- 날짜 : 2021. 3.19.(금)
1. 목표
A. 프로그래머스 코테 2단계 문제 최대한 풀기
B. DFS/BFS 개념 정리
C. BFS 문제 풀기
D. map, iterator 알아보기
2. 프로그래머스 코테 2단계 문제
- 푼 문제 list
- 위장 https://programmers.co.kr/learn/courses/30/lessons/42578
- 타겟 넘버 https://programmers.co.kr/learn/courses/30/lessons/43165
- 단체사진 찍기 https://programmers.co.kr/learn/courses/30/lessons/1835
- 올바른 괄호 https://programmers.co.kr/learn/courses/30/lessons/12909
- 방문 길이 https://programmers.co.kr/learn/courses/30/lessons/49994
- 이진 변환 반복하기 https://programmers.co.kr/learn/courses/30/lessons/70129
- 카펫 https://programmers.co.kr/learn/courses/30/lessons/42842
- 튜플 https://programmers.co.kr/learn/courses/30/lessons/64065
- 다음 큰 숫자 https://programmers.co.kr/learn/courses/30/lessons/12911
- 숫자의 표현 https://programmers.co.kr/learn/courses/30/lessons/12924
- 최댓값과 최솟값 https://programmers.co.kr/learn/courses/30/lessons/12939
- 행렬의 곱셈 https://programmers.co.kr/learn/courses/30/lessons/12949
- JadenCase 문자열 만들기 https://programmers.co.kr/learn/courses/30/lessons/12951
- 예상 대진표 https://programmers.co.kr/learn/courses/30/lessons/12985
A. 위장
#include <string>
#include <vector>
#include <map>
using namespace std;
int solution(vector<vector<string>> clothes) {
int answer = 1;
map<string, int> map_tmp;
for (int i = 0; i < clothes.size(); i++)
map_tmp[clothes[i][1]]++;
for (auto it = map_tmp.begin(); it != map_tmp.end(); it++)
answer *= (it->second + 1);
return (answer - 1);
}- 코드 설명
- 스파이가 입을 수 있는 옷의 목록을 종류별로 clothes 2차원 배열로 입력받는다.
- 첫번째 for loop에서 옷의 각 종류마다 몇 벌씩 있는지 체크한다.
- 두번째 for loop에서 스파이가 코디할 수 있는 경우의 수를 계산한다. 옷 종류마다 있는 옷의 개수에 +1을 하는 이유는 특정 옷 종류를 안입은 경우도 고려하기 때문이다.
- return할 때, 계산된 경우의 수에 1만큼 빼는데, 모든 옷을 안 입는 경우의 수를 빼기 위함이다.
- 부가 설명
- map 자료구조는 string 형의 문자열을 인덱스로 받아서 특정 키 값에 접근시켜주는 자료구조이다.
- map 자료구조는 linked-list처럼 각 노드간 연결되어 있는 자료구조이기 때문에 vector 같은 배열처럼 index로 임의 접근이 불가하다.
- map 자료구조는 순차적으로 메모리가 할당되지 않는다.
- index로 임의접근이 불가하기 때문에 iterator(반복자)로 접근해야한다. (포인터와 비슷하다)
- auto 자료형은 입력받는 변수의 자료형을 입력받는 값의 자료형으로 자동으로 맞춰준다.
B. 타겟 넘버
#include <string>
#include <vector>
using namespace std;
void DFS(int *answer, int target, int sum, int depth, vector<int> numbers, int tmp)
{
sum += (numbers[depth - 1] * tmp);
if (depth != numbers.size())
{
depth++;
DFS(answer, target, sum, depth, numbers, -1);
DFS(answer, target, sum, depth, numbers, 1);
}
else
{
if (sum == target)
(*answer)++;
}
}
int solution(vector<int> numbers, int target) {
int sum = 0;
int answer = 0;
int depth = 1;
DFS(&answer, target, sum, depth, numbers, -1);
DFS(&answer, target, sum, depth, numbers, 1);
return answer;
}- 코드 설명
- 매개변수로 주어진 숫자들을 적절히 더하고 빼서 타겟넘버를 만들 수 있는 경우의 수를 반환하는 문제이다.
- DFS 알고리즘을 활용하여 매개변수 숫자들을 더하고 빼는 모든 경우의 수를 확인하였다.
- 재귀함수인 DFS 함수를 만들었고, soloution함수 내부 첫번째 노드에서 매개변수로 각각 -1과 1을 입력하여 DFS 함수를 두번 실행하였다.(각 숫자(노드)마다 -1과 1을 곱해야 하기 때문)
- DFS 함수 내부엔 조건문이 하나 있는데, 해당 조건문에서 depth와 매개변수 숫자의 크기를 비교해준다. 5. 만약, 같지 않을 경우에 depth를 하나늘려서 -1과 1을 입력하여 DFS 함수를 두 번 재귀 돌린다.
- 만약, 같을 경우에 재귀돌리면서 매개변수 숫자에 -1 또는 1을 곱하고 누적하여 더한 값인 sum과 타겟 넘버를 비교한다. 같은 경우, soloution에서 반환할 answer를 1 늘려준다.
- 재귀가 끝나면 soloution 함수에서 answer를 반환해준다.
- 부가 설명
- DFS에 대한 자세한 설명은 밑에서 다룬다.
C. 단체사진 찍기
#include <string>
#include <vector>
#include <algorithm>
#include <cmath>
using namespace std;
void check(vector<vector<char>> vec_tmp, vector<string> data, int *answer)
{
int flag;
for (int i = 0; i < vec_tmp.size(); i++)
{
flag = 0;
for (int j = 0; j < data.size(); j++)
{
auto a = find(vec_tmp[i].begin(), vec_tmp[i].end(), data[j][0]);
auto b = find(vec_tmp[i].begin(), vec_tmp[i].end(), data[j][2]);
if (data[j][3] == '=')
{
if (abs(b - a) - 1 != data[j][4] - '0')
{
flag = 1;
break;
}
}
else if (data[j][3] == '>')
{
if (abs(b - a) - 1 <= data[j][4] - '0')
{
flag = 1;
break;
}
}
else if (data[j][3] == '<')
{
if (abs(b - a) - 1 >= data[j][4] - '0')
{
flag = 1;
break;
}
}
}
if (flag == 0)
(*answer)++;
}
}
int solution(int n, vector<string> data) {
vector<char> character = {'A', 'C', 'F', 'J', 'M', 'N', 'R', 'T'};
vector<vector<char>> vec_tmp;
int answer = 0;
do {
vec_tmp.push_back(character);
} while (next_permutation(character.begin(), character.end()));
check(vec_tmp, data, &answer);
return answer;
}- 코드 설명
- next_permutation 함수를 do_while 반복문을 통해 실행하면서 charater vector에서 얻을 수 있는 모든 경우의 수를 vec_tmp 2차원 vector 변수에 넣는다.
- check 함수에서 vec_tmp 변수의 모든 경우의 수를 하나씩 고려하여 data로 받은 조건에 부합하는지 확인한다. 부합할 경우 포인터로 받은 answer 값을 1씩 늘려준다.
- check 함수가 끝나면 answer 값을 반환해준다.
- 부가 설명
- next_permutation 함수는 경우의 수를 반환하고자 하는 배열의 처음 iterator와 마지막 iterator를 입력 받아서 현재 경우의 수와 다른 경우의 수를 반환해주는 함수이다.
- next_permutation 함수를 사용할 때 do_while 반복문을 같이 사용하는 이유는 처음 경우의 수까지 고려하기 위함이다.
- find 함수는 특정 배열의 처음과 끝 iterator를 입력받고, 배열에서 찾고자 하는 값을 세번째 인자로 입력하면 배열내부에서 세번째 인자 값에 해당하는 iterator를 반환한다. 만약, 찾는 값이 없을 경우 배열의 마지막 iterator를 반환한다.
- using namespace std를 include 문 밑에 선언해준 이유는 std 라이브러리를 활용하는 코딩을 간편화 시켜주기 위함이다. 해당 선언이 없을 경우, std 라이브러리 함수 앞에 특정 문구를 추가해야하는 번거러움이 발생한다.
D. 올바른 괄호
#include <string>
using namespace std;
bool solution(string s)
{
bool answer = true;
int tmp = 0;
for (int i = 0; i < s.size(); i++)
{
if (s[i] == '(')
tmp++;
else if (s[i] == ')')
tmp--;
if (tmp < 0)
break;
}
if (tmp != 0)
answer = false;
return answer;
}- 코드 설명
- 올바르게 괄호가 열리고 닫혔는지, 괄호의 짝이 맞는지 확인하는 문제이다.
- '('가 입력되면 tmp를 증가시키고 ')'가 입력되면 tmp를 감소시켰다.
- tmp가 음수가 되는 순간은 tmp가 먼저 열리고 닫히지 않은 순간이라고 판단하였다.
- 마지막에 tmp 값이 0인지 확인하여 0이 아니라면 false를 반환하도록 하였다.
E. 방문 길이
#include <string>
#include <vector>
using namespace std;
int solution(string dirs) {
vector<pair<int, int>> vec_tmp; // pos가 지나온 노드 저장
pair<int, int> pos(0, 0); // pos의 좌표 표현
int answer = 0;
int flag;
vec_tmp.push_back(pos);
for (int i = 0; i < dirs.size(); i++)
{
flag = 0;
if (dirs[i] == 'U') // pos 이동
pos.second++;
else if (dirs[i] == 'D')
pos.second--;
else if (dirs[i] == 'L')
pos.first--;
else if (dirs[i] == 'R')
pos.first++;
if (pos.first > 5) // pos 최대 최솟값 제한
pos.first--;
else if (pos.first < -5)
pos.first++;
else if (pos.second > 5)
pos.second--;
else if (pos.second < -5)
pos.second++;
for (int j = 0; j < vec_tmp.size(); j++)
{
if (pos.first == vec_tmp[j].first && pos.second == vec_tmp[j].second) // pos가 지나온 적 있는 노드인지 확인
{
if (vec_tmp[vec_tmp.size() - 1].first == vec_tmp[j - 1].first && vec_tmp[vec_tmp.size() - 1].second == vec_tmp[j - 1].second) // 지나온적 있는 노드라면 간선도 지나왔던 간선인지 확인
flag = 1;
else if (vec_tmp[vec_tmp.size() - 1].first == vec_tmp[j + 1].first && vec_tmp[vec_tmp.size() - 1].second == vec_tmp[j + 1].second)
flag = 1;
}
}
if (!(vec_tmp[vec_tmp.size() - 1].first == pos.first && vec_tmp[vec_tmp.size() - 1].second == pos.second)) // 움직인 후의 위치와 전의 위치가 같은지 확인 (좌표의 최대 최솟값 제한으로 인해 차이가 없을 수도 있음)
vec_tmp.push_back(pos);
else
flag = 1;
if (flag == 0) // flag가 0일때는 지나온 간선이 처음 지난 간선을 의미
answer++;
}
return answer;
}- 코드 설명
- pos가 지나온 간선을 어떤식으로 저장할지가 핵심인 문제이다.
- pos의 위치는 pair로 저장하고 pos가 지나온 노드는 vec_tmp에 차곡차곡 쌓기로 하였다.
- for loop에 처음 들어가면 dirs 값에 따라 pos를 이동시켰다.
- 두번째 조건문에서 pos의 최대 최소값으로 제한하였다.
- 안쪽의 for loop에서 이동한 노드가 이미 지나온 노드인지 확인하였다.
- 이미 지나온 노드로 판단되면 이동 전의 노드끼리 비교하여 이미 지나온 간선인지 판단하였다. 이미 지나온 간선이라면 flag에 1을 입력한다.
- 최대 최솟값 제한으로 pos가 이동하지 않았다면 flag에 1을 입력한다.
- flag가 0일때 solution 함수에서 반환할 answer를 1만큼 증가시켰다.
- 부가 설명
- 내 기억에 스터디원인 sejpark님은 0.5씩 증가시키는 방식으로 간선을 체크하였다.
F. 이진 변환 반복하기
#include <string>
#include <vector>
using namespace std;
string ft_to_digit(int n)
{
string result = "";
string tmp;
while (n)
{
if (n % 2 == 0)
tmp = "0";
else
tmp = "1";
result = tmp + result;
n /= 2;
}
return (result);
}
vector<int> solution(string s) {
vector<int> answer(2, 0);
int int_tmp;
while (1)
{
for (int i = 0; i < s.size(); i++)
{
if (s[i] == '0')
{
s.erase(s.begin() + i--);
answer[1]++;
}
}
int_tmp = s.size();
s = ft_to_digit(int_tmp);
answer[0]++;
if (s == "1")
break;
}
return answer;
}- 코드 설명
- 이진 변환의 횟수와 변환 중 제거된 0의 갯수를 반환하는 문제이다.
- 먼저, 이진수 문자열에서 0을 모두 제거하고 남은 길이를 다시 2진수로 변환한다.
- 위 과정을 1이 될 때까지 반복한다.
- while loop 내부의 for loop에서 이진수 문자열의 0들을 모두 제거한다. 제거할 때마다 제거된 0의 갯수를 나타내는 answer의 1 인덱스 값을 1씩 올려준다.
- 제거한 후 문자열의 길이를 이진수 문자열로 변환한다.
- 이진 변환 횟수를 나타내는 answer 0 인덱스 값을 while loop가 돌아갈 때마다 1씩 올려준다.
- 변환된 이진수 문자열이 "1"일 때, while loop를 빠져나온다.
G. 카펫
#include <string>
#include <vector>
using namespace std;
vector<int> solution(int brown, int yellow) {
vector<int> answer;
int int_tmp = (brown - 4) / 2;
int result1;
int result2;
for (int i = 1; i <= int_tmp / 2; i++)
{
if (yellow == (int_tmp - i) * i)
{
result1 = int_tmp - i + 2;
result2 = i + 2;
break;
}
}
answer.push_back(result1);
answer.push_back(result2);
return answer;
}- 코드 설명
- 겉을 둘러싸는 brown 카펫의 갯수와 안쪽의 yellow 카펫의 갯수를 토대로 카펫의 가로세로 길이를 구하는 문제이다.
- 겉을 둘러싸는 brown 카펫의 꼭지점 카펫(4개)를 뺀 후에 2를 나누어주었다.
- 더해서 나누어준 값이 나오는 여러 경우의 수를 고려하였고 가로세로가 넓이라는 점을 착안해서 각 경우의 수에서 가로세로 계산을 수행하여 yellow 카펫의 수가 나오는 경우를 찾았다.
H. 튜플
#include <string>
#include <vector>
#include <algorithm>
using namespace std;
bool compare(pair<int, int> a, pair<int, int> b)
{
return (a.second > b.second);
}
vector<int> solution(string s) {
vector<int> answer;
vector<int> tmp;
vector<vector<int>> intvec_tmp;
vector<pair<int, int>> vec_tmp;
pair<int, int> pair_tmp;
string str_tmp = "";
int flag = 0;
for (int i = 0; i < s.size(); i++)
{
if (s[i] >= '0' && s[i] <= '9')
str_tmp += s[i];
else if (s[i] == ',' && flag == 2)
{
tmp.push_back(stoi(str_tmp));
str_tmp = "";
}
else if (s[i] == '}' && flag == 2)
{
tmp.push_back(stoi(str_tmp));
intvec_tmp.push_back(tmp);
str_tmp = "";
tmp.clear();
flag--;
}
else if (s[i] == '{')
flag++;
}
for (int i = 0; i < intvec_tmp.size(); i++)
{
for (int j = 0; j < intvec_tmp[i].size(); j++)
{
flag = 0;
for (int z = 0; z < vec_tmp.size(); z++)
{
if (intvec_tmp[i][j] == vec_tmp[z].first)
{
vec_tmp[z].second++;
flag = 1;
break;
}
}
if (flag == 0)
{
pair_tmp.first = intvec_tmp[i][j];
pair_tmp.second = 1;
vec_tmp.push_back(pair_tmp);
}
}
}
sort(vec_tmp.begin(), vec_tmp.end(), compare);
for (int i = 0; i < vec_tmp.size(); i++)
answer.push_back(vec_tmp[i].first);
return answer;
}- 코드 설명
- 처음 for loop에서 2차원 vector 형태로 입력된 문자열을 split 해준다.
- 두번째 for loop에서 문자열 내부의 문자 중복 횟수를 세어줄 것이다.
- 문자 중복 횟수는 pair 형태로 특정 문자와 쌍을 이룰 것이다.
- 문자 중복 횟수를 기준으로 내림차순 정렬한다.
- 정렬 순서대로 answer vector에 쌓아준다.
I. 다음 큰 숫자
#include <string>
#include <vector>
using namespace std;
int one_num(string digit)
{
int result = 0;
for (int i = 0; i < digit.size(); i++)
{
if (digit[i] == '1')
result++;
}
return (result);
}
string to_digit(int n)
{
string result = "";
while (n)
{
result = to_string(n % 2) + result;
n /= 2;
}
return (result);
}
int solution(int n) {
int answer = 0;
string n_digit = to_digit(n);
string str_tmp;
int int_tmp;
int one = one_num(n_digit);
int i = n + 1;
while (1)
{
str_tmp = to_digit(i);
int_tmp = one_num(str_tmp);
if (int_tmp == one)
{
answer = i;
break;
}
i++;
}
return answer;
}- 코드 설명
- 주어진 n보다 큰 수중 2진수의 1의 갯수가 같은 수를 찾는 문제이다.
- n부터 1씩 증가시키면서 이진수 변환 후 1의 갯수를 세어주는 과정을 반복하였다.
- n의 2진수 1의 갯수가 똑같은 지점을 if문을 통해 찾아내었고 그에 해당하는 값을 반환하였다.
J. 숫자의 표현
using namespace std;
int solution(int n) {
int answer = 0;
int tmp;
for (int i = 0; i <= n; i++)
{
tmp = 0;
for (int j = i; n > tmp; j++)
{
tmp += j;
if (n == tmp)
answer++;
}
}
return answer;
}- 코드 설명
- 연속 숫자들을 더하여 입력된 n 값을 몇 번 만들 수 있는지 알아내는 문제이다.
- 바깥쪽 for loop를 활용하여 연속 숫자의 처음 숫자를 결정하였고, 안쪽 for loop를 활용하여 처음 숫자부터 연속적으로 숫자를 더해나갔다.
- if문을 활용하여 연속적으로 더한 값이 n과 같을 경우, 반환될 answer값에 1을 더해주었다.
K. 최댓값과 최솟값
#include <string>
#include <vector>
#include <iostream>
using namespace std;
int compare(string s1, string s2)
{
if (s1[0] == '-' && s2[0] != '-')
return (0);
else if (s1[0] != '-' && s2[0] == '-')
return (1);
else if (s1[0] == '-' && s2[0] == '-')
{
if (s1.length() == s2.length())
{
for (int i = 1; i < s1.size(); i++)
{
if (s1[i] > s2[i])
return (0);
else if (s1[i] < s2[i])
return (1);
}
}
else
{
if (s1.length() > s2.length())
return (0);
else
return (1);
}
}
else if (s1[0] != '-' && s2[0] != '-')
{
if (s1.length() == s2.length())
{
for (int i = 0; i < s1.size(); i++)
{
if (s1[i] < s2[i])
return (0);
else if (s1[i] > s2[i])
return (1);
}
}
else
{
if (s1.length() < s2.length())
return (0);
else
return (1);
}
}
return (0);
}
string solution(string s) {
string answer = "";
vector<string> vec_tmp;
string str_tmp = "";
for (int i = 0; i < s.size(); i++)
{
if (s[i] == ' ')
{
vec_tmp.push_back(str_tmp);
str_tmp = "";
}
else
str_tmp += s[i];
}
vec_tmp.push_back(str_tmp);
for (int i = 0; i < vec_tmp.size(); i++)
cout << vec_tmp[i] << endl;
for (int i = 0; i < vec_tmp.size() - 1; i++)
{
for (int j = i + 1; j < vec_tmp.size(); j++)
{
if (compare(vec_tmp[i], vec_tmp[j]))
{
str_tmp = vec_tmp[i];
vec_tmp[i] = vec_tmp[j];
vec_tmp[j] = str_tmp;
}
}
}
answer += vec_tmp[0];
answer += " ";
answer += vec_tmp[vec_tmp.size() - 1];
return answer;
}- 코드 설명
- int형 숫자형태로 쓰여진 문자열 string에서 최댓값 최솟값을 찾아 반환하는 문제이다.
- 첫번째 for loop에서 공백을 기준으로 숫자들을 split하여 vec_tmp에 넣어주었다.
- 버블 sort 알고리즘을 활용하여 문자열 형태의 숫자들을 오름차순 정렬하였다.
- 숫자의 비교는 compare라는 함수에서 이루어진다.
- 먼저 부호가 서로 다를경우에는 어느 문자열이 음수냐에 따라 return 하는 값이 달라진다. (첫번째 인자로 입력된 문자열이 두번째 문자열보다 작을 경우 0을 반환한다.)
- 부호가 같을 경우 숫자의 길이를 먼저 비교할 것이고 숫자의 길이마저 같을 경우 자릿수를 내려가면서 각 자릿수마다 숫자를 비교할 것이다.(양수 음수에 비교 방식이 다름)
L. 행렬의 곱셈
#include <string>
#include <vector>
using namespace std;
vector<vector<int>> solution(vector<vector<int>> arr1, vector<vector<int>> arr2) {
vector<vector<int>> answer;
vector<int> vec_tmp;
int int_tmp;
for (int i = 0; i < arr1.size(); i++)
{
for (int j = 0; j < arr2[0].size(); j++)
{
int_tmp = 0;
for (int z = 0; z < arr1[i].size(); z++)
int_tmp += arr1[i][z] * arr2[z][j];
vec_tmp.push_back(int_tmp);
}
answer.push_back(vec_tmp);
vec_tmp.clear();
}
return answer;
}- 코드 설명
- 말그대로 행렬의 곱셈 로직을 구현하는 문제이다.
- 첫번째 두번째 for loop에서 arr1과 arr2를 각각 비교할 것이고 세번째 for loop에서 각 인자에 맞게 곱해주고 더해주는 과정을 거친다.
- 곱셈의 결과는 vec_tmp를 매개로 반환할 vector인 answer에 쌓인다.
M. JadenCase 문자열 만들기
#include <string>
#include <vector>
using namespace std;
string solution(string s) {
string answer = "";
int flag = 1;
for (int i = 0; i < s.size(); i++)
{
if (s[i] == ' ')
flag = 1;
else
{
if (flag == 1 && s[i] >= 'a' && s[i] <= 'z')
s[i] -= 32;
else if (flag == 0 && s[i] >= 'A' && s[i] <= 'Z')
s[i] += 32;
flag = 0;
}
}
answer = s;
return answer;
}- 코드 설명
- 입력문자열을 모든 단어의 첫 문자는 대문자이고 나머지 문자는 모두 소문자인 Jadencase 문자열로 바꾸는 문제이다.
- for loop를 돌려서 입력 문자열을 하나씩 검사할 것이다.
- 공백문자일 경우 flag에 1을 입력하여 다음 문자는 대문자임을 알려줄 것이다.
- flag가 1일 때 소문자 알파벳일 경우, 대문자로 바꿔주고 flag가 0일 때 대문자 알파벳일 경우, 소문자로 바꿔준다.
N. 예상 대진표
#include <iostream>
#include <cmath>
using namespace std;
int solution(int n, int a, int b)
{
int answer = 1;
while (1)
{
if (abs(b - a) == 1 && a / 2 != b / 2)
break;
else
answer++;
if (a % 2 == 0)
a /= 2;
else
a = (a / 2 + 1);
if (b % 2 == 0)
b /= 2;
else
b = (b / 2 + 1);
}
return answer;
}- 코드 설명
- 대진표에서 왼쪽부터 차레대로 번호가 부여되는데 인자 a, b로 부여된 번호가 입력되면 해당 번호들을 부여받은 참가자가 몇번째 매치에서 맞붙을 수 있는지 return 하는 문제이다.
- while 문에서 두 참가자의 번호에 계속 2를 나누어줄 것이고 한번 돌아갈 때마다 answer를 1씩 증가시켜줄 것이다.
- 두 참가자 번호의 차이가 1이고 다음 2를 나눈 값이 서로 같을 경우에 while문을 빠져나온다.
- 다음 2를 나눈 값이 같지 않을 조건을 추가한 이유는 번호의 차이가 1이지만 서로 맞붙는 경우가 아닐 경우를 제외시키기 위해서이다.
3. DFS/BFS 개념 정리
A. DFS(Depth-First Search)
DFS(Depth-First Search)는 하나의 정점에서 시작하여 모든 정점들을 하나씩 방문하는
그래프 탐색알고리즘이다. 이름 그대로 하나의 경로를 완전히 탐색한 후에 다음 경로를 완전히 탐색하는 방식으로 모든 정점을 방문한다. 특정 도시에서 다른 도시로 갈 수 있는지 파악하는 문제나 전자회로에서 특정 단자 간에 연결을 확인하는 문제에서 주로 사용된다.
- DFS의 과정
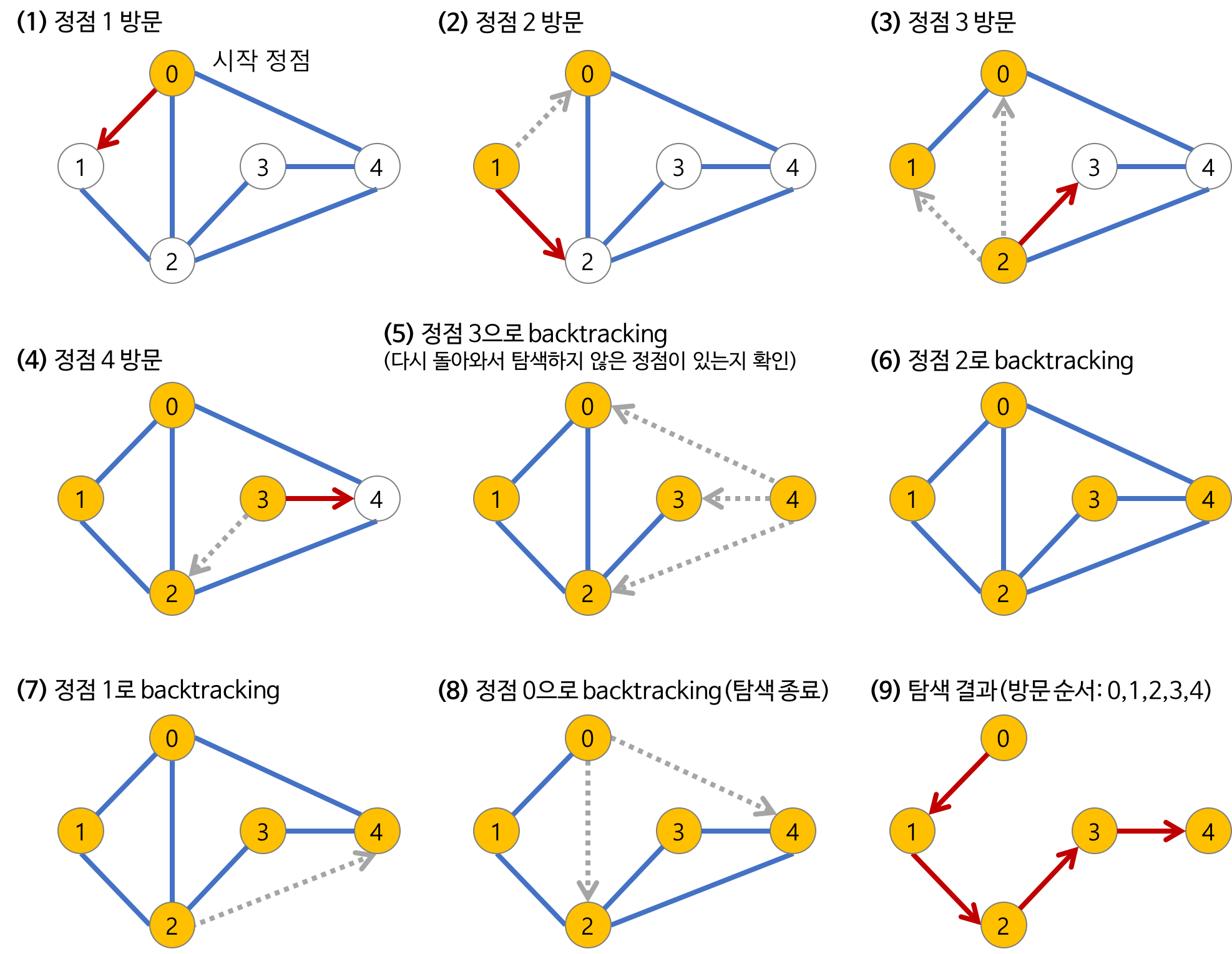
그림 출처 : https://gmlwjd9405.github.io/2018/08/14/algorithm-dfs.html - DFS 구현
: 스택을 활용하는 방법과 재귀를 활용하는 방법이 있다.
#include <string>
#include <vector>
using namespace std;
void DFS(int *answer, int target, int sum, int depth, vector<int> numbers, int tmp)
{
sum += (numbers[depth - 1] * tmp);
if (depth != numbers.size())
{
depth++;
DFS(answer, target, sum, depth, numbers, -1);
DFS(answer, target, sum, depth, numbers, 1);
}
else
{
if (sum == target)
(*answer)++;
}
}
int solution(vector<int> numbers, int target) {
int sum = 0;
int answer = 0;
int depth = 1;
DFS(&answer, target, sum, depth, numbers, -1);
DFS(&answer, target, sum, depth, numbers, 1);
return answer;
}- 위 코드는 위에서 다룬
타겟 넘버문제이다. 해당 문제는 재귀를 활용한 DFS로 풀 수 있는 가장 쉬운 문제이다.
B. BFS(Breadth-First Search)
BFS(Breadth-First Search)는 하나의 정점에서 시작하여 모든 정점들을 하나씩 방문하는
그래프 탐색알고리즘이다. 이름 그대로 가장 인접한 정점을 우선적으로 탐색하는 알고리즘이다. 최단경로 문제에 주로 활용된다.
- BFS의 과정
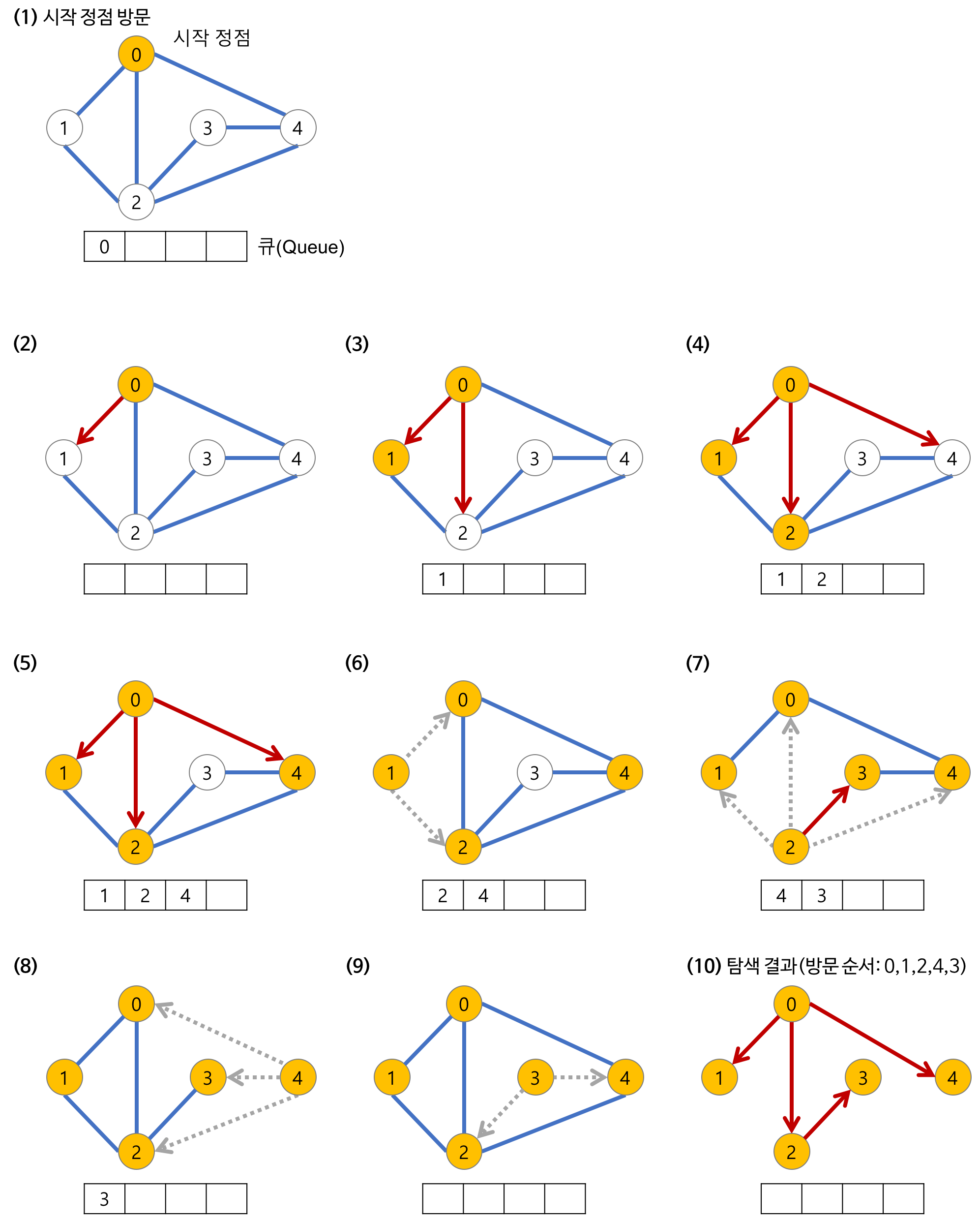
그림 출처 : https://velog.io/@sukong/%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98-%EA%B0%9C%EB%85%90-%EB%84%88%EB%B9%84%EC%9A%B0%EC%84%A0%ED%83%90%EC%83%89BFS-lp8zywtn - BFS 구현
- 루트노드에서 시작한다.
- 루트노드와 인접하고 방문된적 없고, Queue에 저장되지 않은 노드를 Queue에 넣는다.(방문된 노드는 Queue에 저장되어 있다.)
- Queue에서 pop하여 가장 먼저 큐에 저장한 노드를 방문한다.
#include <string>
#include <vector>
#include <queue>
using namespace std;
int check(vector<int> num)
{
for (int i = 0; i < num.size(); i++)
{
if (num[i] == 0)
return (i);
}
return (-1);
}
void BFS(vector<vector<int>> computers, vector<int> &visit, int start)
{
int node;
queue<int> q;
q.push(start);
visit[start] = 1;
while (!q.empty())
{
node = q.front();
q.pop();
for (int i = 0; i < computers[node].size(); i++)
{
if (node != i && visit[i] == 0 && computers[node][i] == 1)
{
q.push(i);
visit[i] = 1;
}
}
}
}
int solution(int n, vector<vector<int>> computers) {
vector<int> visit(computers.size(), 0);
int answer = 0;
int start;
while (1)
{
start = check(visit);
if (start > -1)
{
BFS(computers, visit, start);
answer++;
}
else
break;
}
return answer;
}- 위 코드는 BFS 알고리즘을 활용하여 풀 수 있는 간단한
네트워크라는 문제의 코드이다. 노드간 완전히 연결되어 있는 네트워크의 수가 몇 개인지 구하는 문제이다.
네트워크 문제 : https://programmers.co.kr/learn/courses/30/lessons/43162 - 코드 설명
- 노드의 갯수 n과 노드간 연결을 나타내는 computers vector를 인자로 받는다.
- visit vector를 선언하여 노드의 방문을 표시할 것이다.
- while문 안에서 check 함수를 활용하여 방문한 적 없는 노드를 start 변수에 넣을 것이다.
- start 변수에 -1이 입력되었을 경우 while문을 빠져나온다.(모든 노드를 방문했다는 의미)
- BFS 함수에 start 변수와 함께 computers vector와 visit vector를 인자로 입력할 것이다.
- BFS 함수 내부에서 queue를 하나 선언하고 visit 하나를 넣은 후에 while문으로 들어간다.
- queue에 값이 있을 동안 돌아갈 것인데 queue에서 하나씩 pop하고 for loop에서 pop된 노드와 연결된 노드가 있는지 확인할 것이다.
- 연결된 노드가 없을 경우, queue에 아무 노드도 입력되지 않아서 자연스럽게 while문을 빠져나올 것이다.
- 연결된 노드를 찾은 경우, queue에 해당 노드를 넣고 visit vector에 방문 표시를 할 것이다.
4. BFS 문제 풀기
BFS 알고리즘을 숙련시키기 위해
단어 변환문제와게임 맵 최단거리문제를 더 풀어보았다.
단어변환 문제 : https://programmers.co.kr/learn/courses/30/lessons/43163
게임 맵 최단거리 문제 : https://programmers.co.kr/learn/courses/30/lessons/1844
A. 단어변환 문제
#include <string>
#include <vector>
#include <queue>
#include <map>
#include <algorithm>
using namespace std;
int check(string s1, string s2)
{
int result = 0;
for (int i = 0; i < s1.size(); i++)
{
if (s1[i] != s2[i])
result++;
}
return (result);
}
int visit_fn(string s, vector<pair<string, int>> visit)
{
for (int i = 0; i < visit.size(); i++)
{
if (s == visit[i].first)
return (1);
}
return (0);
}
int solution(string begin, string target, vector<string> words) {
int answer = 0;
int flag = 0;
pair<string, int> pos;
queue<pair<string, int>> q;
vector<pair<string, int>> visit;
pair<string, int> tmp;
tmp.first = begin;
tmp.second = 0;
visit.push_back(tmp);
q.push(tmp);
while (!q.empty() && flag == 0)
{
pos = q.front();
q.pop();
for (int i = 0; i < words.size(); i++)
{
if (check(pos.first, words[i]) == 1)
{
if (words[i] == target)
{
answer = pos.second + 1;
flag = 1;
break;
}
if (!visit_fn(words[i], visit))
{
tmp.first = words[i];
tmp.second = pos.second + 1;
visit.push_back(tmp);
q.push(tmp);
}
}
}
}
return answer;
}- 코드 설명
- 두 개의 단어 begin, target과 단어의 집합 words 가 인자로 입력되면 begin에서 words단어 몇개를 거쳐야 target 단어가 만들어지는지 구하는 문제이다. 단어가 한번 변할 때 단어의 글자 한개만 변환할 수 있고 변환 후의 단어가 words에 있어야 한다.
- queue를 하나 선언하여 pair형 데이터를 넣을 것이다. pair는 first로 단어가 입력될 것이고 second로 몇 번째 변환인지 나타낼 것이다.
- 첫 번째 while문은 선언된 queue에 데이터가 있고 변환의 끝을 알리는 flag가 0일 동안 돌아간다.
- while문 안에서 queue의 데이터가 하나씩 pop될 것이고 for loop를 통해 pop된 단어를 비교하여 words의 단어 중 글자 하나만 다른 단어를 찾을 것이다.
- 방문한 적 있는 단어는 visit vector에 입력되어 있는데 찾은 단어를 visit vector와 비교하여 방문한적 없는 단어라면 해당 단어를 pair 형태로 queue에 넣을 것이다. 이 때, pair의 second는 pop된 pair.second에서 1을 증가시켜서 넣어줄 것이다.
- 4번 과정에서 찾은 단어가 target 단어일 경우, answer에 현재 pair 데이터에 1을 더해서 넣어 줄 것이고 flag에 1을 표시한 후 for loop를 빠져 나올 것이다.
- flag 에 1이 입력되어 while문 까지 빠져나오면 계산된 answer가 return된다.
B. 게임 맵 최단거리 문제
원래는 DFS 알고리즘을 활용하여 풀었으나 효율성이 없는 방식이었다.(시간 초과) 그래서 BFS 알고리즘을 활용하였고, 시간을 단축시킬 수 있었다.
#include <vector>
#include <queue>
using namespace std;
int solution(vector<vector<int>> maps)
{
int answer = -1;
int n = maps[0].size();
int m = maps.size();
pair<int, int> pos(0, 0);
pair<int, int> after_pos;
queue<pair<int, int>> q;
vector<vector<int>> visit(m, vector<int>(n, 0)); // **
q.push(pos);
visit[pos.second][pos.first] = 1;
while (!q.empty())
{
pos = q.front();
q.pop();
if (maps[pos.second + 1][pos.first] == 1)
{
if (pos.second + 1 < m && visit[pos.second + 1][pos.first] == 0)
{
after_pos.first = pos.first;
after_pos.second = pos.second + 1;
visit[pos.second + 1][pos.first] = (visit[pos.second][pos.first] + 1);
if (after_pos.first == n - 1 && after_pos.second == m - 1)
{
answer = visit[after_pos.second][after_pos.first];
break;
}
q.push(after_pos);
}
}
if (maps[pos.second - 1][pos.first] == 1)
{
if (pos.second - 1 >= 0 && visit[pos.second - 1][pos.first] == 0)
{
after_pos.first = pos.first;
after_pos.second = pos.second - 1;
visit[pos.second - 1][pos.first] = (visit[pos.second][pos.first] + 1);
if (after_pos.first == n - 1 && after_pos.second == m - 1)
{
answer = visit[after_pos.second][after_pos.first];
break;
}
q.push(after_pos);
}
}
if (maps[pos.second][pos.first + 1] == 1)
{
if (pos.first + 1 < n && visit[pos.second][pos.first + 1] == 0)
{
after_pos.first = pos.first + 1;
after_pos.second = pos.second;
visit[pos.second][pos.first + 1] = (visit[pos.second][pos.first] + 1);
if (after_pos.first == n - 1 && after_pos.second == m - 1)
{
answer = visit[after_pos.second][after_pos.first];
break;
}
q.push(after_pos);
}
}
if (maps[pos.second][pos.first - 1] == 1)
{
if (pos.first - 1 >= 0 && visit[pos.second][pos.first - 1] == 0)
{
after_pos.first = pos.first - 1;
after_pos.second = pos.second;
visit[pos.second][pos.first - 1] = (visit[pos.second][pos.first] + 1);
if (after_pos.first == n - 1 && after_pos.second == m - 1)
{
answer = visit[after_pos.second][after_pos.first];
break;
}
q.push(after_pos);
}
}
}
return answer;
}- 코드 설명
- 게임 맵이 2차원 vector형인 maps로 주어지면 왼쪽 상단에 위치한 pos에서 우측 하단에 위치한 목적지까지 최단거리를 구하는 문제이다.
- 현재 pos위치와 한칸 뒤 pos위치를 pair형으로 두 번 선언하였다.
- pos데이터를 넣을 queue와 2차원 벡터 형태로 visit를 선언하여 map의 방문을 표시하였다.
- 현재 pos위치를 (0, 0)으로 초기화 하고 queue에 넣어주었다.
- queue에 데이터가 없을 때까지 돌아가는 while문 내에서 queue데이터를 하나 pop하고 pop한 pos의 위치 상하좌우가 벽인지 if 조건문으로 확인할 것이다.
- 상하좌우 중 벽이 아닌 경우가 있으면 if 조건문 내부로 들어와서 현재 pos의 다음 위치가 map의 범위를 벗어나는지, 방문한적 있는 노드인지 확인할 것이다.
- 만약 방문한적 없고 map의 범위 내부라면 다음 노드의 방문을 visit 2차원 벡터에 체크하고 해당 노드가 목적지라면 answer에 해당 노드의 visit 값을 넣고 while문을 빠져나온다. visit 2차원 벡터에 체크할 때, 이전 노드의 visit 값에서 1 더한 값을 넣어 체크한다. 이를 통해 노드가 몇 번째 이동했는지 나타낼 수 있다.
- 부가 설명
- 2차원 벡터는
vector<vector<int>> visit(m, vector<int>(n, 0));형태로 초기화가 가능하다.
