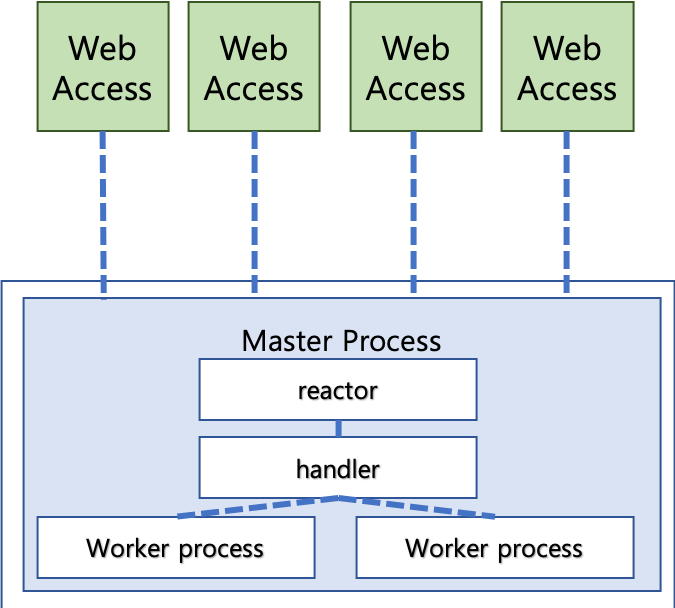
출처 : https://taes-k.github.io/2019/03/08/server-nginx-event-driven/ - Nginx는 클라이언트의 요청을 병렬처리할 때 프로세스를 늘리지 않는다.
- Event-Driven 방식은 싱글 프로세스인 Master process의 reactor가 클라이언트의 요청을 받고, 받은 요청들은 handler를 통해 실제 처리를 수행하는 Worker process에 전달된다.
- 비동기 방식으로 요청이 처리되기 때문에 특정 프로세스가 요청에 대한 응답을 기다릴 때 다른 프로세스의 요청을 처리한다.
3) Nginx 특징
- 싱글 스레드 기반으로 동작하기 때문에 Context Switching이 발생하지 않고 CPU 사용률이 상대적으로 적다.
- Context Switching에 의한 오버헤드가 발생하지 않아서 빠른 처리가 가능하다.
- 프로세스를 늘리지 않고 비동기 처리방식 덕분에 메모리를 많이 사용하지 않는다.
- 많은 I/O, 읽기쓰기 작업이 필요할 경우, 시스템 큐에 요청이 쌓이게 되어 성능이 저하될 수 있다.
- 따라서, 복잡한 처리나 대용량 데이터처리가 필요한 서비스가 아닌 하드웨어 읽기가 발생하지 않는 캐시 제공, 리버스 프록시 서버, 로드 벨런서 등의 역할을 주로 담당하게 된다.
4) Kubernetes에서의 Nginx 배포
-
Nginx image 만들기
a. Dockerfile 작성하기
- 과제에서 Kubernetes의 Container는 alpine OS를 기반으로 하기 때문에 image는 alpine OS 기반으로 만들어준다.
- alpine OS의 패키지 툴은 apk 이다. apk 명령어를 활용하여 Nginx를 설치해준다.
- Container에서 사용할 포트들을 Dockerfile에서 Expose 해준다.
- Openssl를 설치하고 인증서를 만들어준다.
- 생성된 인증서를 default.conf 파일에 추가해준다.
- Nginx에 redirection 및 reverse proxy 기능을 추가하기 위해 로컬에서 default.conf 파일을 작성한다.
- default.conf 파일을 Container의 nginx/conf.d 경로에 넣어주는 설정을 Dockerfile에 추가한다.
- location 제어문을 추가하여 uri에/wordpress입력시에http://$host:5050/로의 redirection 기능을 추가해준다.(http 상태코드는 307)
- location 제어문을 추가하여 uri에/phpmyadmin입력시에http://$host:5000/로의 reverse proxy 기능을 추가해준다.(reverse proxy 포스트 참고)
- image가 Container로 실행될 때 Nginx가 foreground로 실행될 수 있도록 sh파일을 만들어 Entrypoint로 지정해준다.
- pod의 resource data를 InfluxDB에 전달하기 위해 telegraf를 설치한다. telegraf.conf 파일을 수정하여 data를 전송할 InfluxDB의 Host 주소와 데이터를 저장할 데이터베이스의 이름을 입력한다.
- telegraf는 오픈소스 시스템 모니터링 에이전트이다. 웹 서버나 데이터베이스 등이 사용하는 리소스 사용량 데이터를 수집한다.
- Container 내에서 필요한 프로그램을 실행하고 관리하기 위해 Supervisor를 설치한다.
- Supervisor는 supervisor.conf 파일에 실행이 정의된 프로그램을 실행시켜준다.
-command = sh -c "nginx -g 'daemon off;' && kill -s SIGTERM $(cat supervisord.pid)"명령어로 프로그램을 실행시키면 프로그램이 실행될 때 foreground로 실행되므로 && 연산 뒤의 명령어가 실행되지 않고 hold 된다. 그리고 foreground로 실행되던 프로세스에 문제가 생겨 중지되면 && 연산 뒤의 명령어가 실행되어 전체 프로세스를 관리하는 supervisor를 kill 명령어로 중지시킨다.
- Container 내부에서 자식 프로세스로 다른 모든 프로세스를 실행시키던 Supervisor 프로세스가 중지되면 Container 역시 중지되어 이를 감지한 replicaset은 pod를 재실행한다.(pod의 상태를 체크하는 livenessProbe의 대안) -
Nginx yaml 파일 작성하기
a. deployment 오브젝트 배포하기
- deployment는 pod들을 포괄하는 replicaset의 상위 개념이다. 버전 관리에 용이하다.
- Container 필드에서 Container로 배포할 Nginx image 이름을 넣어준다.(직접 만든 image)
- 과제에서 기본적으로 Hub 에서의 image pull을 금지하고 있기 때문에 ImagePullPolicy는 Never로 설정해준다.
- Container에서 사용할 포트를 설정해주고 포트에 이름을 붙여준다.(80 : http, 443 : https)
b. service 오브젝트 배포하기
- 외부와의 통신 방법을 정의하기 위해 Service 오브젝트를 배포한다. 과제에서는 Load Balancer type의 통신을 요구하고 있다.
- metadata 필드에서metallb.universe.tf/allow-shared-ip: shared설정을 안해주면 클러스터 Load Balancer의 IP를 클러스터 내부의 오브젝트 간에 공유를 하지 않기 때문에 각 pod에 접근할 수 있는 IP가 달라진다.
- ports 필드에서 해당 pod의 특정 port로 접근하면 임의로 설정한 Container port로 연결한다는 설정을 추가해준다.(포트 포워딩 기능인듯)
- type 필드에서 Load Balancer type으로 정의해준다.
- Service를 Load balancer type으로 선언하면 해당 pod가 Load balancer가 되는 것이 아니라 Load balancer를 이용하여 통신을 할 수 있다는 뜻이다. 그리고 Loadbalancer type의 Service에 Loadbalancer IP를 지정해주지 않으면 metallb에서 지정해준 ip 범위의 처음 ip 값이 Service의 External IP로 설정된다. -
kubectl apply -f 명령어를 활용하여 작성한 yaml 파일을 적용시켜준다.
5) 주의할 점
- nginx는 기본적으로 background로 실행되는 프로그램이다. 하지만 Container에서 foreground로 실행되고 있는 프로세스가 없다면 Container가 자동으로 꺼지기 때문에 Kubernetes는 해당 Container를 pod로 생성하지 못한다. 따라서 nginx를 foreground로 실행시켜주어야 한다.
6) 참고
- Nginx 이해하기 및 기본 환경설정 세팅하기
https://whatisthenext.tistory.com/123 - Nginx 기본 환경 설정 튜닝 및 설명(익스트림 메뉴얼)
https://extrememanual.net/9976 - Nginx 설치 및 기본 환경 설정(Cory)
https://kscory.com/dev/nginx/install - HTTP 상태 코드
https://developer.mozilla.org/ko/docs/Web/HTTP/Status - Container 중지 오류 해결하기
https://roseline124.github.io/kuberdocker/2019/07/24/docker-study05.html#%EB%8F%84%EC%BB%A4%EC%97%90%EC%84%9C-foreground%EC%99%80-background-%EC%8B%A4%ED%96%89 - supervisor란?
http://supervisord.org/
E. Wordpress 설치 및 배포
1) Wordpress란?
: Wordpress는 세계 최대의 오픈소스 저작물 관리 시스템이다. 우리나라의 서울특별시 홈페이지가 Wordpress기반으로 만들어졌다.
- 저작물 관리 시스템 : 사진, 음성, 전자문서 그와 유사한 컴퓨터 파일 등과 같은 저작물 관리에 사용하는 소프트웨어
2) Kubernetes에서의 Wordpress 배포
- Wordpress image 만들기
a. Dockerfile 작성하기
-https://wordpress.org/latest.tar.gz에서 wordpress 압축파일을 가져온다.
- Wordpress는 php를 활용하는 동적인 웹사이트이므로 Wordpress 구동에 필요한 php 모듈을 설치해준다.
- 과제에서 Wordpress는 Nginx 서버 기반으로 동작해야하므로 Nginx도 설치해준다.
- 동적 웹사이트로의 요청을 처리하기 위해 php-fpm을 경유해야 한다. 이를 위해 Nginx 설정 파일인 default.conf 파일에 php-fpm으로의 redirection 기능을 넣어준다.(php-fpm 포스트 참고)
- image가 Container로 실행될 때 php-fpm이 실행될 수 있도록 sh파일을 만들어 Entrypoint로 지정해준다.
- pod의 resource data를 InfluxDB에 전달하기 위해 telegraf를 설치한다. telegraf.conf 파일을 수정하여 data를 전송할 InfluxDB의 Host 주소와 데이터를 저장할 데이터베이스의 이름을 입력한다.
- Container 내에서 필요한 프로그램을 실행하고 관리하기 위해 Supervisor를 설치한다.
- Supervisor는 supervisor.conf 파일에 실행이 정의된 프로그램을 실행시켜준다.
- Wordpress yaml 파일 작성하기
a. deployment 오브젝트 배포하기
- Container 필드에서 Container로 배포할 Wordpress image 이름을 넣어준다.
- ImagePullPolicy는 Never로 설정해 준다.
- Container port를 5050으로 설정해준다.
- mountPath : Path within the container at which the volume should be mounted. Must not contain ':'.
- subPath : Path within the volume from which the container's volume should be mounted. Defaults to "" (volume's root).
- Configmap으로 정의한 파일 정보를 pod내에서 Volume 형태로 불러온다.
- 만들어진 Volume의 정보를 mountPath로 불러온다.
b. Configmap 만들기
- 환경에 따라 image에 대한 설정파일을 바꿀 일이 있는데, 설정 파일을 바꾸고 image를 다시 만들어서 pod로 배포하는 과정이 불편하다. 이러한 불편함을 해소하기 위해 Configmap을 활용한다.
- pod 내에서 사용할 환경변수나 설정파일을 Configmap 형태로 pod에 적용할 수 있다. 이러한 Configmap을 사용하면 image의 설정이 바뀌었을 때, image를 다시 build할 필요가 없어진다.
- Wordpress를 MySQL 데이터베이스와 연동하기 위해 필요한 Wp-config.php 파일을 정의한다.
- Wp-config.php 파일에서 데이터베이스 이름과 데이터베이스를 사용할 유저 및 비밀번호, 데이터베이스의 host를 정의해준다.
c. service 오브젝트 배포하기
-metallb.universe.tf/allow-shared-ip: shared설정하기
- 포트포워딩 기능 추가하기
- Load Balancer type 정의하기
- kubectl apply -f 명령어를 활용하여 작성한 yaml 파일을 적용시켜준다.
3) 참고
- Wordpress(위키백과)
https://ko.wikipedia.org/wiki/%EC%9B%8C%EB%93%9C%ED%94%84%EB%A0%88%EC%8A%A4 - 저작물 관리 시스템(위키백과)
https://ko.wikipedia.org/wiki/%EC%A0%80%EC%9E%91%EB%AC%BC_%EA%B4%80%EB%A6%AC_%EC%8B%9C%EC%8A%A4%ED%85%9C - Configmap(조대협님 블로그)
https://bcho.tistory.com/1267?category=731548 - alpine-wordpress
https://wiki.alpinelinux.org/wiki/WordPress - wordpress의 구조와 기능
https://engkimbs.tistory.com/870
F. phpMyAdmin 설치 및 배포
1) phpMyAdmin이란?
: phpMyAdmin은 MySQL 데이터베이스를 월드 와이드 웹 상에서 관리할 목적으로 PHP로 작성한 오픈 소스 도구이다.
2) Kubernetes에서의 phpMyAdmin 배포
-
phpMyAdmin image 만들기
a. Dockerfile 작성하기
- phpMyAdmin은 php를 활용하는 동적인 웹사이트이므로 phpMyAdmin 구동에 필요한 php 모듈을 설치해준다.
- 과제에서 phpMyAdmin은 Nginx 서버 기반으로 동작해야하므로 Nginx도 설치해준다.
- Openssl를 설치하고 인증서를 만들어준다.
- 생성된 인증서를 default.conf 파일에 추가해준다.
- Nginx 설정 파일인 default.conf 파일에 php-fpm으로의 redirection 기능을 넣어준다.(php-fpm 포스트 참고)
- Entrypoint로 실행될 sh 파일을 통해https://files.phpmyadmin.net/phpMyAdmin/5.0.2/phpMyAdmin-5.0.2-all-languages.tar.gz을 받아서 phpMyAdmin을 설치해준다.
- phpMyAdmin 디렉토리 내부의 config.inc.php 파일을 수정하여 phpMyAdmin과 MySQL 서버를 연동시켜 준다.
- image가 Container로 실행될 때 php-fpm이 실행될 수 있도록 sh파일을 만들어 Entrypoint로 지정해준다.
- pod의 resource data를 InfluxDB에 전달하기 위해 telegraf를 설치한다. telegraf.conf 파일을 수정하여 data를 전송할 InfluxDB의 Host 주소와 데이터를 저장할 데이터베이스의 이름을 입력한다.
- Container 내에서 필요한 프로그램을 실행하고 관리하기 위해 Supervisor를 설치한다.
- Supervisor는 supervisor.conf 파일에 실행이 정의된 프로그램을 실행시켜준다. -
phpMyAdmin yaml 파일 작성하기
a. deployment 오브젝트 배포하기
- Container 필드에서 Container로 배포할 Wordpress image 이름을 넣어준다.
- ImagePullPolicy는 Never로 설정해 준다.
- Container port를 5000으로 설정해준다.
b. service 오브젝트 배포하기
-metallb.universe.tf/allow-shared-ip: shared설정하기
- 포트포워딩 기능 추가하기
- Load Balancer type 정의하기 -
kubectl apply -f 명령어를 활용하여 작성한 yaml 파일을 적용시켜준다.
3) 참고
- phpMyAdmin(위키백과)
https://ko.wikipedia.org/wiki/PhpMyAdmin - 리눅스 phpMyAdmin 설치하기
http://paulownia.egloos.com/v/3512920
G. MySQL 설치 및 배포
1) MySQL이란?
: MySQL은 오픈 소스의 관계형 데이터베이스 관리 시스템(RDBMS)이다.
2) Kubernetes에서의 MySQL 배포
-
MySQL image 만들기
a. Dockerfile 작성하기
-apk add명령어를 활용하여mysql과mysql-client를 설치해준다.
-mysql-client는 쿼리를 작성하여 데이터를 받아오는 역할만 하고, 실제로 데이터를 관리해주는 것은mysql이다.
- 과제에서는 MySQL pod가 데이터베이스를 관리하고 쿼리를 통해 데이터베이스의 데이터를 보내주는 역할도 해야하기 때문에 두 모듈을 모두 설치하는 것이다.
- my.cnf 디렉토리에 있는 server.conf 파일을 수정해준다.
- server.conf 파일 수정을 통해 소켓통신 경로를 설정해주고 user와 port를 설정해준다. 또한, mysql 서버는 기본적으로 로컬에서 소켓통신만 가능한데 skip-networking을 0으로 설정해줌으로써 외부 네트워크의 접근을 허용한다.
- OpenRC 명령어인 rc-service를 이용하여 MySQL을 실행한다.
- rc-status는 OpenRC의 상태를 확인할 수 있을 뿐만 아니라 runlevel를 set 해준다.
-mysql -u root명령어를 활용하여 root 계정으로 MySQL 프로그램에 접속한다. 그리고 데이터베이스를 생성하고 user에게 권한 부여를 한다. 또한, 임의로 만든 sql 파일을 데이터베이스에 적용한다.
-mysqld_safe명령어로 MySQL server를 실행합니다.
-mysqld명령어로도 MySQL server를 실행할 수 있지만 굳이mysqld_safe명령어를 사용하는 이유는 다음과 같습니다 : mysqld_safe이 내부 스크립트에서 mysqld를 실행하고 mysqld 프로세스를 모니터링하고, 어떤 문제로 mysqld가 강제 종료되면 mysqld를 다시 실행합니다.
- pod의 resource data를 InfluxDB에 전달하기 위해 telegraf를 설치한다. telegraf.conf 파일을 수정하여 data를 전송할 InfluxDB의 Host 주소와 데이터를 저장할 데이터베이스의 이름을 입력한다. -
MySQL yaml 파일 작성하기
a. deployment 오브젝트 배포하기
- Container 필드에서 Container로 배포할 MySQL image 이름을 넣어준다.
- ImagePullPolicy는 Never로 설정해 준다.
- Container port를 3306으로 설정해준다.
- livenessProbe 기능을 추가한다. Kubernetes는 최소 pod 단위로 상태를 체크할 수 있어서 컨테이너 내부의 프로세스에 이상이 생겨도 컨테이너가 이상이 없는 한 Kubernetes는 현재 상태를 유지한다. 이를 보완한 기능이 livenessProbe이다. livenessProbe의 동작원리는 다음과 같다.
1) livenessProbe - exec - command 필드에서 livenessProbe로 실행할 프로그램과 프로그램이 입력으로 받을 파일을 정의한다.
2) 정의한 프로그램의 실행 결과가 오류일 경우, livenessProbe는 해당 pod에 오류가 발생했음을 감지하고 replicaset이 pod를 재생성한다.(ex. 실행프로그램 : sh, 실행파일 : healty.sh 일 때,sh healty.sh동작이 오류로 인지되면 pod를 재생성한다.)
-initialDelaySeconds필드를 통해 pod가 실행된 후 몇 초후에 livenessProbe 기능을 실행시킬 것인지 결정한다.
-periodSeconds필드를 통해 몇 초마다 livenessProbe에서 정의된 프로그램의 실행 상태를 확인할 것인지 결정한다.
-PVC를 이용하여 Volume을 생성하고 mysql 디렉토리에 mount 한다.
b. PVC (Persistent Volume Claim) 생성하기
- PVC를 알아보기 전에 먼저 PV (Persistene Volume)을 알아본다.
- PV는 개발자의 개발활동과 시스템관리를 분리시키기 위해 생긴 개념이다. PV를 통해 인프라에 종속적인 부분인 Volume에 관한 부분은 시스템 관리자가 함께 관리하도록 하여 개발자는 Volume을 쉽게 활용할 수 있다.
- 시스템 관리자는 물리 디스크를 생성하여 PV라는 이름으로 Kubernetes에 등록한다.
- 개발자는 PVC를 지정하여 시스템 관리자가 생성한 PV를 pod와 연결한다.
- 즉, 시스템 관리자가 생성한 물리 디스크를 쿠버네티스 클러스터에 표현한것이 PV이고, Pod의 볼륨과 이 PV를 연결하는 관계가 PVC가 된다.
- Kubernetes 1.6부터 동적생성 기능이 지원된다. PV를 굳이 미리 만들어놓지 않아도 PVC를 지정하면 이에 맞게 PV를 동적으로 생성하여 pod와 연결해준다.
-accessModes필드에서 MySQL만 접근할 수 있도록ReadWriteOnce로 설정해준다.
- resources - requests - storage 필드에서 Volume의 용량을 정한다.
c. service 오브젝트 배포하기
-metallb.universe.tf/allow-shared-ip: shared설정하기
- 포트포워딩 기능 추가하기
- metadata 필드에서 name으로 지정한 부분이 데이터베이스의 host가 된다.
- Load Balancer type 정의하기 -
kubectl apply -f 명령어를 활용하여 작성한 yaml 파일을 적용시켜준다.
3) 주의할 점
- 로컬에서 Container로 Copy할 파일들을 tmp라는 디렉토리에 담아서 일괄적으로 옮길 때, 디렉토리의 권한을 수정해주지 않으면 디렉토리 내부의 파일들은 실행권한이 없어서 Entrypoint로 지정해주었던 sh파일이 실행되지 않는다.
toomanyrequests: You have reached your pull rate limit. You may increase the limit by authenticating and upgrading: https://www.docker.com/increase-rate-limit무분별하게 docker build를 많이 하면 위의 오류가 발생한다. build 횟수는 100회로 제한되어 있고 소모된 build 횟수는 6시간마다 충전된다.
4) 참고
- MySQL(위키백과)
https://ko.wikipedia.org/wiki/MySQL - MySQL 내부구조
https://brunch.co.kr/@jehovah/21 - MySQL 아키텍쳐
https://mysqldba.tistory.com/2 - MariaDB(MySQL) 원격에서 접근이 가능하도록 설정하기
https://gafani.tistory.com/entry/MariaDBMySQL-원격에서-접근이-가능하도록-설정하기 - Alpine Linux Init System
https://wiki.alpinelinux.org/wiki/Alpine_Linux_Init_System - OpneRC
https://wiki.artixlinux.org/Main/OpenRC - 콘솔창에서 데이터베이스 접속
http://www.devkuma.com/books/pages/1196 - mysqld_safe
https://kimyhcj.tistory.com/132 - MySQL의 다양한 실행 프로그램 mysqld_safe, mysql.server, mysqld_multi feat.mysqld
https://stricky.tistory.com/164 - 쿠버네티스 #5 - 디스크 (볼륨/Volume)
https://bcho.tistory.com/1259?category=731548 - alpine-mysql
https://wiki.alpinelinux.org/wiki/MariaDB - dependency-based init system
https://unix.stackexchange.com/questions/596095/what-is-dependency-based-init-system - mariadb option
https://mariadb.com/docs/reference/es10.5/cli/mariadbd/#options-for-mariadbd-mysqld-in-10-5-es - dbms and sql
https://blog.yena.io/studynote/2018/10/02/DBMS-SQL.html - mysql documentation
https://dev.mysql.com/doc/refman/8.0/en/mysqld.html
H. Grafana 설치 및 배포
1) Grafana란?
: Grafana는 메트릭 데이터를 시각화하는데 가장 최적화된 대시보드를 제공하는 오픈소스 메트릭 데이터 시각화 도구이다.
- 메트릭 데이터 : 메트릭은 시간 데이터와 한 두 가지의 숫자 값을 포함하는 데이터입니다.
2) Kubernetes에서의 Grafana 배포
-
Grafana image 만들기
a. Dockerfile 작성하기
- Grafana를 설치한다. 설치 시에http://dl-3.alpinelinux.org/alpine/edge/testing/repository에 접근해야 한다.
- 사전에 임의로 만들어둔 대시보드를 표현하기 위해Grafana.db대시보드 파일을 /grafana/data 경로에 넣어준다.
- image가 Container로 실행될 때 Grafana가 실행될 수 있도록 sh파일을 만들어 Entrypoint로 지정해준다.
- pod의 resource data를 InfluxDB에 전달하기 위해 telegraf를 설치한다. telegraf.conf 파일을 수정하여 data를 전송할 InfluxDB의 Host 주소와 데이터를 저장할 데이터베이스의 이름을 입력한다.
- Container 내에서 필요한 프로그램을 실행하고 관리하기 위해 Supervisor를 설치한다.
- Supervisor는 supervisor.conf 파일에 실행이 정의된 프로그램을 실행시켜준다. -
Grafana yaml 파일 작성하기
a. deployment 오브젝트 배포하기
- Container 필드에서 Container로 배포할 Grafana image 이름을 넣어준다.
- ImagePullPolicy는 Never로 설정해 준다.
- Container port를 3000으로 설정해준다.
b. service 오브젝트 배포하기
-metallb.universe.tf/allow-shared-ip: shared설정하기
- 포트포워딩 기능 추가하기
- Load Balancer type 정의하기 -
kubectl apply -f 명령어를 활용하여 작성한 yaml 파일을 적용시켜준다.
3) 참고
- Grafana란?(44bits)
https://www.44bits.io/ko/keyword/grafana - 메트릭이란 무엇인가?
https://12bme.tistory.com/398 - Grafana란?
https://medium.com/finda-tech/grafana%EB%9E%80-f3c7c1551c38 - kubernetes 모니터링
https://bcho.tistory.com/1269
I. InfluxDB 설치 및 배포
1) InfluxDB란?
: InfluxDB는 인플럭스데이터가 개발한 오픈 소스 시계열 데이터베이스(TSDB)이다. InfluxDB는 SQL 계열 언어를 제공하고 8086 포트를 사용하며, 자료 구조를 조회하기 위한 시간 중심 함수를 내장하고 있다.
- 시계열 데이터베이스 : '하나 이상의 시간'과 '하나 이상의 값' 쌍을 통해 시계열을 저장하고 서비스하는데 최적화된 소프트웨어 시스템이다.
- 타임스탬프 : 특정한 시각을 나타내거나 기록하는 문자열이다.(ex. Tue 01-01-2009 6:00)
2) Kubernetes에서의 InfluxDB 배포
-
InfluxDB image 만들기
a. Dockerfile 작성하기
-apk add명령어를 활용하여 InfluxDB를 설치한다.
- pod의 resource data를 InfluxDB에 전달하기 위해 telegraf를 설치한다. telegraf.conf 파일을 수정하여 data를 전송할 InfluxDB의 Host 주소(localhost)와 데이터를 저장할 데이터베이스의 이름을 입력한다.
- Container 내에서 필요한 프로그램을 실행하고 관리하기 위해 Supervisor를 설치한다.
- Supervisor는 supervisor.conf 파일에 실행이 정의된 프로그램을 실행시켜준다. -
InfluxDB yaml 파일 작성하기
a. deployment 오브젝트 배포하기
- Container 필드에서 Container로 배포할 InfluxDB image 이름을 넣어준다.
- ImagePullPolicy는 Never로 설정해 준다.
- Container port를 8006으로 설정해준다.
-PVC를 이용하여 Volume을 생성하고 influxdb 디렉토리에 mount 한다.
b. PVC (Persistent Volume Claim) 생성하기
-accessModes필드에서 MySQL만 접근할 수 있도록 ReadWriteOnce로 설정해준다.
- resources - requests - storage 필드에서 Volume의 용량을 정한다.
c. service 오브젝트 배포하기
-metallb.universe.tf/allow-shared-ip: shared설정하기
- 포트포워딩 기능 추가하기
- Load Balancer type 정의하기 -
kubectl apply -f 명령어를 활용하여 작성한 yaml 파일을 적용시켜준다.
3) 참고
- InfluxDB(위키백과)
https://ko.wikipedia.org/wiki/InfluxDB - 시계열 데이터베이스(위키백과)
https://ko.wikipedia.org/wiki/%EC%8B%9C%EA%B3%84%EC%97%B4_%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4 - 타임스탬프(위키백과)
https://ko.wikipedia.org/wiki/%ED%83%80%EC%9E%84%EC%8A%A4%ED%83%AC%ED%94%84
J. FTPS 설치 및 배포
1) FTPS란?
FTPS를 살펴보기 이전에 FTP를 먼저 짚고 넘어가겠다.
- FTP(File Transfer Protocol)는 TCP/IP 프로토콜을 가지고 서버와 클라이언트 사이의 파일 전송을 하기 위한 프로토콜이다.
- FTP의 구조

출처 : https://ko.wikipedia.org/wiki/%ED%8C%8C%EC%9D%BC_%EC%A0%84%EC%86%A1_%ED%94%84%EB%A1%9C%ED%86%A0%EC%BD%9C
- 기본적으로 제어 포트인 서버 21번 포트로 사용자 인증, 명령을 위한 연결이 만들어지고, 이 포트를 통해 클라이언트에서 지시하는 명령어가 서버에 전달된다.
- 실제 데이터 전송은 다른 연결을 통해 이루어지고, 두 가지 모드로 나뉜다.
-
액티브 모드 : 서버가 자신의 20번 포트에서 클라이언트가 지정한 포트(1023 이상)로의 연결을 만든다.
-
패시브 모드 : 클라이언트가 자신이 지정한 포트(1023 이상)에서 서버가 지정한 포트(1023 이상)로의 연결을 만든다. 패시브 모드는 클라이언트가 방화벽이나 NAT 등을 사용하는 환경일 때 주로 사용된다.
-
FTPS는 기존의 FTP에 전송 계층 보안(TLS)과 보안 소켓 계층(SSL) 암호화 프로토콜에 대한 지원이 추가된 프로토콜이다.
-
SSL 및 TLS의 원리
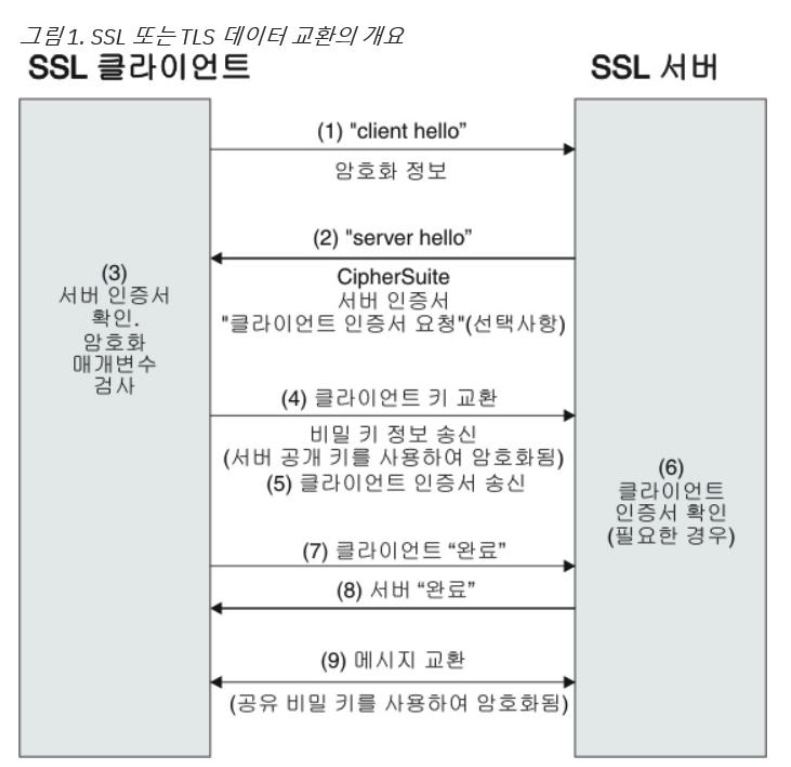
출처 : https://nhj12311.tistory.com/76 -
간략히 설명하면 서버가 건네주는 보자기(공개키)에 클라이언트가 데이터를 넣어서 서버에 보내주면 보자기 내부의 데이터는 서버만 열어볼 수 있다는 원리이다.
-
SSL과 TLS의 차이 : TLS는 SSL3.0을 기반으로 만들어졌고, 큰 차이점은 없다고 한다.
2) Kubernetes에서의 FTPS 배포
- FTPS image 만들기
a. Dockerfile 작성하기
-apk add명령어를 활용하여 FTP 서버 프로그램인 vsftpd(very secure FTPD)를 설치해준다.
- Openssl를 설치하고 인증서를 만들어준다.
- pod의 resource data를 InfluxDB에 전달하기 위해 telegraf를 설치한다. telegraf.conf 파일을 수정하여 data를 전송할 InfluxDB의 Host 주소와 데이터를 저장할 데이터베이스의 이름을 입력한다.
-adduser명령어를 활용하여 FTPS 서버에서 사용할 계정을 만들어준다.
-telegraf & vsftpd /etc/vsftpd/vsftpd.conf명령어로 telegraf와 vsftpd를 실행시켜준다. && 연산과 & 연산의 차이가 있는 것 같다.(&& 연산을 넣었을 때 vsftpd가 실행되지 않음)
- 동일하게 & 연산 대신 개행문자를 넣어서 프로그램을 실행시켜도 vsftpd가 실행되지 않았다.
-vsftpd.conf을 설정에 맞게 수정한다.(https://linux.die.net/man/5/vsftpd.conf) - FTPS yaml 파일 작성하기
a. deployment 오브젝트 배포하기
- Container 필드에서 Container로 배포할 FTPS image 이름을 넣어준다.
- ImagePullPolicy는 Never로 설정해 준다.
- Container port를 21과 21000으로 설정해준다.(21000은 데이터 송수신 포트)
- livenessProbe 기능을 추가한다.
-initialDelaySeconds필드를 통해 pod가 실행된 후 몇 초후에 livenessProbe 기능을 실행시킬 것인지 결정한다.
-periodSeconds필드를 통해 몇 초마다 livenessProbe에서 정의된 프로그램의 실행 상태를 확인할 것인지 결정한다.
b. service 오브젝트 배포하기
-metallb.universe.tf/allow-shared-ipshared 설정하기
- Load Balancer type 정의하기 - kubectl apply -f 명령어를 활용하여 작성한 yaml 파일을 적용시켜준다.
- 옮겨진 파일은 FTP 서버 /home/$(user_id) 디렉토리로 저장된다.
3) 참고
- FTPS(위키백과)
https://ko.wikipedia.org/wiki/FTPS - 파일 전송 프로토콜(위키백과)
https://ko.wikipedia.org/wiki/%ED%8C%8C%EC%9D%BC_%EC%A0%84%EC%86%A1_%ED%94%84%EB%A1%9C%ED%86%A0%EC%BD%9C - ftp, ftps, sftp(ssh) 개념 정리
https://nhj12311.tistory.com/76 - SSL vs TLS의 차이점
https://smartits.tistory.com/209 - vsftpd 설치 및 설정
https://idchowto.com/?p=31982
3. 참고
- kubernetes yaml reference
https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.21/#deployment-v1-apps - docker reference
https://docs.docker.com/engine/reference/builder/#entrypoint - alpine architecture
https://wiki.alpinelinux.org/wiki/Architecture - (subicura)쿠버네티스란?
https://subicura.com/2019/05/19/kubernetes-basic-1.html - (subicura)minikube 설치
https://subicura.com/k8s/prepare/kubernetes-setup.html#minikube - (heryu)ft_services
https://malbongcode.tistory.com/151 - (simian114)ft_services
https://githubmemory.com/repo/simian114/ft_services - virtualbox 사용 이유
https://hysimok.github.io/posts/42seoul/ft_services/ - bash 쉘스크립트 입문
https://m.blog.naver.com/PostView.nhn?blogId=baraem2005&logNo=20168719811&proxyReferer=https:%2F%2Fwww.google.com%2F - Docker image 최적화
https://ahnseungkyu.com/245 - telegraf
https://si.mpli.st/dev/2017-09-10-introduction-to-telegraf/ - Supervisor
http://supervisord.org/ - CGI 개요
https://docs.oracle.com/cd/E19146-01/820-0874/gczzu/index.html - 공통 게이트웨이 인터페이스(위키백과)
https://ko.wikipedia.org/wiki/%EA%B3%B5%EC%9A%A9_%EA%B2%8C%EC%9D%B4%ED%8A%B8%EC%9B%A8%EC%9D%B4_%EC%9D%B8%ED%84%B0%ED%8E%98%EC%9D%B4%EC%8A%A4
